0. 들어가기 전에
- reference
1. abstract
- LMM(Large Multimodal Model) 중 하나인 LLaVA에 대한, 간단한 수정을 통해 성능 향상을 이뤄냈다는 논문 = LLaVA 1.5
- LLaVA: 현재 많은 논문의 baseline으로 사용되는 중요한 모델
- LLaVA 1.5는 LLaVA의 장점을 이어받아
data-efficient한 학습이 가능 - 그 외에도 저자들은
현재 LMM(Large Multimodal Model)의 여러 문제들을 제시하는 등 여러 insight를 제공
2. Introduction
2.1. 과거 연구들
- LLaVA:
너무 TMT(Too Much Talker)라서 문제- 특징
- LLM, vision encoder 사이에 projection layer(Adapter)만을 추가한 매우 간단한 구조
- 장점
real-life visual conversation task를 잘함- 단일 8개 A100 machine에서 1일 만에 훈련 가능한 매우 빠른 학습 속도
- 공개적으로 사용 가능한 데이터만을 사용
- 단점:
- academic task (+ short-form answers e.g. yes/no)
- 특징
- InstructBLIP:
너무 대답이 짧아서 문제- 특징
- 자연스러운 응답과 짧은 답변을 모두 포함하는 instruction following 데이터를 활용하여 학습했음.
- Adapter: Q-former (only finetunes Q-former for visual instruction tuning)
- 장점
- academic task (+ short-form answers e.g. yes/no)
- 단점
- real-life visual conversation task (overfit to academic task, generate short-form answers)
- 긴 문장의 일상 문답 대화를 잘 못하는 이유
- Response format에 대한 ambiguous prompts:
- InsturctBLIP에서는
Q: {Question} A: {Answer}.와 같은 단순한 형태의 prompt를 사용했는데, - 이러한 프롬프트는 원하는 출력 형식을 명확하게 나타내지 않으며
- 따라서 LLM이 short-form answer에 overfitting되었을 것이다.
- InsturctBLIP에서는
- Not finetuning the LLM:
- InstructBLIP은 instruction tuning을 위해 Q-former만 finetuning했는데,
- 이는 LLM의 language understanding을 제한했을 것이다. (LLM을 fine-tuning 하지 않았음으로)
- LLM의 출력 길이를 긴 형식 또는 짧은 형식으로 제어하려면 Qformer의 출력 토큰이 필요하지만
- Qformer는 LLM에 비해 용량이 제한되어 있으므로 LLaVA와 달리 제대로 수행하는 능력이 부족할 수 있다.
- InstructBLIP은 instruction tuning을 위해 Q-former만 finetuning했는데,
- Response format에 대한 ambiguous prompts:
- 특징
- LLAVA와 InstructBLIP의 특징 차이의 원인 요약
- 학습 데이터 및 학습 방법의 차이에 따른 결과
2.2. 제안
- LLaVA-1.5
- academic task (+ short-form answers e.g. yes/no) 도 잘하게 하고 (InstructBLIP이 잘하던거)
- real-life visual conversation task도 잘하게 하자. (LLAVA가 잘하던거)
3. Improved Baselines of LLaVA
3.1. Response formatting prompts
- InstructBLIP의 문제를 해결하면서 짧은 답변을 더 잘 처리할 수 있도록,
- fine-tuning할 때,
출력 형식을 명확하게 나타내는 하나의 응답 형식 프롬프트를 사용할 것을 제안
- fine-tuning할 때,
- 짧은 답변이 필요할 때, VQA 질문 끝에
"단일 단어나 문구를 사용하여 질문에 답변하세요."문구를 prompt에 추가.(formatting) - 이러한 프롬프트가 포함된 VQA-v2 데이터 셋에 대하여 fine-tuning 할 시 성능 향상됨.

- 위 fine-tuning 방법을 통해, LLaVA 1.5에서는 academic task에서도 short-form answer를 잘 할 수 있게 되었다.
- 이러한 프롬프트로 fine-tuning되면,
- LLaVA는 사용자 명령에 따라 출력 형식을 적절하게 조정할 수 있으며
- language only ChatGPT를 사용하여 VQA 답변을 추가로 만들 필요가 없다.
- 학습에 VQAv2를 포함시키는 것만으로도 LLaVA의 성능이 크게 향상된다.
3.2. MLP vision-language connector
- LLaVA의 projection layer를 2 layer MLP(MLP Projection Adapter)로 변경하여 표현력 향상.
- 이는 linear adapter보다 non-linear한 특성을 가지고 있어 더 복잡한 task를 수행할 수 있다.
3.3. Scaling to Higher Resolutions (매우 중요)
- 이미지의 세부 사항을 더 명확하게 볼 수 있도록 입력 이미지의 해상도 확장
CLIP resolution을 224에서 336으로 높인다.
- 임의의 resolution을 가진 high-resolution input을 받을 수 있도록,
patch 단위로 분할하여 encoding하는 방법을 도입했다. (LLaVA-1.5-HD.)
- 현재 사용할 수 있는 CLIP의 최대 resolution이 336×336이기에, 이보다 더 높은 resolution의 이미지를 처리할 필요가 있었다.
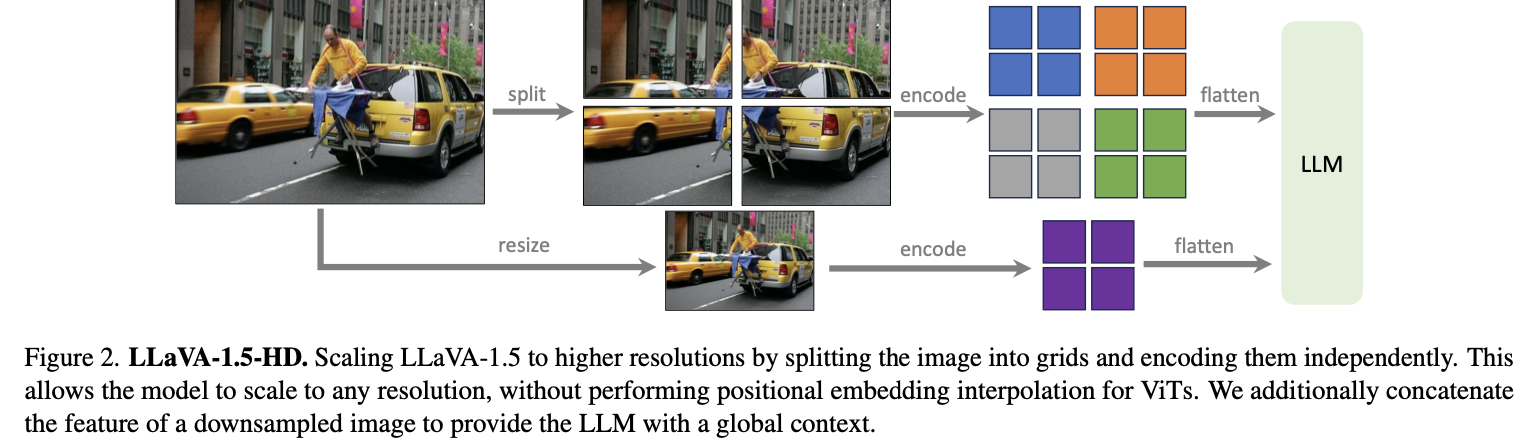
- 일반적으로는 positional embedding interpolation 후 finetuning을 진행하는 식으로 high resolution을 처리하지만,
- 이러한 경우 inference 시, image size가 하나로 고정될 수밖에 없는 문제가 있다.
- 따라서 저자들은 patch 단위로 분할하여 encoding하는 방법을 도입했다.
- 추가로 아래 그림을 보면 알 수 있듯이,
- global context를 얻기 위해 이미지의 사이즈를 줄여 encoding하는 추가적인 방식을 사용하였다.
- 이는 효과적인 성능 향상을 가져왔다.
- 이를 통해 임의의 이미지 사이즈를 encoding할 수 있는 framework를 만들었고,
- 이를 LLaVA-1.5-HD라고 부르기로 한다.
3.3.1. 데이터 스케일링
- 데이터 세분성 확장
- 데이터를 더 작은 단위로 나누어 모델이 학습하도록 하는 방법
- 예를 들어, 이미지를 작은 패치(patch) 단위로 나누어 각각을 독립적으로 학습시킴
- 이러한 접근 방식은 모델이 데이터의 더 많은 세부 사항을 학습할 수 있도록 도와줌
- 데이터를 세분화하여 학습하면, 모델이 실제로 존재하는 정보에 더 집중할 수 있어 Hallucination 문제를 줄일 수 있습니다.
3.3.2. 그 외
- 또한 추가적인 시각적 지식 소스로
GQA 데이터셋을 추가
3.4. language 모델 크기 증대
- LLM scale up도 수행했다. (LLM을 13B로 확장)
- 매개변수(parameter) 수를 늘리거나, 층(layer) 수를 늘리거나
ShareGPT 데이터를 추가
3.5. Academic task oriented data 로 학습
- Academic-task-oriented VQA 데이터셋을
적절한 Instructization을 통해 변형하여 학습시켜 task에 따라 적절한 정답을 낼 수 있도록 했다. - InstructBLIP에서 사용되는 데이터셋인 OKVQA/OCR 추가.
- OKVQA (Open-Ended Knowledge Visual Question Answering):
- 이미지에 대한 질문에 답하는 데이터셋으로, 일반적인 지식과 이미지를 결합하여 답을 생성해야 함
- OCR (Optical Character Recognition):
- 이미지 내 텍스트를 인식하고 이를 바탕으로 질문에 답하는 데이터셋
- OKVQA (Open-Ended Knowledge Visual Question Answering):
- 또한 Region-level VQA(Visual Genome, RefCOCO) 추가. 세부 정보를 지역화하는 기능이 향상됨.
- Region-level VQA:
- Visual Genome:
이미지의 세부 영역에 대한 설명과이를 기반으로 한 질문-응답 데이터셋.
- RefCOCO:
특정 이미지 내 객체를 지칭하는 문장을 통해 해당 객체를 식별하는 데이터셋.
- Visual Genome:
- 세부 정보 지역화:
- 이러한 데이터셋을 추가하면, 모델이 이미지의 특정 영역을 더 정확하게 이해하고 세부 정보를 추출하는 능력이 향상됨
- Region-level VQA:
4. Experiments

4.0. 학습 과정
- LLaVA-1.5의 경우 adapter pre-training을 위해, LLaVA와
동일한 사전 학습 데이터셋을 사용 - instruction tuning (fine-tuning)을 위한 학습 iteration 및 batch size를 LLaVA와 거의 동일하게 유지한다.
- 이미지 입력 해상도가 336 by 336 로 증가했기 때문에 LLaVA-1.5의 학습은 LLaVA보다 약 2배가 걸린다.
- 즉, A100 8개를 사용하여 약 6시간의 사전 학습과 약 20시간의 fine-tuning이 필요
4.1. benchmarks
- 12개의 benchmark에서 모두 SOTA를 달성했다. 저자들은 앞으로의 연구에 있어 중요한 baseline이 될 것이라고 확신한다.
- 이 결과의 discussion 중 중요한 부분을 요약해보면 다음과 같다.
- LLaVA 때와 같이, visual instruction tuning이 중요하다.
- Adapter pre-training에 다른 모델보다 많은 데이터를 사용하지 않았는데도 높은 성능을 얻을 수 있었다.
- 따라서 adapter pre-training의 필요성을 다시 한 번 생각해볼 필요가 있다.
4.2. Emerging Properties
- LLaVA-1.5의 창발성(emergency) 크게 2가지를 언급
- Format instruction generalization:
- LLaVA-1.5에서는 한정적인 format instruction만 학습했다.
- 즉, yes/no 정도만 학습했음에도 불구하고 다양한 format instruction을 잘 처리할 수 있었다.
- 위 그림에서 볼 수 있듯이 대답할 수 없거나, 애매한 문제에 대해서도 잘 처리하는 것을 확인할 수 있다.
- Multilingual multimodal capability.
- ShareGPT의 multilingual language instruction 덕분에 다양한 언어 instruction을 처리할 수 있었다.
- Format instruction generalization:
4.3. LLaVA 의 학습 데이터 효율성
- LLaVA 모델의 경우, 학습 데이터셋의 최대 75%를 무작위로 줄여도 성능이 크게 저하되지 않는다는 결과를 얻었습니다.
- 이러한 결과는 LLaVA 모델의 학습 파이프라인이 이미 매우 효율적으로 설계되었음을 보여줌
- 이는, 데이터를 더 적게 사용하면서도 성능을 유지할 수 있는 가능성을 시사
- 이는 더 정교한 데이터 선택 및 압축 전략을 통해, 모델의 성능을 떨어뜨리지 않으면서도 필요한 학습 데이터를 줄일 수 있다는 것을 의미
5. Open Problems in LMMs
- Large Multimodal Models의 현재 문제들
Data Efficiency
- LLaVA-1.5가 상대적으로 data-efficient하긴 하지만, LLaVA에 비하면 더 많은 cost가 필요했다.
- 앞으로도 data-efficient한 학습이 중요할 것이다.
Hallucination
image resolution이 높아지면 -> hallucination이 크게 감소한다는 것을 확인- 반대로 training data의 resolution이 낮아 이미지를 분간하지 못할 정도가 되면, 모델은 hallucination을 학습하게 된다.
- 따라서 앞으로의 연구에서는 1) detailed annotation도 중요하지만 2) resolution이 높은 데이터도 중요할 것이다.
Compositional Capabilities
- 여러 문제를 한번에 해결하는 것을 아직 잘하지 못한다.
- 예를 들어 VQA 문제를 해결하면서, 한국어로 번역하는 문제에는 아직 어려움
- Multi-image understanding.
- LLaVA는 한 장의 이미지만을 이해할 수 있었지만, 여러 이미지를 이해하는 것이 중요할 것

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.