
현대의 ML/DL
오늘날의 로봇이 커피를 따르거나, 퍼즐을 맞추는 등의 과제를 할 수 있습니다.
이러한 과제를 수행하기까지는 작은 행동 하나라도 인간의 많은 노력과 시간, 그리고 데이터가 필요합니다.
그러나 퍼즐만 맞추는 로봇에게 공놀이를 시킨다면? 당연히 로봇은 부여받은 과제를 해내지 못할 겁니다. 그리고 이 과제를 과제를 수행하기 위해선, 또 다시 많은 노력과 시간, 데이터가 필요해집니다. 처음부터 학습시켜야 하니까요. 이는 음성 인식, object detection도 마찬가지입니다.
따라서 실생활에 쓰이는 로봇은 여러 가지 다른 작업에 대해 훈련된 시스템을 사용합니다.
왜 multi-task learning이 필요할까?
희귀 언어의 번역, 개인 맞춤 교육같이 데이터가 많이 없는 경우엔 어떻게 할까?
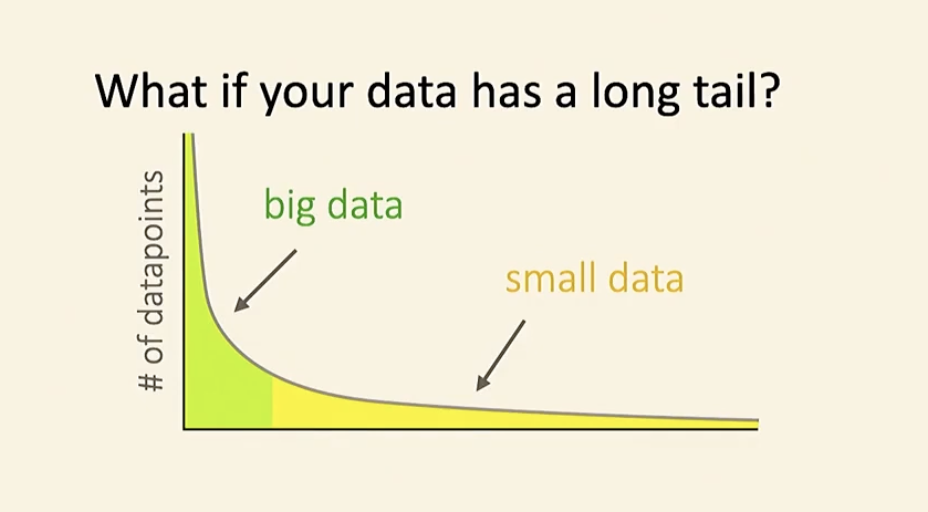
long tail같이 데이터가 왜곡되어있는 경우엔 어떻게 할까? 특히 long tail의 경우엔 머신러닝에 많은 문제를 야기한다고 합니다. 너무 많은 우세한 케이스들이 등장하여 희귀한 케이스의 경우 학습을 잘 하지 못하기 때문입니다.
multi-learning과 meta learning은 이 문제 자체를 해결하지는 못하지만, 이런 종류의 데이터들을 분배해서 더 잘 처리할 수 있을지도 모릅니다.

💡 few shot learning
훈련 데이터 포인터가 몇 개 없을 때
위의 사진에는 왼쪽엔 6개의 데이터가 있고, 이것을 바탕으로 오른쪽의 데이터가 누구의 작품인지 머신러닝을 이용하여 가려내려합니다. 과연... 머신러닝은 제대로 classification을 할 수 있을까요?
데이터가 많이 없는 경우에는 처음부터 학습을 시작하는 것이 아니라 meta learning을 통해서 이전 학습 결과물을 바탕으로 학습을 시키는 것이 더 좋은 방법입니다.
multi-task learning, transfer learning의 주요 역할

102개의 언어 번역기를 만들 때, 다른 데이터를 이용하거나, 다른 언어를 활용하여 데이터를 학습시킬 수 있다고 합니다.
유투브도 multi-task learning를 사용하여 알고리즘을 설계하여 각 유저에게 최적화된 추천을 해줍니다.
“A General Agent”라는 논문에서도 multi-task learning, transfer learning을 어떻게 활용하면 좋을지에 대해 설명한다고 합니다.
Deep learning의 대중화

위의 3개의 데이터셋은 충분한 양의 데이터셋입니다. 딥러닝을 처음부터 훈련시켜서 좋은 결과를 얻을 수 있습니다.
반면에 아래의 2개는 충분하지 않은 데이터셋입니다. 실제로 많은 경우 데이터가 부족한데요. 이 때 중요한 것이 multi-learning과 meta learning입니다. 이 두개를 이용하면 더 큰 데이터 세트에서 이전 정보를 추출하여 부족한 데이터셋에 적용시킬 수 있습니다.
What is Task?

비공식적으로, 우리는 “Task”라고 하면, dataset과 loss function을 입력한 후, 어떤 모델을 만들어내는 것을 생각합니다.
다른 task는 다른 사람 / 조건 / 기능 / 조건 / 단어 / 언어가 될 수 있습니다. 여기서 중요한 포인트로, multi-task는 꼭 다른 “업무 / 객체”이어야 하는 것은 아닙니다.
Critical Assumption

multi-learning과 meta learning을 할 때 주의해야 할 점이 있습니다.
- 응용시키려는 데이터가 완전히 독립적이라면, 학습을 시켜도 아무 의미가 없습니다. 이런 경우엔 단일 학습을 시키는 것이 더 효과적입니다.
- 많은 task가 structure을 공유합니다. 위의 사진을 예를 들면, 병뚜껑, 텀블러 열기 등이 있습니다.
My Opinion
이번 강의를 들으며 두 가지의 생각이 들었습니다.
첫번째는 내가 stanford 강의를 이해할 수 있을까? 였습니다.
영상 속 교수님의 설명은 모두가 이해할 수 있을 정도로 쉽게 설명해주어 1시간이라는 시간이 어떻게 지나가는지 모르고 봤고, 앞으로 있을 7개의 강의가 기대되기 까지 합니다.
두번째로, multi-task하면, 막연하게 데이터가 여러개로 쪼개져 학습이 이루어지기 때문에 더 빨라 선호한다고만 생각했습니다.
그러나, 데이터가 없을 경우에 structure만 같다면 이미 존재하는 빅데이터를 이용하여 학습을 시킬 수 있다는 사실을 배웠고, 이 점이 매우 흥미로웠습니다.
multi-task learning, transfer learning을 더 깊게 배워 이 분야의 전문가가 되어야겠다고 다짐하는 계기가 되었습니다.
