reference
Introduction
- 기존 연구들
- 잠재적으로 픽셀에 할당될 수 있는
제한된 semantic 클래스 레이블 집합을 가정 - 클래스 레이블 수: 학습 데이터셋에 따라 결정되며 일반적으로 수십에서 수백 개의 카테고리
- 잠재적으로 픽셀에 할당될 수 있는
- 학습 데이터셋을 생성하려면, 사람이 직접 수천 개의 이미지에 있는 모든 픽셀을 semantic 클래스 레이블과 연결해야 함
- 이는 매우 노동 집약적이고 비용이 많이 드는 작업
- 사람이 세밀하게 후보 레이블을 인식해야 하므로 레이블 수가 증가함에 따라 주석의 복잡성이 크게 증가
- 해결책? zero-shot 및 few-shot semantic segmentation 방법이 제안
- Zero-shot 방법은 일반적으로 단어 임베딩을 활용하여, 추가 주석 없이 알고 있는 클래스와 처음 보는 클래스 간의 관련된 feature들을 검색하거나 생성
- 기존 zero-shot 연구들은 표준 단어 임베딩을 사용하고 이미지 인코더에 중점을 둠
- 본 논문에서는
- 언어 모델을 활용하여, semantic segmentation 모델의 유연성과 일반성을 높이는 간단한 접근 방식을 제시
- CLIP과 같은 시각적 데이터에 대해 공동 학습된 SOTA 텍스트 인코더를 사용하여 -> 학습 세트의 레이블을 임베딩하고
- 이미지 인코더를 학습시켜 픽셀별 임베딩을 생성
- 텍스트 인코더는 관련된 개념에 가깝게 임베딩되도록 학습되었기 때문에
- 제한된 레이블들에 대한 학습만으로 -> 텍스트 인코더의 유연성을 이미지 인코더로 이전할 수 있다.
- 예측을 공간적으로 정규화할 수 있는 출력 모듈을 추가로 도입
Language-driven Semantic Segmentation
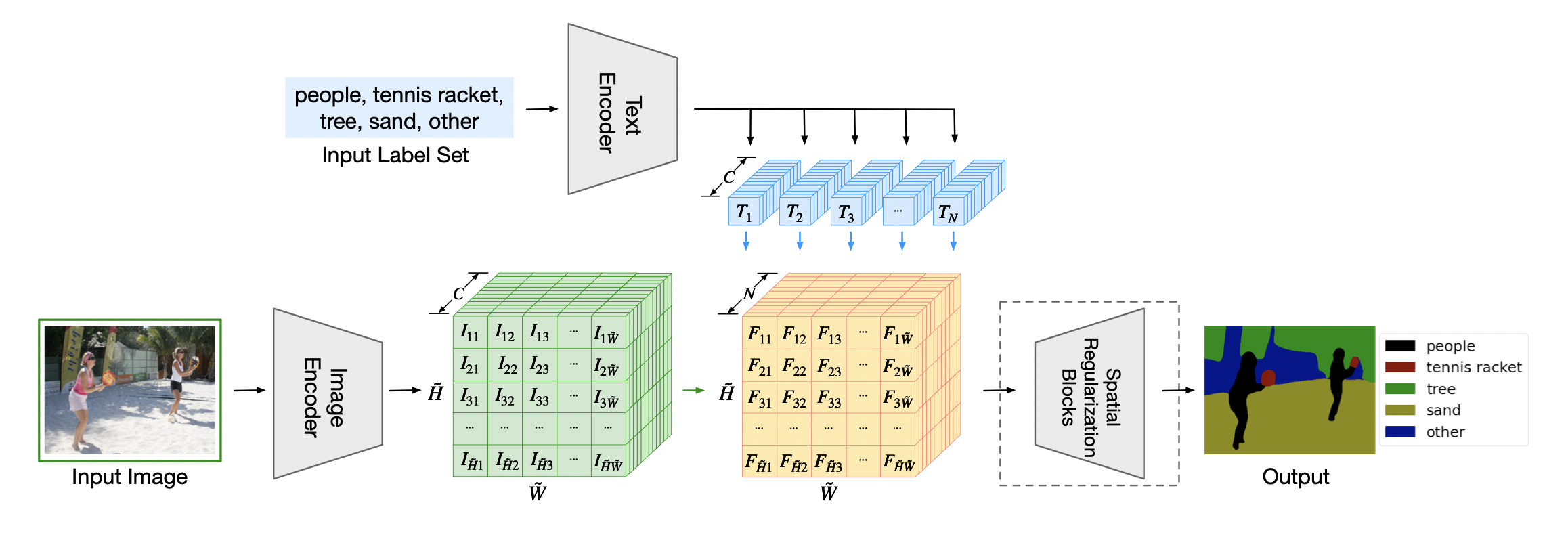
Text encoder
- 여러 아키텍처가 가능하며 사전 학습된 CLIP을 사용한다.
- 설계상 출력 벡터들은 입력 레이블의 순서에 영향을 받지 않으며 N이 자유롭게 변경될 수 있다. ( N= words의 총 개수)
Image encoder
- 이미지 인코더는 모든 입력 픽셀에 대해 임베딩 벡터를 생성한다.
- Dense Prediction Transformer (DPT)를 기본 아키텍처로 활용한다.
- ViT의 공식 ImageNet pretrained weight를 사용하여, 이미지 인코더의 backbone을 초기화
- DPT 디코더를 랜덤으로 초기화
- 학습 중에는, text encoder를 고정하고, 이미지 encoder만 업데이트
Word-pixel correlation tensor
- 위 그림의 노란색

Spatial Regularization
- 위 그림의 마지막 Layer
- 메모리 제약으로 인해 이미지 인코더는, 입력 이미지 해상도보다 낮은 해상도에서 픽셀 임베딩을 예측
- 따라서 예측을
원래 입력 해상도로 공간적으로 정규화하고업샘플링하는 추가 후처리 모듈을 사용 - 이 프로세스 동안, (위 그림의 노락색 벡터 생각해봐!) 모든 연산이 label과 관련하여 동등하게 유지되도록 해야 함
- 즉, 입력 채널 사이에는 상호 작용이 없어야 하며, 그 순서는 단어의 순서에 따라 정의되므로 임의적일 수 있다.
- 따라서 예측을
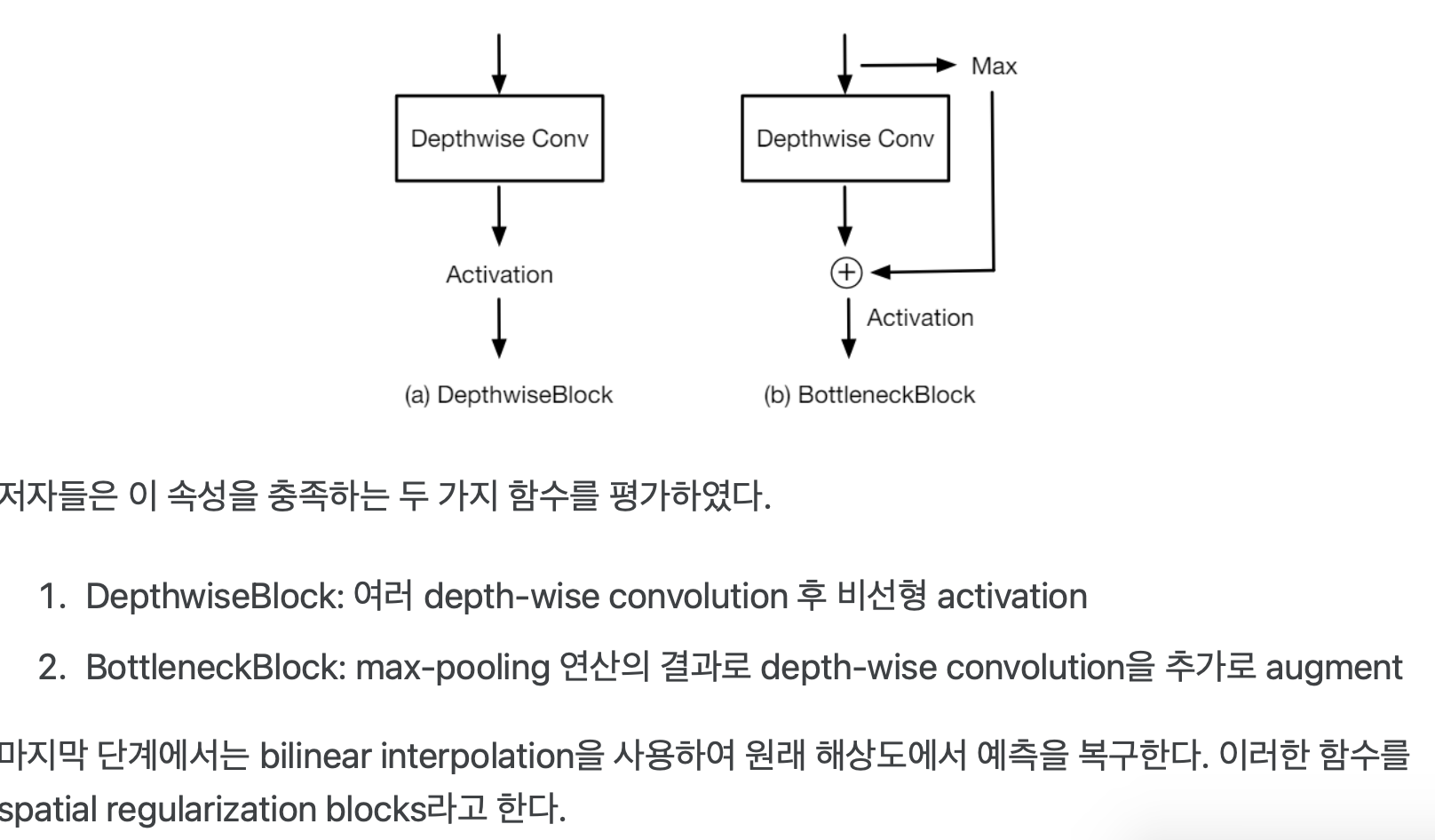
- depthwise-convolution: https://velog.io/@jk01019/depthwise-convolution

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.