0. Reference
1. Abstract
- image 분야의 Transformer
- CNN 기반 image classification 모델보다, (비슷한 크기의 모델) 성능이 더 좋지 못함
- 하지만, 모델의 크기를 선형적으로 키워갈 수록, 성능도 선형적으로 증가하는 것을 발견!
- 규모의 학습이 inductive bias를 이긴 것!
- 그래서, Vision Transformer은 Image classification 도메인으로 많은 양의 데이터로 pre-train 시킨 후,
- 적용 domain에 맞게 (
Head 만 교체해서) fine tuning 하는 방식으로 주로 사용
- 적용 domain에 맞게 (
- 위와 같은 방식으로 사용하였을 떄, SOTA CNN 네트워크보다 훈련에 필요한 연산량이 크게 감소하면서도 성능이 좋았다고 함
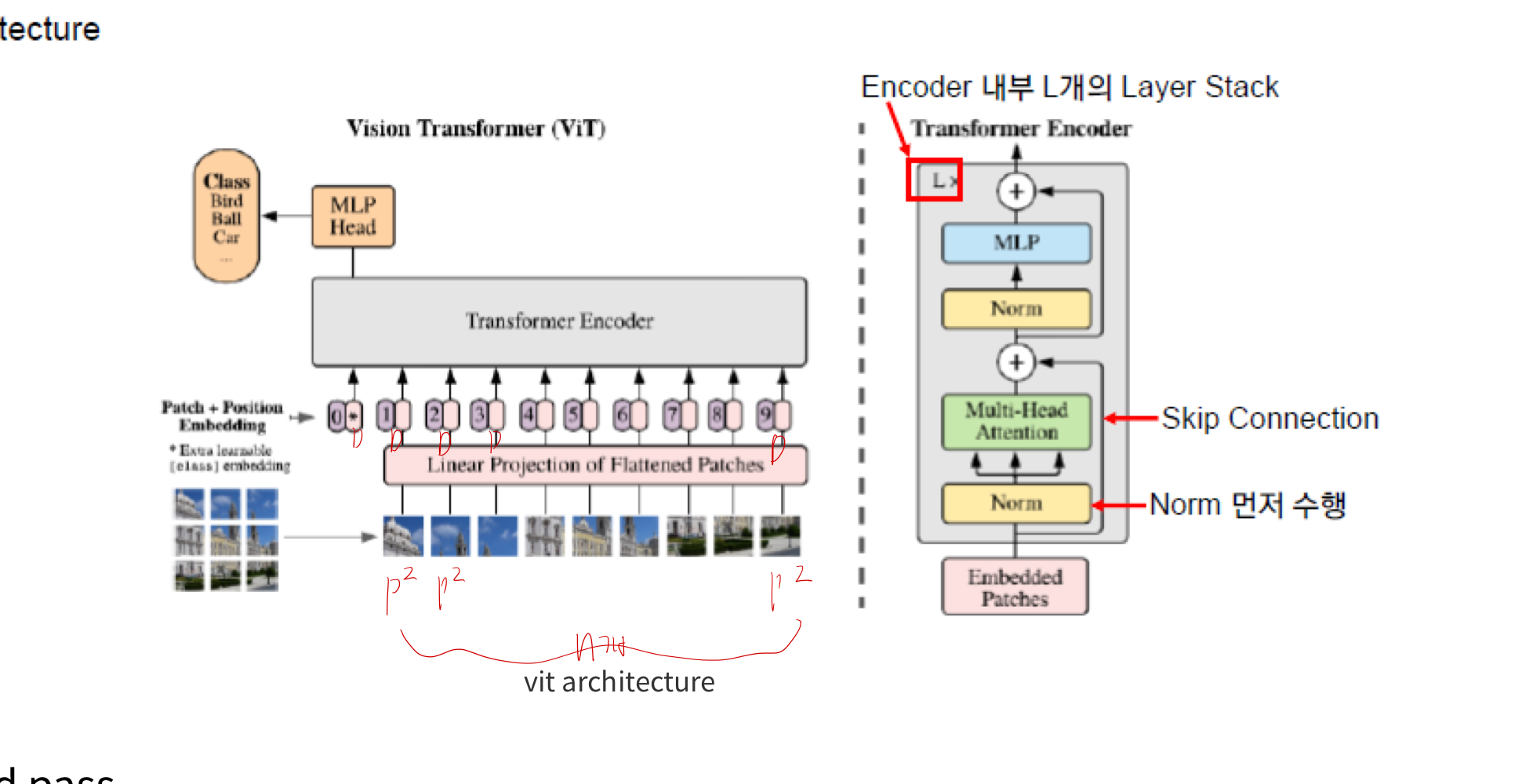
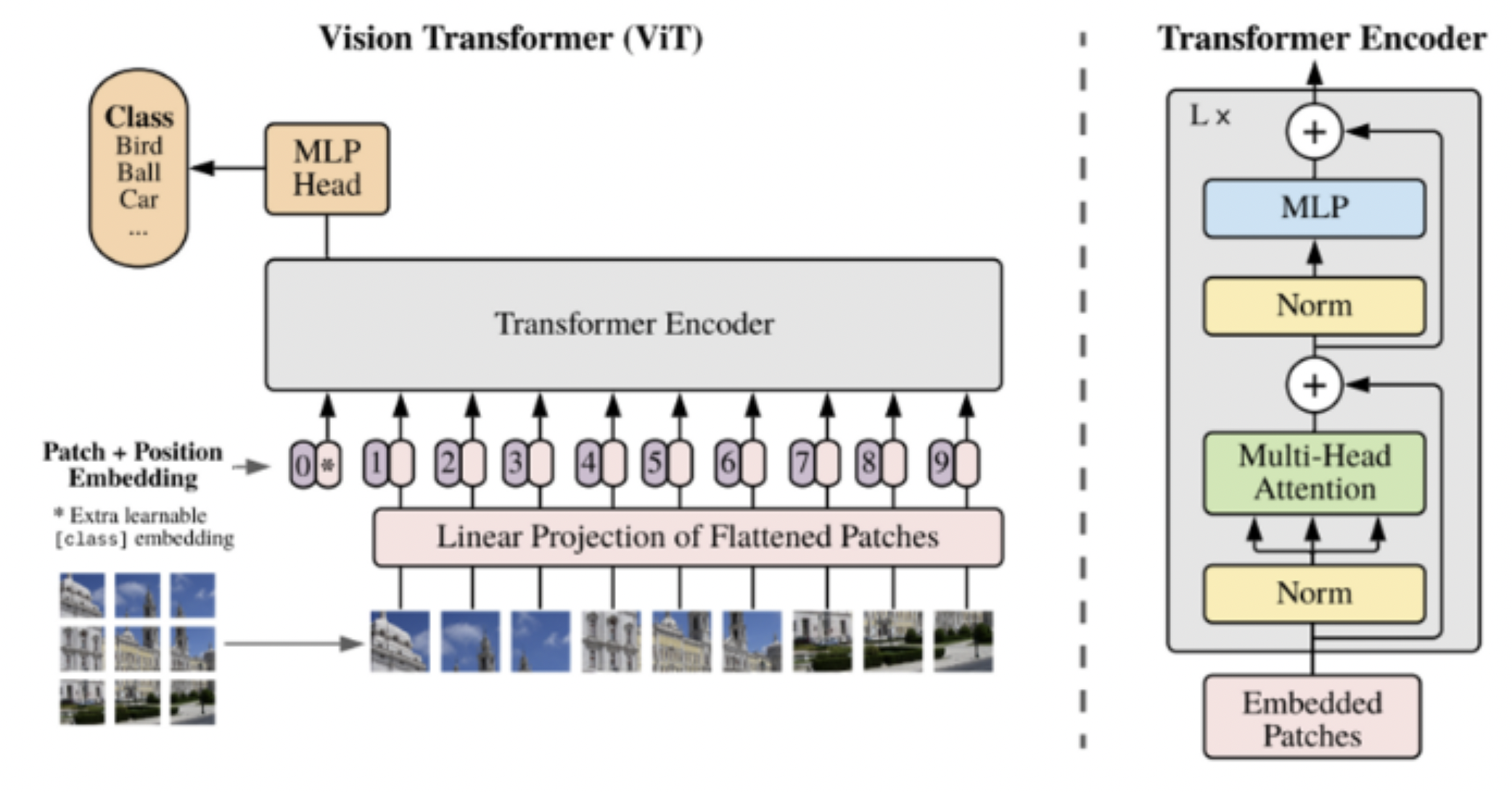
2. Method
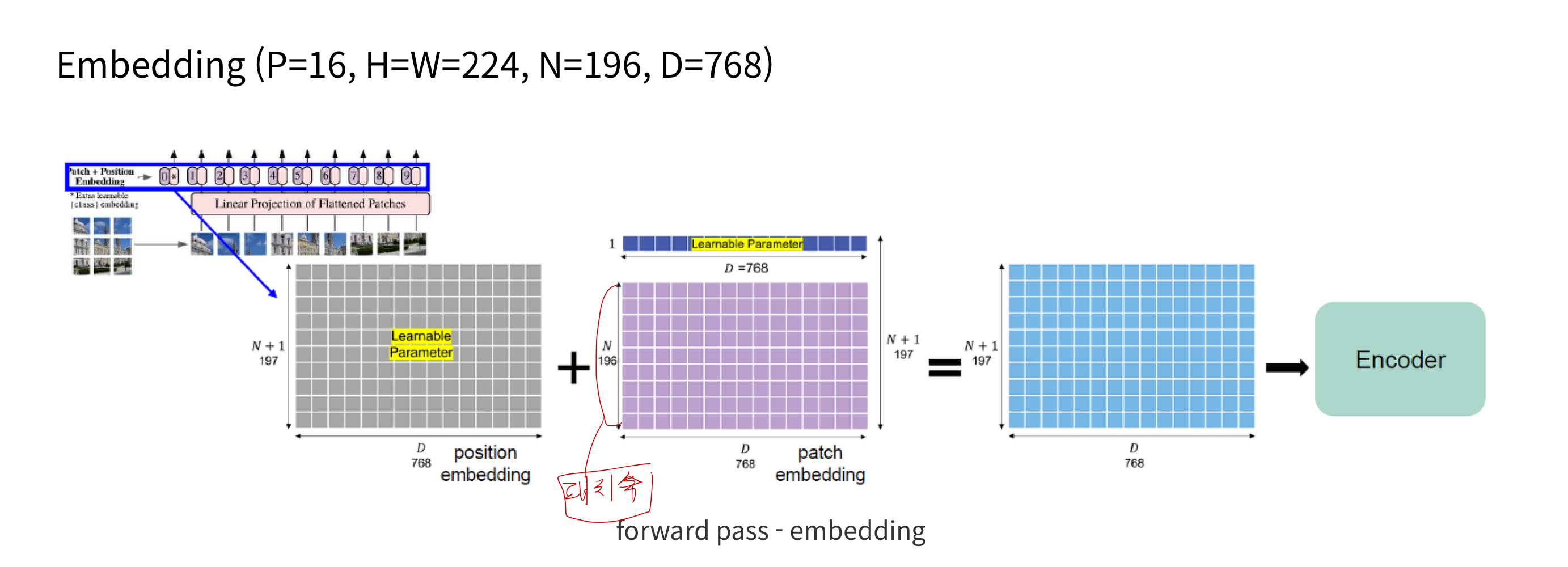
- 이미지를 patch 단위로 분리 -> MLP -> embedding sequence 확보
- embedding sequence -> transformer encoder 에 전달
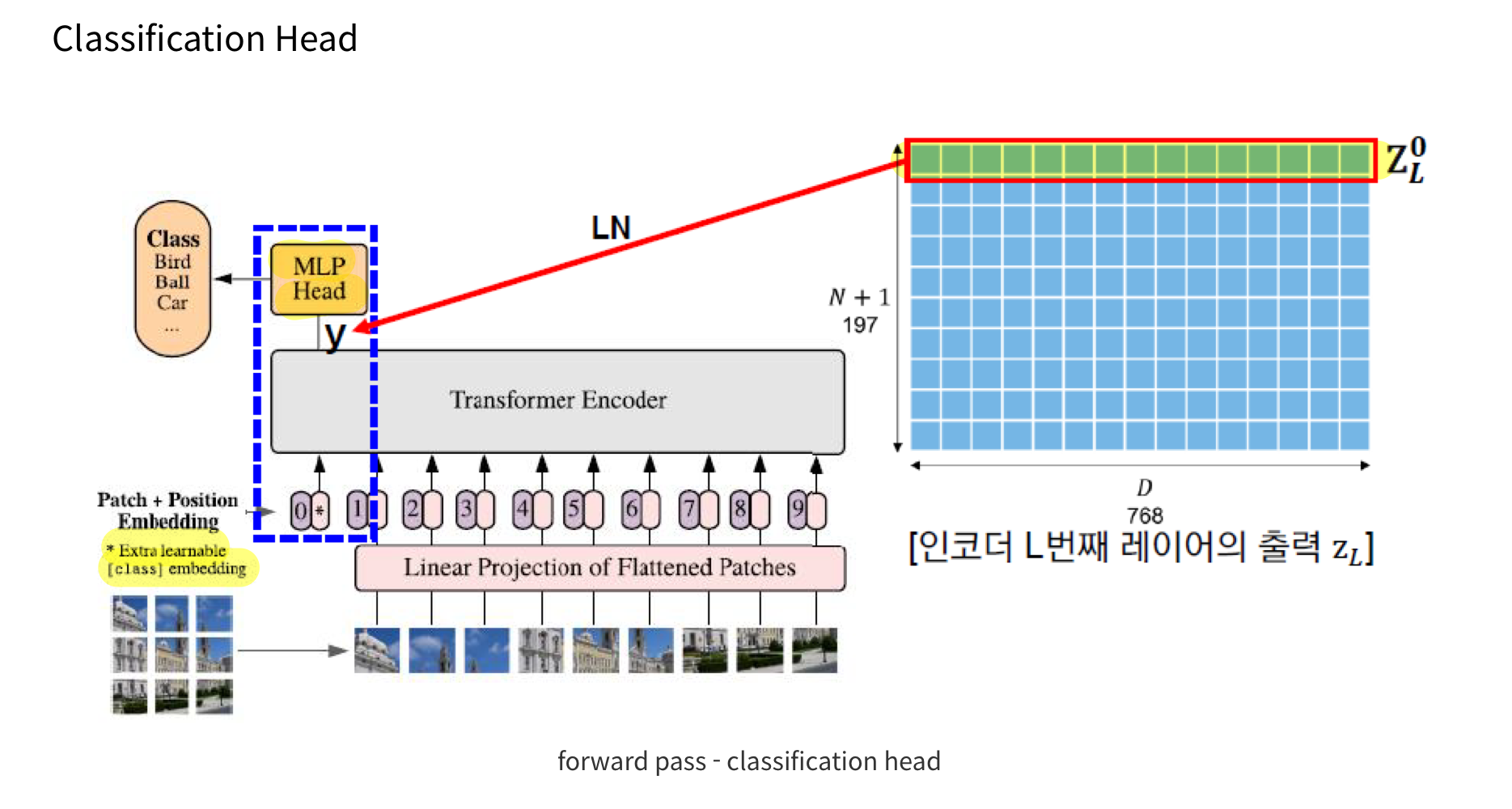
- classification을 수행하기 위해, 추가적으로 훈련이 가능한 "classification token"을 sequence에 더하는 방식)
3. CNN VS Vision Transformer
- Inductive Bias: 모델이 학습 과정에서 일반화에 도움을 주기 위해 가지는 사전 가정. 즉, 모델이 데이터를 이해하고 해석하는 데 도움이 되는 선천적인 구조적 편향입니다.
3.1. 들어가기 전에
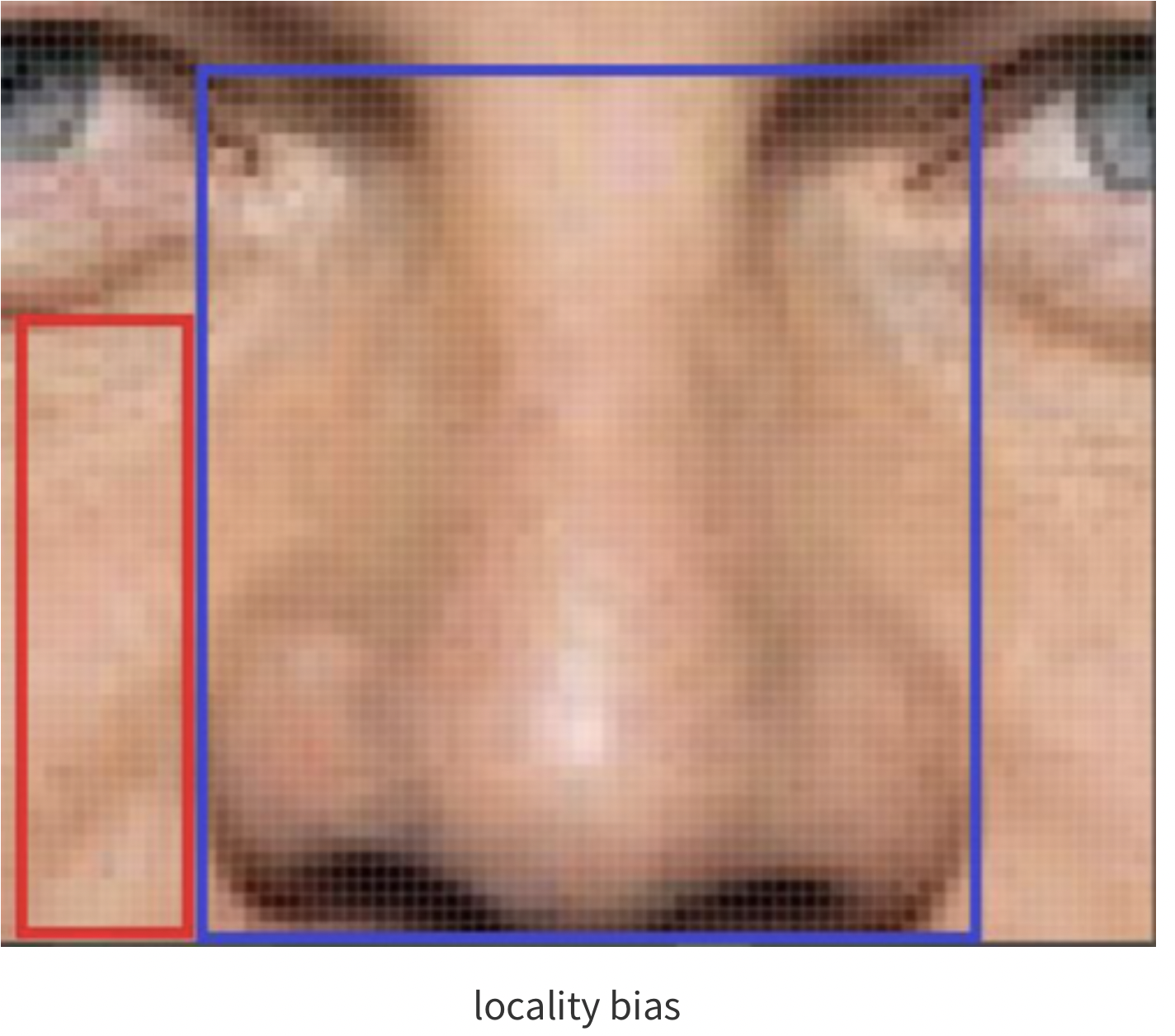
locality (Locality of Pixel Dependencies) = 국소성
- 이미지를 구성하는 특징들은, 이미지 전체가 아닌 일부 지역들에 근접한 픽셀들로만 구성되고, 근접한 픽셀들끼리만 종속성을 갖는다는 가정
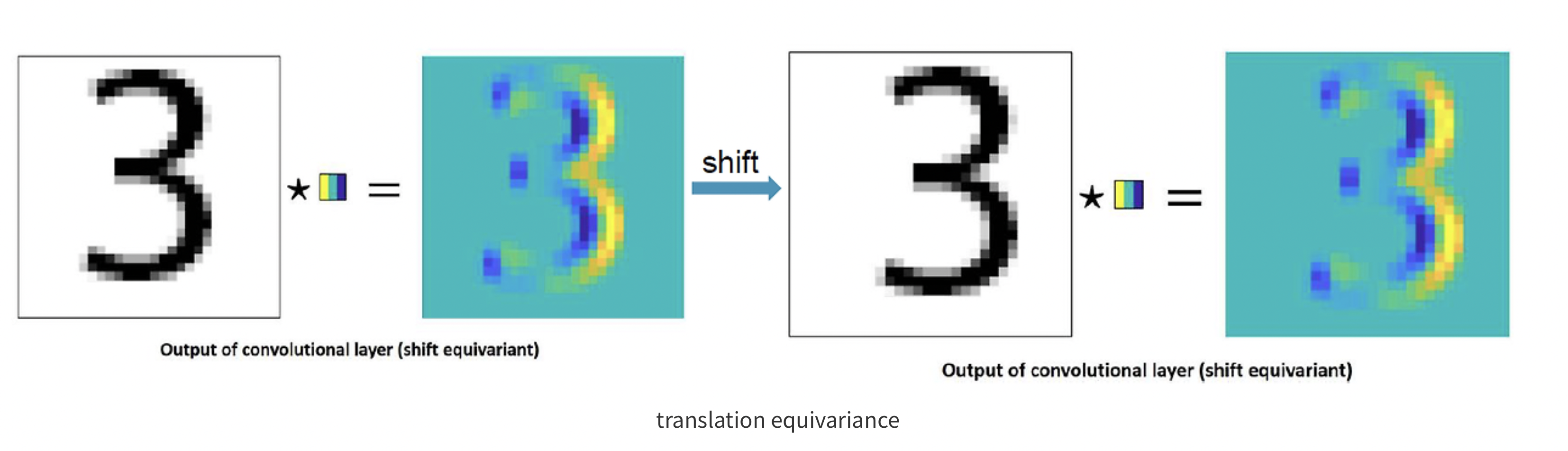
Translation Equivariance
- 입력 위치 변화에 따라, 출력 또한 입력과 동일하게 변화하는 특성
- CNN: Translation Equivariant!
3.2. Convolutional Neural Networks (CNNs)와 Inductive Bias
- Locality (국소성):
- 설명: CNN의 필터는 국소적인 영역에서 작동합니다. 즉, 작은 영역(커널)에서만 연산을 수행하여 이미지의 특정 부분을 집중적으로 처리합니다.
- Two-Dimensional Neighborhood Structure (2차원 이웃 구조):
- 설명: 이미지가 2차원 배열(행렬)로 표현되므로, CNN의 필터는 2차원 구조를 그대로 유지하며 인접한 픽셀 간의 관계를 학습합니다.
- Translation Equivariance (평행 이동 등가):
- 설명: 이미지의 한 부분이 이동해도, 필터가 동일한 특성을 추출할 수 있는 능력. 즉, 이미지의 물체가 이동하더라도 그 물체를 인식할 수 있습니다.
3.3. Vision Transformer (ViT)와 Inductive Bias
- ViT는 CNN과는 다른 구조를 가지고 있으며, CNN의 inductive bias가 상대적으로 약하게 작용
- ViT는 데이터 주도(data-driven) 학습 방식을 통해 이러한 약한 편향을 극복하며, 보다 범용적인(task-agnostic) 구조를 제공
- 그러나 다음과 같은 방법을 통해 일부 inductive bias를 도입합니다:
- MLP Layers와 Locality 및 Translation Equivariance:
- 설명:
- ViT의 MLP 레이어는 각 패치의 특성을 학습하며, self-attention 메커니즘을 통해 국소적 특성 및 위치 변화를 학습
- 이는 CNN에서와 같은 강한 국소성을 제공하지는 않음
- 2D Neighborhood Structure와 입력 패치로 자르는 과정:
- 설명:
- 이미지를 패치로 자르는 과정은 CNN의 필터가 2차원 이웃 구조를 학습하는 방식과 유사하게 작용
- Position Embedding과 Fine-Tuning:
- 설명:
- 위치 임베딩을 통해 패치의 위치 정보를 인코딩하여 이미지의 구조적 정보를 유지
- 이는 학습 후 미세 조정을 통해 더욱 최적화될 수 있음
결론
- ViT는 CNN에 비해 약한 inductive bias를 가지지만, self-attention 메커니즘과 위치 임베딩을 통해 이를 보완하고, 더 범용적인 구조를 제공합니다.
- Hybrid Arichitecture을 사용하기도 합니다.
- Raw image patches + MLP 대신
- Raw image에 CNN을 통과시킨 후, 작아진 image에 대해서 patch=1을 설정
4. Fine-tuning
-
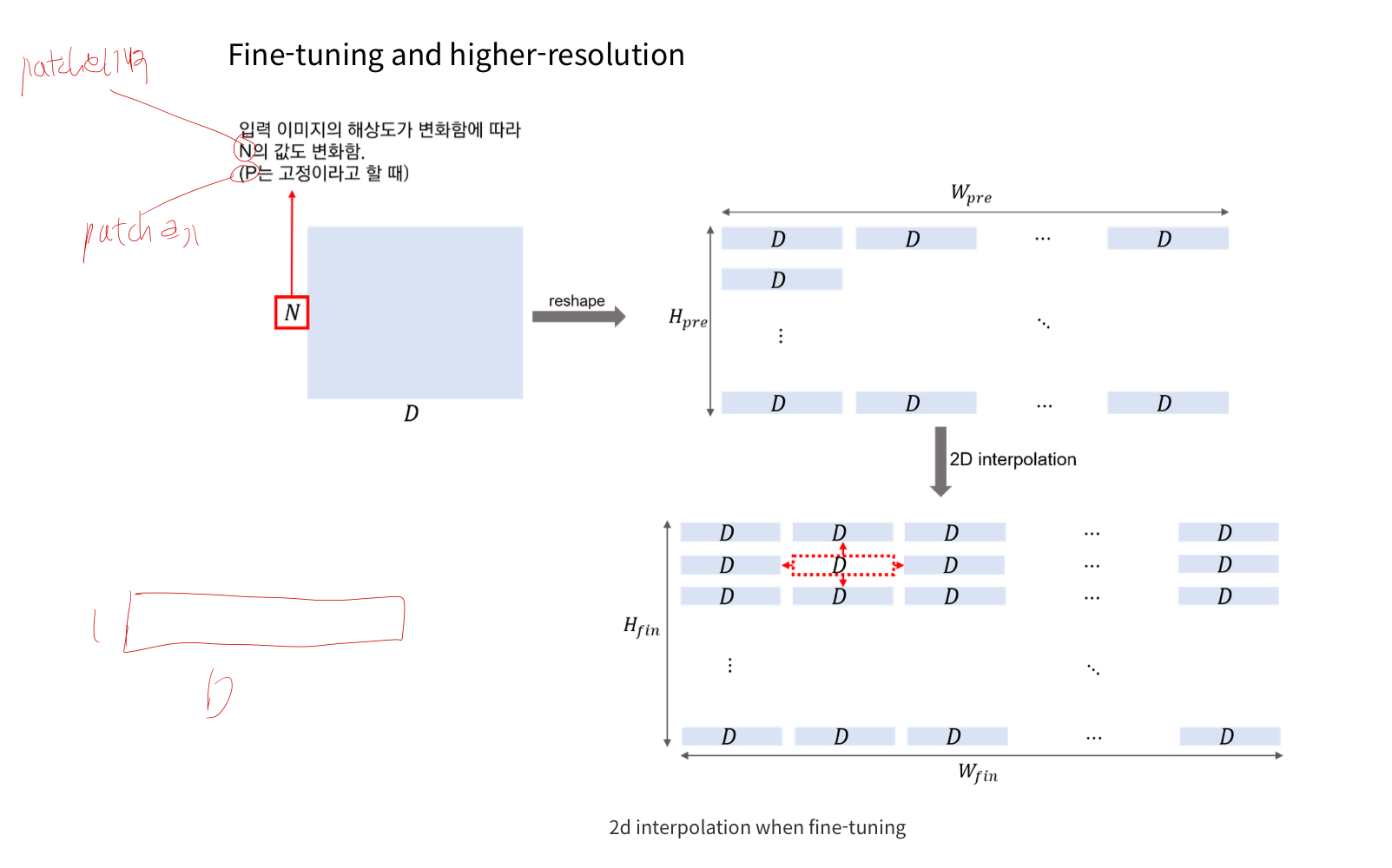
pre-train시 사용했던 patch의 크기가 그대로라면, 만약 fine-tuning시 input image의 해상도가 바뀌면,
- positional encoding을 interpolation 해줘야 함.
-
-
사전학습된 prediction head를 제거하고, 새 head를 가져와서 다양한 Task에 대해 fine-tuning

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것