- https://concept-fusion.github.io
- https://github.com/concept-fusion/concept-fusion
- https://concept-fusion.github.io/assets/pdf/2023-ConceptFusion.pdf
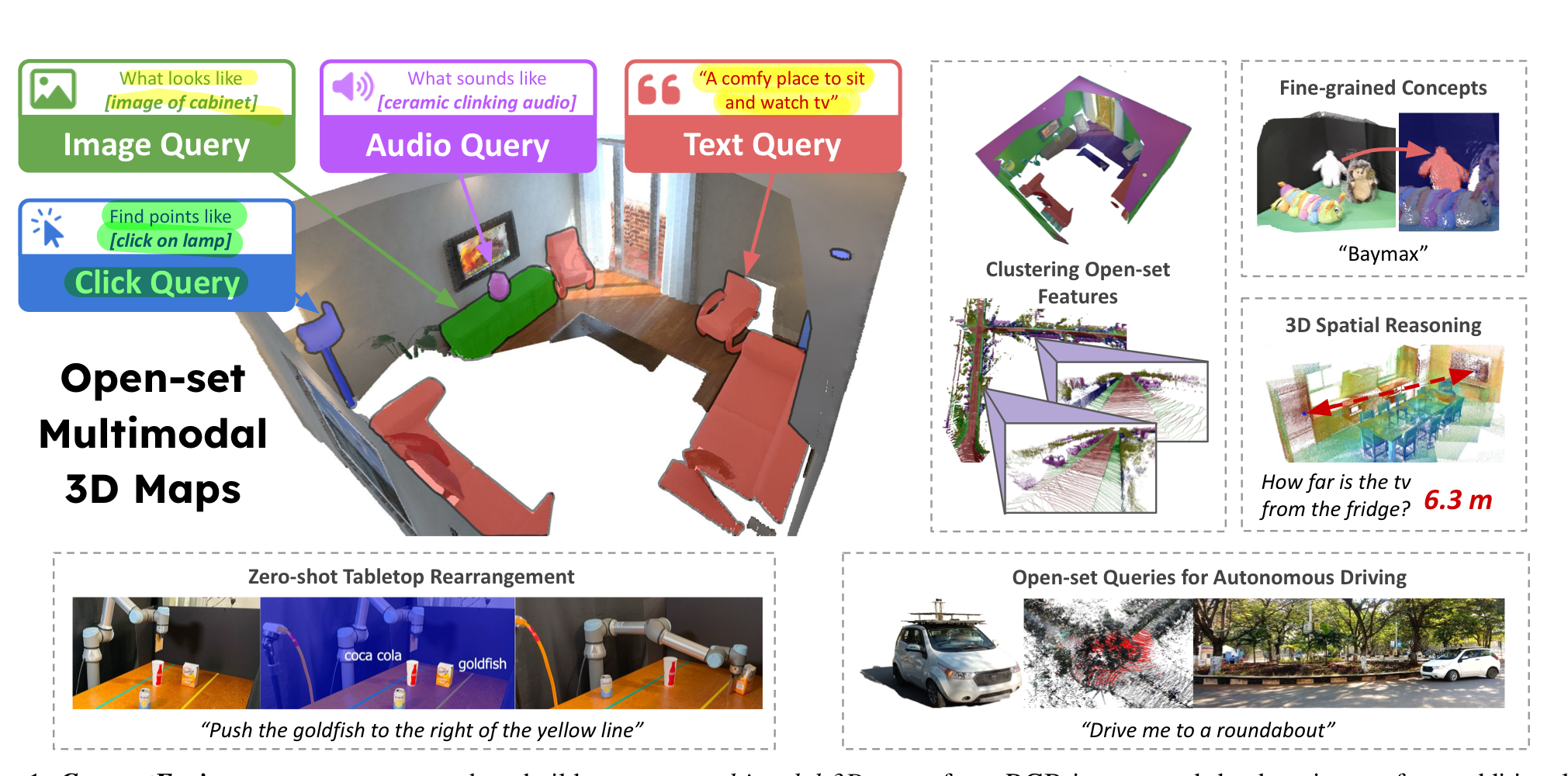
0. Abstract
- semantic concepts을 3D 맵과 통합하는 대부분의 기존 접근법은 주로 폐쇄형 설정에 국한되어 있습니다:
- 즉, 훈련 시에 미리 정의된 유한한 개념 집합에 대해서만 추론할 수 있습니다.
- 또한, 이러한 맵은
클래스 라벨을 사용하여 질의하거나,- 최근의 연구에서는
텍스트 프롬프트를 사용하여 질의할 수 있습니다.
- 최근의 연구에서는
- ConceptFusion
- (i) 근본적으로 개방형 설정으로, 폐쇄된 개념 집합을 넘어 추론할 수 있게 하며
- (ii) 본질적으로 멀티모달로, 언어, 이미지, 오디오, 3D 기하학 등 다양한 질의를 3D 맵에 대해 가능
- 우리는
pixel-aligned open-set features을 전통적인 SLAM 및 다중 뷰 융합 접근법을 통해 3D 맵에 융합할 수 있음을 입증합니다. - 이를 통해 추가적인 학습이나 미세 조정 없이 효과적인 제로샷 공간 추론이 가능하며,
- 기존 방법들보다 롱테일 개념(위 그림의 Baymax, goldfish 등)을 더 잘 유지하여
- 3D IoU에서 40% 이상 더 뛰어난 성능을 보입니다.
- 기존 방법들보다 롱테일 개념(위 그림의 Baymax, goldfish 등)을 더 잘 유지하여
1. Introduction
- CLIP [6], DINO [7], AudioCLIP [8]과 같은 기초 모델과 그 변형들은 추론 시에만 관심 개념이 제공되는 개방형 시나리오에서 인상적인 성능을 보여주었습니다.
- 이 연구에서 우리는
대규모 기초 모델이 제공하는 풍부한 개방형 기능과3D 매핑 시스템에 기대되는 의미적 추론 능력간의 격차를 해소 - 맵 표현은 제로샷으로 사용 가능해야 함(즉, 새로운 작업에 대한 추론 기능이 필요할 때마다 재학습할 필요가 없음) 다음 2가지 기능을 갖춰야 함
- 첫째,
- 3D 맵은 개방형이어야 하며, 기존 시스템보다 훨씬 더 다양한 개념(수량적으로 더 많은 개념)을 다양한 수준의 세부사항으로 캡처해야 합니다.
- 예를 들어, "소다 캔"이라는 개념은 "마실 것" 또는 "특정 브랜드의 소다" 또는 "청량 음료"로 동일하게 표현될 수 있습니다.
- 둘째, 3D 맵은 멀티모달이어야 함.
- 예를 들어, 맵에서 특정 객체를 검색하는 작업은 아래 여러가지 쿼리로 질의해도 잘 작동해야 합니다.
- 단어 하나(예: "소다")
- 추가적인 맥락을 제공하는 긴 문장(예: "부엌 테이블 위에 소다 캔이 있습니까?"),
- 소다 캔의 이미지
- 소다 캔을 여는 '팝' 소리
- 예를 들어, 맵에서 특정 객체를 검색하는 작업은 아래 여러가지 쿼리로 질의해도 잘 작동해야 합니다.
- 기초 모델은 개방형 멀티모달 표현을 달성하는 데 필요한 일부 특성을 가지고 있지만, 3D 매핑에는 직접 적용할 수 없습니다.
- 이 주요 제한은 대부분의 기초 모델이 이미지를 소비하고(예: CLIP [6], ALIGN [9], AudioCLIP [8]), 임베딩 공간에서 전체 이미지의 단일 벡터 인코딩만 생성하기 때문에 존재
- 반면에, 기초 기능을 2D 픽셀에 정렬하도록 특별히 훈련된 최근 접근법(LSeg, OpenSeg)은 fine-tuning 과정에서 많은 개념을 잊어버립니다 [10] (Fig. 4 참조).
- 우리는
pixel-level foundation features이 깊이 또는 색상 정보를 3D 맵에 융합하는 것과 동일한 표면 융합 기술을 활용하여 3D 맵에 융합될 수 있음을 입증합니다. - 우리의 주요 기여는 다음과 같습니다:
- 이미지 수준(글로벌) 기능 벡터만 생성할 수 있는 기초 모델을 이용해서, 픽셀 정렬(로컬) 기능을 계산하는 새로운 메커니즘.
- 개방형 멀티모달 3D 매핑을 평가하기 위한 새로운 RGB-D 데이터셋, UnCoCo.
- UnCoCo는 78개의 일반적인 가정/사무실 물체와 500K 이상의 모달리티 간 질의를 포함
2. related work
- 우리의
pixel-aligned features을 3D 맵에 융합하기 위해, 우리는 밀집 3D 매핑 커뮤니티에서 선구적인 접근법을 활용합니다.- 밀집 SLAM 접근법은 RGB(-D) 이미지에서 camera motion, scene geometry 및 (선택적으로) 색상을 추정
- 이러한 방법의 핵심은 Curless와 Levoy [28]의 volumetric fusion 기술로,
- real-time incremental capture of surface geometry and color 에 적응되었습니다[29, 30, 31, 32, 33].
- 이 연구에서 우리는
pixel-aligned features을 3D 맵에 융합하는 것을 추가하여, 개념적으로 단순하고 계산 효율적인 방법으로 확장합니다.
3. concurrent work (안봐도 됨)
- 나중에, 읽을만한 논문 탐색용으로 보자.
- 동시에 여러 접근법이 3D 장면 이해를 위해 2D 기초 기능과 인터페이스를 시도하고 있습니다.
- CLIP-Fields는 3D 맵과
픽셀(또는 영역) 정렬된 기초 기능(LSeg [24], Detic [41], Sentence-BERT [42])을 압축 신경망에 인코딩합니다[43].- 이 장면 특정 신경망은 이미지 및 언어 임베딩을 3D 장면 포인트와 정렬하는 질의 가능한 데이터베이스 역할을 하며, 언어로 지정된 개방형 질의에 적용될 수 있습니다.
- 새로운 CLIP-Field는 장면마다 훈련되며, 학습된 CLIP-Fields가 새로운 장면이나 장면 내 변화에 대해 일반화할 수 있을지는 아직 탐구되지 않았습니다.
- VLMaps [44], LM-Nav [45], CoWs [46], NLMap-Saycan [47]은 로봇 내비게이션을 위해 언어 명령에 기반한 픽셀 정렬된 LSeg [24] 모델의 개방형 기능을 활용
- 최근 OpenScene [48]은 픽셀 정렬된 LSeg [24]와 OpenSeg [18]을 개방형 3D 분할에 적용하여 이러한 2D 추출기의 기능을 3D 데이터에서 작동하는 신경망에 증류할 수 있음을 보여주었습니다.
- Ding et al. [49]은 이미지 캡셔닝과 같은 더 복잡한 2D 개방형 작업의 기능을 3D 데이터를 소비하는 모델에 증류합니다.
- 위의 접근법들과의 근본적인 차이점은, 우리는 매핑 과정과 동시에 2D 및 3D 기능을 제로샷으로 구축할 수 있으며, 미세 조정이나 증류가 필요 없다는 점을 증명한다는 것
- Mazur et al. [50]의 최근 접근법은 DINO [7]와 같은 이미지 기초 모델의 기능을 실시간으로 융합하여 압축 3D 신경 맵을 생성
- 우리의 접근법은 이 정신에서 개방형이지만, 언어 및 오디오와 같은 여러 모달리티로 확장되며 CLIP에서 픽셀별 기능을 추출하는 새로운 방법을 제시합니다.
- 아마도 우리 접근법과 가장 가까운 것은 Ha와 Song [51]의 의미적 추상화일 것입니다.
- 이 접근법 역시 3D 정렬된 CLIP 기능을 계산하는 제로샷 접근법을 제안합니다.
- 그들은 텍스트 질의와 관련된 영역을 추출하기 위해 주목성 설명 가능성 [52]이라는 다른 메커니즘을 탐구하며, 부분적으로 관찰된 객체의 완성, 언어 설명에서 숨겨진 객체의 위치 지정과 같은 보완적인 기능 세트를 보여줍니다.
- 자세한 내용은 [51]을 참조하십시오.
- 이 작업에서는 다양한 3D 인지 및 로봇 공학 작업에 대해 CLIP 기능을 이미지 픽셀에 무조건적으로 할당하고 이후 3D 맵에 할당하는 데 중점을 둡니다.
- 최근 제안된 접근법인 3D-CLR [53]은 3D 장면에서 개념 학습을 위한 신경 연산자를 제안합니다.
- 이는 3D 공간 질의 모듈 설계에 영감을 주지만 중요한 차이가 있습니다.
- 우리는 기초 모델 기능을 제로샷 방식으로 3D로 올려 모델이 갖추고 있는 모든 기능을 보존하는 반면, [53]은 LSeg [24]에 의존합니다.
4. THE ConceptFusion APPROACH
4.0.1. The open-set multimodal 3D mapping problem
- Given a sequence of image (and depth) observations
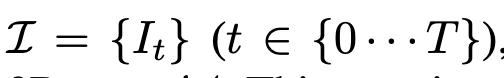
- open-set multi-modal 3D map M을 만드는 것이 목표
- 이 3D 지도에
다양한 modality 질문(요청)을 할 수 있다!- 예: 이미지, 텍스트, 오디오, 마우스 클릭
다양한 modality 질문(요청)은 query vectors 로 표현된다.- modality-specific encoder (a foundation model)
F_mode을 이용해서, query vectors을 구함 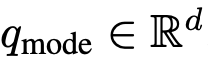
- modality-specific encoder (a foundation model)
4.1. Fusing pixel-aligned foundation features to 3D
4.1.1. Map representations
- 3D map M은, 순서 정렬되지 않은 points이다. (indexed by k)
- 각 point는 아래 정보를 가지고 있다.
- TODO: 아래 질문에 답할 수 있도록 하기
- depth image로부터 vertex position을 구한다는건, mesh 형태로 표현했다는 뜻인가?
- normal vector를 저장한다는 것은, mesh 형태로 표현했다는 뜻인가?
- voxel이 아니고, point인데 어떻게 normal vector이 있지?
- confidence count? 점에 대한 확신의 정도를 어떤 방식으로 구했을까?

4.1.2. Frame pre-processing
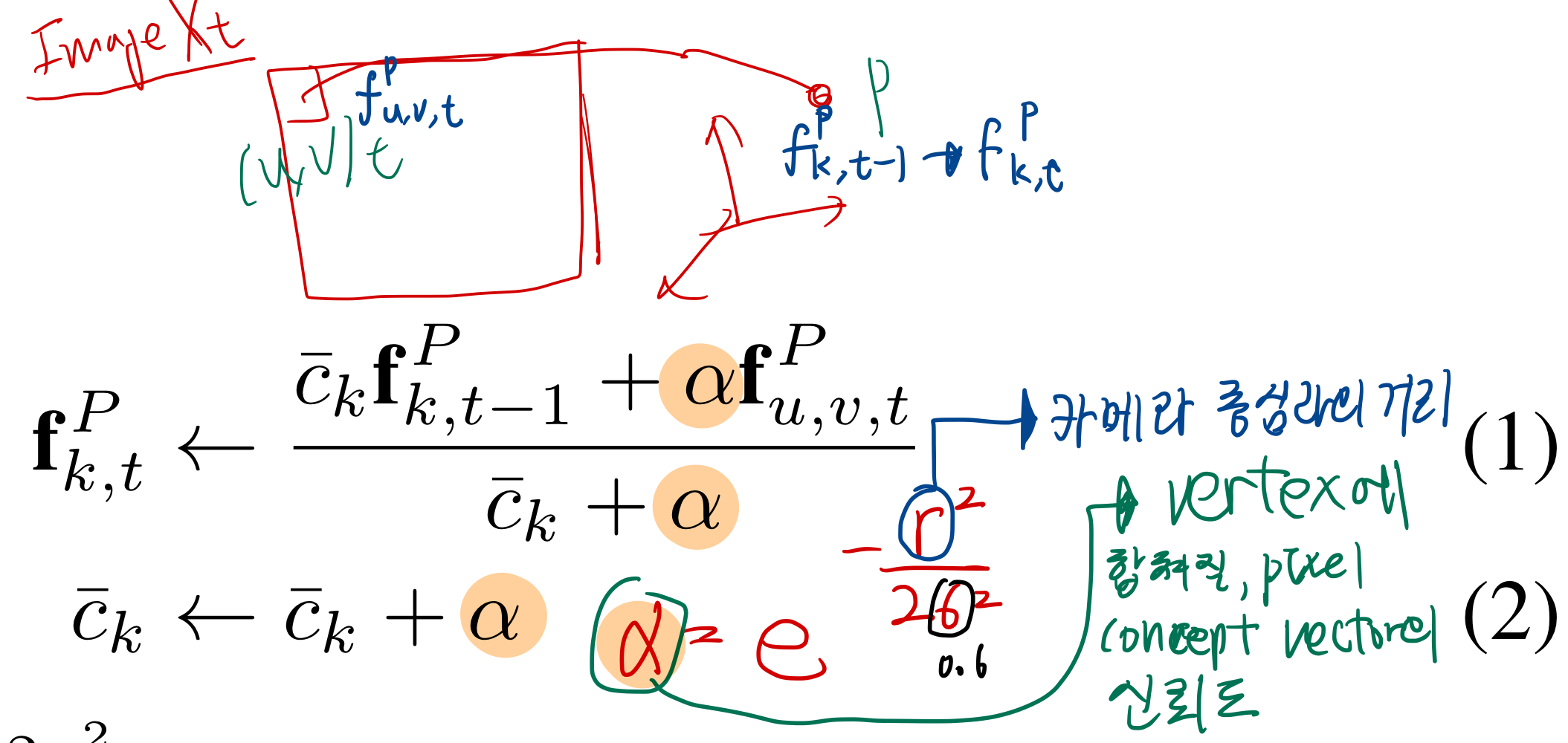
- 각 Image It (color image Ct + depth image Dt)에 대해,
vertex-normal maps (Vt , Nt )와camera pose estimates Pt를 구함 [30, 54].- TODO: 위 부분 어떻게 진행하는 것인지 공부하기
- 각 픽셀에 대해,
semantic context embedding을 계산함. (뒤에 나옴)
4.1.3. Feature fusion
- 3D reconstruction pipeline으로, [30]을 따랐음.
- 먼저, camera pose Pt를 이용해서, vertex 와 normal map을 세계 좌표계로 좌표변환함
- [30]의 depth amp fusion 과정에 나와있는대로, noisy depth points를 제거함
- concept vectors을 3D 공간에 투영하는 과정?
4.2. Computing pixel-aligned features
- LSeg (https://velog.io/@jk01019/LSeg) 와 OpenSeg 논문들이, CLIP같은 foundation model 을 기반으로 하긴 했지만,
- 그들은 pixel level segmentation이 목적이었기 때문에, 라벨링된 image-text data에서의 fine-tuning이 필요했다.
- 그 side effect로, fine-tuning dataset에 없었던 concept에 대해서는 잘 segment 해주지 못하는 문제가 발생했다.
- generality가 증가된 pixel level feature을 확보하기 위해, 아래의 목표를 달성하는 새로운 알고리즘을 제안함.
- CLIP 기반의
global (image-level) context와local (region-level) information을 융합한,pixel-aligned feature을 구축
- CLIP 기반의
4.2.1. Overview
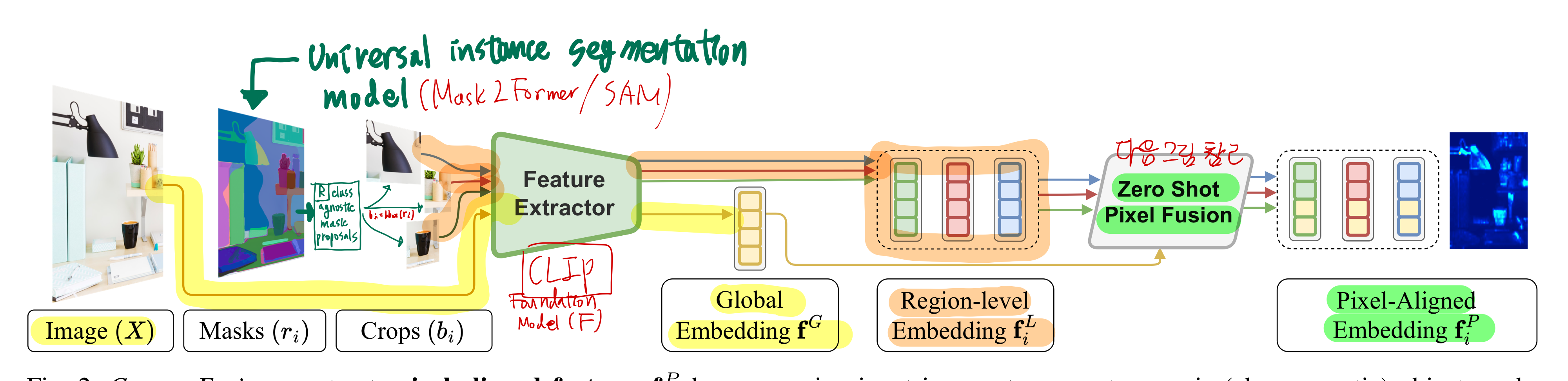
4.2.1. Local embeddings
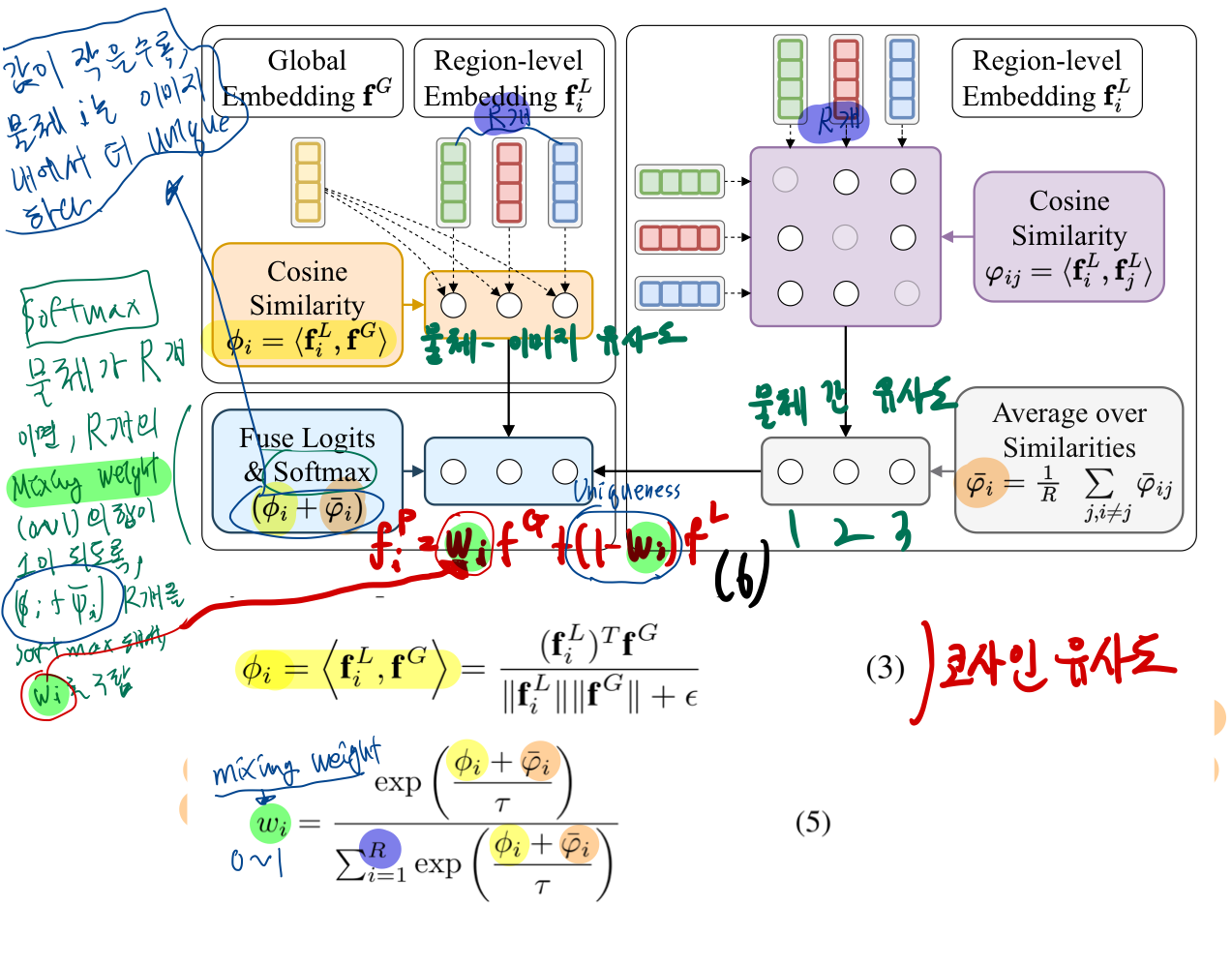
4.2.2. Fusing local and global features
- 요약:
pixel-aligned feature을 구할 때,global feature과local feature을 적절한 비율로 섞어서 만들고 싶다.- pixel 영역에 위치한 물체가
유니크할수록,local feature을 더 많이 반영하자는 아이디어!
- pixel 영역에 위치한 물체가
- weight 구하는 법 (유니크함 정도 측정법)
- 물체 i에 대해,
이미지 전체와의 유사도+다른 물체들과의 유사도를 더한다. - 이 값이 작을수록, 더
유니크하다
- 물체 i에 대해,
- 물체 ri (bounding box) 에 해당하는 pixels의
pixel-aligned feature은- normalized되어, 각 (u,v) pixel에 매핑된다.
- 즉, 이미지의 각 픽셀이 여러 물체의 (bounding box)에 매칭되는 것이 허용된다.
- 각 픽셀에, 새
pixel-aligned feature가 축적될 때마다 normalized 된다.
- 각 픽셀에, 새
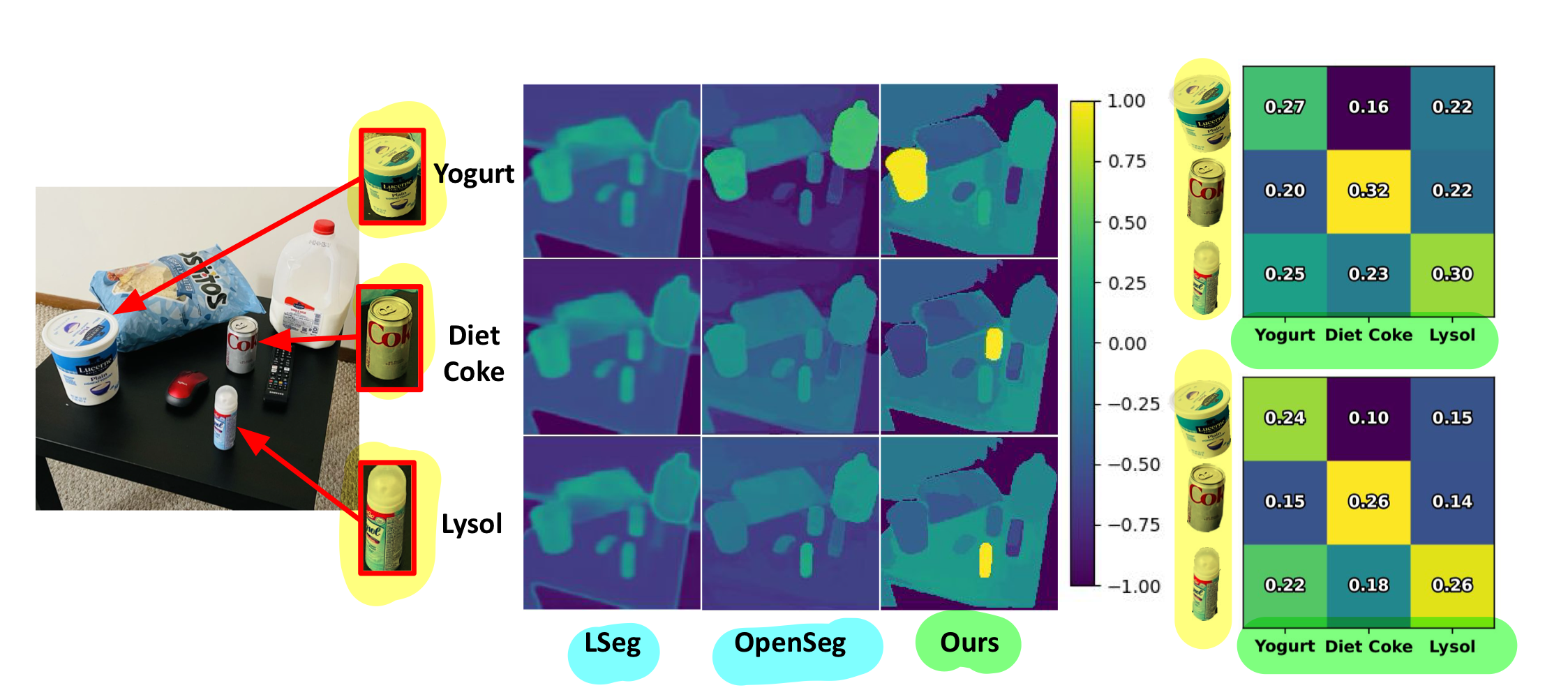
4.2.3. Capturing long-tailed concepts
- 우리는 우리의
pixel-aligned embedding이 (LSeg [24]와 OpenSeg [18]과 같은 접근법보다 더 잘) 세밀하고 롱테일 개념을 캡처한다는 것을 발견 - 우리는 (LSeg와 CLIP 모두에서 사용된) 기본 백본 CLIP 모델이 다이어트 콜라, 라이솔, 요구르트 등의 개념을 알고 있지만,
- fine tuning된 (pixel-aligned) 모델들은 그렇지 않다는 것을 발견
LSeg [24]와 OpenSeg [18]과 같은 접근법들은- 더 작은 라벨이 붙은 데이터셋을 통해 CLIP 기능을 픽셀에 정렬합니다.
- LSeg와 OpenSeg는 segmentation 능력을 얻기 위해, 제한된 개념을 가진 데이터셋에서 fine tuning이 필요합니다.
- 그러나 이 fine tuning 과정은 롱테일 및 세밀한 개념에 대한 제로샷 일반화 능력을 저해
- 반면에, ConceptFusion은 기초 기능을 픽셀 및 3D 포인트에 매핑하는 새로운 방법을 제시하여
- 제로샷 상태를 유지하고 롱테일 개념을 해당 픽셀에 정확히 정렬
4.3. Multimodal querying over 3D feature-fused maps

- 이 유사도들은, 아래의 방법들로 post-processing 할 수 있다.
- thresholding based on score
- non-maxima suppression
- TODO: NMS는 "여러 개의 겹치는 bounding box를 하나로 취합하는 법"인데, 여기서는 어떻게 쓰였을까?
- (optionally) clustering to produce 3D regions of interest
4.4. Building complex 3D spatial query modules
fusing features를 3D 공간에 융합함으로써 얻을 수 있는 기능들- 이미지에서 결코 함께 관찰되지 않은 객체에 대해 추론하는 능력과
- 3D 표현에서만 접근 가능한 공간 속성(예: 상대 위치, 방향, 지지, 포함 등)에 대해 추론하는 능력
- 이를 구현하기 위해, 우리는 계산된 유사성 점수를 활용하여, 더 복잡한 속성을 도출할 수 있는
3D spatial comparator(3DSC) 모듈을 만들었음
우리의 3DSC 세트는 모두RELATION(QUERYa, QUERYb)형태를 가지며,- 적절하게 스칼라 또는 불리언 값을 return
- 전체 3DSC 세트는 아래 2가지를 포함합니다(자세한 내용은 부록 참조).
- HOWFAR(qa, qb)
- 3DSC는 질의 qa와 qb에 의해 참조된 객체 간의 거리를 반환
- 불리언 3DSC:
- ISTOTHERIGHT(qa, qb), ISTOTHELEFT(qa, qb), ONTOPOF(qa, qb), UNDER(qa, qb)
- 질의 qa와 qb에 의해 참조된 객체가 적절한 공간 관계(지정된 보기 방향에 대해)를 만족하는지 여부에 따라 TRUE 또는 FALSE를 반환
- HOWFAR(qa, qb)
- 섹션 6에서는
language queries를적절한 3DSC 조합으로 parsing하기 위해- LLM을 채택합니다.
- 예를 들어, "냉장고와 텔레비전 사이의 거리는 얼마인가?"라는 질의는 HOWFAR(refrigerator, television)로 parsing됩니다.

- 그러나, 특별히 명시되지 않은 한, 이 논문에 제시된 모든 결과에 대해
language queries는 사전 처리 없이 직접 CLIP 텍스트 인코더에 입력됩니다.
4.4.1. Implementation details
- 우리의 feature fusion algorithm 은 ∇SLAM [60] dense SLAM 시스템 위에 구현
- 이는 PointFusion 알고리즘 [30]의 몇 안 되는 구현 중 하나였으며,
- foundation features을 계산하고 접근하기 위해 PyTorch와 인터페이스하는 편리함 때문에 썼습니다.
- 클래스 무관(일반) 객체 마스크를 생성하기 위해, 우리는 카테고리 무관 인스턴스 분할을 위한
Mask2Former[60] 또는segment anything (SAM)[57] 모델을 사용 - Mask2Former를 사용할 때는 이미지당 100개의 마스크 제안을 생성
- SAM을 사용할 때는 마스크 제안의 중복성이 상당히 낮음을 발견하여, Eq. 4의 고유성 항을 삭제
- 객체 후보군끼리의 유사도를 계산하여, weight에 반영했던 것을 폐지
- 우리의 오도메트리 및 매핑 접근법은 프레임 속도(15Hz)로 실행
- 픽셀 정렬 기능 추출 과정은 NVIDIA RTX 3090 GPU에서 오프라인으로 실행되며(
이미지당 10-15초 소요) 실행됩니다.
4.4.2 Real-time inference
- SAM [57], DINO [7], CLIP [6] 등 사용된 foundation models의 성능과 효율성을 최적화하기 위해, 우리는 standard quantization 및 tracing 방법을 사용
- 양자화 및 추적 기술을 모델에 적용함으로써, 정확성을 손상시키지 않으면서 효율성을 크게 향상
- 이를 통해
메모리 및 런타임 효율성이 중요한 실제 시나리오에 모델을 배포할 수 있음
5. Case Studies
- 우리는 다음 질문들을 조사하기 위해 체계적인 실험 연구를 설계했습니다:
- 1) 텍스트, 이미지, 클릭 또는 오디오를 사용하여 질의할 때, 오픈셋 멀티모달 3D 맵은 어떻게 작동하는가?
- 2) 3D로 임베디드된 풍부한 개념 공간을 공간적 추론에 어떻게 활용할 수 있는가?
- 3) ConceptFusion이 실제 로봇 작업에서 얼마나 잘 작동하는가?
- 4) ConceptFusion이 가능하게 하는 이전에는 불가능했던 다운스트림 사용 사례는 무엇인가?
5.0.1. 실험 설정
- 우리의 실험 벤치마크는 여러 공개 데이터셋에서 가져온 시퀀스와 우리가 수집한 시퀀스로 구성됩니다.
- 벤치마크는
ScanNet[61, 62],Replica[63], 및 자가 촬영 시퀀스에서 가져온 20개의 실내(아파트 규모) 장면; 5개의 실외(도시 운전) 장면; 일반 가정용 제품이 있는 20개의 실내(테이블탑) 장면(UnCoCo);- 그리고 ICL [64] 및 iTHOR 벤치마크 [65]에서 가져온 5개의 합성 장면을 포함
5.1. Multimodal queries on the UnCoCo dataset
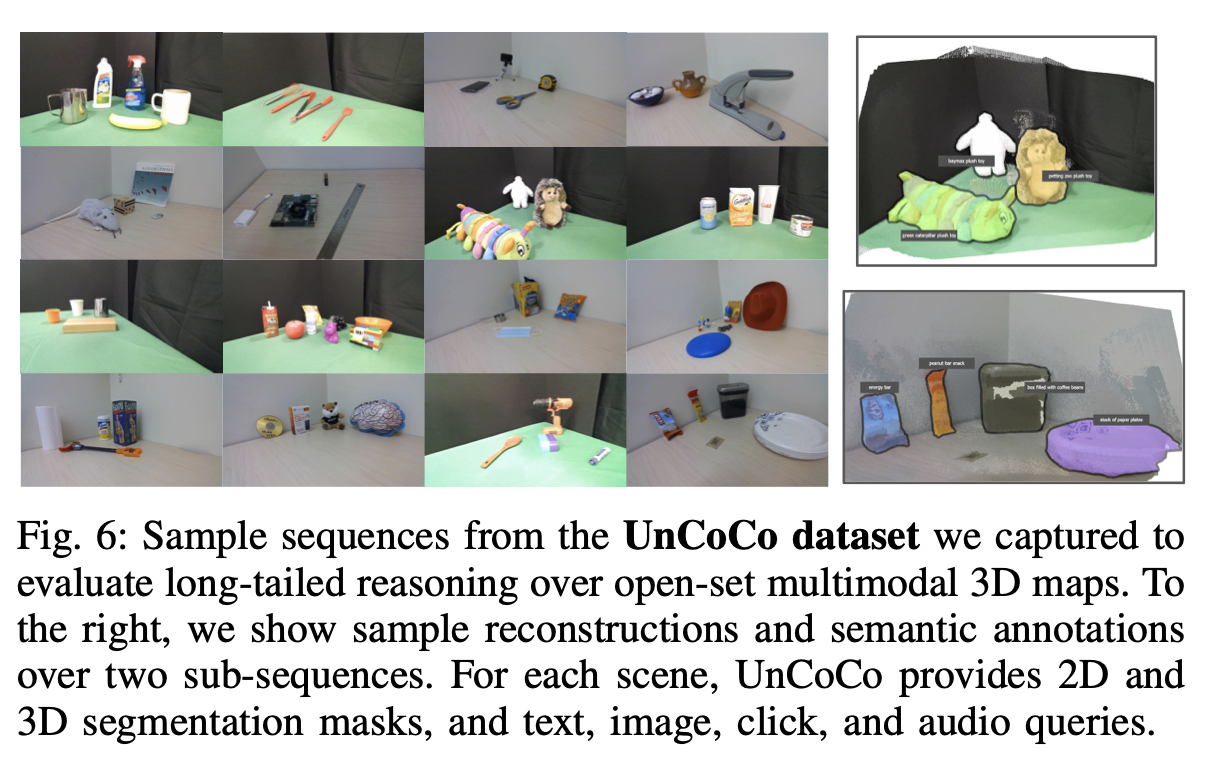
- UnCoCo: 이 격차를 극복하기 위해, 우리는 UnCoCo(Uncommon contexts for Common Concepts)라는 자체 데이터셋을 캡처했습니다. 이 실제 데이터셋은 테이블탑 표면에 있는 78개의 흔히 볼 수 있는 가정 및 사무실 물체의 3D 스캔으로 구성되어 있습니다(Fig. 6 참조). 총 12075개의 컬러 및 깊이 이미지 쌍을 포함한 20개의 RGB-D 이미지 시퀀스가 있습니다. 각 이미지에는 객체별 2D 인스턴스 분할 마스크를 제공하며, 각 장면에는 해당 3D 분할 마스크를 제공합니다. 중요한 것은, UnCoCo는 텍스트, 클릭, 이미지 및 오디오 등 다양한 질의 모달리티를 지원한다는 점입니다.
7. Conclusions
7.1. 한계
- 우리의 방법의 주요 한계는 세 가지로 나뉩니다.
- 첫째, ConceptFusion은 밀집 맵을 통해 작동하며, 종종 아파트 규모의 장면에서
수백만 개의 3D 포인트를 포함하고각 포인트에 고차원 개념 임베딩을 추가하여 대량의 메모리를 필요로 합니다. - 둘째, 우리의 픽셀 정렬 기능은 주로 background 객체에 초점을 맞추고 있으며, 구성력을 결여하고 부정 개념을 이해하지 못합니다.
- 이러한 단점을 완화하는 연구 노력 [73, 74]이 탐구될 가치가 있습니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.