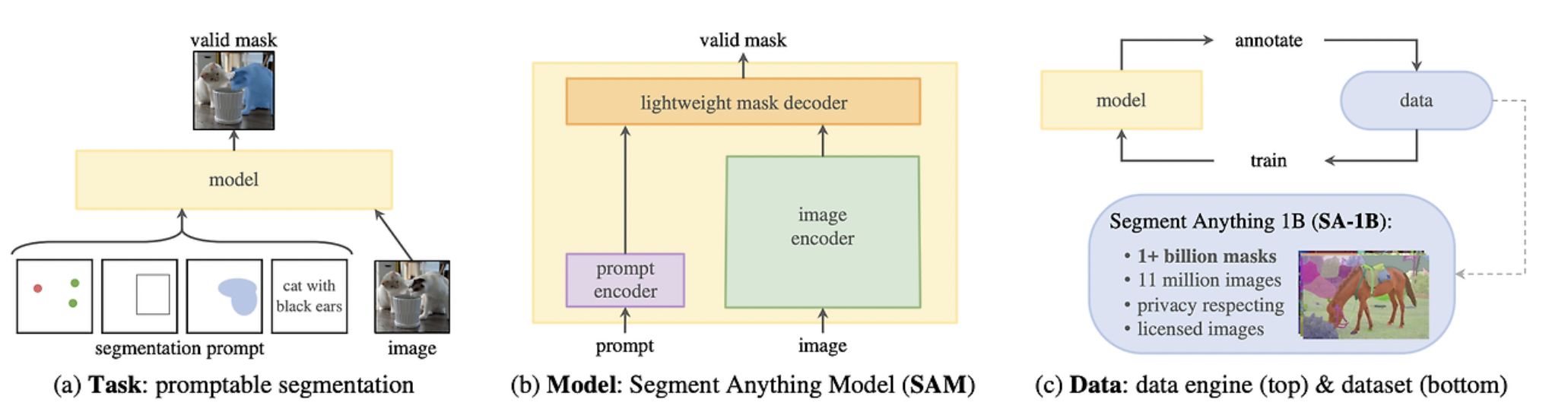
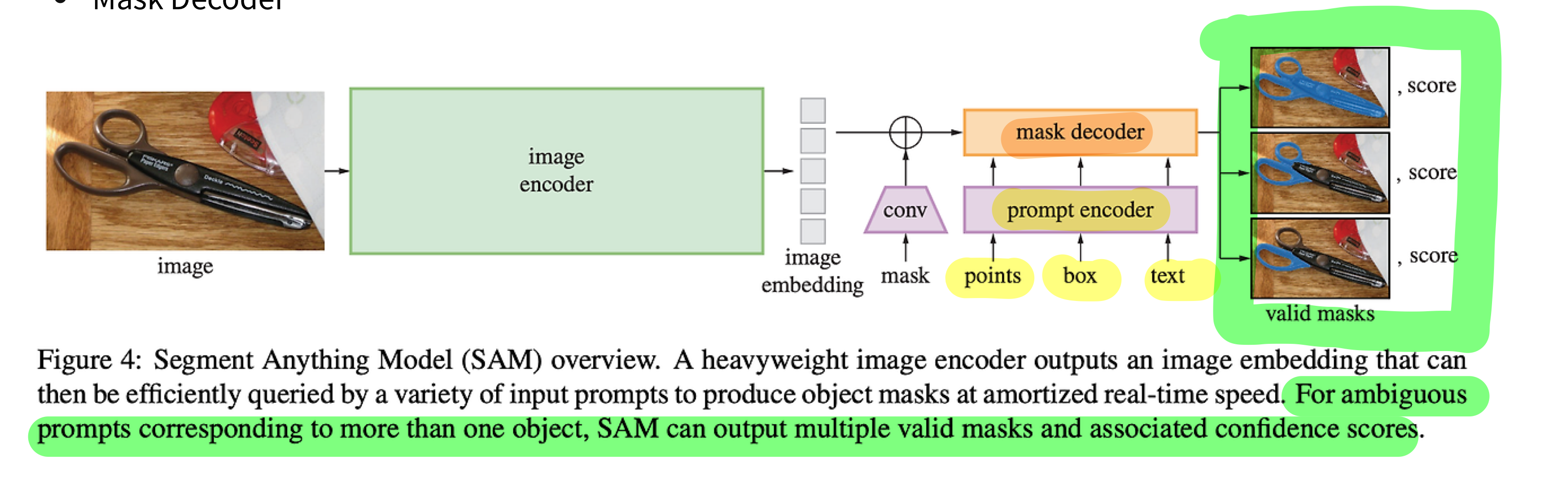
1. Image Encoder
- 연산량 많음
Masked Autoencoder(MAE) pre-trained ViT를 사용Masked Autoencoder(MAE)Vision Transformer
2. Prompt Encoder
- 연산량 매우 적음
- prompt 종류
- sparse point
- 점 points
- 점 좌표가, 이미지 전체에서 차지하는 위치에 대한 positional encoding
(batch, 1, embed_dim) - 해당 Pixel (r,g,b)를 임베딩한 learned embeddings
(batch, 1, embed_dim)
- 점 좌표가, 이미지 전체에서 차지하는 위치에 대한 positional encoding
- 박스 boxes
- 박스의 꼭지점 2개 좌표가, 이미지 전체에서 차지하는 위치에 대한 positional encoding
(batch, 2, embed_dim) - 해당 Pixel (r,g,b) 2개를 임베딩한 learned embeddings
(batch, 2, embed_dim)
- 박스의 꼭지점 2개 좌표가, 이미지 전체에서 차지하는 위치에 대한 positional encoding
- 텍스트 text: CLIP network의 output
- 점 points
- sparse point
3. Mask Decoder
- 연산량 매우 적음

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.