
PART 1. 데이터 모델링의 이해
CHAPTER 2. 데이터 모델과 SQL
1. 정규화(Normalization)
- 정규화 ⭐️⭐️
데이터 정합성을 위해 엔티티를 작은 단위로 분리하는 과정
﹡데이터 정합성: 데이터의 정확성과 일관성을 유지하고 보장- 논리 데이터 모델의 일관성 확보
- 데이터에 대한 중복성 제거
- 정규화 할수록 엔티티 증가
→ JOIN으로 인한 조회 성능 저하 발생 가능 - 데이터 입력, 수정, 삭제 성능 향상
- 정규화 규칙 ⭐️⭐️
- 제1정규형(1NF)
모든 속성은 반드시 하나의 값만 가져야 한다. (도메인)
릴레이션에 속하는 속성의 속성값이 모두 원자값으로 구성되어야 한다.💡 다중값을 가지는 경우?
- 데이터를 꺼내 쓸 때, 불필요한 split을 사용해야 하는 번거로움이 생길 수 있다.
- 모든 인스턴스가 추가된 속성의 개수만큼 속성값을 가지고 있지 않을 수 있기 때문에 공간의 낭비가 발생할 수 있다.
-
ex1) 회원 테이블 → 회원, 직업 테이블
회원(회원id, 이름, 생년월일, 직업)
회원id(PK) 이름 생년월일 직업 1 홍길동 20030303 가수, 배우, 작곡가 … ... … … 회원(회원번호, 이름, 생년월일)
회원id(PK) 이름 생년월일 1 홍길동 20030303 … … … 회원직업정보(회원직업정보id, 회원id, 회원번호 직업)
회원직업id(PK) 회원id(PK) 직업 1 1 가수 2 1 배우 3 1 작곡가 -
ex2) 회원 테이블 → 회원, 사이트 테이블
회원(회원id, 이름, 생년월일, 사이트1, 사이트2, 사이트3)
회원id(PK) 이름 생년월일 사이트1 사이트2 사이트3 1 홍길동 20030303 인스타그램 구글 유튜브 2 김철수 20051010 인스타그램 네이버 NULL 회원(회원id, 이름, 생년월일)
회원id(PK) 이름 생년월일 1 홍길동 20030303 2 김철수 20051010 회원사이트정보(회원사이트정보id, 회원id사이트)
회원사이트정보id(PK) 회원id(FK) 사이트 1 1 인스타그램 2 1 구글 3 1 유튜브 4 2 인스타그램 5 2 네이버
- 제2정규형(2NF)
엔티티의 모든 일반속성은 반드시 모든 주식별자에 종속되어야 한다. (완전함수종속)💡 주식별자가 복합식별자인 경우?
- 일반속성이 주식별자의 일부에만 종속될 수 있다.
-
ex) 일반속성
음료명이 주식별자 중음료코드에만 종속주문(주문번호, 음료코드, 음료명, 주문수량, 음료명)
주문번호(PK) 음료코드(PK) 주문수량 음료명 20250225001 A1001 2 아메리카노 20250225002 A1002 1 아이스티 20250225003 A1002 1 아이스티 주문(주문번호, 음료코드, 주문수량)
주문번호(PK) 음료코드(FK) 주문수량 20250225001 A1001 2 20250225002 A1002 1 20250225003 A1002 1 음료(음료코드, 음료명)
음료코드(PK) 음료명 A1001 아메리카노 A1002 아이스티
- 제3정규형(3NF)
주식별자가 아닌 모든 속성 간에는 서로 종속될 수 없다. (이행종속)-
ex) 일반속성인
소속사명이 다른 일반속성인소속사코드에 종속참가자(참가번호, 이름, 생년월일, 소속사코드, 소속사명)
참가번호(PK) 이름 생년월일 소속사코드 소속사명 1 홍길동 20090305 A001 AC엔터테인먼트 2 김철수 20101020 B001 BD엔터테인먼트 3 최영희 20090703 B001 BD엔터테인먼트 참가자(참가번호, 이름, 생년월일, 소속사코드)
참가번호(PK) 이름 생년월일 소속사코드(FK) 1 홍길동 200090305 A001 2 김철수 20101020 B001 3 최영희 20090703 B001 소속사(소속사코드, 소속사명)
소속사코드(PK) 소속사명 A001 AC엔터테인먼트 B001 BD엔터테인먼트
-
- 보이스코드정규형(BCNF)
결정자가 후보키로 취급되지 않는다.
모든 결정자가 항상 후보키가 되도록 릴레이션 분해- ex) R1(A, B, C)
A, B→C,C→BR1(A, C), R2(C, B)
- ex) R1(A, B, C)
- 제1정규형(1NF)
2. 반정규화(De-Normalization)
-
반정규화 ⭐️⭐️
데이터의 조회 성능을 향상시키기 위해 데이터의 중복을 허용하거나 데이터를 그룹핑하는 것- 입력, 수정, 삭제 성능 저하될 수 있음
- 데이터 정합성 이슈가 발생할 수 있음
→ 데이터 무결성 저해
-
테이블 반정규화 ⭐️
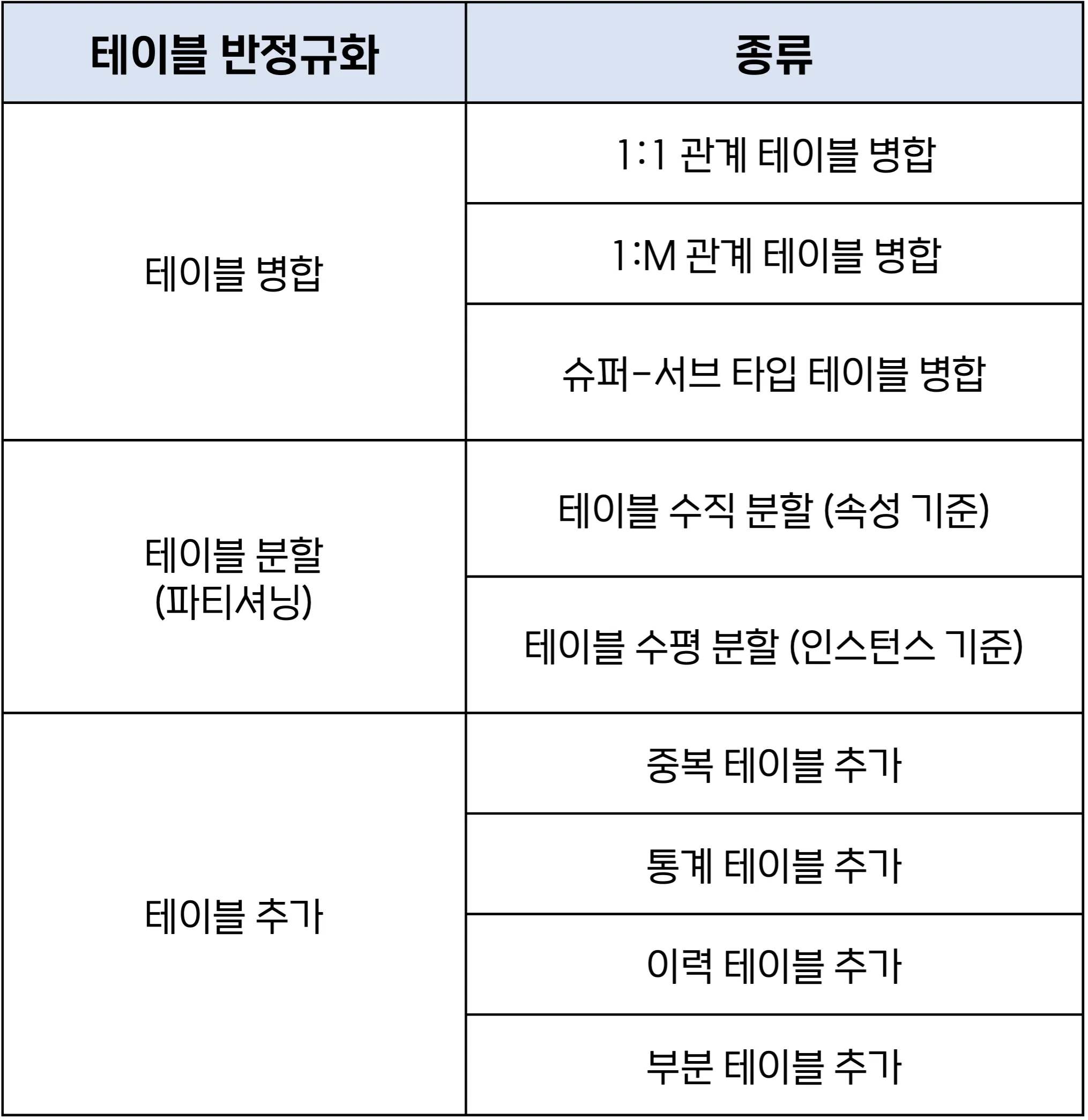
-
테이블 병합
-
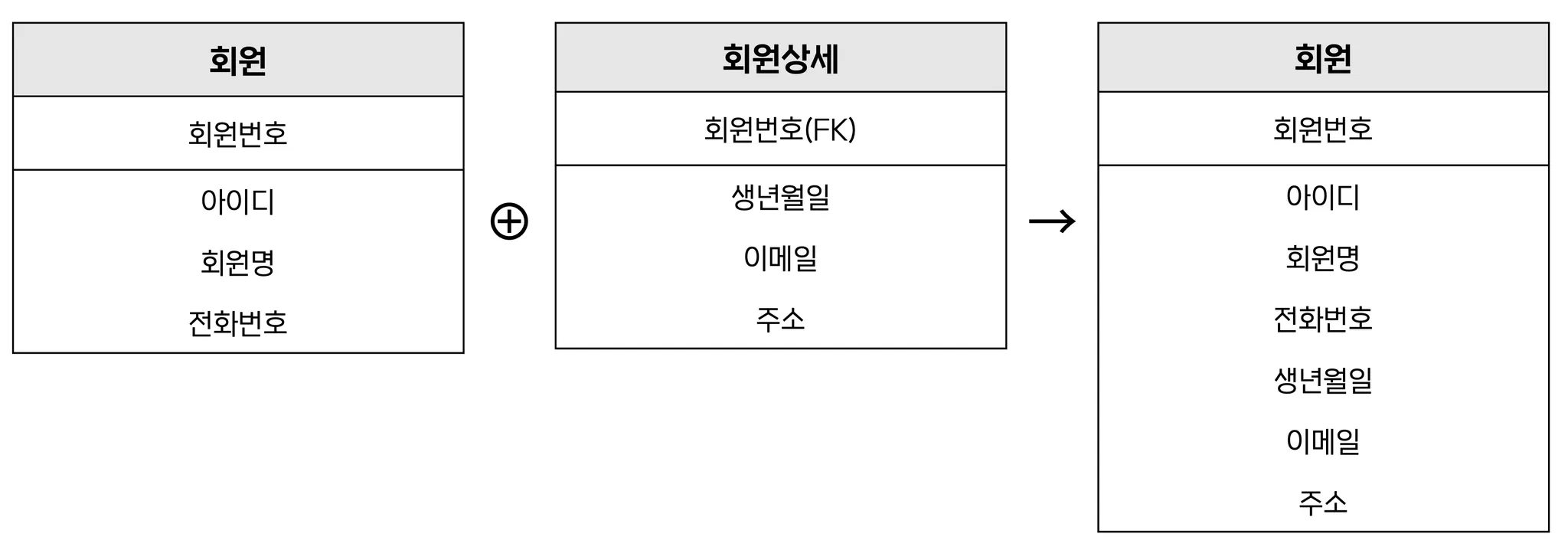
1:1 관계 테이블 병합
Ex) 회원 ⊕ 회원상세 → 회원
-
1:M 관계 테이블 병합
Ex) 주문 ⊕ 주문상세 → 주문
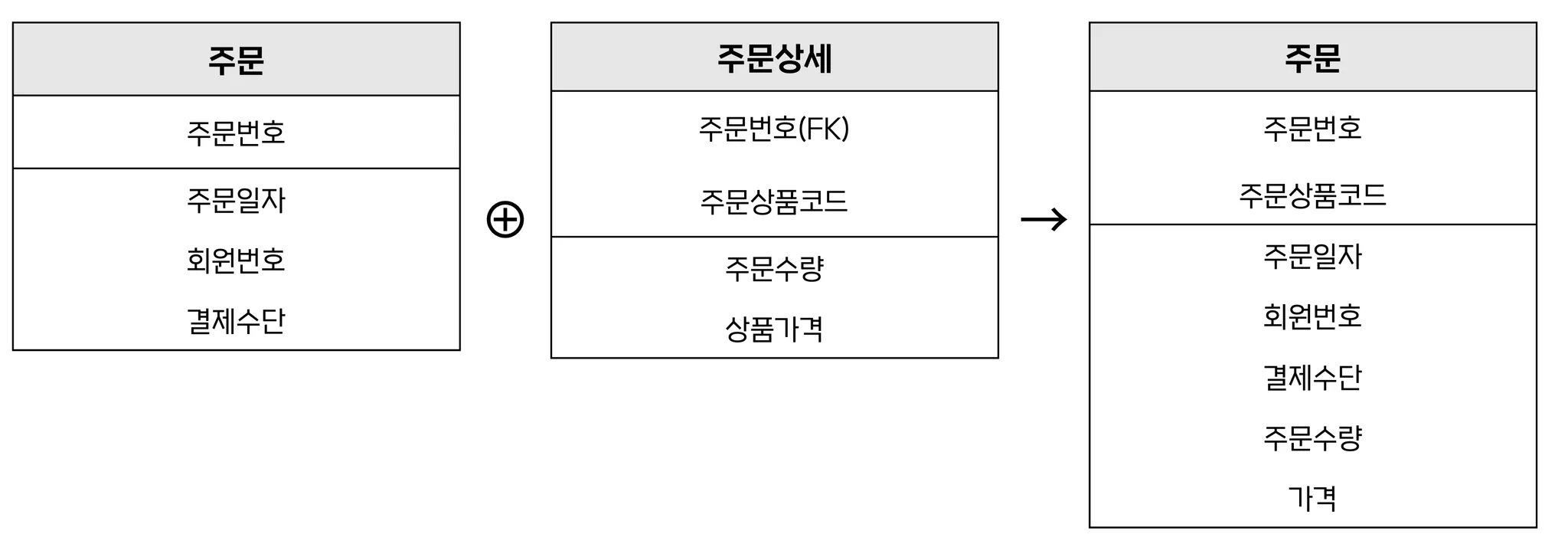
중복된 데이터가 생길 수 있음(주문일자, 회원번호, 결제수단)
1에 해당하는 엔티티의 속성 개수가 많으면 병합했을 때 중복 데이터가 많아지므로 적절하지 않음 -
슈퍼-서브 타입 테이블 병합
EX) super(사건), sub(일반 사건, 특수 사건 등)
-
-
테이블 분할
-
테이블 수직 분할: 엔티티의 일부 속성을 별도의 엔티티로 분할 (1:1 관계 성립)
자주 사용하는 속성이 아니거나 대부분의 인스턴스가 해당 속성값을NULL로 갖고 있을 때 고려
Ex) 회원 → 회원 ⊕ 회원배우자

💡 테이블을 수직 분할하면 한 개의 블록에 더 많은 인스턴스를 저장할 수 있게 된다. ✅
- 디스크 I/O를 줄일 수 있다.
- 데이터베이스는 데이터를 블록 단위로 저장 및 검색한다.
- 이 블록은 크기가 정해져 있기 때문에 한 행의 길이가 길어지면 한 블록에 담을 수 있는 행 개수가 적어진다.
- 그래서 수직 분할하면, 한 블록에 담을 수 있는 행 개수가 많아져서 검색 성능이 좋아질 수 있다.
-
테이블 수평 분할: 엔티티의 인스턴스를 특정 기준으로 별도의 엔티티로 분할
Ex) 주문 → 주문(2024) ⊕ 주문(2025)파티션 기능을 사용하여 주문일자에 따라 데이터를 물리적으로 분리
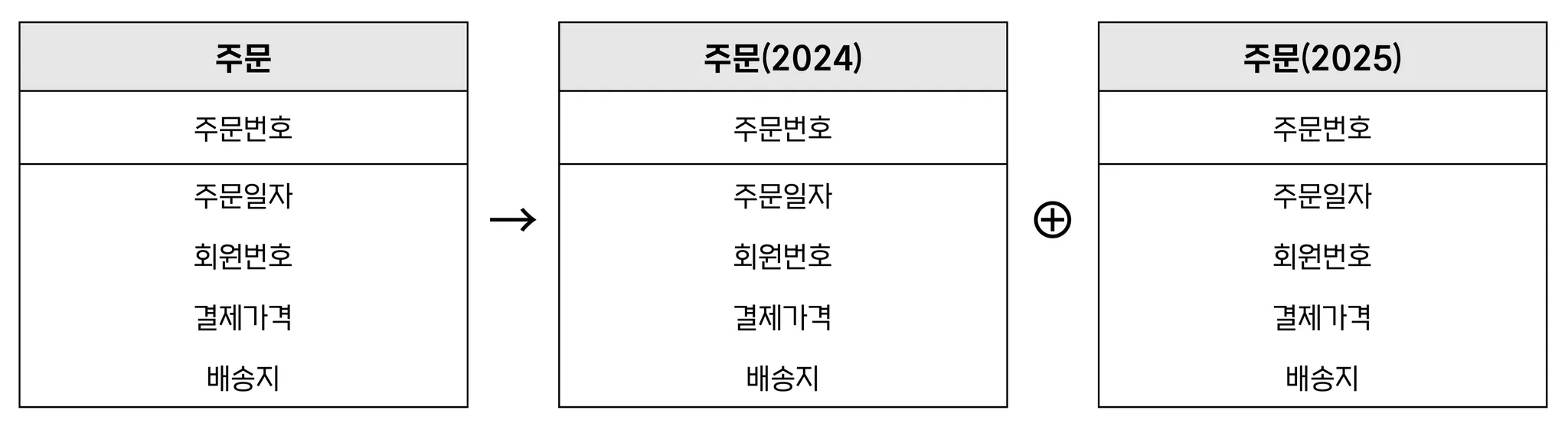
💡 파티셔닝 vs. 샤딩
- 파티셔닝(Partitioning)
- 수평/수직 분할
- 하나의 DB 안에서 분리하여 저장
- 관리 용이성, 쿼리 최적화
- 샤딩(Sharding)
- 수평 분할
- 여러 개의 DB 서버에 분산하여 저장
- 성능 최적화, 확장성
- 파티셔닝(Partitioning)
-
-
테이블 추가
- 중복 테이블 추가
데이터의 중복을 감안하더라도 성능상 반드시 필요하다고 판단되는 경우 별도의 엔티티 추가 - 통계 테이블 추가
기존 엔티티의 데이터를 이용하여 새로운 엔티티에 통계치를 미리 계산하여 저장
Ex) 주문 데이터를 이용하여 월매출 테이블에 통계치를 미리 계산하여 저장
- 이력 테이블 추가
데이터를 변경 이력과 함께 관리해야 할 경우 별도의 테이블을 추가하여 과거 데이터를 보존
Ex) 상품가격이력 테이블에서 과거의 상품가격에 대한 데이터 관리
- 부분 테이블 추가
특정 기능이나 작업을 위해 전체 데이터를 보관하는 것이 비효율적일 경우 필요한 데이터만 따로 저장
Ex) 회원 대상 메일 발송건이 다량으로 생기는 경우 메일 발송에 필요한 정보만 부분 테이블로 생성
- 중복 테이블 추가
-
-
컬럼 반정규화 ⭐️
- 중복 컬럼 추가
업무 프로세스상 JOIN이 필요한 경우가 많아 컬럼을 추가하는 것이 성능 측면에서 유리할 경우 고려
- 파생 컬럼 추가
프로세스 수행 시 부하가 염려되는 계산값을 미리 컬럼으로 추가하여 보관하는 방식
- 이력 테이블 컬럼 추가
대량의 이력 테이블을 조회할 때 속도가 느려질 것을 대비하여 조회 기준이 될 것으로 판단되는 컬럼을 미리 추가해 놓는 방식
- 중복 컬럼 추가
-
관계 반정규화(중복관계 추가) ⭐️
- 업무 프로세스상 JOIN이 필요한 경우가 많아 중복 관계를 추가하는 것이 성능 측면에서 유리할 경우 고려
- 데이터 무결성을 깨트릴 위험성이 없음
3. 트랜잭션(Transaction)
- 트랜잭션 ⭐️⭐️
- 데이터를 조작하기 위한 하나의 논리적인 작업 단위
- 데이터 모델로 표현할 수 있어야 함
- 데이터는 트랜잭션 범위로 묶일 수 있음
- 하나의 커밋으로 묶여야 함
4. NULL
- NULL ⭐️⭐️
존재하지 않음, 값이 없음
- NULL 연산 ⭐️⭐️
- 가로 연산: NULL이 포함되어 있으면 결과값은 NULL이 됨
- NULL이 포함된 사칙연산 결과 항상 NULL
Ex) NULL * 10, 3 + NULL
- NULL이 포함된 사칙연산 결과 항상 NULL
- 세로 연산: 집계 연산, 다른 인스턴스의 데이터와 연산할 때는 NULL값 제외함
- 가로 연산: NULL이 포함되어 있으면 결과값은 NULL이 됨
- NULL 비교 ⭐️⭐️
- 알 수 없음 반환 (IS NULL 제외)
5. 성능 데이터 모델링
- 성능 데이터 모델링
데이터베이스의 성능을 향상시키기 위해 설계 단계부터 성능과 관련된 사항들이 모델링에 반영될 수 있도록 하는 것- 방법: 정규화, 반정규화, 테이블 통합, 테이블 분할 등
- 방법: 정규화, 반정규화, 테이블 통합, 테이블 분할 등
- 성능 데이터 모델링 순서
- 데이터 모델에 맞게 정규화 수행
- 데이터베이스의 용량 및 트랜잭션 유형 파악
- 데이터베이스 성능을 고려하여 반정규화 수행
- PK/FK 등을 조정하여 인덱스를 반영함로써 성능을 향상시킨다.
- 데이터 모델의 성능 검증
