
Part2. SQL 기본 및 활용
CHATER 1. SQL 기본
1. 관계형 데이터베이스
- 데이터베이스
데이터를 저장하는 공간
- 관계형 데이터베이스(RDB, Relational Database)
관계형 데이터 모델에 기초를 둔 데이터베이스- RDBMS(Relational Database System)
RDB를 관리, 감독하기 위한 시스템
Ex) Oracle, SQL Server(MSSQL), MySQL, MariaDB, PostgreSQL
- RDBMS(Relational Database System)
- TABLE
- 관계형 데이터베이스의 기본 단위
- 관계형 데이터베이스는 모든 데이터를 2차원 테이블 형태로 표현
- 데이터베이스는 여러 개의 테이블로 구성됨
- 컬럼(Column): 세로 열
- 로우(Row): 가로 행
- SQL(Structured Query Language)
관계형 데이터베이스에서 데이터를 다루기 위해 사용하는 언어
2. SELECT문
- SELECT ⭐️⭐️
저장되어 있는 데이터를 조회하고자 할 때 사용하는 명령어SELECT COL1, COL2, ... FROM TABLE1 WHERE COL1 = 'A';SELECT * FROM TABLE1;- 테이블명이나 컬럼명에 별칭(Alias)을 붙여서 짧게 줄여 쓸 수 있음
- 테이블명에 별칭을 설정했을 경우, 테이블명 대신 별칭을 사용해야 함
- 별칭이 없으면, 컬럼명 대문자로 표시
SELECT M.NAME AS MEMBER_NAME, O.COST FROM MEMBER M, ORDER O WHERE M.ID = O.MEMBER_ID;
- 테이블명이나 컬럼명에 별칭(Alias)을 붙여서 짧게 줄여 쓸 수 있음
- 산술 연산자 ⭐️⭐️
사칙연산의 기능을 가진 연산자
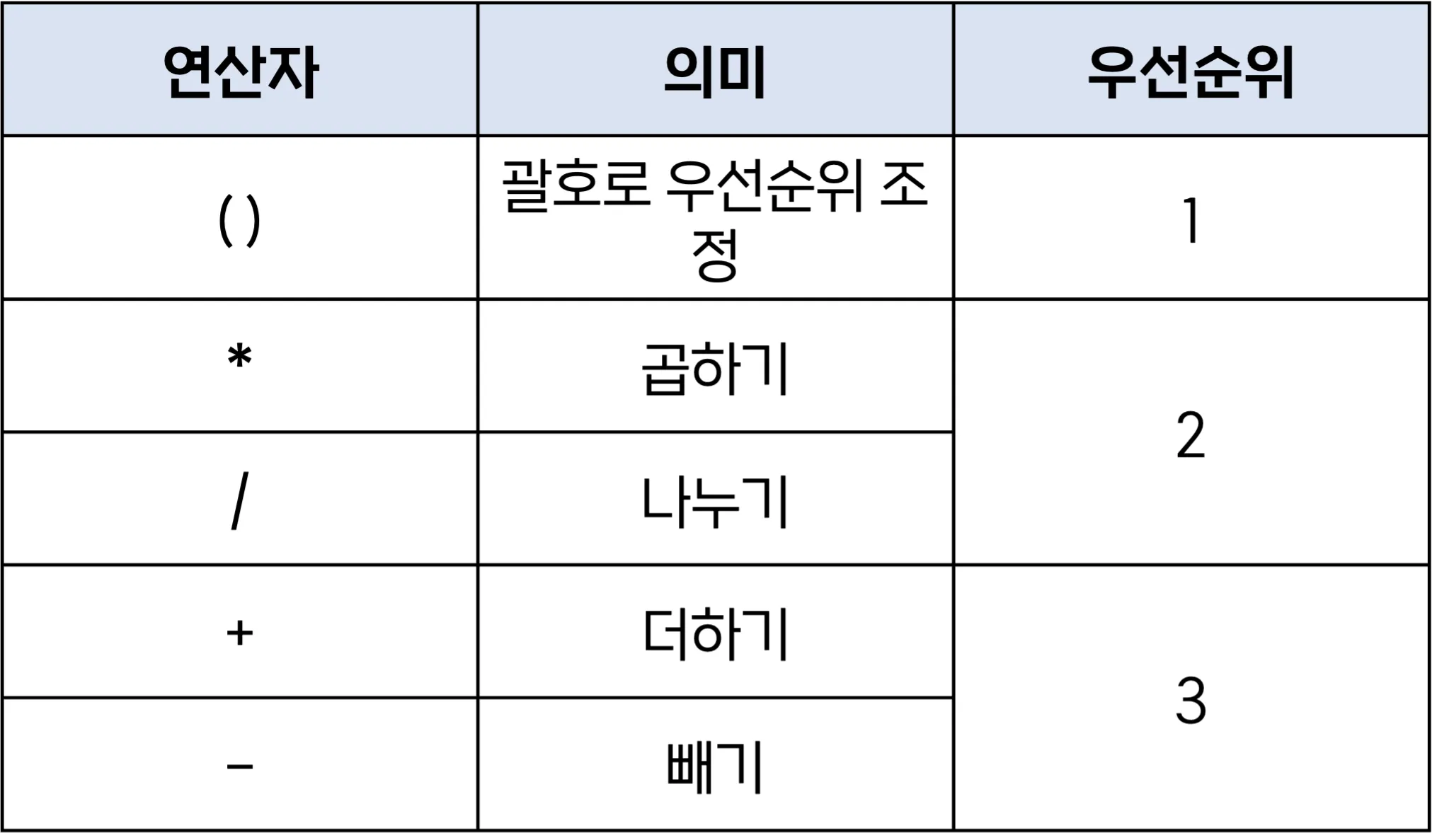
- 합성 연산자
문자와 문자를 연결할 때 사용하는 연산자||SELECT 'S' || 'Q' || 'L' || '!' AS SQLD FROM T1;
3. 함수
- 문자 함수 ⭐️⭐️
CHR(ASCII 코드)- ASCII 코드는 총 128개의 문자를 숫자로 표현할 수 있도록 정의해 놓은 코드이다. CHR 함수는 ASCII 코드를 인수로 입력했을 때 매핑되는 문자가 무엇인지를 알려주는 함수
- CHR(65) → A
SELECT CHR(65) FROM T1;
LOWER(문자열)- 문자열을 소문자로 변환해주는 함수
- LOWER(’ROSE’) → rose
SELECT LOWER('ROSE') FROM T1;
UPPER(문자열)- 문자열을 대문자로 변환해주는 함수
- UPPER(’rose’) → ROSE
SELECT UPPER('rose') FROM T1;
LTRIM(문자열 [, 특정 문자)])* []는 옵션- 특정 문자를 따로 명시해주지 않으면 문자열의 왼쪽 공백 제거
- 특정 문자를 명시해주면 문자열을 왼쪽부터 한 글자씩 특정 문자와 비교하여 특정 문자에 포함되어 있으면 제거하고 포함되지 않았으면 멈춤
- LTRIM(’ ROSE’) → ROSE
SELECT LTRIM(' ROSE') FROM T1; - LTRIM(’DEVELOPER’, ‘DE) → VELOPER
RTRIM(문자열 [, 특정 문자])*[] 옵션- 특정 문자를 따로 명시해주지 않으면 문자열의 오른쪽 공백 제거
- 특정 문자를 명시해주면 문자열을 오른쪽부터 한 글자씩 특정 문자와 비교하여 특정 문자에 포함되어 있으면 제거하고 포함되지 않았으면 멈춤
- RTRIM(’ROSE ‘) → ROSE
SELECT RTRIM('ROSE ') FROM T1; - RTRIM(’SQL’, ‘LE’) → SQ
TRIM([위치] [특정 문자] [FROM] 문자열)*[] 옵션- 옵션이 하나도 없을 경우 문자열의 왼쪽과 오른쪽 공백 제거
- 옵션이 있을 경우 문자열을 위치(
LEADINGorTRAILINGorBOTH)로 지정된 곳부터 한 글자씩 특정 문자와 비교하여 같으면 제거하고 같지 않으면 멈춤 - 특정 문자는 한 글자만 지정할 수 있음
- TRIM(’ ROSE ’) → ROSE
SELECT TRIM(' ROSE ') FROM T1; - TRIM(LEADING ‘블’ FROM ‘블랭핑크’) → 랙핑크
SELECT TRIM(LEADING '블' FROM '블랭핑크') FROM T1;
SUBSTR(문자열, 시작점 [, 길이])*[] 옵션- 문자열의 원하는 부분만 잘라서 반환해주는 함수, 1-based
- 길이를 명시하지 않을 경우 문자열의 시작점부터 문자열의 끝까지 반환
- SUBSTR(’블랭핑크로제’, 3, 2) → 핑크
SELECT SUBSTR('블랭핑크로제', 3, 2) FROM T1;
LENGTH(문자열)- 문자열의 길이 반환
- LENGTH(’ROSE’) → 4
SELECT LENGTH('ROSE') FROM T1;
REPLACE(문자열, 변경 전 문자열 [, 변경 후 문자열])*[] 옵션- 문자열에서 변경 전 문자열을 찾아 변경 후 문자열로 바꿔주는 함수
- 변경 후 문자열을 명시해주지 않으면 문자열에서 변경 전 문자열 제거
- REPLACE(’블랭핑크로제’, ‘로제’, ‘제니’) → 블랭핑크제니
SELECT REPLACE('블랭핑크로제', '로제', '제니') FROM T1;
- 숫자 함수 ⭐️⭐️
ABS(수)- 수의 절댓값 반환
SIGN(수)- 수의 부호 반환
- 양수 → 1, 음수 → -1, 0 → 0
ROUND(수 [, 자릿수])*[] 옵션- 수를 지정된 자릿수까지 반올림하여 반환
- 기본값 0
- ROUND(123.45, -2) → 100
TRUNC(수, [, 자릿수])*[] 옵션- 수를 지정된 소수점 자릿수까지 버림하여 반환
- 기본값 0
CEIL(수)- 소수점 이하의 수를 올림한 정수 반환
FLOOR(수)- 소수점 이하의 수를 버림한 정수 반환
MOD(수1, 수2)- 수1을 수2로 나눈 나머지 반환
- 수2가 0이면 수1 반환
- 수1, 수2 모두 음수이면 음수로 반환
- 날짜 함수 ⭐️
SYSDATE- 현재의 연, 월, 일, 시, 분, 초를 반환
- SYSDATE → 2025-03-08 09:00:00
SELECT SYSDATE FROM T1;
EXTRACT(특정 단위 FROM 날짜 데이터)- 날짜 데이터에서 특정 단위만 출력해서 반환
- 단위: YEAR, MONTH, DAY, HOUR, MINUTE, SECOND
- EXTRACT(YEAR FROM SYSDATE) → 2025
SELECT EXTRACT(YEAR FROM SYSDATE) AS YEAR FROM T1;
ADD_MONTHS(날짜 데이터, 특정 개월 수)- 날짜 데이터에서 특정 개월 수를 더한 날짜 반환
- ADD_MONTHS(TO_DATE('2024-12-31', 'YYYY-MM-DD'), -1) → 2024-11-30
SELECT ADD_MONTHS(TO_DATE('2024-12-31', 'YYYY-MM-DD'), -1) AS PREV_MONTH FROM T1;
- 변환 함수 ⭐️
데이터베이스에서 데이터 유형에 대한 형변환을 할 수 있는 방법은 2가지가 있다.- 명시적 형변환
- 변환 함수를 사용하여 데이터 유형 변환을 명시적으로 나타냄
- 암시적 형변환
- 데이터베이스가 내부적으로 알아서 데이터 유형을 변환함
- 조건절에서
BIRTHDAY(VARCHAR)를 숫자와 비교할 경우, 데이터베이스는BIRTHDAY를 NUMBER형으로 변환하게 됨 - 암시적 형변환이 가능하다고 컬럼의 데이터 유형을 고려하지 않고 쿼리를 작성하게 되면 성능 저하를 불러올 수도 있고, 에러가 생기는 경우도 있기 때문에 되도록 명시적 형변환을 사용하는 게 좋음
TO_NUMBER(문자열)- 문자열을 숫자형으로 변환
- TO_NUMBER(’1234’) → 1234
TO_CHAR(수 or 날짜 [, 포맷])*[] 옵션- 수나 날짜형의 데이터를 포맷 형식의 문자형으로 변환
- TO_CHAR(1234) → ‘1234’
- TO_CHAR(SYSDATE, ‘YYYYMMDD HH24MISS’)
TO_DATE(문자열, 포맷)-
포맷 형식의 문자형의 데이터를 날짜형으로 변환
포맷 표현 의미 YYYY 년 MM 월 DD 일 HH 시(12) HH24 시(24) MI 분 SS 초
-
- 명시적 형변환
💡 ORACLE 날짜 계산
오라클에서 날짜 계산은 숫자 계산과 같다. 특정 날짜에 숫자 1을 더하면 하루를 더한 것과 같아진다.
1: 1일1/24: 1시간1/24/60: 1분1/24/(60/10): 10분
- NULL 관련 함수 ⭐️⭐️
- ORACLE 함수
NVL(인수1, 인수2)
인수 1의 값이 NULL일 경우 인수2 반환, NULL이 아닐 경우 인수1 반환NULLIF(인수1, 인수2)
인수1과 인수2가 같으면 NULL 반환, 같지 않으면 인수1 반환
- SQL Server 함수
COALESCE(인수1, 인수2, 인수3, ...)- NULL이 아닌 최초의 인수 반환
ISNULL(인수1, 인수2)- 인수1이 NULL이면 인수2 반환, NULL이 아니면 인수1 반환
- 인수1이 NULL이면 인수2 반환, NULL이 아니면 인수1 반환
- ORACLE 함수
- CASE, DECODE ⭐️⭐️
- ‘~이면 ~이고, ~이면 ~이다’ 식으로 표현되는 구문
- CASE WHEN 절에 컬럼명을 별칭으로 사용할 수 없음
# EX1 CASE WHEN LINE = 1 THEN 'NAVY' WHEN LINE = 2 THEN 'GREEN' WHEN LINE = 3 THEN 'ORANGE' [ELSE 'WHITE'] END # EX2 CASE LINE WHEN 1 THEN 'NAVY' WHEN 2 THEN 'GREEN' WHEN 3 THEN 'ORANGE' [ELSE 'WHITE'] END # EX3(ORACLE) DECODE (LINE, 1, 'NAVY', 2, 'GREEN', 3, 'ORANGE' [, 'WHITE'])
4. WHERE 절
-
WHERE 절 ⭐️⭐️
INSERT를 제외한 DML문을 수행할 때 원하는 데이터만 골라 수행할 수 있도록 해주는 구문SELECT COL1, COL2, ... FROM TABLE_NAME WHERE CONDITION;
-
비교 연산자 ⭐️
연산자 의미 예시 = 같음 WHERE COL = 5 < 작음 WHERE COL < 5 ≥ 작거나 같음 WHERE COL <= 5 > 큼 WHERE COL > 5 ≥ 크거나 같음 WHERE COL >= 5
-
부정 비교 연산자 ⭐️⭐️
연산자 의미 예시 != 같지 않음 WHERE COL != 5 ^= 같지 않음 WHERE COL ^= 5 <> 같지 않음 WHERE COL <> 5 NOT 컬럼명 = 같지 않음 WHERE NOT COL = 5 NOT 컬럼명 > 크지 않음 WHERE NOT COL > 5
-
SQL 연산자 ⭐️⭐️
연산자 의미 예시 BETWEEN A AND B A와 B 사이 (A, B 포함) WHERE COL BETWEEN 100 AND 200 LIKE 비교 문자열 포함 WHERE COL LIKE ‘APPL%’
WHERE COL LIKE ‘%PPLE’
WHERE COL LIKE ‘%PPL%’
WHERE COL LIKE ‘A__L%’IN (LIST) LIST 중 하나와 일치 WHERE COL IN (10, 20, 30)
WHERE (COL1, COL2) IN ((10,20))IS NULL NULL 값 WHERE COL IS NULL ESCAPE
_혹은%가 포함된 문자를 검색하고자 할 때,ESCAPE를 지정해서 쿼리를 작성할 수 있다. EX#%, `#`SELECT * FROM SAMPLE WHERE COL1 LIKE '%#%%' ESCAPE '#';
-
부정 SQL 연산자 ⭐️⭐️
연산자 의미 예시 NOT BETWEEN A AND B A와 B 사이가 아님 (A, B 미포함) WHERE COL NOT BETWEEN 100 AND 200 NOT IN (LIST) LIST 중 일치하는 것 없음 WHERE COL NOT IN (10, 20, 30) IS NOT NULL NULL 값 아님 WHERE COL IS NOT NULL
💡 드모르간 법칙
NOT (A AND B) ≡ (NOT A) OR (NOT B)
NOT (A OR B) ≡ (NOT A) AND (NOT B)
- 논리 연산자 ⭐️⭐️
연산자 의미 AND 모든 조건이 TRUE여야 함 OR 하나 이상의 조건이 TRUE여야 함 NOT TRUE → FALSE, FALSE → TRUE - 우선 순위: ( ) → NOT → AND → OR
5. GROUP BY, HAVING 절
- GROUP BY ⭐️⭐️
데이터를 그룹별로 묶을 수 있도록 해주는 절- NULL도 집계에 포함
- NULL도 집계에 포함
- 집계 함수 ⭐️⭐️
데이터를 그룹별로 나누면 그룹별로 집계 데이터를 도출하는 것이 가능해짐COUNT(*) 전체 행 개수를 반환 COUNT(COL) 컬럼값이 NULL인 행을 제외한 개수 반환 COUNT(DISTINCT COL) 컬럼값이 NULL이 아닌 행에서 중복을 제외한 개수 반환 SUM(COL) 컬럼값들의 합계 반환 AVG(COL) 컬럼값들의 평균 반환 MIN(COL) 컬럼값들의 최솟값 반환 MAX(COL) 컬럼값들의 최댓값 반환 STDDEV(COL) 컬럼값들의 표준 편차 반환 VARIAN(COL) 컬럼값들의 분산 반환 - HAVING ⭐️⭐️
GROUP BY 절을 사용할 때 WHERE 절처럼 사용하는 조건절- WHERE 절을 사용해도 되는 조건까지 HAVING 절로 써버리면 성능상 불리할 수도 있다. 왜냐하면 WHERE 절에서 필터링이 선행되어야 GROUP BY 할 데이터량이 줄어들기 때문이다.
💡 WHERE vs. HAVING ⭐️
WHERE
조회되는 데이터에 대한 조건 설정
HAVING
그룹화된 데이터에 대한 조건 설정
💡 SELECT 문의 논리적 수행 순서 ⭐️⭐️
1. FROM
2. WHERE
3. GROUP BY
4. HAVING
5. SELECT
6. ORDER BY
💡 DISTINCT 뒤에 컬럼이 여러 개 오는 경우?
- 주어진 컬럼값이 모두 동일한 행들로만 중복으로 처리
SELECT DISTINCT NAME, AGE FROM MEMBER;- 애초에 여러 컬럼이 SELECT 절에 올 때, 하나의 컬럼에만 DISTINCT를 적용할 수 없다. 하나의 컬럼에만 적용하고 싶으면
GROUP BY를 이용해야 한다.
SELECT NAME, MIN(AGE) FROM users GROUP BY NAME;
6. ORDER BY 절
- ORDER BY ⭐️⭐️
SELECT한 데이터를 정렬할 수 있음- ASC: 오름차순(Ascending), 기본값
- DESC: 내림차순(Descending)
- NULL 데이터
- Oracle의 경우 NULL을 최댓값으로 취급, SQL Server의 겨우 최솟값으로 취급
NULLS FIRST,NULLS LAST옵션으로 NULL의 정렬상 순서 변경 가능
ex)ORDER BY AGE ASC NULLS FIRST
SELECT문에서 컬럼명을 별칭으로 변경해도 ORDER BY에서는 원본 컬럼을 참조할 수 있어서 무엇으로 사용하든 상관 없음
7. JOIN
- JOIN ⭐️
각기 다른 테이블을 한 번에 보여줄 때 쓰는 쿼리
- EQUI JOIN
- equal(=) 조건으로 JOIN하는 것
SELECT P.PRODUCT_CODE, P.NAME, R.ID, R.CONTENT FROM PRODUCT P, REVIEW R WHERE A.PRODUCT_CODE = R.PRODUCT_CODE - Non EQUI JOIN
- equal(=) 조건이 아닌 다른 조건(BETWEEN, >, >=, <, <=)으로 JOIN하는 것
SELECT P.NAME, R.CONTENT, R.REGDATE FROM PRODUCT P, REIEW R WHERE R.REGDATE BETWEEN P.START_DATE AND P.END_DATE - 3개 이상 JOIN
- OUTER JOIN
JOIN 조건에 만족하지 않는 행들도 출력되는 형태- LEFT OUTER JOIN: JOIN에 성공한 데이터와 성공하지 못한 나머지 LEFT TABLE 데이터 추출
- RIGHT OUTER JOIN: JOIN에 성공한 데이터와 성공하지 못한 나머지 RIGHT TABLE 데이터 추출
- Oracle에서는 테이블 옆에 (+) 기호 붙여주면 됨
- LEFT OUTER JOIN:
WHERE P.CODE = R.CODE(+)
- LEFT OUTER JOIN:
8. STANDARD JOIN
-
표준 조인
RDBMS를 벤더별로 구분하면 Oracle, MySQL, MariaDB 등이 있다.
벤더마다 SQL 문법에 차이가 크면 호환성 이슈가 발생하고, SQL을 사용하는 사람들 입장에서도 효율성이 떨어지기 때문에 표준이 되는 ANSI SQL을 지정하게 되었다. STANDARD JOIN은 ANSI SQL 중 하나이다.
-
INNER JOIN ⭐️⭐️
JOIN 조건에 충족하는 데이터만 출력되는 방식
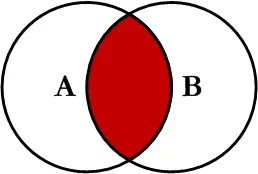
SELECT P.CODE, P.NAME, R.MEMBER_ID, R.CONTENT FROM PRODUCT A INNER JOIN REVIEW R ON P.CODE = R.CODE;
-
LEFT OUTER JOIN ⭐️⭐️
SQL에서 왼쪽에 표기된 테이블의 데이터는 무조건 출력되는 JOIN
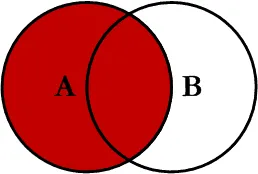
- 테이블에 JOIN되는 데이터가 없는 행들은 오른쪽 테이블 컬럼의 값이 NULL로 출력됨
SELECT P.CODE, P.NAME, R.MEMBER_ID, R.CONTENT FROM PRODUCT P LEFT OUTER JOIN REVIEW R ON P.CODE = R.CODE;
-
RIGHT OUTER JOIN ⭐️⭐️
SQL에서 오른쪽에 표기된 테이블의 데이터는 무조건 출력되는 JOIN
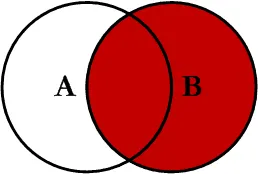
- 왼쪽 테이블에 JOIN되는 데이터가 없는 행들은 왼쪽 테이블 컬럼의 값이 NULL로 출력됨
SELECT R.MEMBER_ID, R.CONTENT, P.CODE, P.NAME FROM REVIEW R RIGHT OUTER JOIN PRODUCT P ON R.CODE = P.CODE;
-
FULL OUTER JOIN ⭐️⭐️
왼쪽, 오른쪽 테이블의 데이터가 모두 출력되는 방식
- LEFT OUTER JOIN과 RIGHT OUTER JOIN의 합집합 (중복값은 제거)
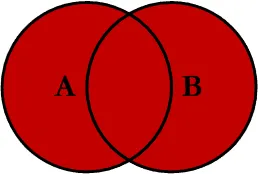
SELECT R.CAST AS R_CAST, I.CAST AS I_CAST FROM RUNNING_MAN R FULL OUTER JOIN INFINITE_CHALLENGE I ON R.CAST = I.CAST;
-
NATURAL JOIN ⭐️⭐️
A와 B 테이블에서 같은 이름을 가진 컬럼들이 모두 동일한 데이터를 가지고 있을 경우 JOIN되는 방식- ON 사용할 수 없음
- 공통 컬럼 앞에 OWNER 명(테이블명)을 붙이면 에러 발생
SELECT * FROM RUNNING_MAN R NATURAL JOIN INFINITE_CHALLENGE I;
-
CROSS JOIN(Cartesian Product) ⭐️⭐️
A와 B 테이블 사이에 조합할 수 있는 모든 경우를 출력하는 방식- 별도의 JOIN 조건이 없는 경우
# EX1 SELECT M.NAME, M.JOB, D.CODE, D.NAME FROM MEMBER M CROSS JOIN DRINK D; # EX2 SELECT M.NAME, M.JOB, D.CODE, D.NAME FROM MEMBER M, DRINK D;
💡 USING ⭐️
- USING 조건절을 이용하여 같은 이름을 가진 컬럼 중 원하는 컬럼만 JOIN에 이용할 수 있음
- SELECT 절에서 USING 절로 정의된 컬럼 앞에는 별도의 별칭(alias)나 테이블명을 붙이지 않아야 함
- EX) USING (NAME, GENDER)
Standard Join 이미지 출처: Visual Representation of SQL Joins
