- Hydra: A Real-time Spatial Perception System for
3D Scene Graph Construction and Optimization - https://arxiv.org/pdf/2201.13360
- https://github.com/MIT-SPARK/Hydra
리뷰
1. 특징
- 3D semantic 지도를 생성하는 것 뿐만 아니라,
- 물체에 대한 3D bounding box와 중심점도 도출가능
- 실내 공간의 방을 구분 가능
- 위 계층적 지도를 online으로 구축 가능
-1.2. Dataset
- 시뮬레이터
- Matterport3D : https://github.com/niessner/Matterport
- uHumans2 : https://web.mit.edu/sparklab/datasets/uHumans2/
- 실세계
- SidPac
- Simmons
- Stanford3D
0. abstract
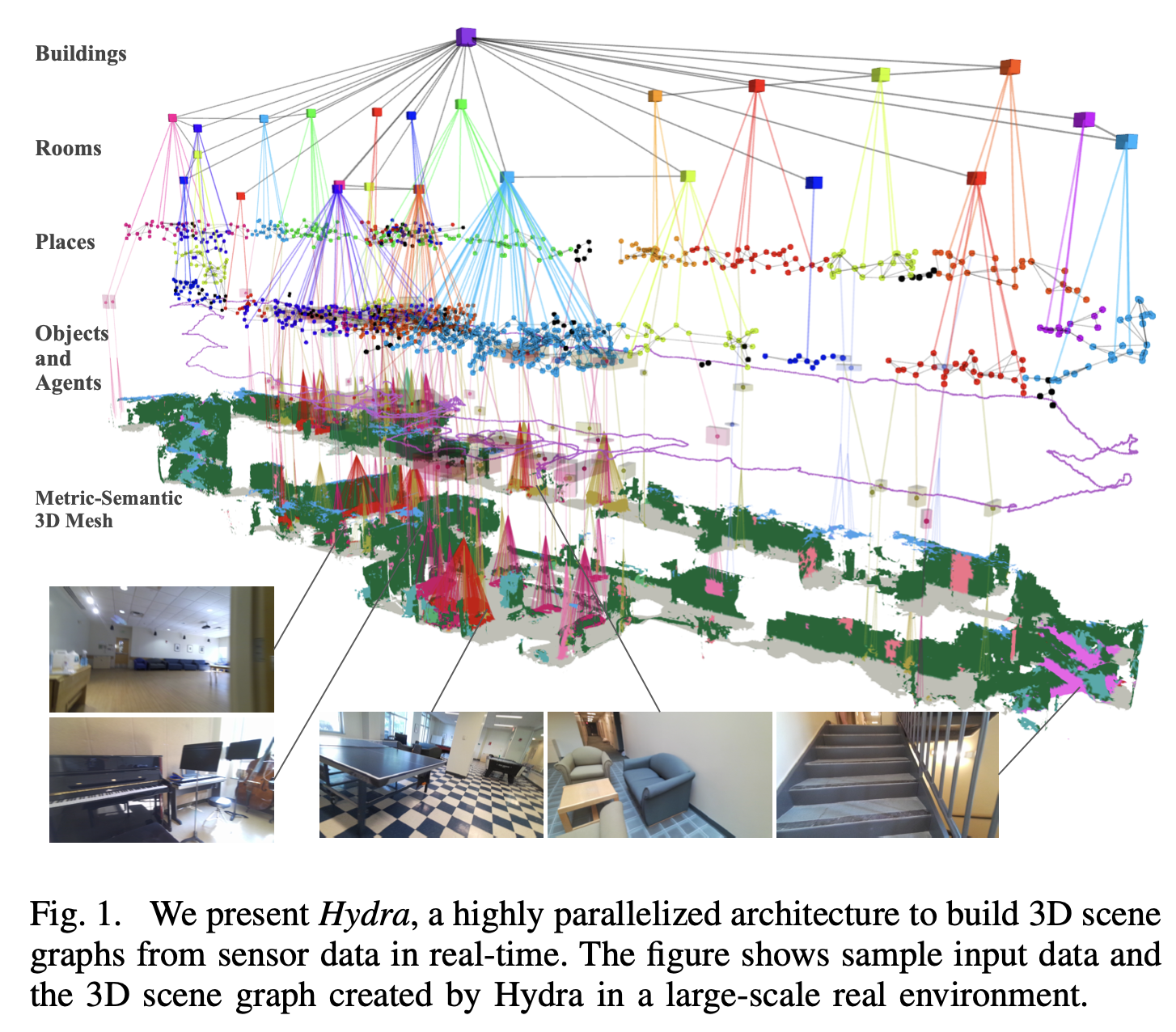
- 이 논문은 카메라 + IMU + Odomtry 를 사용하여, 실시간으로 3D scene graph를 구축하기 위한 알고리즘 모음을 설명
- 첫 번째 기여:
- 3D scene graphs의 계층을 점진적으로 구축하기 위한
실시간알고리즘을 개발
- 3D scene graphs의 계층을 점진적으로 구축하기 위한
- 두 번째 기여
loop closure detection and optimization in 3D scene graphs를 개발- 3D scene graph는, 계층적으로 구성되어 있기 때문에, (정보가 많아서)
loop closure detection에 훨씬 유용하다!
- 그런 다음 우리는
loop closures 결과를 기반으로, 3D scene graph를 최적화하는 최초의 알고리즘을 제안- 우리의 접근 방식은
embedded deformation(변형) graphs에 의존하여 scene graph의 모든 계층을 동시에 수정
- 우리의 접근 방식은
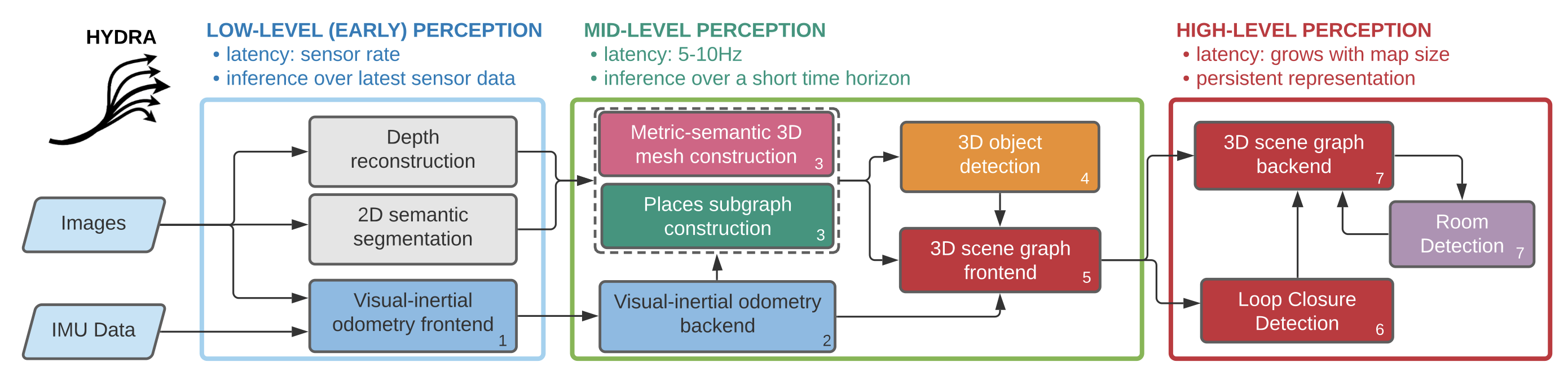
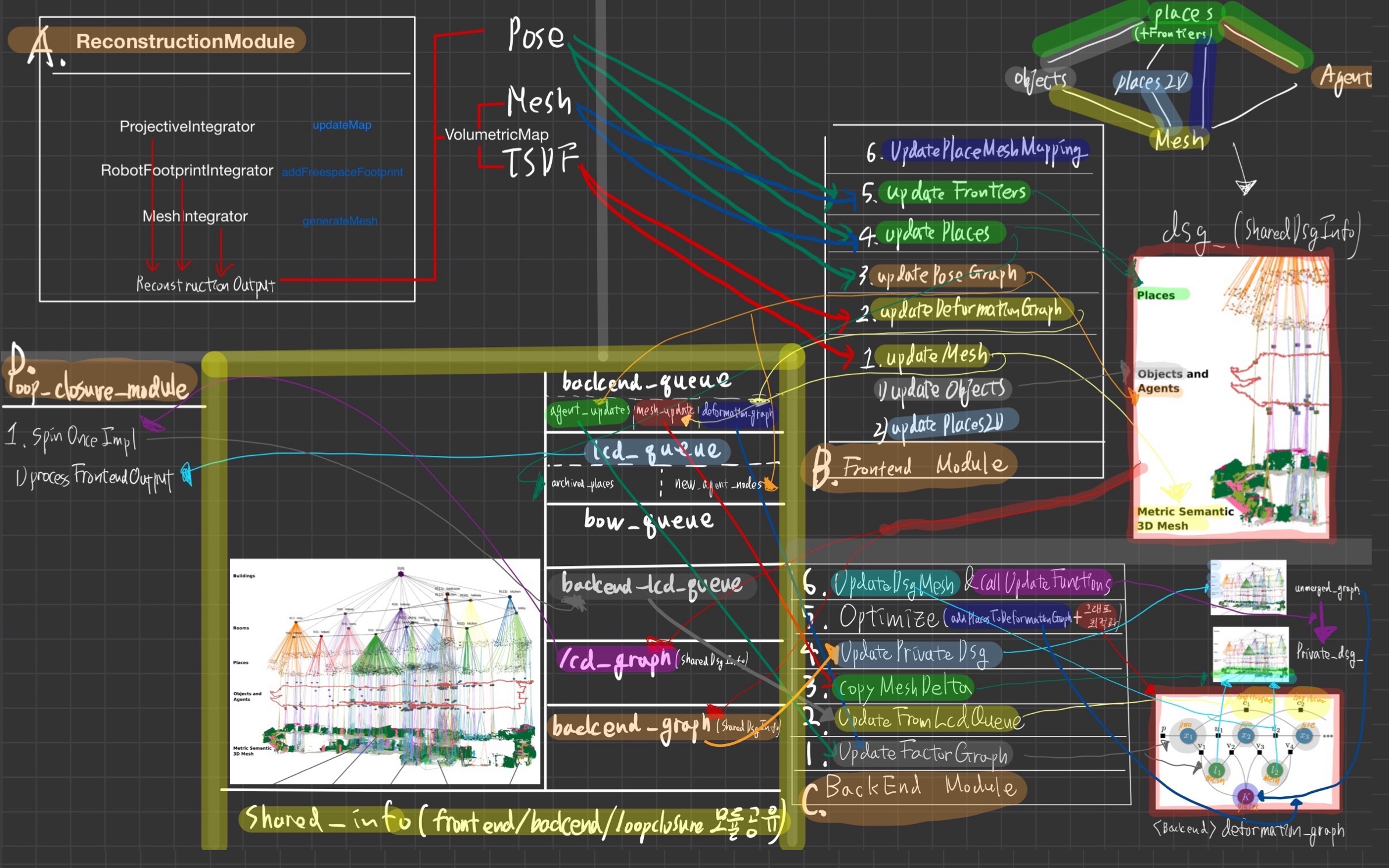
- 우리는 제안된 Spatial Perception System을 Hydra1이라는 고도로 병렬화된 아키텍처에 구현하여,
fast early and mid-level perception processes (e.g., local mapping)를slower high-level perception (e.g., global optimization of the scene graph)과 결합- 아래에 자세한 설명이 나오니, 지금 위 다이어그램을 전부 이해할 필요는 없다.
- 우리는 Hydra를 시뮬레이션 및 실제 데이터로 평가하여
- 온라인으로 실행됨에도 불구하고
- 배치 오프라인 방법과 대적할만한 정확도로 3D scene graph를 구축/유지보수 할 수 있음
- 우리는
다양한 환경(아파트 단지, 사무실 건물, 지하철)에서 Hydra를 평가했음
3. introduction
- 과거 연구들은
환경 전체의 ESDF를 사용하여 3D 씬 그래프를 구축하는데,- ESDF의 메모리 요구 사항은 환경의 크기에 따라 비례하여 증가
- 과거 연구에서, ESDF는
루프 클로저에 따라 변경되는 로봇의 trajectory 추정에서 재구성- 즉, 루프 클로저가 감지될 때마다 ESDF를 다시 계산해야 하며,
- 이는 로봇의 위치와 자세가 변경되기 때문에 필수적인 과정
- 실시간 작동의 문제점
- 루프 클로저가 발생할 때마다 ESDF를 재구성하고, 3D 씬 그래프를 새로 구축하는 과정은 많은 계산 자원과 시간이 필요
- 결과적으로, 이는 실시간으로 작동해야 하는 로봇 시스템에 부적합할 수 있음
- 이 논문의 주요 동기: 센서 데이터로부터 실시간으로 계층적 3D 씬 그래프를 구축
- 첫 번째 기여:
로봇이 환경을 탐색하면서, 씬 그래프의 레이어를 점진적으로 재구성하는 실시간 알고리즘을 개발하는 것- 이 계산은 환경의 크기에 관계없이 일정 시간 내에 실행
- 우리의 두 번째 기여는
3D scene graph의 루프 클로저 감지 및 최적화를 연구하는 것 - 우리는 루프 클로저를 감지하는, (
계층적 디스크립터를 사용) 새로운 계층적 접근 방식을 제안- 먼저, 현재 검지한 주변의 place 그래프(계층 3)와 서버에 저장된 공간 그래프의 유사도를 비교하고, 유사하면
- 현재 검지한 주변의 object의 여러 class 별 분포(계층 2)를, 서버의 그것과 비교하고,
- 현재 검지한 이미지 frame과 서버의 그것을 비교
- 그런 다음, 우리는
- 루프 클로저 결과에 응답하여, 3D 씬 그래프를 최적화하는 첫 번째 알고리즘을 제안
- 우리의 접근 방식은
- 임베디드 변형 그래프를 사용하여 scene graph의 모든 레이어(3D 메쉬, 장소, 객체 및 방)를 동시에 수정
4. related work
4.1. 메트릭-시맨틱 및 계층적 매핑.
- 전통적인 3D 재구성 및 SLAM 기법의 성숙도와
딥러닝이 제공하는 새로운 시맨틱 이해 기회로 인해 메트릭-시맨틱 매핑에 대한 관심이 최근 몇 년간 급증
객체 기반 지도 + 밀집 지도가, 객체와 전체 환경을 잘 재구성할 수 있지만,- 로봇이 탐색할 때 필요한 높은 수준의 공간 이해를 제공하는 데에는 한계가 있음
- 로봇의 효율적 탐색을 위해서는, 계층화가 필요하다는 뜻
- 객체 기반 지도와 밀집 지도:
- 객체 기반 지도:
개별 객체들을 중심으로 맵을 만드는 방식- 예를 들어 방 안의 책상, 의자, 컴퓨터 등을 각각 인식하고 이를 지도로 표현
- 밀집 지도:
환경 전체를 아주 세밀하게 3D 형태로 재구성- 예를 들어, 방 안의 모든 물체와 표면을 포함하는
포인트 클라우드나3D 메쉬로 표현
- 예를 들어, 방 안의 모든 물체와 표면을 포함하는
- 결합된 접근 방식:
- 일부 연구에서는 이 두 가지 방식을 결합
- 즉, 특정 객체들을 인식하면서도 전체 환경을 3D 형태로 자세히 재구성
- 탐색에의 한계:
- 그러나 이러한 밀집 지도나 결합된 지도는
고급 시맨틱 정보(예: 방의 위치나 구조)를 추정하지 않기 때문에, - 로봇이 실제 환경에서 효과적으로 탐색하는 데 어려움을 겪을 수 있습니다.
- 두 번째 연구 라인:
계층적 지도 모델 구축에 중점을 둠 - 초기 작업:
- 초기 연구에서는 주로
2D 지도에 초점을 맞췄음- 즉, 평면적인 지도로 환경을 표현했음
- 이 과정에서
메트릭 표현(정확한 거리와 위치 정보)과위상 표현(공간의 연결 관계)을 조화시키는 방법을 조사했습니다.
- 최근에는 3D 장면 그래프가 3D 환경에 대한 표현력 있는 계층적 모델로 제안
5. REAL-TIME INCREMENTAL 3D SCENE GRAPH LAYERS CONSTRUCTION
- 이 섹션에서는
- 로봇의 궤적 추정치(예: visual-inertial odometry)를 기반으로
3D 장면 그래프의 계층을 구축하는 방법을 설명
- 로봇의 궤적 추정치(예: visual-inertial odometry)를 기반으로
- 이후 섹션 IV에서는
루프 클로저에 대응하여 그래프를 수정하는 방법을 다룹니다.- 우리는 실내 환경에 중점을 두고 [49]에서 도입된
3D 장면 그래프 모델을 채택
- 이 모델에서
- Layer 1은 메트릭-시맨틱 3D 메쉬
- Layer 2는 객체와 에이전트의 서브그래프
- Layer 3는 장소의 서브그래프
- Layer 4는 방의 서브그래프
- Layer 5는 모든 방과 연결된 건물 노드
- 계층 1-3을 구축하고 장소를 방으로 분할하는 방법을 제시
5.1. A. 계층 1-3: mesh, objects 및 places
- current odometry estimates 를 기반으로, 1-3 계층을 build하는 방법을 소개하겠다.
5.1.1. Mesh(계층 1), Objects(계층 2), Places(계층 3)
5.1.1.1. Mesh(계층 1)
metric - semantic 3D mesh 의 실시간 구축은 Kimera[50]의 확장임- 작지만 중요한 변화가 있음
- Kimera
- Voxblox[43] 을 이용해서,
semantically labeled point clouds를,- TSDF와 ESDF로 통합
- 각 voxel의 semantic label에 대한 Bayesian inference도 추론
- Voxblox[43] 을 이용해서,
- Kimera와 현 논문의 다른점
- Voxblox [43]의 구현을 기반으로 하여
- TSDF와 ESDF를 공간적으로 윈도우링하고,
- 사용자 지정 반경(우리 구현에서는 8m) 내에서 로봇 주변의 볼륨 모델만 형성
- 이 반경은 ESDF가 사용하는 메모리 양을 제한하기 위해 선택됨
- 이 “active widnow” 내에서, 우리는 Voxblox의
marching cube구현을 사용하여, 아래 2개를 추출metric - semantic 3D mesh(계층 1)- places(계층 3)
- mesh들을 장애물로 생각하고 GVD를 돌려서 생긴 꼭지점들 = places
- 즉, 장애물과의 거리가 먼 지점들을 의미
- marching cube? : https://velog.io/@jk01019/Marching-Cube
- mesh와 place가 active window 밖으로 이동하면, 그것들은
3D scene graph frontend(섹션 IV)에 전달 - 우리는 또한
marching cube(metric - semantic 3D mesh 를 만드는데 씀) 을 수정하여- zero crossing에 해당하는
TSDF 복셀(즉, surface을 포함하는 복셀)을 라벨링 - 이러한 복셀을 "parent"라고 부르며, 해당 mesh 꼭지점들을 추적
- zero crossing에 해당하는
- 그런 다음, (가장 가까운 장애물까지의 거리를 이미 저장하고 있는)
각 ESDF 복셀에 대해,- 추가로 어떤 부모가 해당 복셀에 가장 가까운지를 추적
5.1.1.2. Objects(계층 2)
- “active widnow” 내에서 3D 메쉬를 추출한 후, 우리는 객체를 분할(3D 장면 그래프의 레이어 2)
- 이를 위해
metric - semantic 3D mesh의 꼭지점들을 유클리드 클러스터링- 특히, 각 세맨틱 클래스에 속하는 꼭지점들을 독립적으로 클러스터링
- Kimera 처럼
- 유클리드 클러스터링의 결과는 각 잠재 Object에 대한 중심점(centroid)과 bounding box를 추정하는 데 사용
- 점진적 작업 중에, 잠재 객체가
동일한 세맨틱 클래스의 기존 객체 노드와 겹치는 경우,- 새로운 mesh 꼭지점들을 이전 객체 노드에 추가하여 이를 병합
- 새로운 객체가 기존 객체 노드와 일치하지 않으면 새로운 노드로 추가됨
- 기준:
한 객체의 중심점이다른 객체의 경계 상자에 포함되는 경우 두 객체가 겹친다고 간주
5.1.2. Places (계층 3):
- Kimera에서는
- 환경의 단일 ESDF를 구축한 후 [44]를 사용하여 places subgraph(레이어 3)를 추출
- https://arxiv.org/pdf/1803.04345
- 2018년, 65회 인용
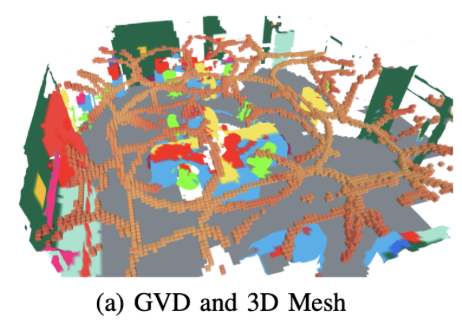
- 본 논문은, ESDF 통합 중에 실시간으로 구축된 일반화된 보로노이 다이어그램(GVD, 그림 2a에 표시)을 사용하여
- 점진적으로 places subgraph를 추출하는 접근 방식을 구현
- ESDF로부터 places를 추출할 때,
- parents voxel를 사용하여, 각 place를 3D 메쉬의 가장 가까운 꼭지점에 연결
- 즉, 각 place(계층3)과 가장 가까운 장애물 mesh(계층1)을 연결
- GVD는 적어도 두 개의 장애물("basis points" 또는 "parents")과 등거리인 복셀 집합
- basis points: mesh들 중 중요한 지점
- parents: mesh 위의 지점
- “active widnow” 내에서 ESDF 통합의 부산물로 GVD를 얻으며, 이는 [30]의 접근 방식을 따름
- 특히, GVD에 속하는 복셀은 ESDF를 업데이트하는 데 사용되는
브러쉬파이어 알고리즘의 파형으로 쉽게 감지할 수 있음
- 특히, GVD에 속하는 복셀은 ESDF를 업데이트하는 데 사용되는
- GVD가 업데이트될 때마다,
- 충분한 "basis points"(우리 구현에서는 3개)을 가진 GVD의 새로운 복셀 멤버를 반복 검사하여 노드나 엣지를 생성
- 즉, 3개 장애물로부터 같은 거리에 있는 GVD voxel이 place에 해당하는 노드나 엣지가 된다는 뜻!!
GVD 복셀을 Place 노드로 활용하고 엣지를 구성하는 과정
요약
- GVD 복셀 중 중요한 지점을 Place 노드로 간주해 연결 작업을 시작한다.
- 홍수 채우기 방식으로 복셀들을 그룹화(place와의 거리에 따른 clustering)하고, 각 그룹 사이에 가상의 엣지를 구성한다.
- 경로의 편차가 큰 지점에 노드를 추가하여 엣지를 분할하고 최적화한다.
- 최종적으로 연결되지 않은 노드를 제거하고 추가 엣지를 생성해 Subgraph가 연결되도록 보장**한다.
1. GVD 복셀을 Place 노드로 간주하는 조건
- GVD 복셀이 아래 조건을 만족하면 Place 노드로 처리:
- 4개 이상의 기준점(basis points)을 가지는 경우.
- 또는, 복셀 주변의 구조가 특정한 "코너 복셀 템플릿"과 일치하는 경우.
(이 템플릿은 복셀의 위치가 공간에서 중요한 경계를 형성하는지를 확인하는 데 사용됨)
2. 노드 간의 엣지(edge) 생성 단계
- 두 가지 단계를 번갈아 가며 실행하여 노드 간의 엣지를 식별하고 생성해.
-
단계 1: 홍수 채우기(Flood-fill) 방식으로 노드 연결
- GVD 복셀에 가장 가까운 Place 노드의 ID를 기록(레이블링)한다.
- 같은 Place 노드에 속하는 복셀들을 하나의 그룹으로 병합한다.
- 이 과정을 통해, 인접한 노드들 간의 가상의 엣지 집합을 생성한다.
- 예: ID 1번 Place 노드에 가까운 모든 복셀들을 하나의 클러스터로 묶고, 그 클러스터끼리 엣지를 연결.
- 홍수 채우기 과정에서는 연결된 인접 노드들을 병합하여 연결성을 높인다.
-
단계 2: GVD 복셀 편차에 따라 엣지 분할
- 두 노드 간의 직선 엣지가 경계를 벗어나는 경우:
- 가장 편차가 큰 복셀에 새로운 노드를 추가하고, 그 지점을 기준으로 엣지를 나눈다.
- 이렇게 하면, 노드 간의 연결을 더 정밀하게 구성할 수 있다.
- 두 노드 간의 직선 엣지가 경계를 벗어나는 경우:
3. 엣지와 노드의 최적화
- 두 단계를 여러 번 반복하여 최종적으로 식별된 엣지들을 sparse graph에 추가한다.
- 그 후, 연결되지 않은 노드들은 제거한다.
4. 추가 엣지 생성 및 Subgraph 연결
- 마지막으로, "active window"(활성 영역) 내의 연결되지 않은 구성 요소들 사이에 엣지를 추가한다.
- 이 과정을 통해, Place 노드들로 구성된 Subgraph가 끊기지 않고 모두 연결되도록 한다.
5.1.3. Room detection (layer 4)
- Kimera [50]의 방 탐지 접근 방식은 아래 이유로 인해, 임의의 건물(특히 다층 건물)에는 쉽게 적용되지 않습니다.
- 전체 환경의 부피 표현을 필요로 하며
- 방의 기하학적 특성(예: 천장 높이)에 대한 가정을 하므로
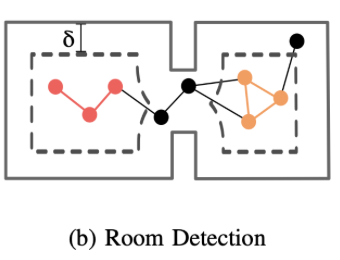
- 이러한 문제를 해결하기 위해, 우리는
place의 sparse sub graph(layer 3) Gp에서 직접 방을 분할하는3D scene graph의 레이어 4를 구축하는 새로운 접근 방식을 제시 - 이
place의 sparse sub graph(layer 3) Gp는- 섹션 III-A의 접근 방식에 의해 생성된 것이거나,
- 섹션 IV에서 설명된 대로 루프 클로저 후에 최적화된 것일 수 있습니다.
- 2가지 아이디어로 방 탐지를 해보자.
아이디어 1: voxel based 맵에서,팽창(dilation) 연산은 환경 내의 방을 드러내는 데 도움- 즉, 장애물을 팽창시키면, 환경 내의 작은 구멍(예: 문)이 점차 닫혀
- 복셀 기반 맵이 자연스럽게 분리된 구성 요소(즉, 방)로 분할됨
- 즉, 장애물을 팽창시키면, 환경 내의 작은 구멍(예: 문)이 점차 닫혀
아이디어 2:place의 sparse sub graph(layer 3) Gp의 각 노드는, 가장 가까운 장애물까지의 거리를 저장하고 있다는 점- 따라서 복셀 기반 맵에서의 팽창 연산은 Gp의 위상적 변화로 직접 매핑될 수 있습니다.
- 더 정확히 말하자면, 맵을 거리 δ만큼 팽창시키면, 장애물 거리보다 작은 모든 place(노드)는 그래프에서 사라집니다(더 이상 자유 공간에 있지 않기 때문입니다).
- place의 노드별로, 가장 가까운 장애물까지의 거리를 저장하고 있으므로,
- 거리가 δ 보다 작은 노드들은 사라진다!
- place의 노드별로, 가장 가까운 장애물까지의 거리를 저장하고 있으므로,
- 우리는 거리 δ를 증가시키면서 맵을 팽창시킵니다. (장애물의 크기를 팽창시킨다)
- (예: [0.45, 1.2]m 범위 내에서 균일하게 분포된 10개의 거리를 하나씩 선택하며 맵을 팽창시킴).
- 각 팽창 거리마다, 우리는 거리 δ보다 작은 노드(및 해당 엣지)를 제거하여 place sub-graph(Gp)를 가지치기합니다.
- 가지치기된 place sub-graph를 (Gp,δ) 라고 부릅니다.
- place sub-graph(Gp,δ) 에서 연결된 구성 요소의 수를 셉니다.
- 위 그림의 빨간색, 주황색 총 2개의 구성요소가 있음
- 직관적으로, 적절한 δ를 선택하면 연결된 구성 요소가 환경 내의 방에 해당
- 그런 다음, "10번 iteration하여 도출된 10개의
연결된 구성 요소의" 중간값 nr을 계산하여- δ 선택의 견고성을 확보하고,
- nr 개의 연결된 구성 요소를 가진 가장 큰 Gp,δ⋆ 를 선택합니다.
- nr개의 연결된 구성 요소를 가지게 하는 범위 내에서, δ 값을 가장 작게
- 마지막으로, Gp,δ⋆ 는 원래 그래프 Gp 의 일부 노드를 놓칠 수 있기 때문에,
- 이러한 라벨이 없는 노드들(위 그림의 검은색 노드들)을
부분적으로 초기화된 클러스터링 기법(partially seeded clustering)을 통해 할당
- 이러한 라벨이 없는 노드들(위 그림의 검은색 노드들)을
- 특히, 우리는 그래프의 각 노드를,
모듈성의 가장 큰 증가를 초래하는 커뮤니티(혹은 클러스터, 즉, 방)에 할당하려고 반복적으로 시도하는탐욕적 모듈성 기반 커뮤니티 탐지 접근(greedy modularity-based community detection) 방식을 사용합니다.- 모듈성(modularity)?
- 그래프의 모듈성이 크다는 뜻은
- 노드들이 클러스터(커뮤니티) 내에서는 밀집하게 연결되어 있고,
- 클러스터(커뮤니티) 간 연결은 낮은 상태
- 그래프의 모듈성이 크다는 뜻은
- 초기 커뮤니티(클러스터)는 Gp,δ⋆ 에서 감지된 연결된 구성 요소(위 그림의 빨간색,주황색)로 설정하고,
- 라벨이 없는 노드들(위 그림의 검은색)만 반복적으로 탐색
- 이는 정성적으로 일관된 결과를 생성하며,
- 관련 기술(예: 그래프 클러스터링에 인기 있는 방법인 스펙트럴 클러스터링은 Gp의 라플라시안의 고가 분해를 필요로 합니다)보다
확장성이 훨씬 뛰어납니다.
- 관련 기술(예: 그래프 클러스터링에 인기 있는 방법인 스펙트럴 클러스터링은 Gp의 라플라시안의 고가 분해를 필요로 합니다)보다
5.2. persistent representations: loop closure detection and 3d scene graph optimization
- scene graph를 이용해서 loop detection하는 방법
- loop closure을 찾은 후, scene graph를 보정하는 방법
5.2.A. loop closure detection and geometric verification
5.2.A.1. Top-down Loop Closure Detection
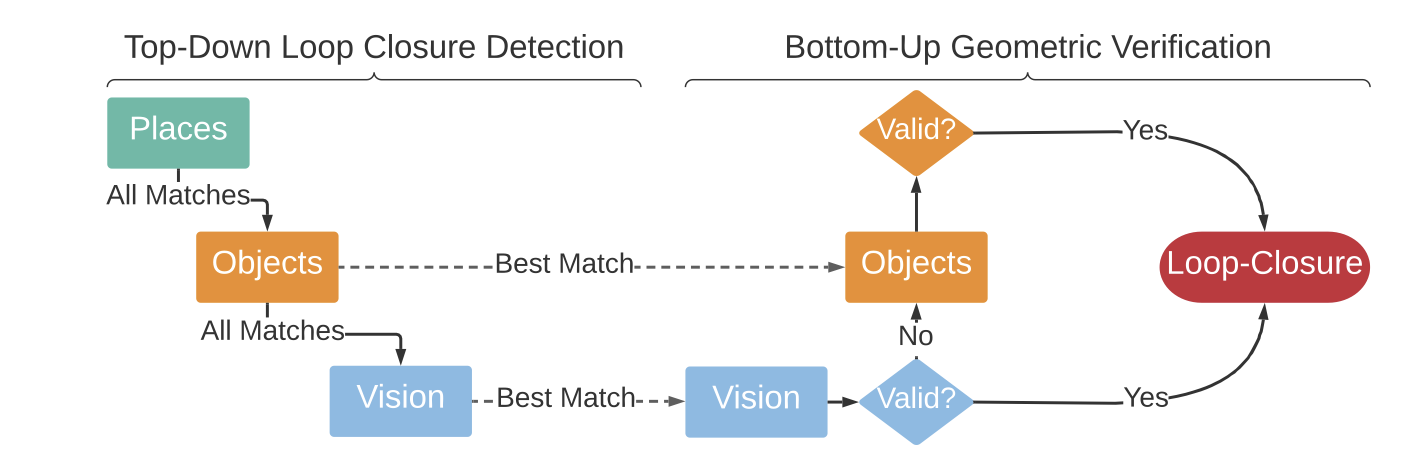
- 이 그림은 루프 클로저 감지 및 검증 과정을 단계별로 설명하여,
- 로봇이 동일한 장소를 여러 번 방문했을 때, 이를 인식하고 처리하는 방법을 보여줌
- 3D scene graph의 에이전트 계층(2 layer): 로봇의 trajectory를 설명하는 포즈 그래프를 저장
- 우리는 이 포즈를 에이전트 노드라고 부름
- 우리의 구현에서는 각 에이전트 노드에 대해 키프레임을 저장하며, 여기에서 appreance 정보를 추출할 수 있습니다.
- (key camera image frame을 노드마다 저장한다는 뜻인듯함)
- 루프 클로저 감지는
최신 에이전트 노드(현재 로봇 포즈에 해당하는)와 일치하는과거의 에이전트 노드를 찾는 것을 목표로 합니다 (즉, 동일한 장면의 일부를 관찰한).
- 각
에이전트 노드에 대해, 우리는노드 주변의 통계를 설명하는계층 구조의 descriptors를 구성 - 이 기술자는 low-level appearance에서부터 objects semantics 및 places geometry까지 포함
- 이 기술자는 새로운 에이전트 노드가 생성될 때 한 번만 계산
- 루프 클로저 감지를 위해, 우리는
현재(쿼리) 노드의 계층적 descriptors와 모든과거 에이전트 노드 descriptors를 비교하여 일치를 찾습니다. - 루프 클로저 감지를 수행할 때, 우리는 장소 기술자에서 객체 기술자, 그리고 외관 기술자로 계층을 내려가며 비교
- places descriptor
- 에이전트 노드로부터 반경 내의 장소로부터 계산됨
- 노드 주변의 각 장소와 관련된 거리의 히스토그램 (노드 근처의 지도 기하학을 직관적으로 설명)
- 만약 비교했을 때, 기술자 거리가 임계값 이하이면 -> objects 기술자와 appearance 기술자를 비교
- objects descriptor
- 에이전트 노드로부터 반경 내의 객체부터 계산됨
- 노드 주변의 객체 레이블의 히스토그램 (주변의 객체 집합을 직관적으로 설명)
- low-level appearance descriptor
- 표준 DBoW2 appearance descriptor를 포함
- https://velog.io/@jk01019/DBoW2
- TODO: 좀 더 공부 필요
- 표준 DBoW2 appearance descriptor를 포함
- 기술자 비교 중 하나라도 잠정적인 일치를 반환하면, 우리는 기하학적 검증을 수행
- descriptor를 계산할 때, 우리는 또한 기하학적 검증에 사용되는
노드 주변의 객체 및 장소의 ID를 추적
5.2.A.2. Bottom-up Geometric Verification
- 쿼리 에이전트 노드(i)와 일치하는 에이전트 노드(j) 사이에 잠정적인 루프 클로저가 발생한 후,
- 우리는 상향식 기하학적 검증을 수행하여 두 노드 사이의 상대적인 포즈를 계산
- 특히, 주어진 계층(예:
에이전트 계층에서의 appreance 기술자 간의 일치또는객체 계층에서의 객체 기술자 간의 일치)에서 일치가 발생할 때마다 우리는 프레임 i와 j를 등록하려고 시도 - appreance 특징을 등록하기 위해,
- 우리는 [48]에서와 같이 표준 RANSAC 기반 기하학적 검증을 사용
- 48: Kimera
- 만약 그것이 실패하면, 객체를 등록하려고 시도
- TEASER++ [69]를 사용
- 2020년, 630회 인용
- https://arxiv.org/pdf/2001.07715
- 객체 등록에도 실패한 루프 클로저를 폐기
- TEASER++ [69]를 사용
- 이러한 상향식 접근 방식은
- 카메라 시점이나 조명 변화로 인해, appreance 기반 기하학적 검증에 실패한 노드 조합이,
- 객체 기반 기하학적 검증 동안 유효한 루프 클로저로 성공적으로 이어질 수 있다는 이점
- 섹션 VI는 제안된 계층적 기술자가, 감지된 루프 클로저의 품질과 양을 개선한다는 것을 증명
5.2.B. 3D scene graph optimization
- 루프 클로저에 대응하여 3D scene graph를 수정하기 위해,
- Scene Graph Frontend는
- 섹션 III에 설명된 모듈의 출력을 단일 3D Scene Graph로 "조립"
- Scene Graph Backend는 아래 2가지를 수행
- (i) 변형(deformation) 그래프 접근 방식을 사용하여 그래프를 최적화
- (ii) 로봇이 동일한 위치를 여러 번 방문하는 것에 해당하는, 중복된 서브그래프를 제거하는 후처리
- Scene Graph Frontend는
5.2.B.1. Scene Graph Frontend
- https://velog.io/@jk01019/Hydra-Paper-Scene-Graph-Backend
- 프론트엔드는
드리프트가 보정되지 않은3D Scene Graph의 초기 추정치를 구축합 - 프론트엔드는 섹션 III에 설명된 모듈의 결과(최신 mesh(layer 1), place sub-graph(layer3), object(layer2), agent pose-graph(layer2) (모두 현재 로봇 포즈 주변의 반경으로 제한됨)를 입력으로 받음
- 해당 node와 edge는 점진적으로
- (
현재 시점까지의 전체 Scene Graph를 저장하는) 3D Scene Graph 데이터 구조에 추가됨
- (
- 그런 다음, 프론트엔드는 nanoflann [7]을 사용하여,
- 각 obect 또는 agent 노드(layer2)에서
- active window 내의 가장 가까운 place 노드(layer 3)로의 계층 간 엣지를 채움
- nanoflann: https://github.com/jlblancoc/nanoflann
- 이는 k-최근접 이웃 탐색을 수행하는 데 최적화된 도구야.
- nanoflann을 사용해 새로 추가된 객체나 에이전트 노드에서, 가장 가까운 장소 노드를 찾아 엣지(edge)를 추가하는 거지.
- 마지막으로, 프론트엔드는 (아래에 설명된
변형 그래프 접근 방식에서 최적화될) mesh의 샘플링된 버전을 계산- subsampled mesh는
옥트리 기반의 꼭지점 클러스터링 mesh 단순화접근 방식을 통해 계산되며, - 이로 인해 아래 2개가 생성됨
smaller subset of nodes(mesh control point)- 노드 간의 연결을 나타내는 엣지
옥트리 기반의 꼭지점 클러스터링 mesh 단순화- 옥트리(Octree)는 3차원 공간을 점진적으로 분할하는 트리 구조야.
- 이때 중요한 것은 공간을 8개로 반복적으로 나누는 거야.
- 예를 들어, 큐브 같은 공간을 생각해보자. 이 큐브를 중심을 기준으로 8등분하면 작은 큐브들이 생기지? 이렇게 큐브들이 계속해서 작은 큐브로 나뉘는 구조가 옥트리야.
- 각 레벨에서는 이 작은 큐브 안에 어떤 정보가 포함되어 있는지 확인하고, 이를 통해 중요한 점들을 클러스터링하는 과정이야.
- 3D 메쉬는 많은 꼭지점(vertex)과 엣지로 구성되는데, 옥트리는 이런 많은 데이터 포인트들을 일정한 기준에 따라 묶어 단순화시켜줘.
- 중요한 포인트만 남기고, 나머지 덜 중요한 점들은 클러스터로 묶어서 처리하는 방식이지.
- 이렇게 클러스터링이 완료되면, 수많은 꼭지점 중에서 소수의 중요한 점들만 남겨서 전체 메쉬 구조를 간소화해.
- 이렇게 단순화된 메쉬는
control points라고 불리는 소수의 노드들로 구성돼. - 이 control points는 이후 최적화 과정에서 매우 중요한 역할을 해.
- subsampled mesh는
5.2.B.1. Scene Graph Backend:
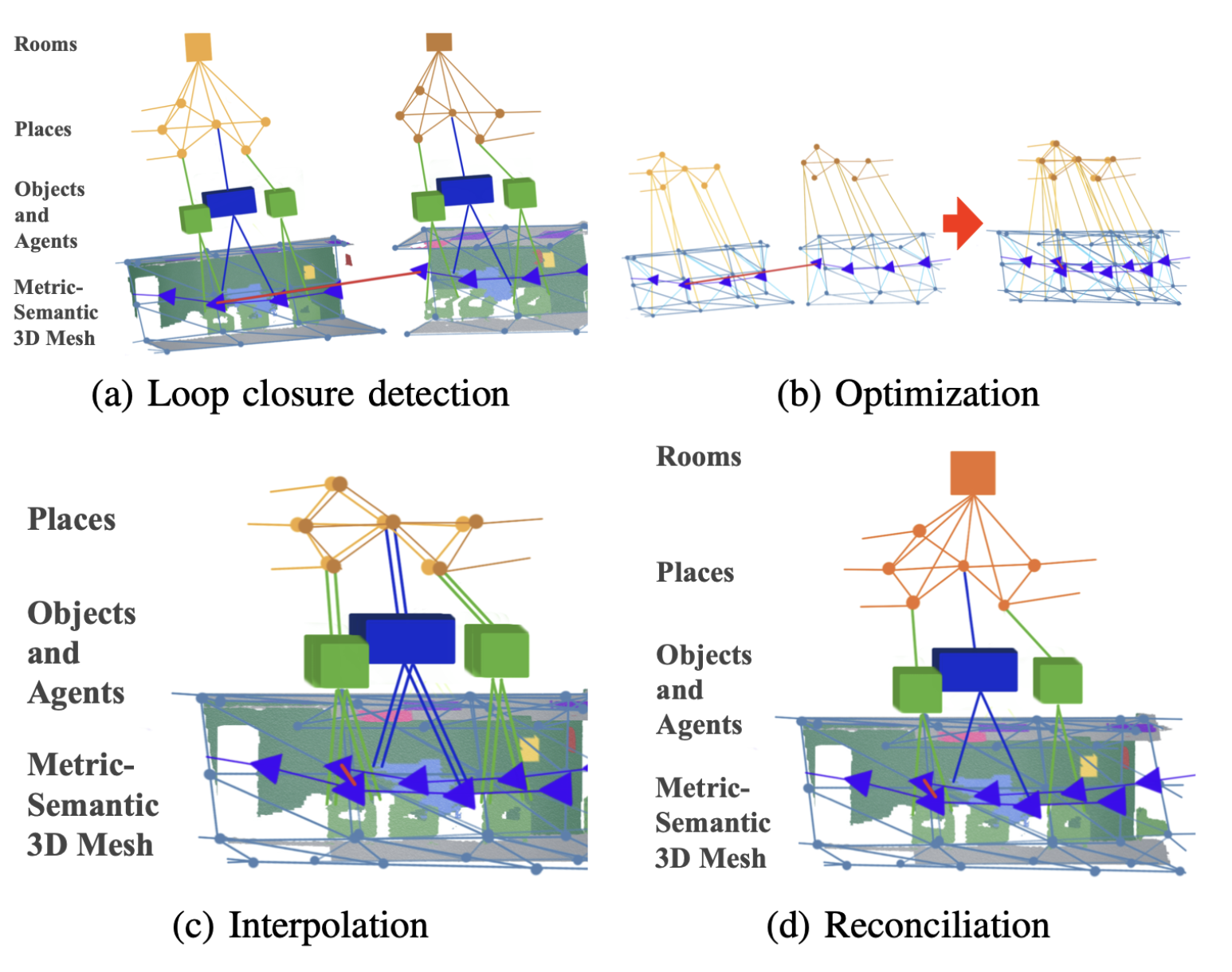
- 루프 클로저가 감지되면, 백엔드는
프론트엔드 Scene Graph에서 생성된embedded deformation graph[59]를 Optimization한 다음,- [59]에서와 같이 interpolation을 통해 Scene Graph의 다른 노드를 재구성(reconciliation)
- 보다 구체적으로, 우리는
- (i) odometry 및
루프 클로저 엣지를 모두 포함하는 pose graph로 구성된 에이전트 계층 2, - (ii) mesh control point(
smaller subset of nodes) 및 해당 edge를 포함하는 sub-graph, (mesh를 클러스터링해서 샘플링한 계층 1) - (iii) place 계층(3) 의
minimum spanning tree로 구성된deformation 그래프를 형성- TODO: minimum spanning tree 공부 필요
- (i) odometry 및
- 이러한 layer은 (프론트엔드에 의해 추가된) layer 간 edge를 통해 연결된 서브그래프를 형성
- place 계층(3) 의
minimum spanning tree를 사용하는 선택은, 주로 계산상의 이유minimum spanning tree의 사용은 place 그래프의 sparsity을 유지
embedded deformation graph approach는- deformation graph의 각 노드를 pose(local frame)과 연관시킨다.
- 그리고, local frames(poses)를 조정하는 최적화 문제를 푼다.
- 최적화 문제: 각 edge와 연관된 변형(loop closures 포함)을 최소화
- 이를 통해 3D scene graph의 하위 집합을 ->
edge potentials을 최소화해야 하는 factor graph [11]로 변환- factor graph
- 노드와 엣지로 구성된 그래프에서 엣지의 잠재적 에너지(potential)를 최소화하는 문제로 변환돼.
- 이 잠재적 에너지는 노드 간의 관계(변형,
거리)를 나타내고, - 최적화를 통해 각 엣지의 변형을 최소화하는 방향으로 계산돼.
- factor graph
- 최적화에 대한 자세한 내용은 [59]를 참조하자.
- (상용 solvers에 적합한) standard pose graph optimization problem를 얻기 위해,
- ([59]의 affine 대신)
- rigid transforms을 사용하는 reformulation of the deformation graph을 사용
- rigid VS affine
- Rigid 변환은 물체의 회전과 이동만 허용하며, 크기나 모양은 변하지 않게 유지하는 방식이야.
- 이와 달리 Affine 변환은 물체의 크기나 모양이 변할 수 있어.
- 이 차이가 중요한 이유는, Rigid 변환은 물리적으로 변할 수 없는 구조(예: 건물이나 단단한 객체)에서 더욱 정확한 모델링을 가능하게 해줘.
- 특히, 우리는 GTSAM [2]의 Graduated Non-Convexity (GNC) solver를 사용하며,
- 이는 incorrect loop closures를 outliers로 거부할 수도 있음
- 최적화가 완료되면, pose 노드(layer2)는 새로운 위치로 업데이트되고,
- 전체 mesh (layer 1)는
[59]의 deformation graph approach을 기반으로 interpolation
- 전체 mesh (layer 1)는
- 그런 다음, 우리는 새로 변형된 mesh에서 해당 버텍스의 위치로부터 object 중심점과 3D bounding box를 재계산 (layer 2)
- 이 업데이트 동안, 중첩된 노드도 병합됩니다:
- place 노드의 경우, 우리는 거리 임계값(0.4m) 내의 노드를 병합
- object 노드의 경우,
- 해당 객체가 동일한 의미 레이블을 가지고 있고,
- 하나의 노드가 다른 노드의 경계 상자 내에 포함되는 경우 노드를 병합
- 우리는
노드가 병합되지 않은 scene graph의 버전을 유지- 이걸 유지하면, 나중에
GNC에 의해 outlier로 판단된 루프 클로저가 있을 경우 -> 잘못된 루프 클로저를 취소할 수 있게 합니다.
- 이걸 유지하면, 나중에
- 마지막으로, 우리는 섹션 III에 설명된 접근 방식을 사용하여 병합된 장소에서 방(layer 4)을 다시 감지
8. EXPERIMENTS
- 이 섹션에서는 Hydra가 오프라인 배치 방법과 비교 가능한 정확도로 실시간으로 3D 장면 그래프를 구축함을 보여줌
8.1. A. 실험 설정
데이터셋.
- 우리는 실험을 위해 두 가지 데이터셋을 사용합니다:
- uHumans2(uH2) [50]와 SidPac.
- uH2 데이터셋은 Unity 기반 시뮬레이션 데이터셋으로 [50], 작은 아파트, 사무실, 지하철역의 세 장면을 포함
- 이 데이터셋은 시각-관성 데이터뿐만 아니라 지상 진리 깊이 및 2D 시맨틱 분할을 제공
- 또한 벤치마킹 목적으로 사용되는 지상 진리 로봇 궤적도 제공
- SidPac 데이터셋은 시각-관성 핸드헬드 장치를 사용하여 대학원생 주거 건물에서 수집된 실제 데이터셋
- 우리는 Kinect Azure 카메라를 주요 수집 장치로 사용했으며,
- 외부 위치 추정 입력을 제공하기 위해 Kinect에 Intel RealSense T265를 견고하게 부착
- 데이터셋은 두 개의 별도 녹화로 구성됩니다. 첫 번째 녹화는 건물의 두 층(1층과 3층)을 다루며, 1층의 공용실, 음악실, 오락실을 거쳐 계단을 올라 3층의 긴 복도와 학생 아파트를 지나 다시 다른 계단을 내려가 음악실과 공용실을 다시 방문하여 시작 지점에서 끝납니다. 두 번째 녹화도 두 층(3층과 4층)을 다루며, 학생 아파트와 두 층에 걸쳐 중복되는 라운지 및 주방 구역을 맵핑합니다. 이 장면들은 장면의 규모(평균 약 400미터), 유리와 강한 햇빛이 있는 지역(이로 인해 Kinect의 부분적인 깊이 추정 발생), 복도에서의 특징이 적은 지역으로 인해 특히 도전적입니다.
- 우리는 추가 높이 사전 조건을 사용하여 드리프트를 줄이고 건물 평면도와 질적으로 일치시키기 위해 수동으로 조정된 포즈 그래프 최적화를 통해 SidPac 데이터셋의 지상 진리 궤적을 얻습니다.
Hydra.
- 실제 데이터셋의 경우, 우리는 Kinect의 depth reconstruction을 사용하며 (그림 5 참고),
- MIT 장면 파싱 챌린지 [72]의 사전 학습된 모델을 사용하여 HRNet [64]를 통해 2D 시맨틱 분할을 수행
- 더 새로운 성능이 좋은 네트워크들도 존재하지만 (예: [5, 15, 24]),
- ADE20k [72]에 대한 사전 학습된 시맨틱 분할 모델이 있는 네트워크는 거의 없으며, 우리의 추론 툴체인(ONNX와 TensorRT)과 호환
- 시뮬레이션 데이터셋의 경우, 제공된 깊이와 분할을 사용
- 시뮬레이션 및 실제 데이터셋 모두에서 우리는 Kimera-VIO [48]를 사용하여 시각-관성 위치 추정을 수행하며,
- 실제 장면에서는 Kimera-VIO 추정값을 RealSense T265의 출력과 결합하여 위치 추정 궤적의 품질을 향상시킴
- 그림 5의 나머지 블록들은 이 논문에서 설명한 접근 방식을 따라 C++로 구현되었습니다.
- 실험에서는 AMD Ryzen9 3960X (24코어)와 두 개의 Nvidia GTX3080을 탑재한 워크스테이션을 사용하지만,
- 이 섹션의 끝에서는 임베디드 컴퓨터(Nvidia Xavier NX)의 시간 결과도 보고
9. 결론
- Hydra는 새로운 온라인 알고리즘과 고도로 병렬화된 인식 아키텍처 덕분에 센서 속도로 실행됩니다.
- 또한, 새로운 3D 장면 그래프 최적화 방법을 통해 환경의 지속적인 표현을 구축할 수 있습니다.
- 제안된 접근 방식이 로봇을 위한 고급 3D 장면 이해로 가는 중요한 단계라고 생각하지만, Hydra는 여러 방향으로 개선될 수 있습니다.
- 첫째, 재구성된 3D 장면 그래프의 일부 노드는 라벨이 지정되지 않습니다(예: 이 논문의 알고리즘은 방을 감지할 수 있지만, 주어진 방을 '주방' 또는 '침실'로 라벨링할 수 없습니다).
- 향후 작업에는 Hydra를 학습 기반 방법과 연결하여 3D 장면 그래프 노드 라벨링을 수행하는 것이 포함됩니다.
- 둘째, [67]을 기반으로 3D 장면 그래프의 노드와 엣지에 더 풍부한 관계와 기능을 라벨링하는 것도 흥미로울 것
- 셋째, 장면 그래프 최적화 접근 방식과 포즈 그래프 최적화 간의 연결은 최근의 포즈 그래프 희소화 발전을 활용하여 최적화 효율성을 향상시킬 수 있는 기회를 제공합니다.
- 마지막으로, 예측, 계획 및 의사 결정에 3D 장면 그래프를 사용하는 것의 의미는 대부분 탐구되지 않았으므로(초기 예제는 [1, 46] 참조) 향후 연구의 새로운 길을 엽니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.