-1. abstract
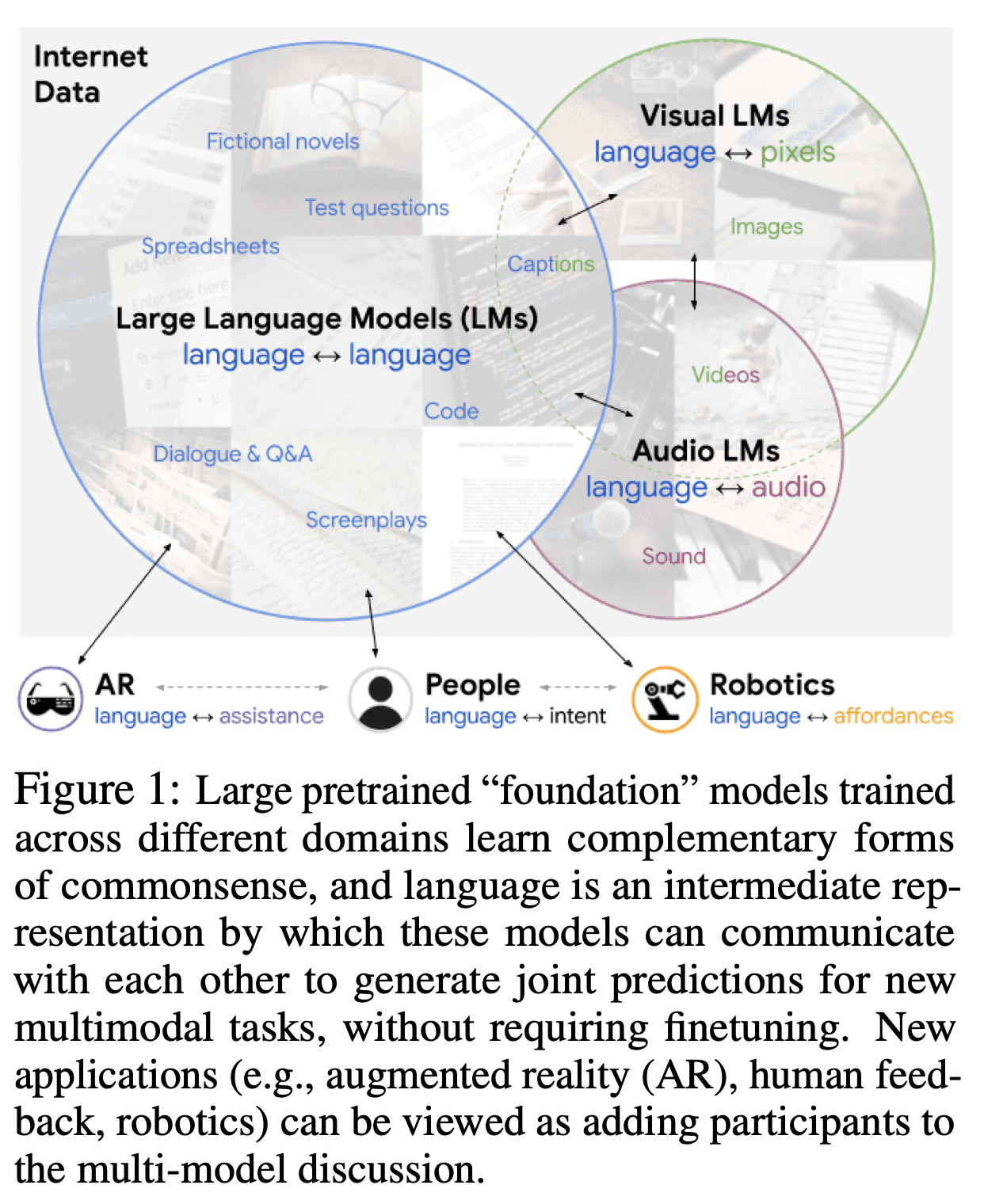
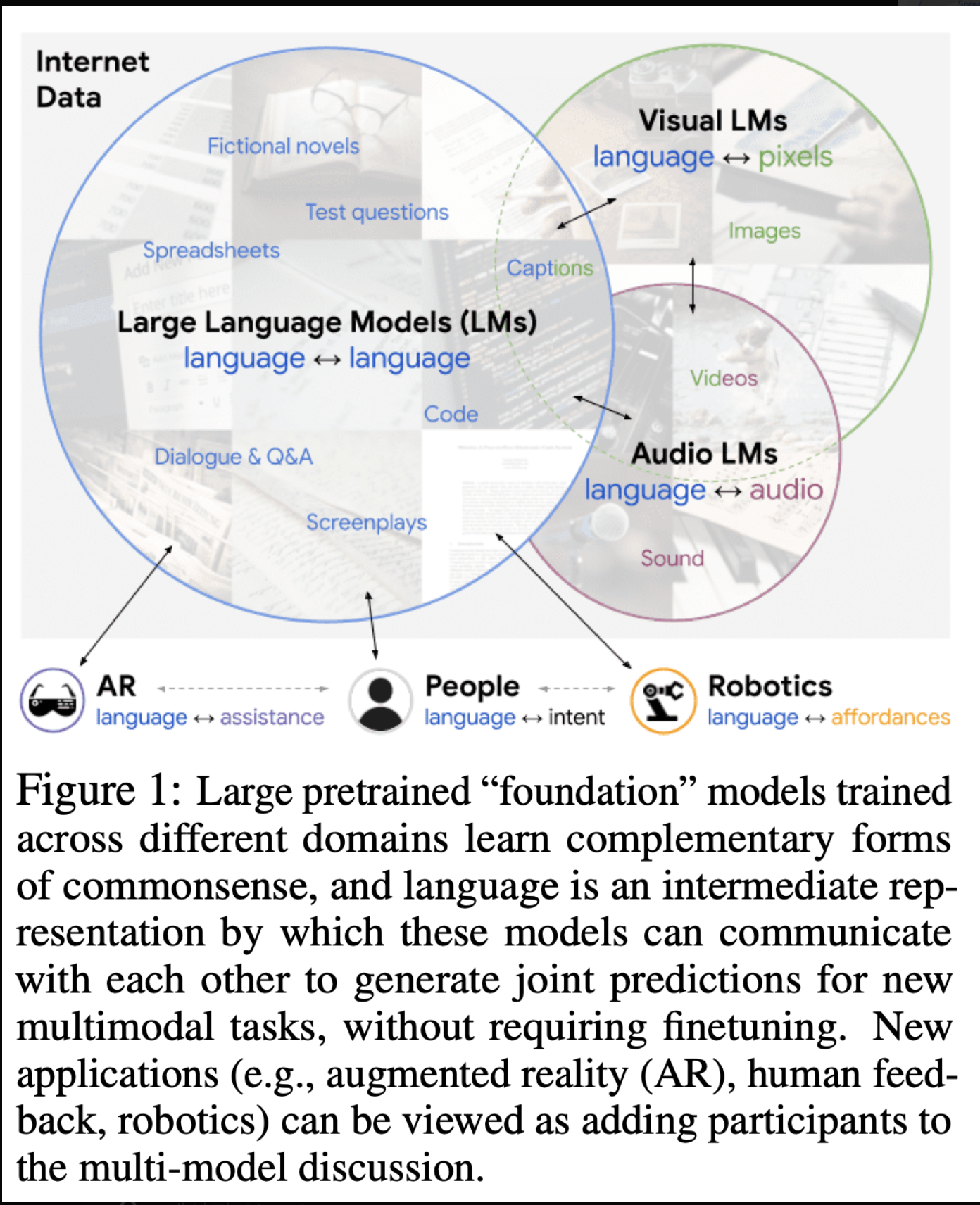
- 대규모 사전 훈련된(예: "Foundation") 모델들은 훈련된 데이터의 도메인에 따라 독특한 능력을 보입니다.
- 이러한 도메인들은 일반적이지만, 서로 겹치는 부분은 거의 없습니다.
- 예를 들어,
- 시각-언어 모델(VLMs)은 인터넷 규모의 이미지 캡션으로 훈련되지만,
- 대규모 언어 모델(LMs)은 (이미지 없이) 인터넷 규모의 텍스트(예: 스프레드시트, SAT 질문, 코드)로 추가 훈련됨
- 그 결과, 이러한 모델들은 서로 다른 도메인에서 다양한 형태의 상식 지식을 저장
- 이 연구에서는 이러한 다양성이 상호 보완적이며, 소크라틱 모델(SMs)을 통해 이를 활용할 수 있음을 보여줍니다.
- 소크라틱 모델은
- 여러 사전 훈련된 모델들을
멀티모달 기반 프롬프팅을 통해 제로샷으로 구성하여, - 정보 교환과 새로운 멀티모달 능력 획득이 가능하게 하는 모듈형 프레임워크
- 여러 사전 훈련된 모델들을
- 소규모 엔지니어링만으로도 소크라틱 모델은 아래 분야의 최첨단 성능과 경쟁할 수 있을 뿐만 아니라
- 제로샷 이미지 캡션 생성 및
- 비디오-텍스트 검색
- 다음과 같은 새로운 응용 프로그램도 가능하게 합니다:
- (i) 자아 중심 비디오에 대한 자유 형식 질문에 답변,
- (ii) 외부 API 및 데이터베이스(예: 웹 검색)와 인터페이스를 통해 사람들과 멀티모달 보조 대화를 진행 (예: 요리법),
- (iii)
로봇 인식 및 계획
-1.1. 추가설명
멀티모달 기반 프롬프팅
- 멀티모달 기반 프롬프팅은 텍스트, 이미지, 오디오 등 다양한 형태의 데이터를 활용하여 모델 간의 상호작용을 유도하는 방법
- 각 모델은 특정 도메인에서 사전 훈련되어 있으며, 이들은 주로 텍스트(언어), 이미지(시각), 오디오(청각) 데이터를 처리하는 데 최적화되어 있습니다.
- 멀티모달 프롬프팅은 이러한 다양한 형태의 데이터를 통합하여. 모델들 간의 상호작용을 촉진하고, 이를 통해 더 풍부한 정보를 교환하게 합니다.
정보 교환
- 각 모델은 자신이 보유한 도메인 지식을 다른 모델과 공유합니다.
- 이를 통해 단일 모델로는 불가능한 복잡한 문제를 해결할 수 있습니다.
- 예를 들어, 이미지 캡션 생성에서는
- 시각 모델:
이미지를 분석하여 텍스트 모델에 전달하고, - 텍스트 모델:
이를 바탕으로 적절한 캡션을 생성
- 시각 모델:
새로운 멀티모달 능력 획득
- 소크라틱 모델은 단순히 기존의 모델들을 결합하는 것이 아니라, 이들 간의 상호작용을 통해 새로운 기능을 획득
- 예를 들어,
- 비디오 데이터를 처리할 때 시각 모델이 프레임을 분석하고,
- 언어 모델이 이를 설명하는 텍스트를 생성하며,
- 오디오 모델이 음성 설명을 추가하는 방식으로 협력할 수 있습니다.
- 이를 통해 단일 모달리티 모델로는 불가능한 복합적이고 정교한 작업을 수행할 수 있습니다.
모듈형 프레임워크
- 모듈형 프레임워크는 여러 독립된 구성 요소(모듈)를 결합하여 전체 시스템을 구축하는 방식
- 소크라틱 모델에서는 각 사전 훈련된 모델이 하나의 모듈로 작동하며, 이 모듈들은 필요에 따라 유연하게 결합되고 재구성될 수 있습니다.
- 이는 특정 작업에 맞게 시스템을 맞춤화하거나 확장하는 데 매우 유용합니다.
0. 그림
0.1. 그림 1
0.2. 그림 2

- 위 그림은 소크라틱 모델(Socratic Models, SMs)이 VLM(Visual Language Model)과 LM(Language Model)의 프롬프팅을 통해
- 제로샷으로
인터넷 이미지에 대한 캡션을 생성하는 방법
- 제로샷으로
- 이 그림은 SM 시스템이 특정 작업에 맞게 fine-tuing된 방법(예: ClipCap)만큼 표현력이 있을 수 있음을 강조합니다.
세부 내용:
- 프롬프트 템플릿:
- 왼쪽 텍스트 상자는 이미지 캡션을 생성하기 위한 프롬프트 템플릿을 보여줍니다.
- 예시: "I am an intelligent image captioning bot. This image is a {img_type}. There {num_people}. I think this photo was taken at a {place1}, {place2}, or {place3}. I think there might be a {object1}, {object2}, {object3},... in this {img_type}. A creative short caption I can generate to describe this image is:"
요약:
- 이 그림은 소크라틱 모델(SM)이 VLM과 LM의 프롬프팅을 통해 제로샷으로 이미지 캡션을 생성할 수 있으며,
- 특정 작업에 맞게 미세 조정된 방법(ClipCap)만큼이나 표현력이 풍부하다는 것을 보여줍니다.
- 이를 통해 SM 시스템이 다양한 도메인에서의 멀티모달 학습과 정보 통합을 통해 강력한 성능을 발휘할 수 있음을 시각적으로 설명하고 있습니다
0.3. 그림 3

- 위 그림은 소크라틱 모델(Socratic Models, SMs)이 VLM(Visual Language Model), LM(Language Model), ALM(Audio Language Model)과 함께 프롬프팅되어
비디오의 주요 순간들에 대한 캡션을 생성하는 과정을 보여줍니다. - 이러한 캡션은 언어 기반의 세계 상태 기록(예: 이벤트 로그)으로 구성될 수 있으며, 이를 통해 LM이 자유형 질문에 답할 수 있습니다.
- 이 그림은 SMs가 비디오의 주요 순간들을 분석하여 캡션을 생성하고, 이러한 캡션을 언어 기반의 이벤트 로그로 구성하는 방법을 보여줍니다.
- 이를 통해 LM은 이러한 로그를 바탕으로 자유형 질문에 답할 수 있습니다.
- 예시로 주어진 질문 - "내가 마지막으로 손을 씻은 때는 언제인가?"에 대해,
- 시스템은 이벤트 로그를 참조하여 정확한 시간을 제공하고, 그 이유를 설명합니다.
- 이는 SMs가 다양한 모달리티 정보를 통합하여 실시간으로 질문에 답할 수 있는 강력한 기능을 가지고 있음을 시각적으로 보여줍니다.
0.4. 그림 4

- 위 그림은 소크라틱 모델(Socratic Models, SMs)이 VLM(Visual Language Model), LM(Language Model), 그리고
언어 조건부 로봇 정책을 활용하여, 로봇이 자유형 인간 명령으로부터 계획을 파싱하고 생성하는 방법을 보여줍니다. - 이 그림은 소크라틱 모델(SM)이 VLM, LM, 그리고
언어 조건부 로봇 정책을 통해 로봇이 인간의 자유형 명령을 이해하고, 이를 기반으로복잡한 작업을 수행하는 과정을 시연 - 이러한 접근 방식은 로봇이 다양한 객체를 인식하고, 주어진 명령에 따라 정확하게 조작할 수 있도록 돕는다.
- 이를 통해 SMs는 로봇 공학 분야에서 강력한 응용 가능성을 보여줍니다.
6. Discussion
- 소크라틱 모델(Socratic Models, SMs)은
여러 대규모 사전 훈련된 모델 간의 구조화된 대화(즉, 프롬프팅)를 통해- 새로운 멀티모달 작업에 대한 공동 예측을 하는 모듈형 프레임워크
- SMs는 다양한 데이터 도메인(예: 텍스트-텍스트, 텍스트-이미지, 텍스트-오디오)에서 사전 훈련된 기초 모델에 저장된 상식 지식을 활용
- 이들 모델은 인터넷 규모의 데이터를 포함할 수 있습니다.
이미지 캡션 생성,비디오-텍스트 검색,자아 중심 인식,멀티모달 대화,로봇 인식 및 계획을 위한 시스템은 SMs 프레임워크의 예시일 뿐이며,- 기존 기초 모델을 적응시켜 새로운 멀티모달 기능을 제로샷으로 캡처하고
- 추가적인 도메인별 데이터 수집이나 모델 미세 조정 없이도
- 이러한 기능을 수행할 수 있는 새로운 기회를 제공할 수 있음
- 또한, 미세 조정 후 성능 저하가 발생하는 분포 변화에 대한 견고성을 유지할 수 있음 [58].
- 잠재적인 미래 작업은 소크라틱 상호작용 자체를 메타 학습하고, 언어 외의 추가 모달리티를 포함하여 모듈 간 엣지를 확장하는 것
- 예를 들어, 모듈 간 이미지를 전달하는 것
광범위한 영향:
- SMs는 추가 데이터 수집이나 모델 미세 조정 없이 기성의 대규모 사전 훈련된 모델을 사용하여 AI 시스템을 구축하는 새로운 관점을 제공
- 이는 여러 가지 실용적인 이점, 새로운 응용 프로그램, 그리고 위험을 초래할 수 있습니다.
- 첫째로, SMs는 비전문가를 포함한 시스템의 행동을 언어를 통해 해석할 수 있는 창을 제공
- 또한, 이 기술의 진입 장벽이 낮습니다.
- SMs는 최소한의 계산 자원으로 새로운 기능을 캡처하도록 설계할 수 있으며, 전통적으로 데이터가 부족한 응용 프로그램을 해결할 수 있습니다.
- 시연된 결과를 생성하기 위해 모델 훈련을 사용하지 않았습니다.
- 이는 가능성을 열어주지만 의도치 않은 최종 사용 응용 프로그램의 유연성을 증가시키므로, 시간 경과에 따라 주의 깊게 모니터링해야 할 잠재적 위험도 증가시킵니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.