모델 성능 평가란, 실제값과 모델에 의해 예측된 값을 비교하여 두 값의 차이를 구하는 것으로 과적합(Overfitting)을 방지하고 최적의 모델을 찾기 위해 실시한다.
머신러닝 회귀 모델 평가 방법
회귀 모델의 평가 지표로는 MSE, RMSE, MAPE 등이 있고 이 값들은 오차이기 때문에 값이 작을수록 해당 모델이 우수한 성능을 가지고 있다는 것을 의미한다.
1. MAE (Mean Absolute Error)
실제값과 예측값의 차이에 대한 절대값의 평균
abs(y_train - y_predict).mean()2. MAPE (Mean Absolute Percentage Error)
에러 비율((실제값 - 예측값)/실제값)의 절대값에 대한 평균
abs((y_train - y_predict)/y_train).mean()3. MSE (Mean Squared Error)
에러(실제값 - 예측값) 제곱의 평균
분산과 유사한 공식
((y_train - y_predict)**2).mean()- MSE를 쓰는 이유 :
더 큰 오류에 대해 더 큰 패널티를 부과하기 위해.
4. RMSE (Root Mean Squared Error)
MAE에 루트를 씌운 값으로 표준편차와 유사한 공식
((y_train - y_predict)**2).mean() ** (1/2)
MAE ** (1/2)R2 Score
'실제 값의 분산 대비 예측값의 분산 비율' 로 요약 될 수 있으며, 예측 모델과 실제 모델이 얼마나 강한 상관관계 (Correlated)를 가지는가로 설명력을 요약할 수 있음.
(회귀 모델이 얼마나 '설명력' 이 있느냐를 의미)
from sklearn.metrics import r2_score
r2_score(y_test, y_predict)4) 특징으로는 다른 평가지표인 MAE MSE RMSE 모두 에러에 대한 값이기 때문에 작을수록 좋은 값이지만 R2 Score는 1에 가까울 수록 좋음
* 회귀에서는 Accuracy를 사용하지 않는 이유
데이터의 일치 여부를 판단하는 것이라 회귀를 판단하기엔 적절하지 않고 분류에 적합함.
회귀는 MAE, MSE, RMSE와 같은 지표들로 판단하는 것이 보다 적합함.
머신러닝 분류 모델 평가 방법
1. 정확도 (Accuracy)
실제 데이터에서 예측 데이터가 얼마나 같은지 판단하는 지표
- 1번 방법
(y_test == y_predict).mean()- 2번 방법
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)- 3번 방법
(f1socre -- ACCURACY)
from sklearn.metrics import classification_report
print(classification_report(y_test, y_predict))-
주의 사항 1
이진 분류의 경우 데이터의 구성에 따라 ML(Machine Learning) 모델의 성능을 왜곡할 수 있기 때문에 정확도 수치 하나만 가지고 성능을 평가하지 않음 -
주의 사항 2
정확도 평가 지표는 불균형한 레이블 데이터 세트에서는 성능 수치로 사용돼서는 안됨
정확도(Accuracy)의 한계점
정확도(Accuracy)는 불균형한 레이블 값 분포에서 머신러닝의 성능을 판단할 경우, 적합한 평가 지표가 아님.
예를 들어 우리가 실습한 캐글 타이나닉 문제에서 성별로만 예측을 진행해도 0.76555라는 높은 수치가 나오게 됨.
즉, 정확도는 불균형한 레이블 데이터 세트에서는 평가 지표로 사용하는 것에 신중해야 합니다.
정확도가 가지는 분류 평가 지표로서 이러한 한계점을 극복하기 위해 여러 가지 분류 지표와 함께 적용해야 하는데, 이런 단점을 보완할 수 있는 평가지표로는 오차행렬(Confusion Matrix)를 사용할 수 있을 것
2. 오차행렬(Confusion Matrix)
이진 분류에서 오차행렬은 분류 모델이 얼마나 헷갈리고 있는지도 함께 보여주는 지표.
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_predict)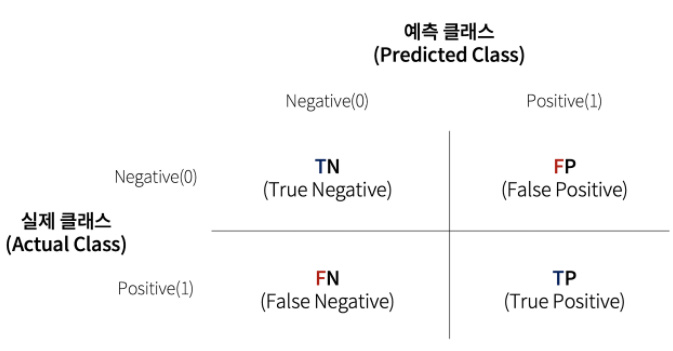
T는 True, 예측과 실제값이 동일한 것을 의미
F는 False, 예측과 실제값이 다른 것을 의미
P는 Positive, 예측값이 긍정 (1)을 의미
N은 Negative, 예측값이 부정 (0)을 의미
3. 정밀도 (Precision)
Positive로 예측한 경우 중 실제로 Positive인 비율로 수식으로는 TP/TP+FP 로 나타낼 수 있음
Titanic 예제의 경우 생존자라고 예측한 값 중에서 실제 생존자를 예측한 정확도
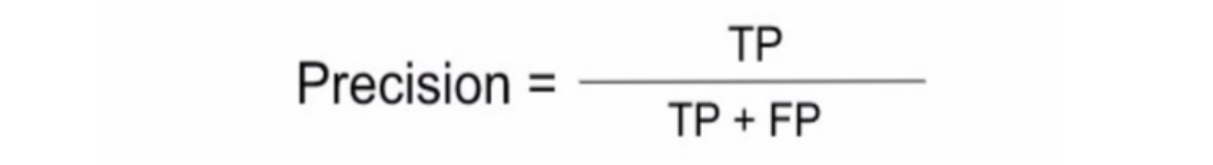
4. 재현율(Recall) = 민감도(Sensitivity)
실제 Positive인 것 중 올바르게 Positive를 맞춘 것의 비율로 실제 정답을 얼마나 맞췄는가의 의미. TP/TP+FN
Titanic 예제의 경우 실제 생존자에 대해 생존자를 얼마나 정확하게 예측했는지

5. F1 Score
Precision과 Recall의 조화평균으로 분류 클래스 간 데이터가 불균형이 심각할 때 사용하며 높을수록 좋은 모델
F1 Score = 2PrecisionRecall / (Precision + Recall)
from sklearn.metrics import f1_score
pred = pipe.predict(X_test)
f1_score(y_test, pred)* 정확도, 정밀도, 재현율, F1 Score는 모두 0~1 사이 값을 가지며, 1에 가까워 질수록 성능이 좋다는 것을 의미
