바인딩 변수의 좋은 예
어떤 칼럼 A의 값 A0인 행을 조회하려고 한다.
select *
from some_db
where A = A0;그럼 이러한 SQL문을 날릴 수 있다.
이번엔 A가 A1인 행을 조회하려고 한다.
select *
from some_db
where A = A1;역시 이렇게 쓸 수 있다.
그러나 이렇게 하면 SQL문이 캐싱되지 못한다.
둘은 완전히 다른 쿼리이기 때문이다.
따라서 이를 바인드 변수로 묶어서
procedure FOO(bar in ...) {}로 sql을 구성하는 것이 좋다.
이렇게 하면 하나의 프로시저를 공유하면서 캐싱이 되기 때문이다.
부작용
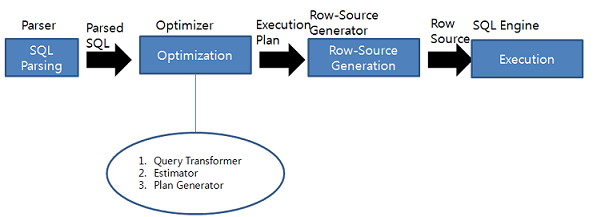
실행 계획을 캐싱하고 나서
실제 실행 시에는 변수 값만 다르게 바인딩 하면서 실행한다.
즉 변수 바인딩은 최적화 이후에 일어나기 때문에,
최적화 시에는 바인딩 한 칼럼의 데이터 분포를 이용하지 못한다.
따라서 바인드 변수를 사용할 시에는
옵티마이저가 해당 칼럼이 표준분포를 따른다고 가정하고 실행 계획의 비용을 계산하게 되는데
실제 데이터도 그렇다면 문제가 없지만,
그렇지 않을 경우엔 실행 시점에 바인딩 된 값에 따라
최적이 아닌 실행 계획이 실행될 수 있다는 문제가 있다.
자세한 이유는 다음과 같다.
통계 데이터의 부재
선택도: 전체 레코드 중에서 조건절에 의해 선택될 것으로 예상되는 레코드의 비율(%)
카디널리티: 특정 액세스 단계를 거치고 나서 출력될 것으로 예상되는 결과 건수
라고 할 때,
기본적으로 카디널리티는 선택도와 전체 레코드 수의 곱으로 표현될 수 있다.
또한 조건문에 따라, 예를 들어 범위 기반 검색 조건에 따라 선택도가 (통계에 의거해) 고정돼 있는데
레코드 수는 일정하므로, 특정 조건문이 포함되는 SQL문의 카디널리티 역시 일정하다.
예를 들어 number > :NO라는 조건문이 있을 때
이때의 선택도는 5%라고 고정되어 있다.
전체 행이 1000개라고 했을 때 옵티마이저는 카디날리티가 50개라고 예측을 할 것이다.
이 결과에 의거해 만들어진 실행 계획에
100을 바인딩 한다면?
실제 카디날리티는 900이 될 것이고,
이는 옵티마이저가 예측한 것과 큰 차이가 난다.
하지만 옵티마이징 당시에는 무슨 값이 나올지 모르므로,
중립적인 선택을 한 것이다.
반면 바인드 변수를 이용하지 않고 literal 상수를 사용하여
number > 100이라는 조건문으로 교체하게 되면
카디날리티는 900으로 나오게 된다.
이는 정확한 칼럼 통계 정보를 이용했기 때문이다.
즉 바인드 변수를 쓰게 되면 캐싱을 할 수 있는 대신 칼럼의 통계 데이터는 활용할 수 없다.
(칼럼 히스토그램 정보를 사용하지 못하는 것이지 이를 제외한 다른 통계정보들은 충분히 활용한다.)
바인드 변수 Peeking
바인드 변수 peeking이라는 기능은
맨 처음 들어오는 바인드 변수의 실제 값을 기반으로
실행 계획을 세우는 기능이다.
하지만 이 기능을 쓰면 SQL 성능이 들쭉날쭉 해진다.
데이터의 분포가 A: 80%, B: 5%, C: 3%, D: 2% 라고 하자.
여기서 조건문에 들어갈 변수를 바인딩 하는 프로시저를 작성했고,
맨 처음에 A를 찾는 SQL문을 작성했다면,
이후에 해당 프로시저를 이용할 때는 사용자가 A를 찾든 D를 찾든
항상 Full Scan을 하게 된다. (선택도가 높은 데이터를 찾을 땐 인덱스보단 Full scan이 더 좋다는 사실이 옵티마이저에 입력됐기 때문에)
적어도 그 실행 계획이 캐시에서 밀려나기 전까진 그렇다.
A가 80%라는 통계 데이터를 기반해서 실행 계획을 짰기 때문에 그렇다.
반대로 맨 처음 D를 넣었다면 인덱스를 사용하기 때문에 나중에 A를 넣을 때 느려질 것이다.
검색을 여러번 반복할 것이기 때문이다.
쿼리 수행 전에 확인하는 실행 계획은 이 바인드 변수 Peeking 기능이 적용되지 않은 실행 계획이다.
이는 물론 Peeking은 1회 실행 시에 등장하는 바인드 변수를 기반으로 행해지기 때문이다.
이렇게 바인드 변수를 쓰면 인덱스 계획에 방해가 되기도 한다.
