SQLP
1.오라클 아키텍처 기본
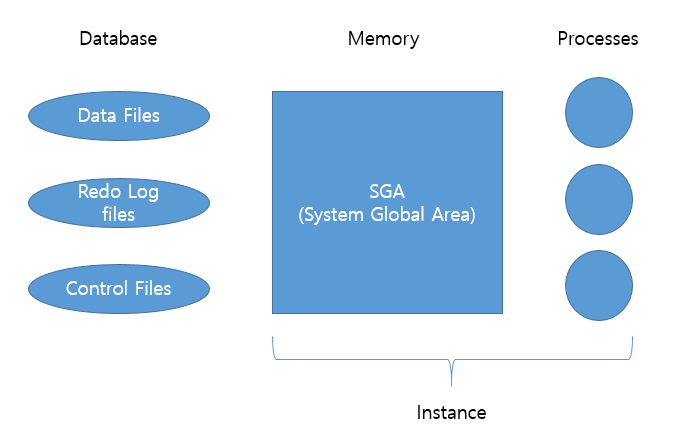
SGA(System Global Area) 라고 하는 메모리 캐시 영역이 있음디스크 (DB)에 직접 접근하는 것보다 훨씬 빠름여러 프로세스가 동시에 데이터 액세스할 수 있으므로 Lock 메커니즘이 필요DB는 Block 단위로 읽고 씀DBWR(DB Writer)와 CKP
2.메모리 구조: DB 버퍼 캐시
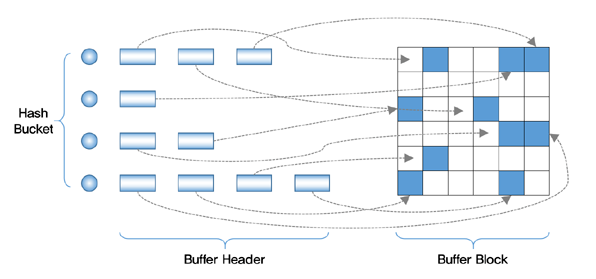
오라클에서 I/O는 블록 단위로 이루어진다.일반적인 경우, 블록을 하나씩 읽지만 (single block read) 테이블 전체를 다 읽어야 하는 full scan 시에는 여러개 씩 읽는다. (multi block read)(Dirty 버퍼를 데이터 파일에 기록하는 과
3.버퍼 핸들이란 무엇인가

많은 사람들이 시스템 성능을 평가할 때 논리적 I/O를 쳐다보는데 시간을 보내며, 논리적 I/O를 CPU 사용량의 큰 지표로서 생각한다. 이는 맞지 않다. 몇 가지 이유 때문에 잘못 가고 있는 것이다. 이러한 가정의 중요한 오류 중 하나는 오라클이 논리적 I/O 를
4.메모리 구조: Redo
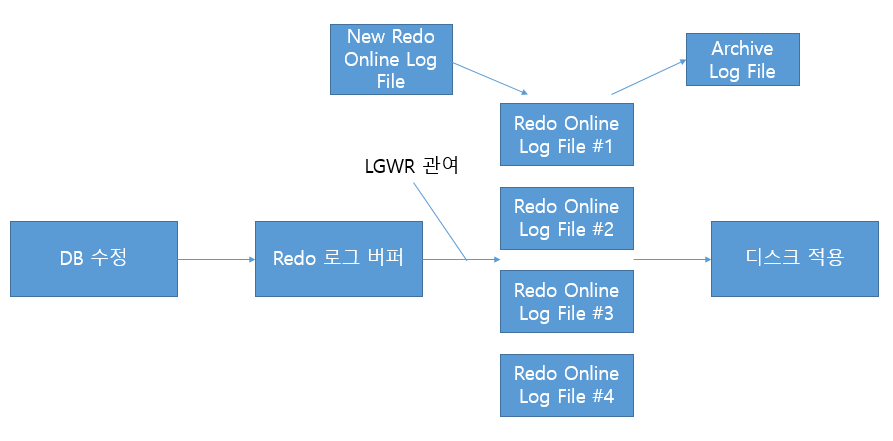
Redo log는 데이터베이스에서 만들어지는 모든 변경 사항을 그때마다 저장하는 로그이다.Datafile 과 control file 의 변경사항은 모두 Redo Log에 기록된다. 변경 사항은 Redo Log 파일에 바로 저장되는 것이 아니라, Redo Log 버퍼에
5.메모리 구조: 공유 풀
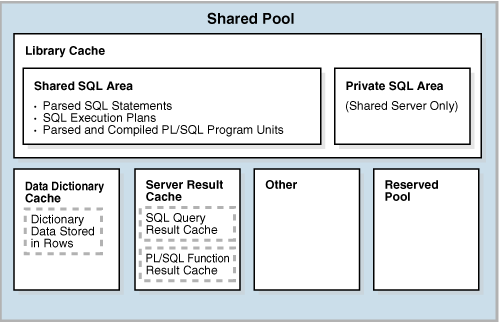
<a href="https://docs.oracle.com/database/121/CNCPT/memory.htm공유 풀은 다양한 유형의 프로그램 데이타를 캐싱한다.예를 들어 공유 풀은 파싱된 SQL 코드, 시스템 파라미터, 데이터 딕셔너리 정보를 저장하고
6.메모리 구조: PGA
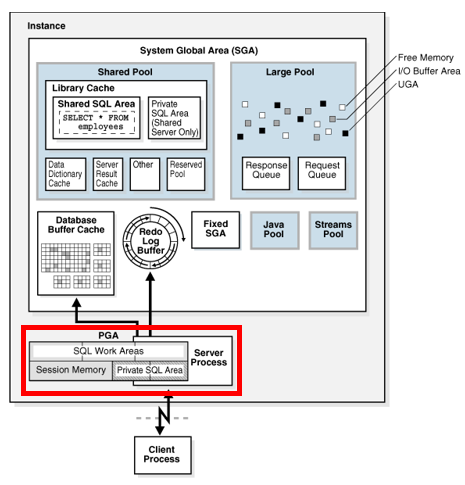
UGA(User Global Area)는 로그온 정보나 세션이 필요로 하는 정보를 저장하고 있는 세션 메모리이다. UGA는 세션의 상태를 저장하고 있다.세션이 PL/SQL 패키지를 메모리로 로드할 때,UGA는 패키지의 상태를 저장하며, 이는 특정 시점의 패키지 변수에
7.대기 이벤트
어떤 프로세스 A가 선행 프로세스가 일을 끝마치기 전까지는 일을 하지 못한다고 할 때, A가 마냥 기다리면서 CPU를 점유하는 것은 자원 낭비이다.그래서 선행 프로세스가 일을 끝내기 전에 sleep 상태로 접어들게 되는데이를 대기 이벤트 (wait event)라고 하며
8.SQL과 옵티마이저
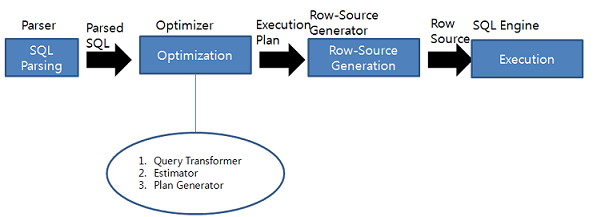
과거의 파일 시스템에서의 DB 프로그래머는 데이터 처리 절차를 일일히 코딩했다.지금은 SQL 언어만 작성하면 DBMS의 SQL 옵티마이저가 이를 대신해준다.사용자가 SQL문을 작성하면, 옵티마이저는 사용자가 원하는 결과를 최저의 비용으로 얻을 수 있는 데이터 처리 절차
9.바인드 변수의 중요성
어떤 칼럼 A의 값 A0인 행을 조회하려고 한다.그럼 이러한 SQL문을 날릴 수 있다.이번엔 A가 A1인 행을 조회하려고 한다.역시 이렇게 쓸 수 있다.그러나 이렇게 하면 SQL문이 캐싱되지 못한다.둘은 완전히 다른 쿼리이기 때문이다.따라서 이를 바인드 변수로 묶어서로
10.Static & Dynamic SQL
Static SQL String 형 변수에 담지 않고 코드 사이에 직접 기술한 SQL. Pro\*C 과 같은 언어로 코드 사이에 SQL문을 작성하면 PreCompile 시에 해당 SQL문이 파싱 되고 권한이 확인되어 String형 변수에 담긴다. 결국 String형 변
11.데이터베이스 Call
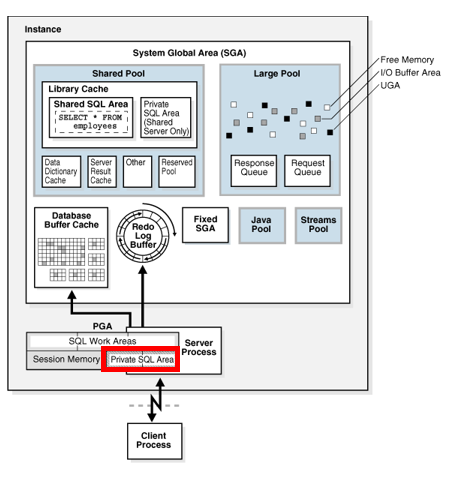
프라이빗 SQL 영역은 파싱된 SQL문과 세션별 정보들을 가지고 있다. 서버 프로세스가 SQL이나 PL/SQL 코드를 실행하면바인드 변수와 쿼리 실행 상태정보, 파싱된 SQL문,쿼리 실행 work area 등 처리에 필요한 정보들은 여기에 저장된다.그리고 여기에 접근하
12.네트워크 부하 감소 전략
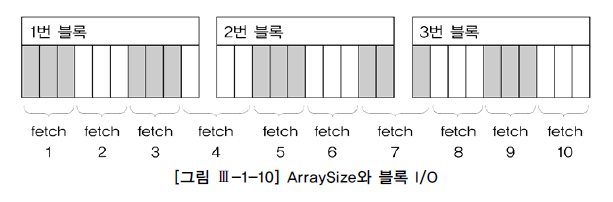
부분범위처리에 따르면, Array가 빨리 채워질 수록 결과를 빨리 받아볼 수 있다.Array가 빨리 채워진다는 건 ArraySize가 작을 수도, Array에 채울 데이터가 많은 것일 수도 있다.데이터의 양이 같다고 가정했을 때,ArraySize는 Fetch Call
13.데이터베이스 I/O 원리
오라클을 포함한 모든 DBMS에서 I/O는 블록 단위로 이루어진다. 내가 한 레코드(한 줄)나 한 칼럼이 필요하더라도 그게 속한 블록 전체를 읽어서 가져온다.오라클의 성능을 좌우하는 것은 이 블록을 얼마나 액세스하는 지이다.그리고 물론 디스크에서 갖고 오는 것보다 버퍼
14.제 1장 문제 1 ~ 10
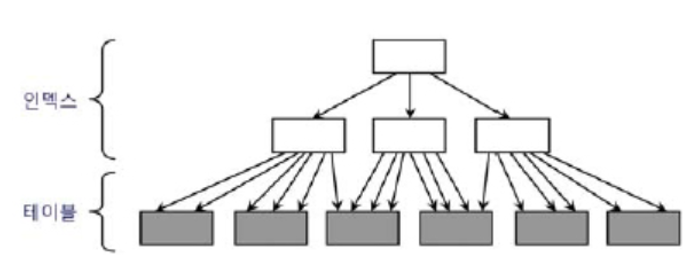
연결 요청에 대한 부하는 쓰레드 기반 아키텍처보다 프로세스 기반 아키텍처에서 더 심하게 발생한다.전용 서버 (Dedicated Server) 방식으로 오라클 데이터베이스에 접속하면 사용자가 데이터베이스 서버에 연결 요청을 할 때마다 서버 프로세스가 생성된다.공유 서버
15.제 1장 문제 11 ~ 20
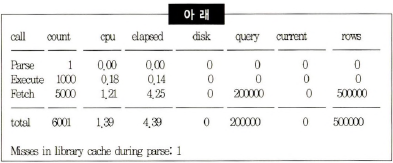
1\. SELECT 문장을 수행할 땐 Execute, Parse, Fetch 순으로 Call이 발생한다.2\. SELECT 문장에선 대부분 I/O가 Fetch Call 단계에서 일어난다.3\. Group By를 포함한 SELECT 문장에서 Group By 결과집합을 만
16.트랜잭션
트랜잭션 트랜잭션은 업무 처리를 위한 논리적인 작업 단위로, 내부의 여러 연산들이 하나의 연산처럼 전부 처리되거나 아니면 (도중에 오류가 발생하는 등의 경우) 하나도 처리되지 않도록 해야 한다. (All or Nothing) 트랜잭션의 특징 Atomicity: 원자
17.Lock
Lock 트랜잭션의 순차적 진행을 보장할 수 있는 직렬화(Serialization) 장치로, DBMS마다 Lock 메커니즘을 구현하는 방식과 세부적인 기능이 다르다. Lock의 종류 공유 Lock 배타적 Lock 갱신 Lock 의도 Lock 스키마 Lock B
18.제 2장 문제 21 ~ 31
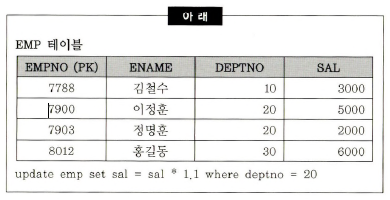
트랜잭션의 원자성을 훼손하지 않는 선에서 트랜잭션을 가능한 짧게 정의할 것같은 데이터를 갱신하는 프로그램이 가급적 동시에 수행되지 않도록 트랜잭션을 설계할 것select 문장에 for update 문장을 사용하지 말 것온라인 트랜잭션을 처리하는 DML 문장을 1순위로
19.옵티마이저
SQL과 옵티마이저에 대해 읽고 오자.옵티마이저는 규칙기반과 (Rule-Based Optimizer, RBO)와비용기반 (Cost-Based Optimizer, CBO)로 나뉜다.RBO는 미리 정해진 일정 규칙에 의거해 옵티마이징을 한다. 규칙들에는 우선순위가 있으며
20.쿼리 변환
옵티마이저의 3개 서브머신, Query Transformer, Plan Generator, Estimator 중 Query Transformer는 더 나은 실행계획을 위해 사용자가 작성한 쿼리를 같은 결과를 보장하는 한에서 수정하기도 한다.서브 쿼리는 쿼리 안의 쿼리로
21.제 3장 문제 32 ~ 42
비용이란 기본적으로, SQL 수행 과정에 수반될 것으로 예상되는 I/O 일량을 계산한 것이다.데이터베이스 Call 발생량도 옵티마이저의 중요한 비용 요소다.옵티마이저가 비용을 계산할 때, CPU 속도, 디스크 I/O 속도 등도 고려할 수 있다.최신 옵티마이저는 I/O에
22.인덱스 기본원리
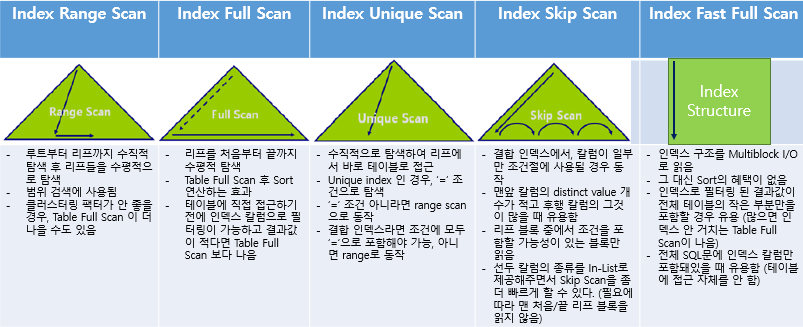
인덱스는 테이블과 같이 세그먼트 단위로 존재한다.인덱스는 테이블의 Skinny 한 버전으로, 테이블의 row(s)를 포함하는 블록은 너무 크기 때문에 한 번 거쳐가는 단계로서 존재한다.인덱스도 블록 단위로 존재하기 때문에 인덱스를 거치는 개수도 중요하긴 하다.인덱스 전
23.인덱스 튜닝
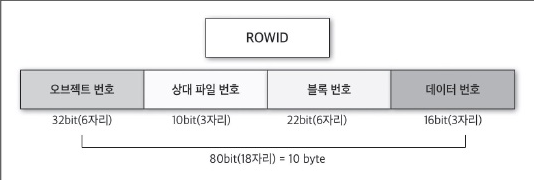
인덱스 변형함 가공, 함수 씌우기, 형변환 등부정형 where id != '123' where idx is null: 검색이 안 됨where idx is not null : 오라클은 인덱스에 null 안 넣어서, 필터링 효과가 전혀 없음where idx1 is n
24.조인
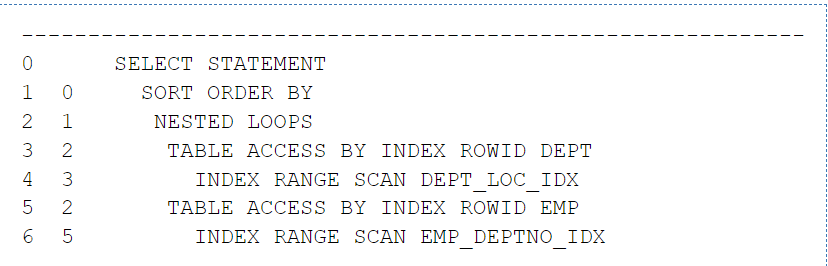
조인 방법에는 크게 세 가지가 있다.1\. Nested Loop Join (NL Join)2\. Sort Merge Join3\. Hash JoinNested Loop Join은 단순한 이중포문으로 구현된다.여기서 바깥 for문에서 쓰이는 table_a를 outer라고
25.제 4장 문제 43 ~ 63
432index_asc이기 때문에 항상 오름차순으로 간다. 시작점은 deptno = 20, sal=2000이다. 오름차순이고, 조건이 comm<=100이기 때문에 comm=100에서 시작할 순 없다.만약 comm >= 100이 조건이었다면 deptno = 20,
26.소트 튜닝
Oracle 실행계획에 나타나는 오퍼레이션 형태를 기준으로 설명한다.전체 로우를 대상으로 집계를 수행할 때 나타난다.실제 소트를 하진 않으며, SQL Server에선 Stream Aggregate라고 표시된다.결과 집합을 단순히 정렬했을 때 나타나는 오퍼레이션이다.So
27.DML 튜닝
그 동안은 조회를 위한 튜닝이었다.이제 데이터를 삽입/삭제하는 DML 튜닝에 대해 알아보자.인덱스는 사실 전적으로 조회를 위한 기능이다.데이터를 수정하면 인덱스도 그에 맞춰줘야 하므로 인덱스는 무조건 DML에 좋지 않다.Update를 수행할 때 테이블 레코드는 직접 변
28.파티션 활용
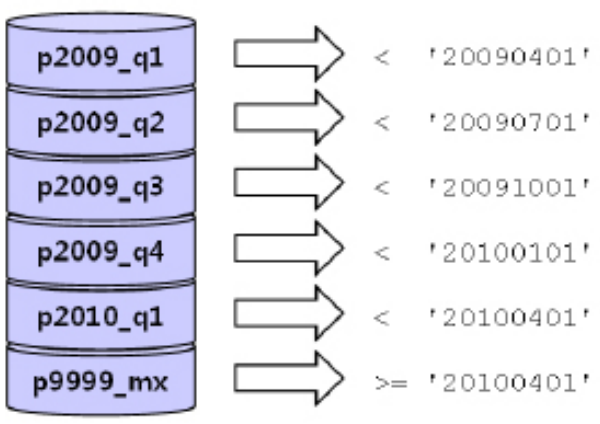
파티셔닝(Partitioning)은 테이블 또는 인덱스 데이터를 파티션 단위로 나누어 저장하는 것을 말한다.테이블과 인덱스 데이터를 파티셔닝하면 파티션 키에 따라 물리적으로 별도의 세그먼트에 데이터를 저장한다.파티셔닝이 필요한 이유는 다음과 같다.관리적 측면: 파티션
29.배치 프로그램 튜닝
배치 프로그램은 일련의 작업들을 하나로 묶어 처리하는 것을 말한다.좀 더 자세히 말하면, 사용자와의 상호작용 없이 대량의 데이터를 처리하는 일련의 작업들을 묶어 정기적으로 반복하거나 정해진 규칙에 따라 자동으로 수행하는 것을 말한다.정해진 시점, 주로 야간에 정기적으로
30.제 5장 문제 64 ~ 82
643sum 함수에서, 레코드 안에서 칼럼끼리 합하는데 하나가 Null이면 Null이 나온다. 근데 각 레코드의 합 결과끼리 합할테는 결과가 Null이 나온 레코드를 무시하고 합한다.1 - (20 + 70)으로 90이다.2 - 첫째 둘째 레코드는 무시되고 세번째 레코드
31.SQLP 실기 기출
ORD_MATERIAL에 대해서 1년 단위로 파티션되어 있음ord_dt로 range scan 하도록 group by 튜닝?join 순서대용량이라는 내용은 없으므로 NL Join 가능할 듯order는 stat_cd가 01, 02 인 것들은 15만 건 order에서 st
32.SQLP 퀴즈
퀴즈3432, 441, 43, 4231RANK242POSITION IS NULL250% 80(1 - disk / (query+current))3441, 341322, 31431221334슈퍼타입과 서브타입을 변환하는 방식에서는 수직분할과 수평분할 방식이 존재하지 않는다
33.실기 문제
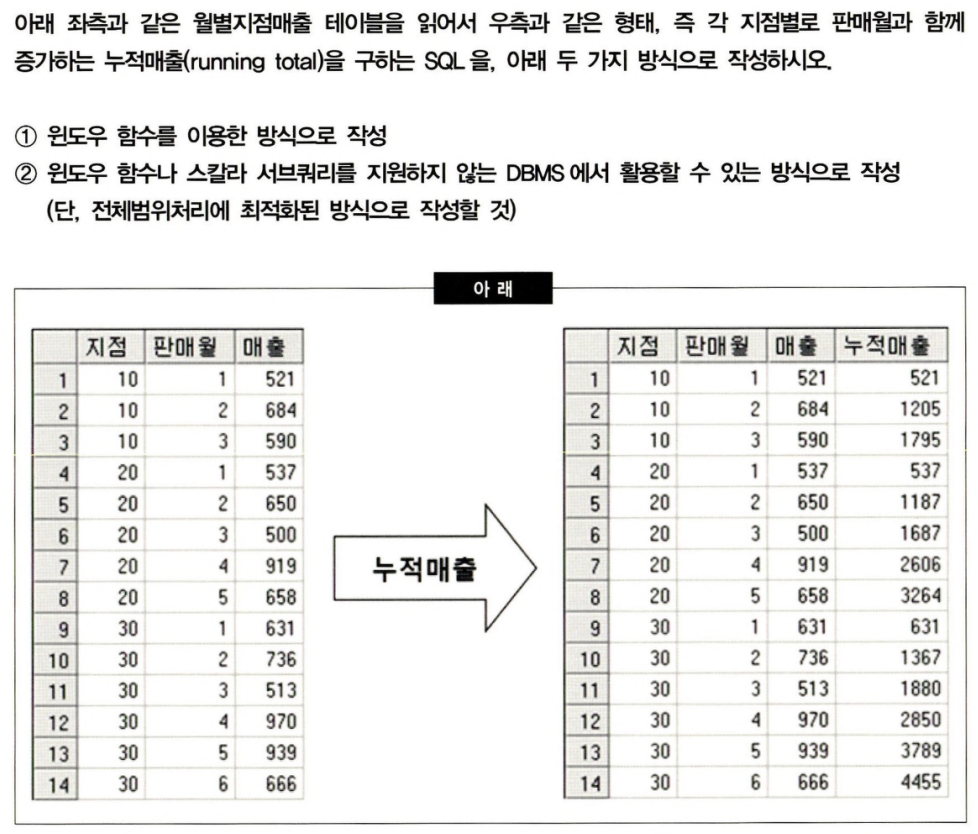
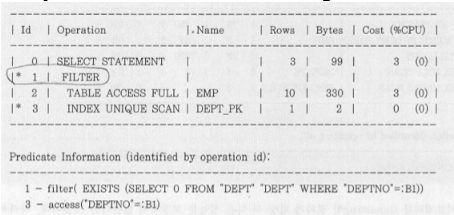
결과는 5개 밖에 안 되는데 주문 테이블에서 45185줄을 다 스캔해버린다.게다가 고객 테이블은 고객 20명 밖에 안 된다.02김철수, 05홍길동은 겹치지 않으므로 union all이 가능하다.부분범위처리를 해준다. NL Join을 사용하도록 하자. 주문 테이블을 먼저
34.제 48회 SQLP 실기 복기
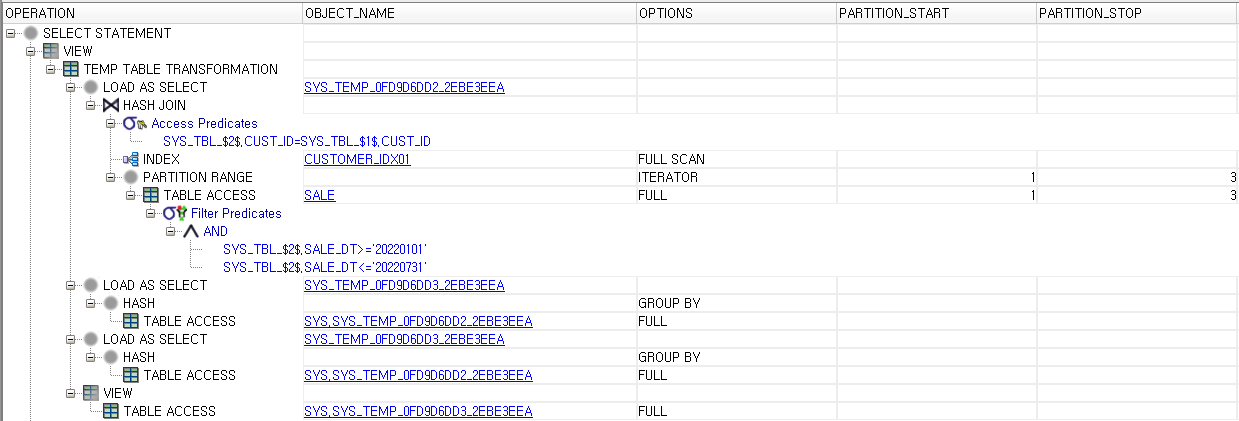
다음 쿼리를 재작성하라. 문제 쿼리에 order by는 없었지만 결과 확인할 때 편하도록 넣었다.