
가상 면접 사례로 배우는 대규모 시스템 설계 기초 책을 바탕으로 정리한 내용입니다.
목차
- 단일서버
- 데이터베이스
- 규모확장
1. 단일서버
웹 앱, 데이터베이스, 캐시 등이 전부 서버 한 대에서 실행된다.
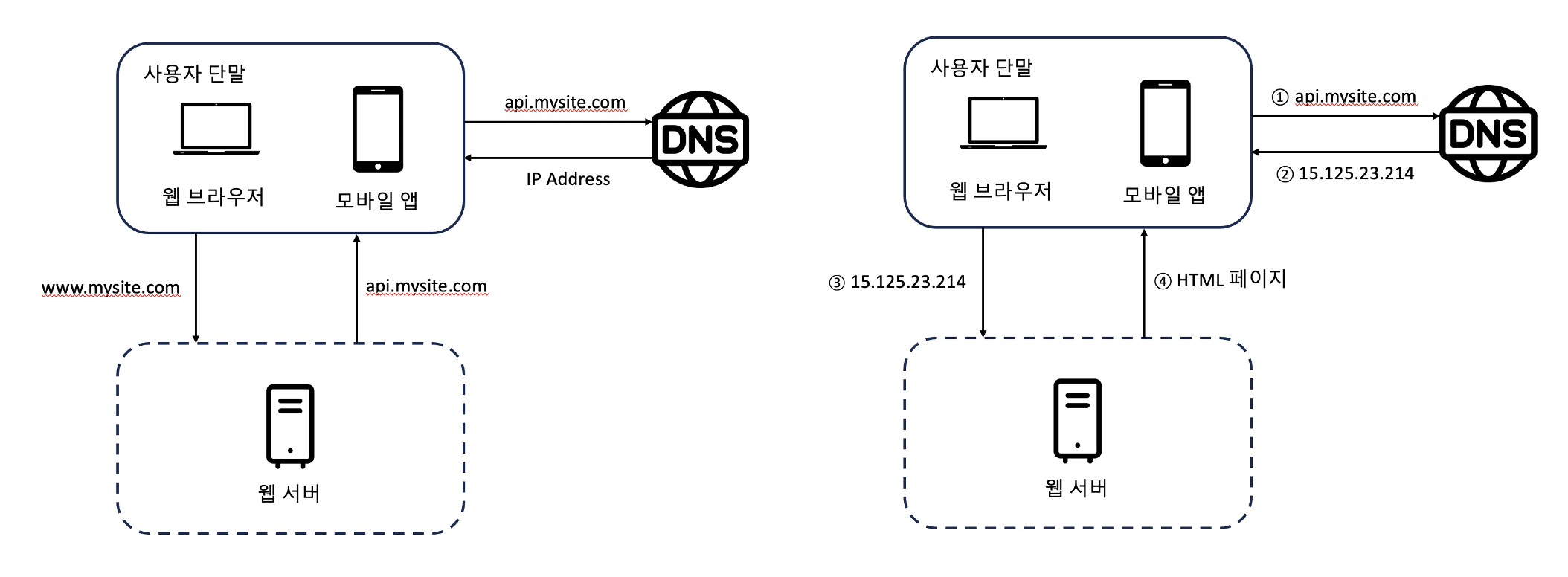
- 사용자는 도메인 이름(api.mysite.com)을 이용하여 웹사이트에 접속한다.
- DNS 조회 결과로 IP 주소(15.125.23.214)가 반환된다.
- 해당 IP주소로 HTTP 요청이 전달된다.
- 요청을 받은 웹 서버는 HTML 페이지 또는 JSON 형태의 응답을 반환한다.
실제 요청이 오는 2가지 단말?
- 웹 애플리케이션
- 비즈니스 로직, 데이터 저장 - 서버 구현용 언어(Java, Python)
- 프레젠테이션용 - 클라이언트 구현용 언어(HTML, JavaScript)
- 모바일 앱
- HTTP 프로토콜을 통해서 반환될 응답 데이터의 포맷으로 JOSN(JavaScript Object Notattion)이 주로 사용된다.
- 예제
{ "id": 12, "firstName": "John", "lastName": "Smith", "address": { "streetAddress": "21 2nd Street", "city": "New Tork", "state": "NY", "postalCode": 10021 }, "phoneNumbers": [ "212 555-1234", "646 555-4567" ] }
2. 데이터베이스
사용자가 많아지면 단일 서버로는 충분하지 않아서 여러 서버를 두어야 한다.
하나는 웹/모바일 트래픽 처리 용도이고, 다른 하나는 데이터베이스용이다.
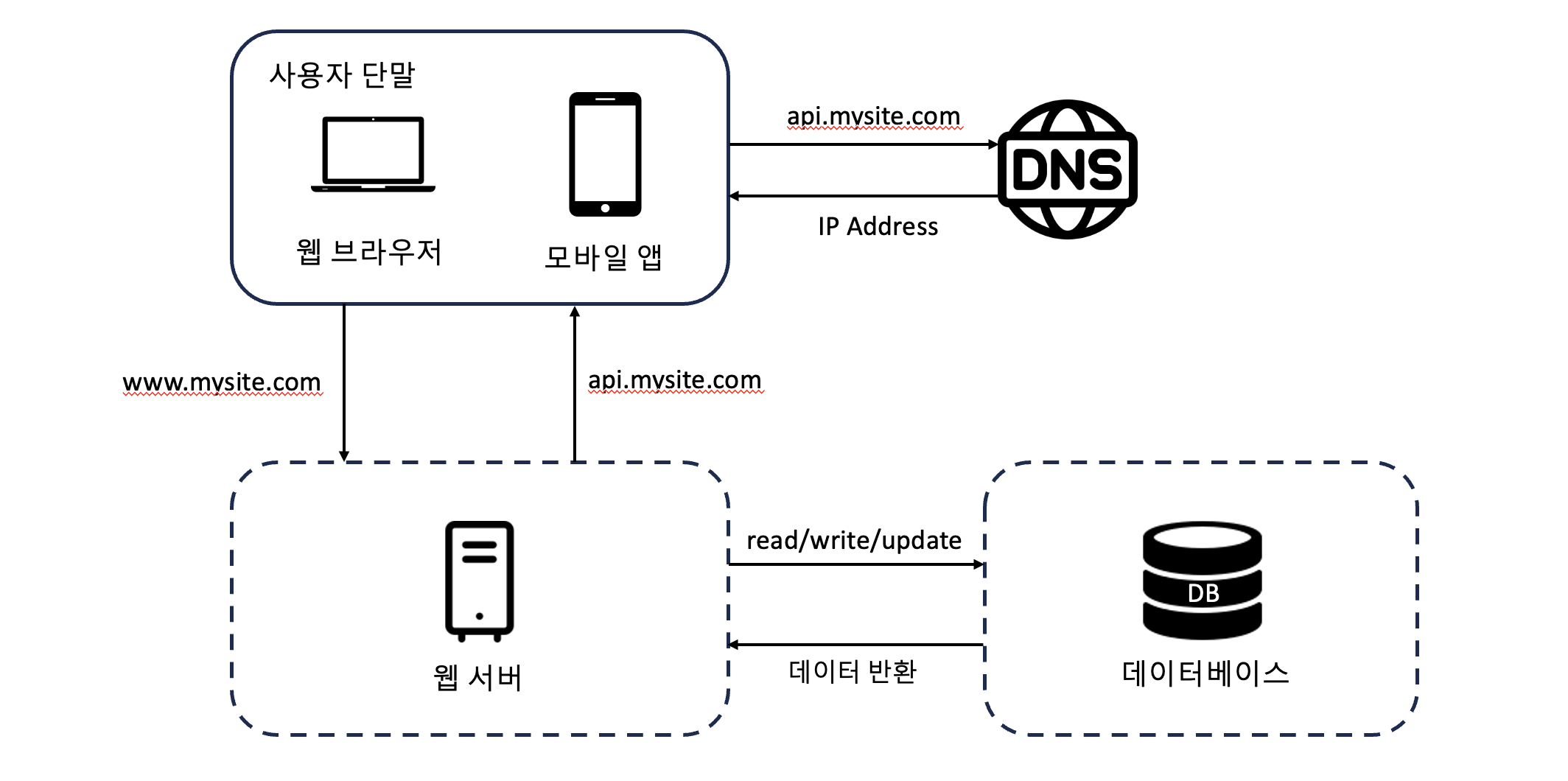
어떤 데이터베이스를 사용할 것인가?
1. 관계형 데이터베이스(Relational Database)
2. 비-관계형 데이터베이스(NoSQL)
| 구분 | RDBMS | NoSQL |
|---|---|---|
| DB | MySQL, ORACLE, PostgreSQL, Aurora | MongoDB, CouchDB, Neo4j, HBase, Amazon DynamoDB |
| 데이터 모델 | 테이블 간 관계를 기반으로 한 정형화된 데이터 모델 | 비정형화된 데이터 모델 키-값(key-value), 그래프(graph), 칼럼(column), 문서(document) 저장소(store) 등 |
| 확장성 | 수직적 확장방식으로 확장성이 제한적 | 수평적 확장방식으로 확장성이 우수 |
| 트랜잭션 | ACID 지원 | ACID보다 덜 엄격한 BASE(Basically Available, Soft State Eventual consistency) |
| 적용 분야 | 고정적인 스키마, 복잡한 관계를 갖는 데이터 | 대규모 데이터, 높은 확장성, 유연한 스키마 등 |
| 예시 | 금융권, 주문 관리, 인사 관리 등 | 소셜 미디어, IoT 기기 데이터 수집, 로그 데이터 분석 등 |
3. 규모 확장
1) 수직적 규모 확장 vs 수평적 규모 확장
'스케일 업(scale up)'이라고 불리는 수직적 규모확장(vertical scaling) 프로세스는 서버에 고사양 자원(더 좋은 CPU, 더 많은 RAM 등)을 추가하는 행위이다.
'스케일 아웃(scale out)'이라고 불리는 수평적 규모확장(horizontal scaling) 프로세스는 더 많은 서버를 추가하여 성능을 개선하는 행위이다.
서버로 유입되는 트래픽의 양이 적을 때는 수직적 확장이 좋은 선택이다.
하지만, 수직적 규모 확장에는 한계가 있다.
- 한 대의 서버에 CPU나 메모리를 무한대로 증설할 방법이 없다.
- 장애에 대한 자동복구(failover) 방안이나 다중화(redundancy) 방안을 제시하지 않는다. 그렇기 때문에 서버에 장애가 발생하면 웹사이트/앱은 완전히 중단된다.
따라서 대규모 애플리케이션을 지원하는 데는 수평적 규모 확장법이 더 적절하다.
2) 로드밸런서(Load Balancer)
부하 분산 집합(load balancing set)에 속한 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할을 한다.
로드밸런서를 사용하는 이유?
사용자가 웹 서버에 바로 연결될 때, 웹 서버가 다운되면 사용자는 웹 사이트에 접속할 수 없다. 또한, 너무 많은 사용자가 접속하여 웹 서버가 한계 상황에 도달하게 되면 응답 속도가 느려지거나 서버 접속이 불가능해질 수도 있다.
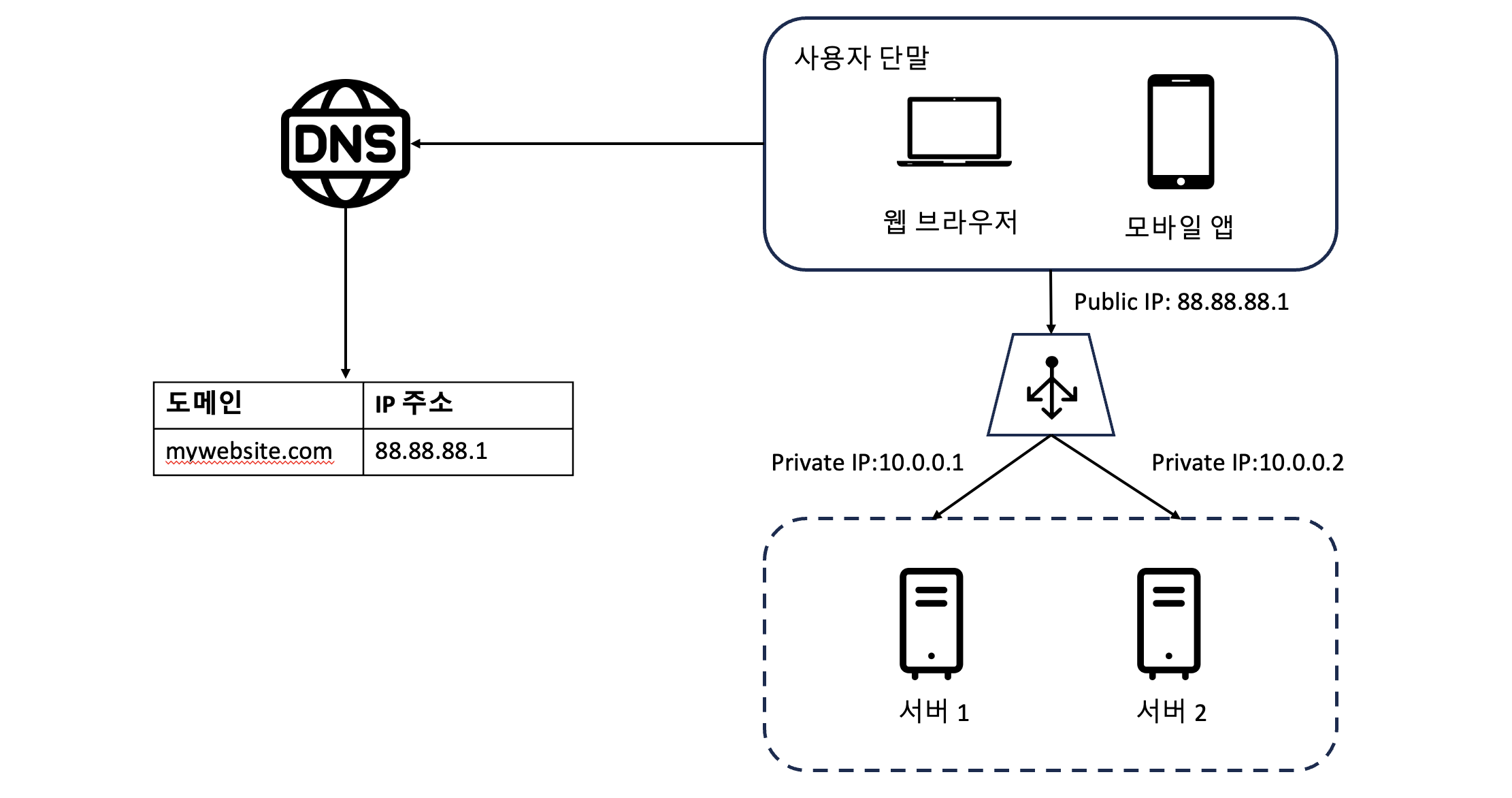
- 사용자는 로드밸런스의 공개 IP 주소로 접속한다.
: 웹 서버는 클라이언트의 접속을 직접 처리하지 않고, 보안을 위해 서버 간 통신에는 사설 IP 주소가 이용된다. - 부하 분산 집합에 또 하나의 웹 서버를 추가하면,장애를 복구하지 못하는 문제(no failover)는 해소되고,웹 계층의 가용성(availability)은 향상된다.
예제
서버 1이 다운되면 모든 트래픽은서버 2로 전송된다. 따라서 웹 사이트 전체가 다운되는 일이 방지된다. 부하를 나누기 위해 새로운 서버를 추가할 수도 있다.- 웹사이트로 유입되는 트래픽이 증가하여 2대의 서버로 트래픽을 감당할 수 없는 시점이 온다. 이때, 로드밸런서가 있으므로 대처가능하다. 웹 서버 계층에 더 많은 서버만 추가하면, 로드밸런서가 자동으로 트래픽을 분산할 것이다.
🗒️ 사설 IP 주소: 같은 네트워크에 속한 서버 사이의 통신에만 쓰일 수 있는 IP 주소로, 인터넷을 통해서는 접속할 수 없다. 로드밸런서는 웹 서버와 통신하기 위해 사설 주소를 이용한다.
3) 데이터베이스 다중화
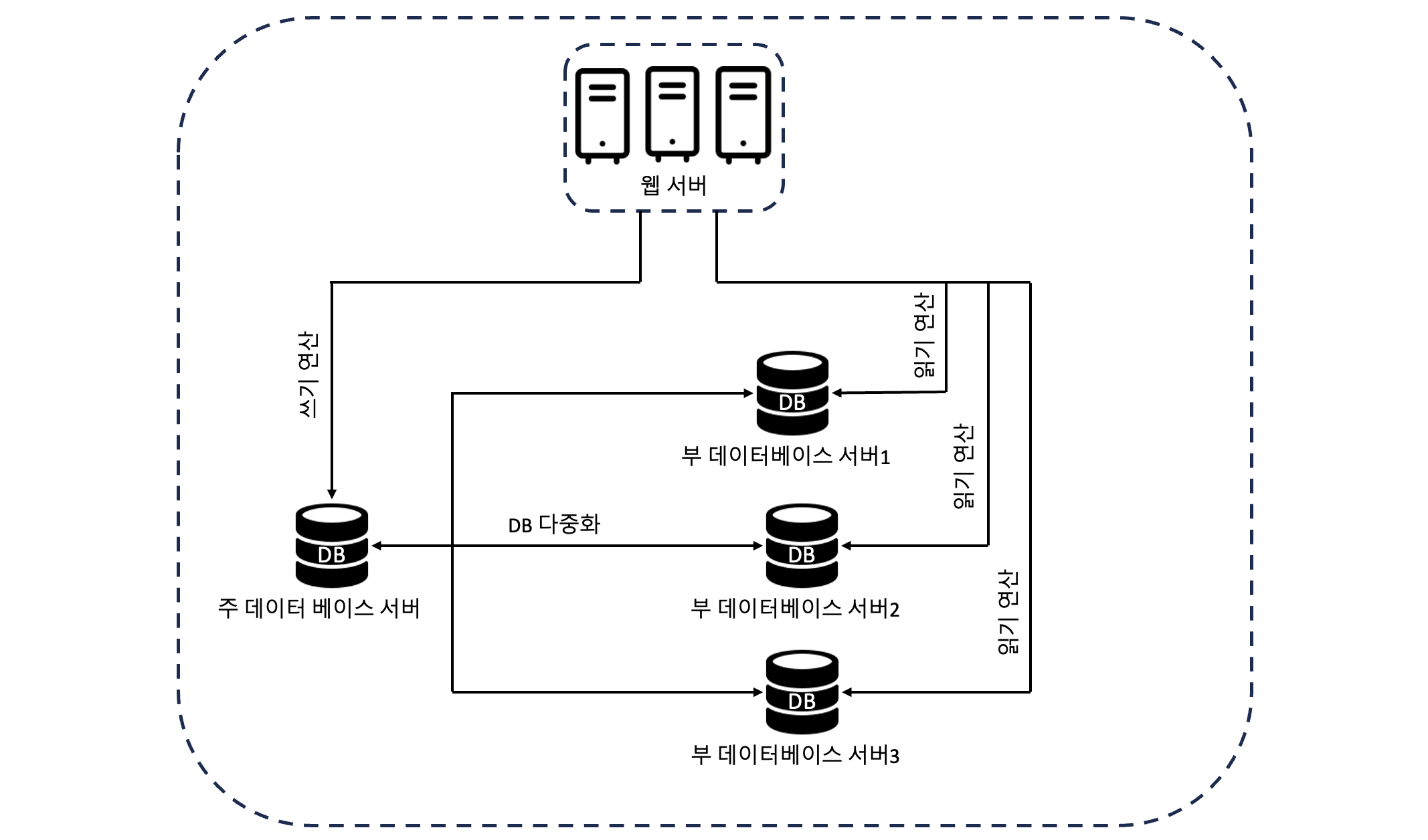
대부분의 DBMS는 다중화를 지원한다. 구조는 주로 주(master) - 부(slave) 관계로 되어 있다. 쓰기연산(write operation)은 master에서만 가능하며, slave에서는 master에서 변경된 데이터의 사본을 전달 받아 읽기 연산(read operation)만을 수행한다.
대부분의 애플리케이션은 읽기 연산이 쓰기 연산보다 많기 때문에 일반적으로 부 데이터베이스의 수가 주 데이터베이스의 수보다 많다.
장애가 발생한다면?
- 부 데이터베이스가 죽는 경우
- 부 데이터베이스가 한 대면 일시적으로 주 데이터베이스가 읽기 연산을 가져가서 부하가 잠깐 많아지기는 하지만 서비스는 정상적으로 동작한다.
- 부 데이터베이스가 여러 대면 나머지 서버들로 분산되기 때문에 문제가 되지 않는다.
- 주 데이터베이스가 죽는 경우
- 부 데이터베이스 중 하나가 주 데이터베이스가 되어 읽기 연산을 처리하면 된다. 하지만, 프로덕션(production) 환경에서는 부 데이터베이스에 보관된 데이터가 최신 상태가 아닐 수 있다는 문제점이 있긴 하다.
따라서 데이터베이스 다중화는 더 나은 성능, 안정성(reliability), 가용성(availability)의 장점을 갖고 있다.
다음은 로드밸런서와 데이터베이스 다중화를 고려한 설계안이다.
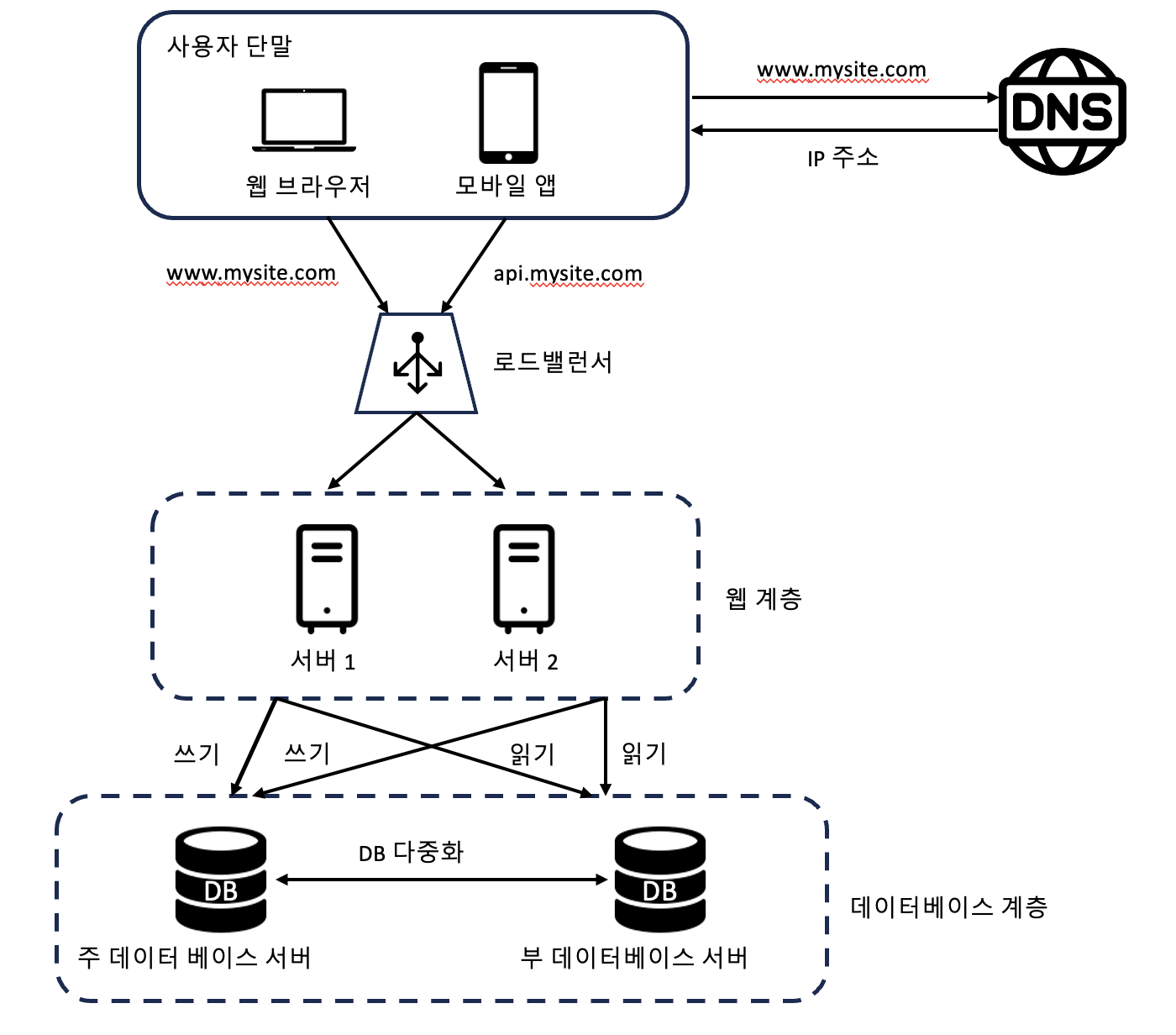
- 사용자는 DNS로부터 로드밸런서의 공개 IP주소를 받는다.
- 사용자는 해당 IP 주소를 사용해 로드밸런서에 접속한다.
- HTTP 요청은 서버 1이나 서버 2로 전달된다.
- 웹 서버는 사용자의 데이터를 부 데이터베이스 서버에서 읽는다.
- 웹 서버는 데이터 변경 연산의 경우 주 데이터베이스로 전달한다.
🗒️ 쓰기 연산: insert, update, delete
