
Part2. SQL 기본 및 활용
CHATER 2. SQL 활용
1. 서브쿼리(Subquery)
- 서브쿼리 ⭐️⭐️
하나의 쿼리 안에 존재하는 또 다른 쿼리-
위치에 따른 분류
위치 분류 SELECT 절
ORDER BY 절
UPDATE 문의 SET 절
INSERT 문의 VALUE 절스칼라 서브쿼리(Scalar Subquery) FROM 절 인라인 뷰(Inline View) WHERE 절, HAVING 절 중첩 서브쿼리(Nested Subquery) -
스칼라 서브쿼리
- 주로 SELECT 절에 위치하지만 컬럼이 올 수 있는 대부분 위치에 사용 가능
- 컬럼 대신 사용되므로 반드시 하나의 값만을 반환해야 하며 그렇지 않은 경우 에러 발생
SELECT R.PRODUCT_ID, (SELECT P.PRODUCT_NAME FROM PRODUCT P WHERE P.PRODUCT_ID = R.PRODUCT_ID) AS PRODUCT_NAME, R.MEMEBER_ID, R.CONTENT FROM REVIEW R; -
인라인 뷰
- FROM 절 등 테이블명이 올 수 있는 위치에 사용 가능
SELECT R.PRODUCT_ID, P.PRODUCT_NAME, P.PRODUCT_PRICE, R.MEMBER_ID, R.CONTENT FROM REVIEW R, (SELECT PRODUCT_ID, PRODUCT_NAME, PRICE FROM PRODUCT) P WHERE R.PRODUCT_ID = P.PRODUCT_ID; -
중첩 서브쿼리
-
WHERE 절과 HAVING 절에 사용 가능
-
메인 쿼리와 관계에 따른 분류
분류 메인 쿼리와 관게 비연관 서브쿼리
(Uncorrelated Subquery)· 메인 쿼리와 관계를 맺고 있지 않음
· 서브쿼리 내에 메인 쿼리의 컬럼이 존재하지 않음연관 서브쿼리
(Correlated Subquery)· 메인 쿼리와 관계를 맺고 있음
· 서브쿼리 내에 메인 쿼리의 컬럼 존재 -
반환 데이터 형태에 따른 분류
분류 반환 데이터 형태 단일 행(Single Row) 서브쿼리 · 서브쿼리가 항상 1건 이하의 데이터 반환
· 단일 행 비교 연산자와 함께 사용
ex) =, <, >, <=, >=, <>다중 행(Multi Row) 서브쿼리 · 서브쿼리가 여러 건의 데이터 반환
· 다중 행 비교 연산자와 함께 사용
ex) IN, ALL, ANY, SOME, EXISTS다중 컬럼(Multi Column) 서브쿼리 서브쿼리가 여러 컬럼의 데이터 반환
💡 ANY, SOME
서브쿼리 결과 중 하나라도 참이면TURE반환 -
-
2. 뷰(View)
- 뷰 ⭐️
특정 SELECT 문에 이름을 붙여 재사용 가능하도록 저장해놓은 오브젝트- 가상 테이블
- 실제 데이터를 저장하지는 않고 해당 데이터를 조회해오는 SELECT 문만 가지고 있음
CREATE OR REPLACE VIEW DEPT_MEMBER AS SELECT D.ID, D.NAME, M.FIRST_NAME, M.LAST_NAME FROM DEPARTMENT D INNER JOIN MEMBER M ON D.ID = M.DEPARTMENT_ID; - 뷰 특징 ⭐️⭐️
특징 설명 보안성 보안이 필요한 컬럼을 가진 가상 테이블일 경우 해당 컬럼을 제외한 별도의 뷰를 생성하여 제공
함으로써 보안 유지 가능독립성 테이블 스키마가 변경되었을 경우 어플리케이션은 변경하지 않고 관련 뷰만 수정 편리성 복잡한 쿼리 구문을 뷰명으로 단축시킴으로써 가독성을 높이고 편리하게 사용 가능
3. 집합 연산자
- 각 쿼리의 결과 집합을 가지고 연산하는 명령어 ⭐️⭐️
집합 명령어 의미 UNION ALL 각 쿼리의 결과 집합의 합집합. 중복된 행도 그대로 출력 UNION 각 쿼리의 결과 집합의 합집합. 중복된 행은 한 줄로 출력 INTERSECT 각 쿼리의 결과 집합의 교집합. 중복된 행은 한 줄로 출력 MINUS/EXCEPT 앞에 있는 쿼리의 결과 집합에서 뒤에 있는 쿼리의 결과 집합을 뺀 차집합.
중복된 행은 한 줄로 출력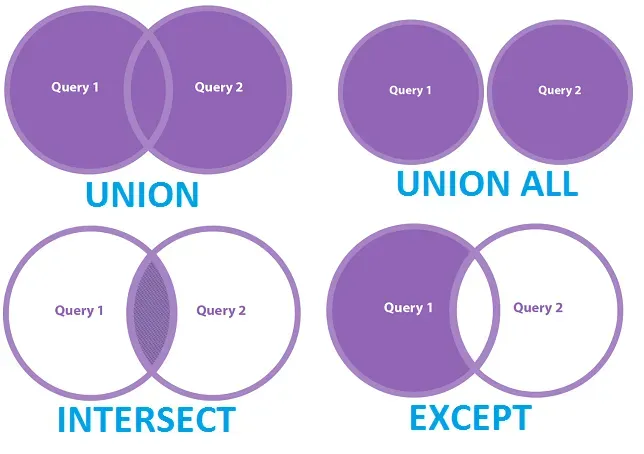
-
UNION ALL
SELECT * FROM RUNNING_MAN UNION ALL SELECT * FROM INFINITE_CHALLENGE; -
UNION
- 데이터베이스 내부적으로 중복된 행을 제거하는 과정을 거쳐야하므로 성능상 불리할 수 있음
SELECT * FROM RUNNING_MAN UNION SELECT * FROM INFINITE_CHALLENGE; -
INTERSECT
SELECT * FROM RUNNING_MAN INTERSECT SELECT * FROM INFINITE_CHALLENGE; -
MINUS/EXCEPT
SELECT * FROM RUNNING_MAN MINUS SELECT * FROM INFINITE_CHALLENGE;💡 두 쿼리 결과를 연산할 때, 컬럼명이 다르면?
헤더값은 첫 번째 쿼리를 따라간다!
ex) TABLE1(EN, JB), TABLE2(NM, JI) → RESULT(EN, JB)
-
4. 그룹 함수
- 그룹 함수 ⭐️⭐️
데이터를GROUP BY하여 나타낼 수 있는 데이터를 구하는 함수
- 역할에 따른 분류 ⭐️⭐️
집계 함수 COUNT, SUM, AVG, MAX, MIN 등 총계 함수 ROLLUP, CUBE, GROUPING SETS 등 - ROLLUP ⭐️⭐️
-
소그룹 간의 소계 및 총계를 계산하는 함수
-
인자 순서에 따라서 결과가 달라짐
함수 결과 ROLLUP(A) · A로 그룹핑
· 총합계ROLLUP(A, B) · A, B로 그룹핑
· A로 그룹핑
· 총합계ROLLUP(A, B, C) · A, B, C로 그룹핑
· A, B로 그룹핑
· A로 그룹핑
· 총합계 -
예시:
GROUP BY ROLLUP(DEPARTMENT, JOB)
- 부서별, 직무별 상세 집계 (DEPARTMENT, JOB)
- 부서별 소계 (DEPARTMENT, NULL)
- 전체 합계 (NULL, NULL)SELECT DEPARTMENT, JOB, COUNT(*) AS EMP_COUNT, SUM(SALARY) AS TOTAL_SALARY FROM EMPLOYEE GROUP BY ROLLUP(DEPARTMENT, JOB);DEPARTMENT JOB EMP_COUNT TOTAL_SALARY IT 개발자 3 15000000 IT DBA 2 12000000 IT NULL 5 27000000 영업 영업사원 4 16000000 영업 영업관리자 1 8000000 영업 NULL 5 24000000 NULL NULL 10 51000000
-
- CUBE ⭐️⭐️
-
소그룹 간의 소계 및 총계를 다차원적으로 계산할 수 있는 함수
-
조합할 수 있는 모든 그룹에 대한 소계 집계
함수 결과 CUBE(A) · A
· 총합계CUBE(A, B) · A, B로 그룹핑
· A로 그룹핑
· B로 그룹핑
· 총합계CUBE(A, B, C) · A, B, C로 그룹핑
· A, B로 그룹핑
· A, C로 그룹핑
· B, C로 그룹핑
· A로 그룹핑
· B로 그룹핑
· C로 그룹핑
· 총합계 -
예시:
GROUP BY CUBE(DEPARTMENT, JOB)
- 부서별, 직무별 상세 집계 (DEPARTMENT, JOB)
- 부서별 집계 (DEPARTMENT, NULL)
- 직무별 집계 (NULL, JOB)
- 전체 합계 (NULL, NULL)SELECT DEPARTMENT, JOB, COUNT(*) AS EMP_COUNT, SUM(SALARY) AS TOTAL_SALARY FROM EMPLOYEE GROUP BY CUBE(DEPARTMENT, JOB);DEPARTMENT JOB EMP_COUNT TOTAL_SALARY IT 개발자 3 15000000 IT DBA 2 12000000 IT NULL 5 27000000 영업 영업사원 4 16000000 영업 영업관리자 1 8000000 영업 NULL 5 24000000 NULL 개발자 3 15000000 NULL DBA 2 12000000 NULL 영업사원 4 16000000 NULL 영업관리자 1 8000000 NULL NULL 10 51000000
-
- GROUPING SETS ⭐️⭐️
-
특정 항목에 대한 소계를 계산하는 함수
-
인자값으로
ROULLUP이나CUBE를 사용할 수도 있음함수 결과 GROUPING SETS(A, B) · A로 그룹핑
· B로 그룹핑GROUPING SETS(A, B, ()) · A로 그룹핑
· B로 그룹핑
· 총합계GROUPING SETS(A, ROLLUP(B)) · A로 그룹핑
· B로 그룹핑
· 총합계GROUPING SETS(A, ROLLUP(B, C)) · A로 그룹핑
· B, C로 그룹핑
· B로 그룹핑
· 총합계GROUPING SETS(A, B, ROLLUP(C)) · A로 그룹핑
· B로 그룹핑
· C로 그룹핑
· 총합계 -
예시:
GROUP BY GROUPING SETS(DEPARTMENT, JOB, ());
- 부서별 집계 (DEPARTMENT)
- 직무별 집계 (JOB)
- 전체 집계 (())SELECT DEPARTMENT, JOB, COUNT(*) AS EMP_COUNT, SUM(SALARY) AS TOTAL_SALARY FROM EMPLOYEE GROUP BY GROUPING SETS(DEPARTMENT, JOB, ());DEPARTMENT JOB EMP_COUNT TOTAL_SALARY IT NULL 5 27000000 영업 NULL 5 24000000 NULL 개발자 3 15000000 NULL DBA 2 12000000 NULL 영업사원 4 16000000 NULL 영업관리자 1 8000000 NULL NULL 10 51000000
-
- GROUPING ⭐️
-
ROLLUP,CUBE,GROUPING SETS등과 함께 쓰이며 소계를 나타내는 행(ROW)을 구분할 수 있게 해줌- 0: 일반 그룹의 데이터 (원래 존재하는 값)
- 1: 생성된 총계 행
-
그룹핑 기준이 되는 컬럼을 제외하고는
NULL로 표현되었지만GROUPING함수를 이용하면 원하는 위치에 원하는 텍스트를 출력할 수 있음 -
예시:
SELECT CASE GROUPING(ORDER_DT) WHEN 1 THEN 'TOTAL' ELSE ORDER_DT END AS ORDER_DT, COUNT(*) FROM STARBUCKS_ORDER GROUP BY ROLLUP(ORDER_DT) ORDER BY ORDER_DT;ORDER_DT COUNT(*) 2024-03-01 150 2024-03-02 175 2024-03-03 200 TOTAL 525
-
5. 윈도우 함수
- 윈도우 함수 ⭐️⭐️
OVER키워드와 함께 사용됨
- 역할에 따른 분류 ⭐️⭐️
순위 함수 RANK, DENSE_RANK, ROW_NUMBER 집계 함수 SUM, MAX, MIN, AVG, COUNT 행 순서 함수 FIRST_VALUE, LAST_VALUE, LAG, LEAD 비율 함수 CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT - 순위 함수 ⭐️⭐️
RANK 1, 2, 2, 4, 5, 5, 7, … DENSE_RANK 1, 2, 2, 3, 4, 5, 5, 6, … ROW_NUMBER 1, 2, 3, 4, 5, 6, 7, … - RANK
- 순위를 매기면서 같은 순위가 존재하면 존재하는 수만큼 다음 순위를 건너 뜀
- 예시1
# EX1 SELECT ORDER_DT, COUNT(*), RANK() OVER(ORDER BY COUNT(*) DESC) AS RANK FROM STARBUCKS_ORDER GROUP BY ORDER_DTORDER_DT COUNT(*) RANK 2024-03-05 200 1 2024-03-02 150 2 2024-03-03 100 3 2024-03-04 100 3 2024-03-01 80 5 - 예시2
# EX2 SELECT NAME, DEPT_ID, SALARY, RANK() OVER(PARTITION BY DEPT_ID ORDER BY SALARY DESC) AS RANK FROM EMP;NAME DEPT_ID SALARY RANK 김철수 10 5000000 1 이영희 10 4500000 2 박민수 10 4000000 3 황지영 20 6000000 1 정대현 20 5500000 2 송미라 20 5500000 2 강동원 20 4800000 4
- DENSE_RANK
- 순위를 매기면서 같은 순위가 존재하더라도 다음 순위를 건너뛰지 않고 이어서 매김
- 예시
SELECT NAME, DEPT_ID, SALARY, DENSE_RANK() OVER(PARTITION BY DEPT_ID ORDER BY SALARY DESC) AS DENSE_RANK FROM EMP;NAME DEPT_ID SALARY RANK 김철수 10 5000000 1 이영희 10 4500000 2 박민수 10 4000000 3 황지영 20 6000000 1 정대현 20 5500000 2 송미라 20 5500000 2 강동원 20 4800000 3
- ROW_NUMBER
- 순위를 매기면서 동일한 값이라도 각기 다른 순위를 부여
- 예시
SELECT ORDER_DT, COUNT(*), ROW_NUMBER() OVER(PARTITION BY DEPT_ID ORDER BY SALARY DESC) AS ROW_NUMBER FROM EMP;NAME DEPT_ID SALARY RANK 김철수 10 5000000 1 이영희 10 4500000 2 박민수 10 4000000 3 황지영 20 6000000 1 정대현 20 5500000 2 송미라 20 5500000 3 강동원 20 4800000 4
- RANK
- 집계 함수 ⭐️⭐️
-
SUM
-
데이터의 합계를 구하는 함수
-
인자값으로는 숫자형만 올 수 있음
-
예시1:
# EX1 SELECT NAME, SUBJECT, SCORE, SUM(SCORE) OVER(PARTITION BY NAME) AS TOTAL_SCORE FROM SQLD; -
예시2: Oracle의 경우
OVER절 내에ORDER BY절을 써서 데이터의 누적값을 구할 수 있음.RANGE UNBOUNDED PRECENDING구문이 없어도 누적합 집계가 적용됨# EX2 SELECT NAME, SUBJECT, SCORE, SUM(SCORE) OVER(PARTITION BY NAME ORDER BY SUBJECT DESC RANGE UNBOUNDED PRECEDING) AS TOTAL_SCORE FROM SQLD;NAME SUBJECT SCORE TOTAL_SCORE 김철수 데이터 모델링의 이해 40 40 김철수 SQL 기본 및 활용 35 75 이영희 데이터 모델링의 이해 16 16 이영희 SQL 기본 및 활용 80 96
-
-
MAX
-
데이터의 최댓값을 구하는 함수
-
예시: 과목별 최대 점수를 받은 사람만 출력
SELECT NAME, SUBJECT, SCORE FROM (SELECT NAME, SUBJECT, SCORE, MAX(SCORE) OVER(PARTITION BY SUBJECT) AS MAX_SCORE FROM SQLD) WHERE SCORE = MAX_SCORE;
-
-
MIN
- 데이터의 최솟값 구하는 함수
- 예시: 과목별 최소 점수를 받은 사람만 출력
SELECT NAME, SUBJECT, SCORE FROM (SELECT NAME, SUBJECT, SCORE, MIN(SCORE) OVER(PARTITION BY SUBJECT) AS MIN_SCORE FROM SQLD) WHERE SCORE = MIN_SCORE;
-
AVG
- 데이터의 평균값을 구하는 함수- 예시: 과목별 평균 점수 이상을 받은 사람만 출력
SELECT NAME, SUBJECT, SCORE FROM (SELECT NAME, SUBJECT, SCORE, ROUND(AVG(SCORE) OVER(PARTITION BY SUBJECT)) AS AVG_SCORE FROM SQLD) WHERE SCORE >= AVG_SCORE;
💡 윈도우 함수 옵션 ⭐️
- 문법
범위 의미 UNBOUNDED PRECEDING 위쪽 끝 행 UNBOUNDED FOLLOWING 아래쪽 끝 행 CURRENT ROW 현재 행 n PRECEDING 현재 행에서 위로 n만큼 이동 n FOLLOWING 현재 행에서 아래로 n만큼 이동
기준 의미 ROWS 행 자체가 기준 RANGE 행이 가지고 있는 값이 기준 - WINDOWING 절을 이용하여 집계하려는 데이터의 범위를 지정할 수 있음
RANGE ROWS BETWEEN UNBOUNDED PRECEDING AND n PRECEDING BETWEEN UNBOUNDED AND CURRENT ROW BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING BETWEEN n PRECEDING AND n PRECEDING BETWEEN n PRECEDING AND CURRENT ROW BETWEEN n PRECEDING AND UNBOUNDED FOLLOWING BETWEEN CURRENT ROW AND n FOLLOWING BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING BETWEEN n FOLLOWING AND n FOLLOWING BETWEEN n FOLLOWING AND UNBOUNDED FOLLOWING UNBOUNDED PRECEDING
*default: RANGE UNBOUNDED PRECEDINGn PRECEDING CURRENT ROW - 예시: 과목별 평균 점수 이상을 받은 사람만 출력
-
COUNT
- 데이터 건수를 구하는 함수
- 예시1: 과목별로 본인보다 점수가 높거나 같은 건수 카운트
SELECT NAME, SUBJECT, SCORE, COUNT(*) OVER(PARTITION BY SUBJECT ORDER BY SCORE DESC RANGE UNBOUNDED PRECEDING) AS HIGHER_COUNT FROM SQLD; - 예시2: 과목별로 본인 점수와 5점 이하로 차이가 나거나 점수가 같은 건수 카운트
SELECT NAME, SUBJECT, SCORE, COUNT(*) OVER(PARTITION BY SUBJECT ORDER BY SCORE DESC RANGE BETWEEN 5 PRECEDING AND 5 FOLLOWING) AS SIMILAR_COUNT FROM SQLD;
-
- 행 순서 함수
- FIRST_VALUE
- 가장 선두에 위치한 데이터를 구하는 함수
(SQL Server에서는 지원하지 않음)
SELECT NAME, SUBJECT, SCORE, FIRST_VALUE(SCORE) OVER(ORDER BY SCORE) AS FIRST_VALUE FROM SQLD; - 가장 선두에 위치한 데이터를 구하는 함수
- LAST_VALUE
- 가장 끝에 위치한 데이터를 구하는 함수
(SQL Server에서는 지원하지 않음)
SELECT NAME, SUBJECT, SCORE, LAST_VALUE(SCORE) OVER(ORDER BY SCORE) AS LAST_VALUE FROM SQLD; - 가장 끝에 위치한 데이터를 구하는 함수
- LAG ⭐️
-
특정 수만큼 앞선 데이터를 구하는 함수
-
default: 1 (두 번째 인자값 생략할 때)
SELECT NAME, SUBJECT, SCORE, LAG(SCORE, 3) OVER(ORDER BY SCORE) AS LAG FROM SQLD;
-
- LEAD ⭐️
- 특정 수만큼 뒤에 있는 데이터를 구하는 함수
- default: 1 (두 번째 인자값 생략할 때)
SELECT NAME, SUBJECT, SCORE, LEAD(SCORE, 2) OVER(ORDER BY SCORE) AS LEAD FROM SQLD;
- FIRST_VALUE
- 비율 함수 ⭐️
- RATIO_TO_REPORT
- 파티션 별 합계에서 차지하는 비율을 구하는 함수
(SQL Server에서 지원 안함) - 0 ≤ x ≤ 1
- 예시: 과목별 점수 합계에서 차지하는 비율 구하기
SELECT NAME, SUBJECT, SCORE, SUM(SCORE) OVER(PARTITION BY SUBJECT) AS SUM, SCORE/SUM(SCORE) OVER(PARTITION BY SUBJECT) AS "SCORE/SUM", RATIO_TO_REPORT(SCORE) OVER(PARTITION BY SUBJECT) AS RATIO_TO_REPORT FROM SQLD;NAME SUBJECT SCORE SUM SCORE/SUM RATIO_TO_REPORT 김철수 데이터 모델링의 이해 40 56 0.714286 0.714286 이영희 데이터 모델링의 이해 16 56 0.285714 0.285714 김철수 SQL 기본 및 활용 35 115 0.304348 0.304348 이영희 SQL 기본 및 활용 80 115 0.695652 0.695652
- 파티션 별 합계에서 차지하는 비율을 구하는 함수
- PERCENT_RANK
- 해당 파티션의 맨 위 끝 행을 0, 맨 아래 끝 행을 1로 놓고 현재 행이 위치하는 백분위 순위 값을 구하는 함수
- 0 ≤ x ≤ 1
- 예시: 과목별로 나눈 파티션에서 해당 점수가 차지하는 백분위 순위 구하기
SELECT NAME, SUBJECT, SCORE, RANK() OVER(PARTITION BY SUBJECT ORDER BY SCORE) AS RANK, COUNT(*) OVER(PARTITION BY SUBJECT) AS COUNT, (RANK() OVER(PARTITION BY SUBJECT ORDER BY SCORE)-1)/ (COUNT(*) OVER(PARTITION BY SUBJECT)-1) AS "(RANK-1)/(COUNT-1)", PERCENT_RANK() OVER(PARTITION BY SUBJECT ORDER BY SCORE) AS PERCENT_RANK FROM SQLD;NAME SUBJECT SCORE RANK COUNT (RANK-1)/(COUNT-1) PERCENT_RANK 김철수 데이터 모델링의 이해 7 1 5 0 0 이영희 데이터 모델링의 이해 12 2 5 0.25 0.25 김지현 데이터 모델링의 이해 15 3 5 0.5 0.5 박형준 데이터 모델링의 이해 16 4 5 0.75 0.75 정상현 데이터 모델링의 이해 19 5 5 1 1 김철수 SQL 기본 및 활용 22 1 5 0 0 이영희 SQL 기본 및 활용 22 1 5 0 0 김지현 SQL 기본 및 활용 57 3 5 0.5 0.5 박형수 SQL 기본 및 활용 88 4 5 0.75 0.75 정상현 SQL 기본 및 활용 89 5 5 1 1
- CUME_DIST
- 해당 파티션에서의 누적 백분율을 구하는 함수 (SQL Server에서 지원 안함)
- 0 < x ≤ 1
- 예시: 점수 누적 백분율 구하기
SELECT NAME, SUBJECT, SCORE, COUNT(*) OVER(ORDER BY SCORE) AS COUNT, COUNT(*) OVER() AS TOTAL_COUNT, COUNT(*) OVER(ORDER BY SCORE)/COUNT(*) OVER() AS "COUNT/TOTAL_COUNT", CUME_DIST() OVER(ORDER BY SCORE) AS CUME_DIST FROM SQLD;NAME SUBJECT SCORE COUNT TOTAL_COUNT COUNT/TOTAL_COUNT CUME_DIST 김철수 데이터 모델링의 이해 7 1 10 0.1 0.1 이영희 데이터 모델링의 이해 12 2 10 0.2 0.2 김지현 데이터 모델링의 이해 15 3 10 0.3 0.3 박형준 데이터 모델링의 이해 16 4 10 0.4 0.4 정상현 데이터 모델링의 이해 19 5 10 0.5 0.5 김철수 SQL 기본 및 활용 22 7 10 0.7 0.7 이영희 SQL 기본 및 활용 22 7 10 0.7 0.7 김지현 SQL 기본 및 활용 57 8 10 0.8 0.8 박형수 SQL 기본 및 활용 88 9 10 0.9 0.9 정상현 SQL 기본 및 활용 89 10 10 1.0 1.0
- NTILE
- 주어진 수만큼 행들을 n등분한 후 현재 행에 해당하는 등급을 구하는 함수
- 예시: 성적 NTILE 구하기
﹡할당 행이 남아있을 경우 맨 앞의 그룹부터 하나씩 더 채워짐SELECT NAME, SUBJECT, SCORE, NTILE(1) OVER(ORDER BY SCORE DESC) AS NTILE1, NTILE(3) OVER(ORDER BY SCORE DESC) AS NTILE3, NTILE(5) OVER(ORDER BY SCORE DESC) AS NTILE5 FROM SQLD;NAME SUBJECT SCORE NTILE1 NTILE3 NTILE5 정상현 SQL 기본 및 활용 89 1 1 1 박형수 SQL 기본 및 활용 88 1 1 1 김지현 SQL 기본 및 활용 57 1 1 2 이영희 SQL 기본 및 활용 22 1 2 3 김철수 SQL 기본 및 활용 22 1 2 3 정상현 데이터 모델링의 이해 19 1 2 4 박형준 데이터 모델링의 이해 16 1 2 4 김지현 데이터 모델링의 이해 15 1 3 4 이영희 데이터 모델링의 이해 12 1 3 5 김철수 데이터 모델링의 이해 7 1 3 5
- RATIO_TO_REPORT
6. Top-N 쿼리
- Top-N
- N위까지 추출
- N위까지 추출
- ROWNUM ⭐️
-
수도 컬럼(Pseudo Column)
-
자동으로 번호 매기는 컬럼
﹡ROWNUM은 ORDER BY 절 이전에 부여되므로, 정렬 후 순서와 ROWNUM이 일치하지 않을 수 있음SELECT ROWNUM, NAME, SUB1, SUB2 FROM EXAM_SCOREEMPNO NAME SUB1 SUB2 ROWNUM 1001 김철수 85 90 1 1002 이영희 92 88 2 1003 박지민 78 85 3 1004 최수진 95 93 4 1005 정민준 88 87 5 -- 상위 3명 학생 조회 (잘못된 방법) SELECT ROWNUM, NAME, SUB1, SUB2 FROM EXAM_SCORE WHERE ROWNUM <= 3 ORDER BY (SUB1 + SUB2) DESC;-- 상위 3명 학생 조회 (올바른 방법) SELECT * FROM ( SELECT NAME, SUB1, SUB2 FROM EXAM_SCORE ORDER BY (SUB1 + SUB2) DESC ) WHERE ROWNUM <= 3;
-
- ROW_NUMBER ⭐️
-
윈도우 함수의 순위 함수를 이용한 Top-N 쿼리 작성
SELECT * FROM ( SELECT ROW_NUMBER() OVER(ORDER BY SUB1 DESC, SUB2 DESC) AS RNUM, NAME, SUB1, SUB2 FROM EXAM_SCORE) WHERE RNUM <= 5;RNUM NAME SUB1 SUB2 1 최수진 95 93 2 이영희 92 88 3 정민준 88 87 4 김철수 85 90 5 박지민 78 85
-
7. 셀프 조인(Self Join)
- 셀프 조인
-
자신과 조인
-
FROM 절에 같은 테이블이 두 번 이상 등장
-
별칭(ALIAS)을 표기해줘야 함
SELECT A.TYPE, A.NAME, B.TYPE, B.NAME FROM CATEGORY A, CATEGORY B WHERE A.NAME = B.PARENT AND A.TYPE = '대';TYPE NAME PARENT 대 전자제품 NULL 중 컴퓨터 전자제품 중 모바일 전자제품 소 노트북 컴퓨터 소 데스크톱 컴퓨터 소 스마트폰 모바일 소 태블릿 모바일 ↓ 쿼리 실행 결과
A.TYPE A.NAME B.TYPE B.NAME 대 전자제품 중 컴퓨터 대 전자제품 중 모바일
-
8. 계층 쿼리
- 계층 쿼리 ⭐️⭐️
-
테이블에 계층 구조를 이루는 컬럼이 존재할 경우 계층 쿼리를 이용해서 데이터를 출력할 수 있음
-
셀프 조인할 때 depth가 깊어질수록 셀프 조인이 반복되는데, 이것을 계층 쿼리를 이용하면 좀 더 간단하게 쿼리를 작성할 수 있음
SELECT LEVEL, TYPE, NAME, PARENT, SYS_CONNECT_BY_PATH(NAME, '/') AS PATH FROM CATEGORY START WITH PARENT IS NULL CONNECT BY PRIOR NAME = PARENT ORDER SIBLINGS BY NAME;LEVEL TYPE NAME PARENT PATH 1 대 전자제품 NULL /전자제품 2 중 모바일 전자제품 /전자제품/모바일 2 중 컴퓨터 전자제품 /전자제품/컴퓨터 3 소 데스크톱 컴퓨터 /전자제품/컴퓨터/데스크톱 3 소 노트북 컴퓨터 /전자제품/컴퓨터/노트북 3 소 스마트폰 모바일 /전자제품/모바일/스마트폰 3 소 태블릿 모바일 /전자제품/모바일/태블릿
-
💡 구문, 컬럼 설명 ⭐️⭐️
LEVEL
현재의 depth 반환. 루트 노드는 1SYS_CONNECT_BY_PATH(컬럼, 구분자)
루트 노드부터 현재 노드까지의 경로 출력 함수START WITH
경로가 시작되는 루트 노드 생성 절CONNECT BY
루트로부터 자식 노드 생성 절. 조건에 만족하는 데이터가 없을때까지 노드 생성PRIOR
바로 앞에 있는 부모 노드 값 반환ORDER SIBLINGS BY
같은 레벨끼리 정렬CONNECT_BY_ROOT
루트 노드의 주어진 컬럼 값 반환CONNECT_BY_ISLEAF
가장 하위 노드인 경우 1 반환, 그 외에는 0 반환
9. 참고
- 정규표현식 ⭐️
-
패턴
패턴 의미 예시 (매칭되는 값) ^ 문자열의 시작 ^A → “Apple”, “A123” $ 문자열의 끝 Z$ → “XYZ”, “123Z” . 임의의 한 문자 A.B → “ACB”, “A1B” * 0개 이상 반복 A*B → “B”, “AB”, “AAAB” + 1개 이상 반복 A+B → “AB”, “AAAB” (단, “B”는 매칭X) ? 0개 또는 1개 존재 A?B → “B”, “AB” [] 문자 집합 [abc] → “a”, “b”, “c” [^] 문자 제외 [^0-9] → 숫자가 아닌 문자 {n,m} n~m개 반복 A{2,4} → “AA”, “AAA”, “AAAA” -
함수(오라클)
함수 역할 문법 예시 REGEXP_LIKE 문자열이 특정 정규식 패턴과 일치하는지 여부 반환(TRUE/FALSE) REGEXP_LIKE(컬럼명, '정규식') WHERE REGEXP_LIKE(name, '^A'); REGEXP_INSTR 문자열에서 특정 패턴이 처음 등장하는 위치 반환 REGEXP_INSTR(문자열, '정규식', 시작위치, N번째출현, 0 또는 1, 매칭모드) REGEXP_INSTR('xyz abc def abc', 'abc'); → 5 REGEXP_SUBSTR 정규식에 매칭되는 부분 문자열 추출 REGEXP_SUBSTR(문자열, '정규식', 시작위치, N번째출현, 매칭모드) REGEXP_SUBSTR('User123 Hello456', '[0-9]+', 1, 2) → ‘456’ REGEXP_REPLACE 정규식을 이용해 문자열을 찾아 다른 문자열로 변경 REGEXP_REPLACE(문자열, '정규식', '대체문자열', N번째출현, 매칭모드) REGEXP_REPLACE('User123 Hello456', '[0-9]+', 'X', 1, 1) → ‘UserX Hello456’
-
- 순수관계연산자
- σ(selection), π(projection), ÷(division), ⨝(join)
집합 연산 이미지 출처: Interesting Read — SQL Set Operators — Union, Union ALL, Intersect & Minus/Except
