AI 스쿨 7_J1_자기주도학습
1.22.9.22 자기주도학습

지난 수업 시간에서 응용 1, 2를 정확하게 따라하지 못했던 조건문, 반복문을 복습하기로 했다.Q 숫자를 입력받아 음수와 양수 여부를 출력<결과값>숫자를 입력하세요: -2음수문자열 -> 리스트리스트를 순회하며 요소 하나씩 꺼내기 가능Q "월화수목금토일"을 리스트
2.9.29 자기주도학습 (9.26~28 학습 내용)
이번주에 수강했던 내용 코드 복습 및 정리
3.머신러닝 알고리즘 유형과 학습법의 기본 개념
머신러닝은 AI의 하위 개념이며 딥 러닝(Deep Learning)이 머신러닝의 하위 개념이다.머신러닝 알고리즘 유형을 구분하는 것에는 두가지 기준이 있다.첫 번째 기준은 정답의 유무로 구분되는 1) 지도학습과 2) 비지도학습이 있다. 지도학습에는 분류(Classifi
4.머신러닝 회귀/분류 모델의 평가 방법 정리
모델 성능 평가란, 실제값과 모델에 의해 예측된 값을 비교하여 두 값의 차이를 구하는 것으로 과적합(Overfitting)을 방지하고 최적의 모델을 찾기 위해 실시한다.회귀 모델의 평가 지표로는 MSE, RMSE, MAPE 등이 있고 이 값들은 오차이기 때문에 값이 작
5.머신러닝-피처 엔지니어링의 종류
데이터를 설명하고 예측을 수행하는 데 사용되는 입력 변수.피처들은 일반적으로 수치이나, 그래프와 같은 자료 구조적인 피처들도 있다.데이터는 값의 형태에 따라 수치형 데이터와 범주형 데이터로 구분할 수 있다. 이때 우리가 해결하고자 하는 문제를 컴퓨터가 잘 이해할 수 있
6.머신러닝 부스팅(Boosting) 기본 개념 정리
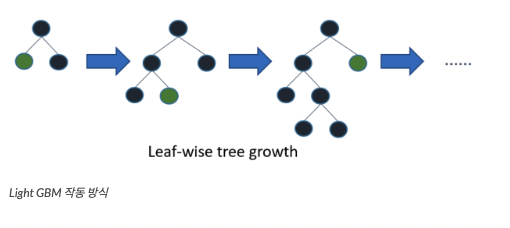
머신러닝에서 부스팅은 오차를 줄이기 위해 사용되는 학습 방법. 앙상블 기법 중 하나로 약한 모델 여러개를 결합하여 성능을 높이는 알고리즘. 배깅과의 다른 점은 배깅이 여러 데이터셋으로 나눠 학습을 한다면 (동시, 병렬 학습) 부스팅은 데이터셋 모델이 뒤의 데이터셋을 정
7.머신러닝-분류(Classification)에 대하여
머신러닝은 인공지능을 구현하는 여러 방법 중 하나로 유용한 함수를 컴퓨터가 학습하는 것이다.머신러닝은 상황(Task)에 따라 크게 3가지로 분류가 가능하다지도 학습은 이러한 input이 들어오면 이런 output이 나와야 한다는 것을 알려주는 것이다Classificat
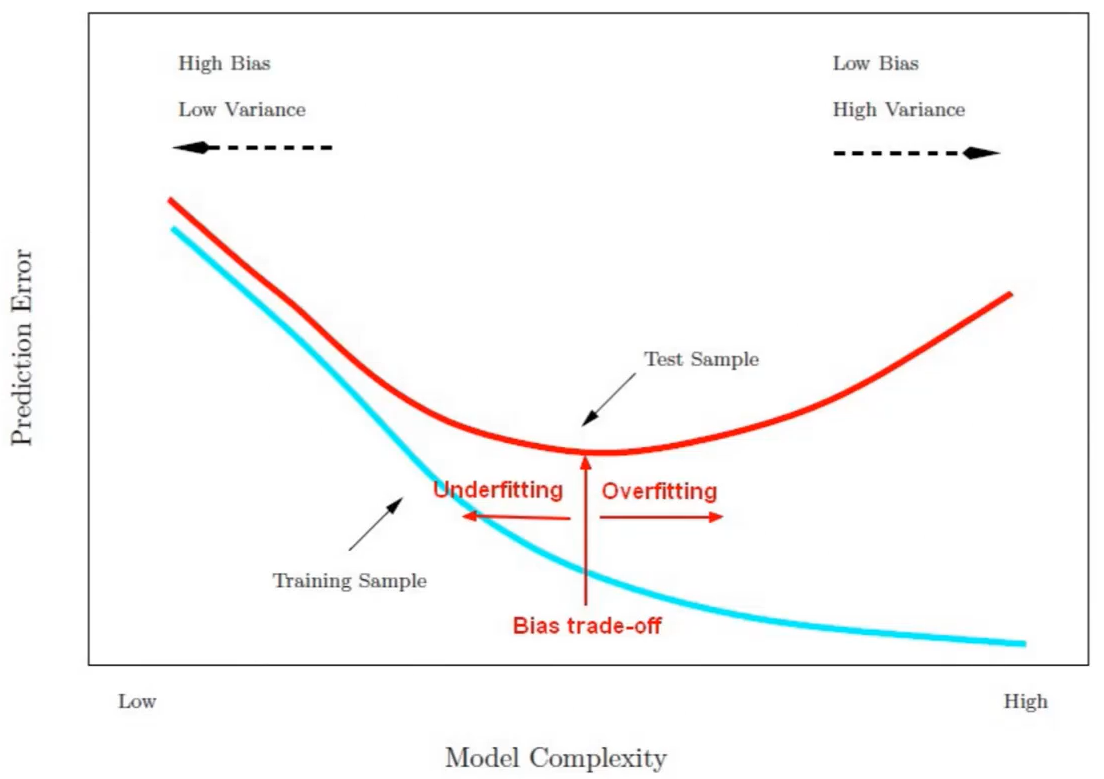
8.머신러닝 최적화와 경사하강법
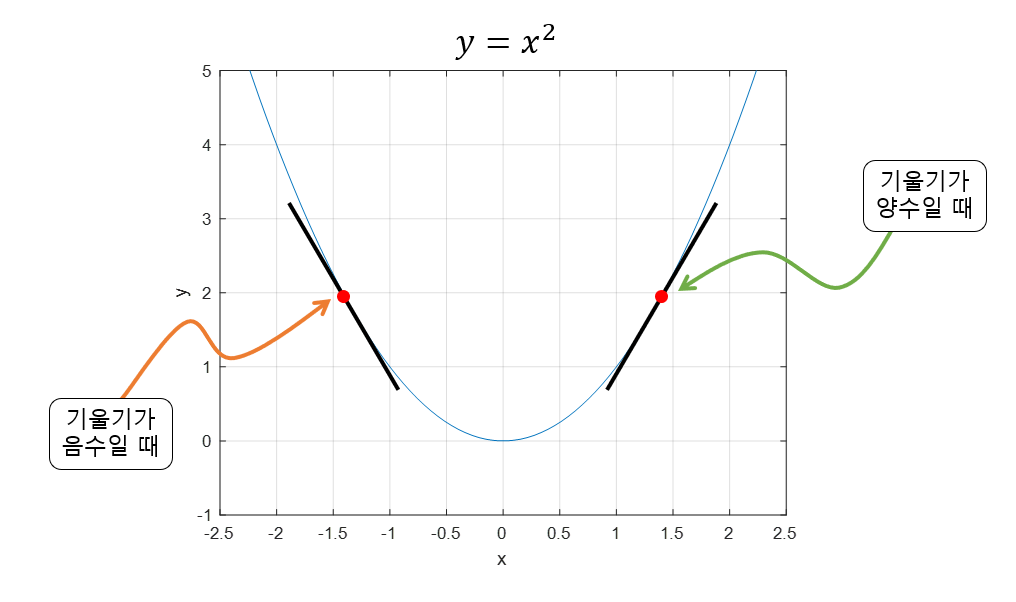
Loss함수를 정의하고 Loss 함수를 최소화 해주는 모형, 패턴을 찾는 것머신러닝에서 모델이 나타내는 확률 분포와 데이터가 따르는 실제 확률 분포 사이의 차이를 나타내는 함수즉, 예측값과 실제값 사이의 차이를 나타내는 함수이다MAE(Mean Absolute Error
9.Support Vector Machine(SVM)이란
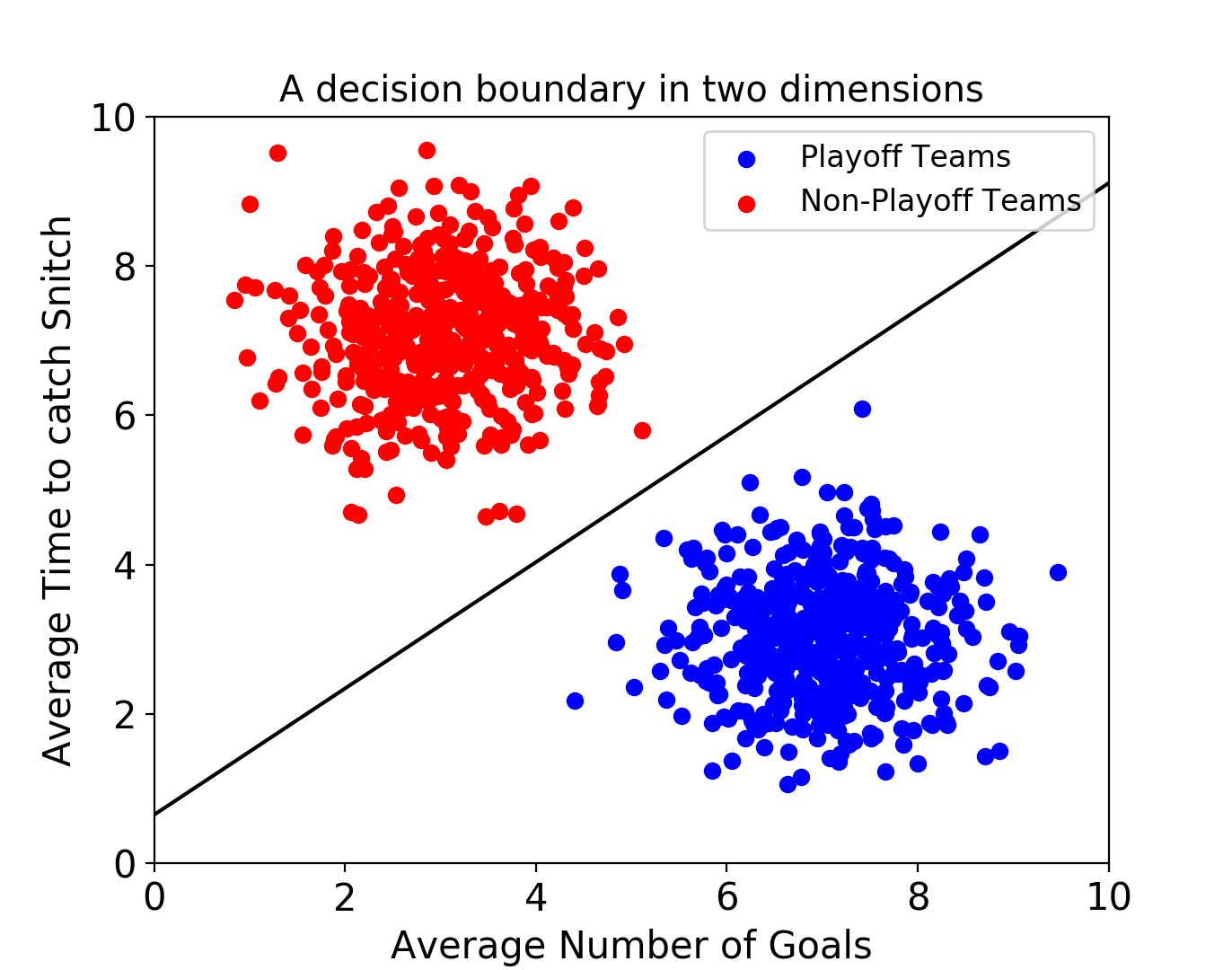
선형 또는 비선형적인 분류, 회귀, 이상치 탐색에도 사용할 수 있는 머신러닝 방법론딥러닝(2013) 이전 시대까지 널리 사용된 방법론복잡한 분류 문제를 잘 해결하고 상대적으로 작거나 중간 크기를 가진 데이터에 적합한 알고리즘최적화 모형으로 모델링 후 최적의 분류 경계를
10.머신러닝 Decision Tree란
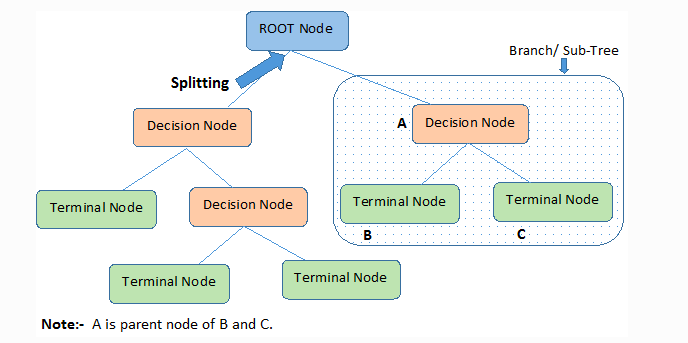
분류, 회귀 작업 및 다중출력 작업도 가능한 다재다능한 머신러닝 방법론IF-THEN 룰에 기반해 해석이 용이함일반적으로 예측 성능이 우수한 랜덤 포레스트 방법론의 기본 구조CART(Classification And Regression Tree) 훈련 알고리즘을 이용해
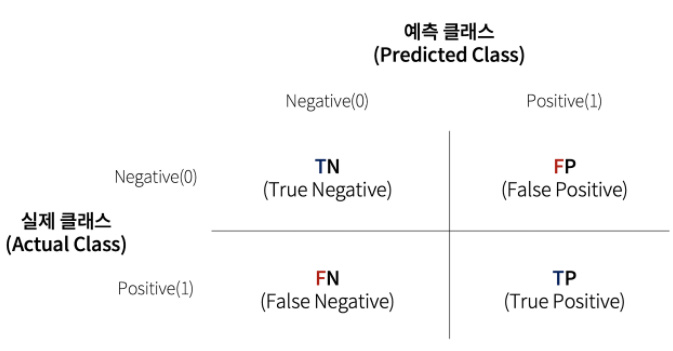
11.Confusion Matrix(혼돈 행렬)과 분류 성능 평가 지표
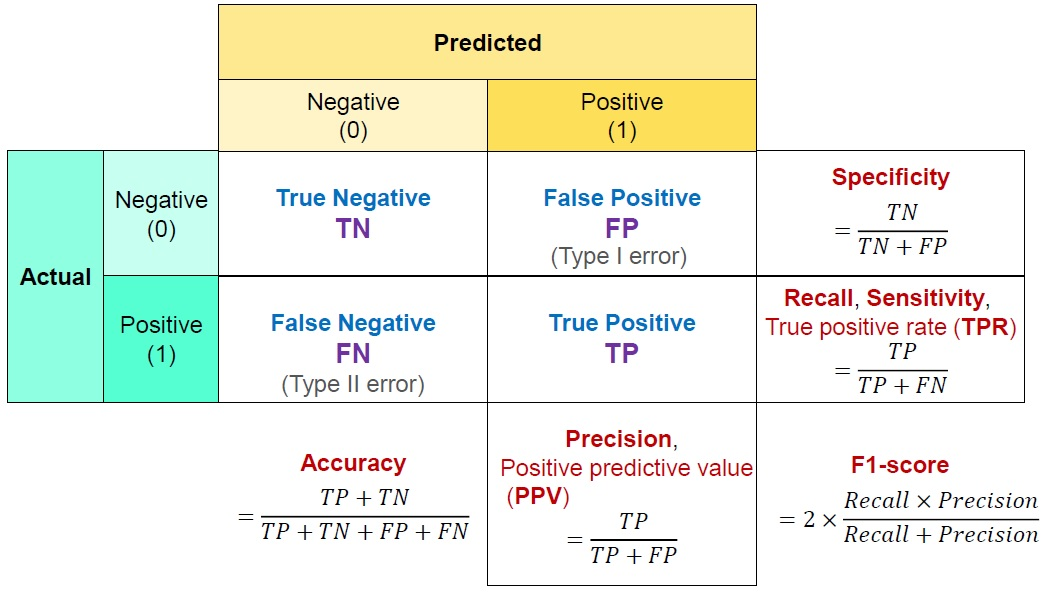
예측과 실제 값 사이의 관계를 행렬 형태로 표현한 것을 Confusion Matrix(혼돈 행렬 or 오차 행렬) 이라고 한다.True : 예측한 것이 정답False : 예측한 것이 오답Positive : 모델이 Positive라고 예측예) 암 진단 시 암이라고 진단N
12.ANN, DNN, CNN
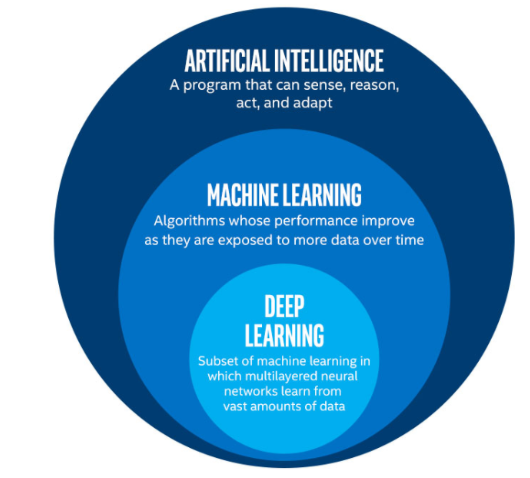
인공지능(AI : Artificial Intelligence)인간의 지능이 가지고 있는 기능을 갖춘 컴퓨터 시스템을 뜻하며, 인간의 지능을 기계 등에 인공적으로 구현한 것을 말한다.머신러닝/기계학습(ML : Machine Learning)인공지능의 하위 분야로 컴퓨터가