LM
1.[23,10][1617] Improved Baselines with Visual Instruction Tuning

https://arxiv.org/pdf/2310.03744https://velog.io/@jk01019/Visual-Instruction-TuningLMM(Large Multimodal Model) 중 하나인 LLaVA에 대한 간단한 수정을 통해 성능
2024년 7월 7일
2.[23,4][4800]Visual Instruction Tuning

https://arxiv.org/pdf/2304.08485이 논문은 LLaVA(Large Language and Vision Assistant)라는 멀티모달 모델을 소개이 모델은 시각 인코더(CLIP)와 언어 모델(Vicuna 언어 디코더)을 결합하여 시각적
2024년 7월 5일
3.240721 논문 조사
Physically Grounded Vision-Language Models for Robotic Manipulationhttps://arxiv.org/pdf/2309.025612023, 9월 41회RoboCLIP:One Demonstration is Enou
2024년 7월 21일
4.Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
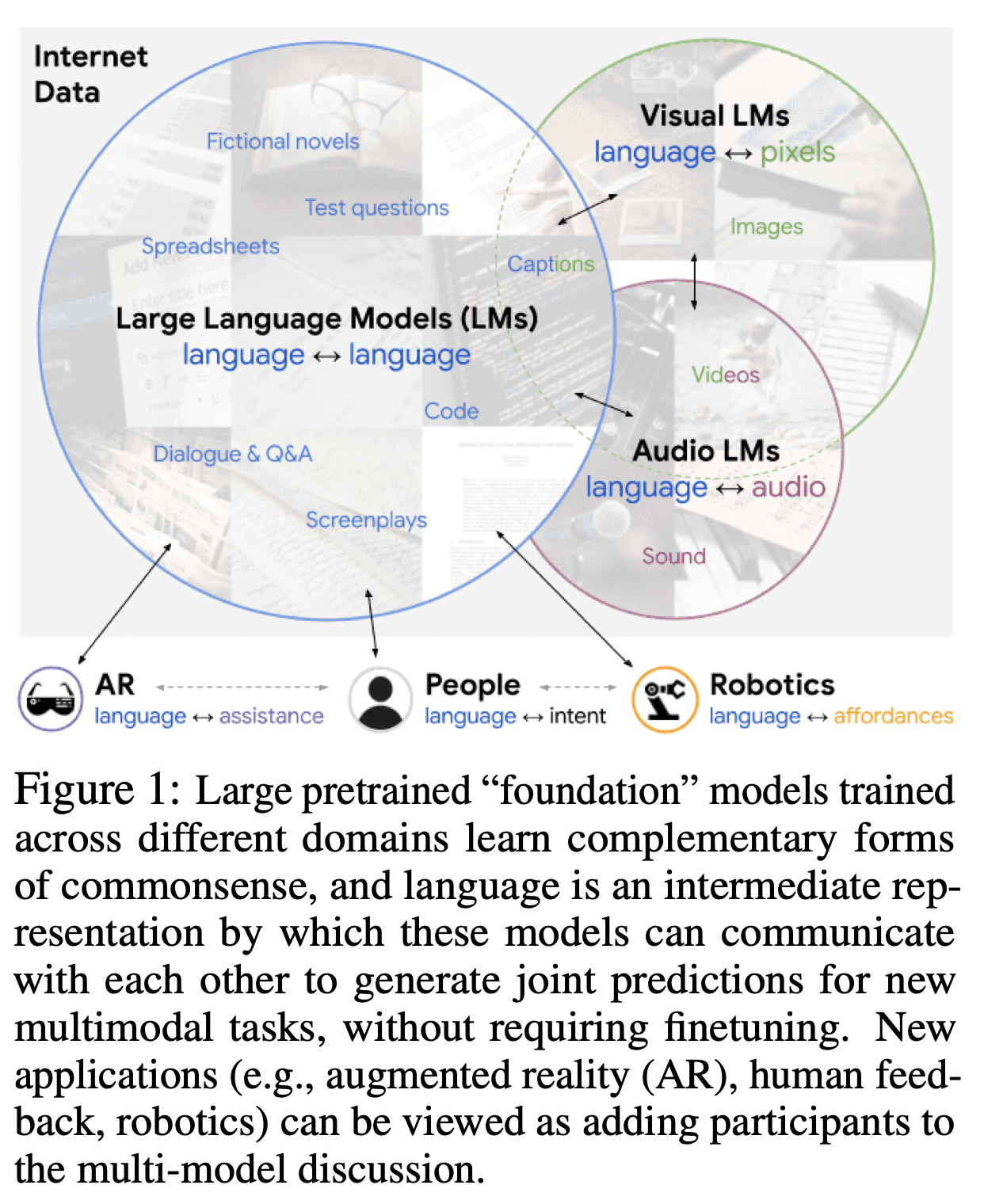
대규모 사전 훈련된(예: "Foundation") 모델들은 훈련된 데이터의 도메인에 따라 독특한 능력을 보입니다. 이러한 도메인들은 일반적이지만, 서로 겹치는 부분은 거의 없습니다. 예를 들어, 시각-언어 모델(VLMs)은 인터넷 규모의 이미지 캡션으로 훈련되지만, 대
2024년 7월 25일