-1. 풀고자 하는 문제
-1.1. 로컬 환경 사람 검지 기능 시험개발
- 카메라(RGBD, RGB 모두)를 이용하여, 사람들을 검지
- 1번에서 검지된 사람들에 대해, RGBD camera & 2D-lidar을 기반으로, 거리와 방향을 estimation
- 추가적 목표: ID tracking 시도
거리와 방향이 estimated 된 사람들정보를 이용하여, 주행/서비스 쪽에서 이를 사용할 수 있는 형태로 가공.
-1.2. 개발 결과물
- 로봇 local -> cloud 데이터 송수신 로직 개발
- input
- local에서 카메라 image 송신
- output
- cloud에서 카메라 image 수신
- 설명
- 2월 진행 phase에서, 알고리즘의 자원 소모량 최적화에 대해 깊게 진행하진 않고, 전체적인 pipeline 구축에 더 초점을 맞추고 진행할 계획
- 그러므로, cloud에서 돌리는 것을 먼저 생각 중
- 카메라 기반, human 인지(detection or segmentation)
- input
- 카메라 이미지
- output
- detection: (image plane 상에서) human bounding box 좌표
- segmentation: (image plane 상에서) human pixel 좌표들
- 설명
- cloud에서 구동
알고리즘 성능 평가(성능, inference time)&자원 소모량(CPU, 메모리 사용량)진행- 코드화 진행
- RGBD 카메라 기반
human 인지 결과에 대해, 거리와 방향 estimation
- input
- detection: (image plane 상에서) human bounding box 좌표
- segmentation: (image plane 상에서) human pixel 좌표들
- output
- 검지된 사람들에 대한 방향 및 거리(검지된 사람들에 대한 pointcloud)
- 설명
- 실세계에서의 정량적 평가는 어려울듯.(사람의 거리나 방향에 대한 ground truth가 있는 데이터셋이 있나 조사)
- 개발 내용을 코드화
- RGBD 카메라 기반
- RGB 카메라 기반
human 인지 결과에 대해, 거리와 방향 estimation 및 코드화
- input
- detection: (image plane 상에서) human bounding box 좌표
- output
- 검지된 사람들에 대한 방향 및 거리
- 설명
- bounding box 사각형의 밑면이 사람의 신발 부분이라 가정하에, 거리와 방향 estimation
- camera FOV를 알면,
사람의 발바닥 검지가 가능한 범위를 알 수 있으므로, 그 범위 내에 들어오는 사람들에 대해서만 estimation- z=0이라는 가정으로 IPM(Inverse Perspective Mapping)을 수행
- Lidar나 Depth camera의 정보와 fusion하여 사용 가능할듯.
- 실험적:
사람의 발바닥 검지가 가능한 범위밖에서 검출된 사람이라 할지라도, 방향만 estimation 할 수 있다면, 2d-lidar 정보 등을 이용하여, 거리도 estimation할 수 있지 않을까?
- RGB 카메라 기반
- 2번과 3번의 결과를, fused sensor information에 융합
- input:
- 2번, 3번의 output 정보
- output:
- 팀원들과 논의 필요
- 3d point cloud / 2d local map / 기존 lscan 등의 형태에 반영 가능해 보임
- 해당 사람 정보를 추후 어떤 식으로 활용할지 & 메모리나 연산량 최적화에 따라 좌우될듯
0. 브레인스토밍
- 카메라 2대로부터, streaming 해서 데이터를 실시간으로 받음
방법 1
- 받은 이미지 데이터를, 사람 bounding box 처리함
- bounding box의 pointcloud를 clustering 해서, 사람 point cloud를 뽑음.
- 뽑은 사람 point cloud를, 로봇 중심 좌표계로 변환
방법 2
- 받은 이미지 데이터를, 사람 segmentation 처리함.
- segmentation pixel을 그대로, 사람 point cloud로 처리함
- 뽑은 사람 point cloud를, 로봇 중심 좌표계로 변환
1. 업무 순서
- 로봇에서, 카메라 영상을 확보 (10초 정도)
- realsense를 가지고,
카메라 이미지/뎁스 이미지를 스트리밍 하는 방법 정리 - 코드 구현
- 로봇에서는 어떻게? 할지 정리
- 확보된 카메라 영상을 YOLO로 돌리기
- bounding box로 했을 때 걸리는 시간 조사 (이미지 size에 따른 차이 조사)
- segmentation 했을 때 걸리는 시간 조사 (이미지 size에 따른 차이 조사)
- YOLO 돌린 결과를 -> 사람 point cloud로 변환
- 사람 point cloud를 -> 로봇 중심 좌표계로 전환
- 로봇 중심 좌표계 사람 point cloud -> 2d local map으로 전환.
2. 3가지를 해보자.
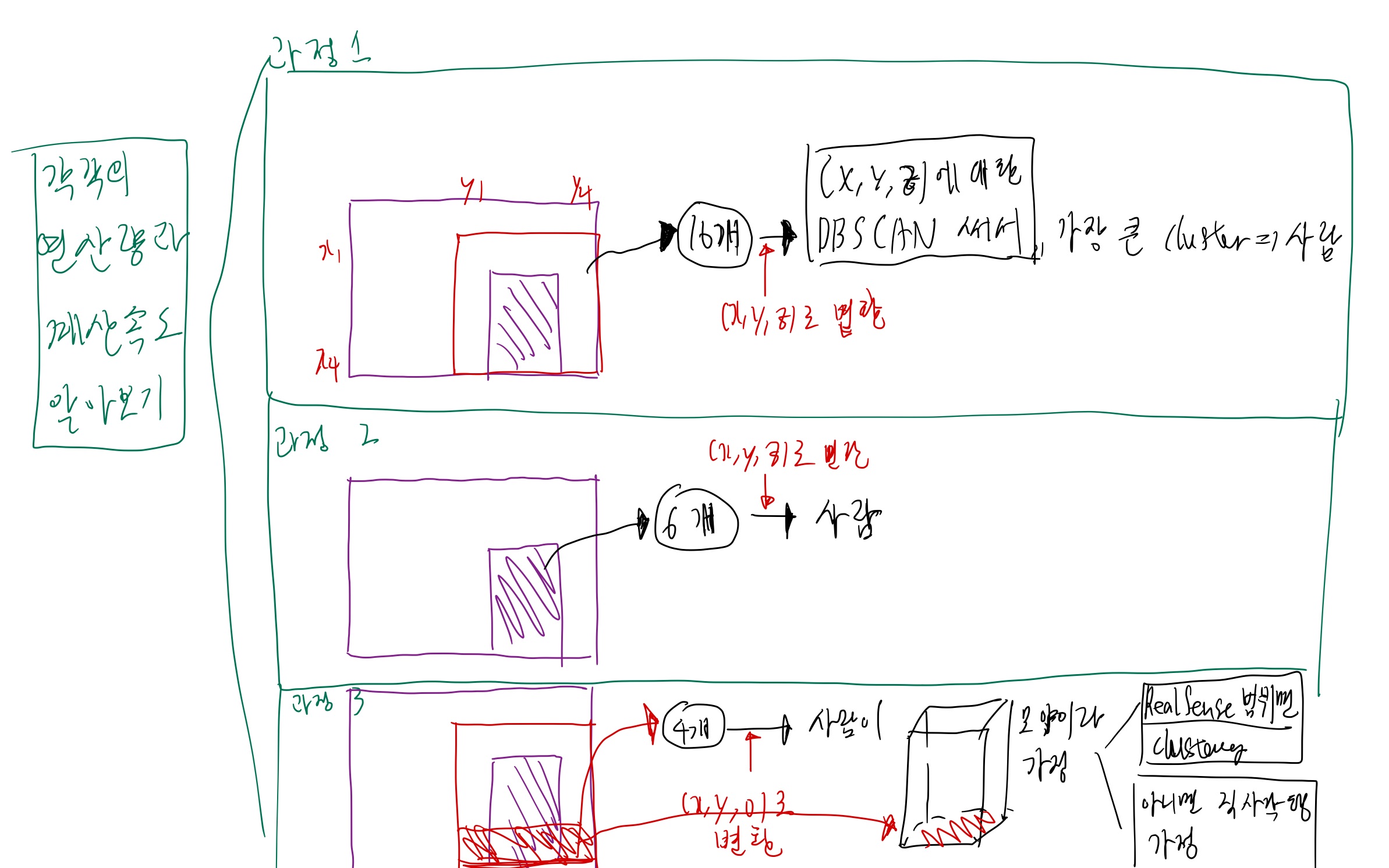
2. 구체화
2.2. 카메라 영상을 YOLO로 돌리기
2.2.1. input/output
- input: 카메라 이미지
- output:
- 사람 bounding box, 사람 tracking 결과, 사람 segmentation 결과
2.2.2. 기대 산출물
- 이미지를 rescaling 했을 때, 소요 시간에 대한 결과
- github 코드
2.2.3. 과정
2.3.3.1. YOLO bounding box 얻어내는 방법
- 공유용: 사람 bounding box 가 있는 영상
- 실제: 사람 bb의 꼭지점 pixel 위치가 중요 (x1,y1,x4,y4)
- 1장에 n명이 있으면, -> (n, 4)
- input이 (480, 640), (240, 320), (120, 160) 일 때의 성능과 속도 분석
결과: 쓸만한 결과 내에서 비교하자.- 메모리 사용량과 CPU 사용량도 비교하자.
- 찍은 비디오를 이용해서, 성능 파악
TODO: 비디오를 input으로 넣어서 돌려보는 법 파악TODO: 비디오의 input size를 바꿔서 넣는 방법 파악TODO: 속도를 측정해서, 1장 당 처리 속도 print 하는 방법 파악TODO: 속도를 빠르게 하는 인자 파악해서 적용
- 어떤 네트워크를 사용할 것인가? -> YOLOv8n (가장 작은 것으로 쓰자.)
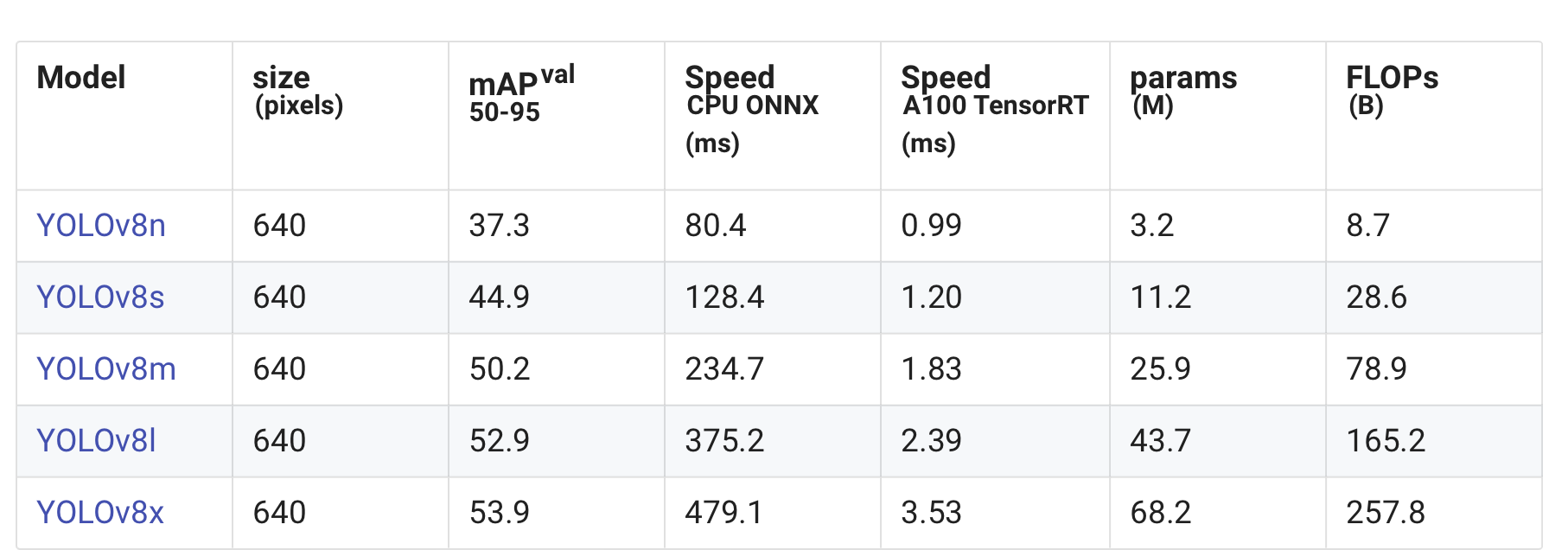
- mAPval values are for single-model single-scale on COCO val2017 dataset.
Reproduce by yolo val detect data=coco.yaml device=0 - Speed averaged over COCO val images using an Amazon EC2 P4d instance.
Reproduce by yolo val detect data=coco128.yaml batch=1 device=0|cpu
- TODO: 모델을 export 할 수 있는데, 이게 어떤 것인지 확인해보기
- predict VS result
- predict
- inference speed를 print는 해주는데, 다른 방법으로 확보하는 방법은 찾지 못했음
- result
- predict
2.3.3.2. YOLO tracking 얻어내는 방법
- 공유용: tracking id가 있는 영상
- 실제: 사람 id
2.3.3.3. YOLO segmentation 얻어내는 방법
- 공유용: segmentation 된 영상
- 실제: human의 pixel

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.