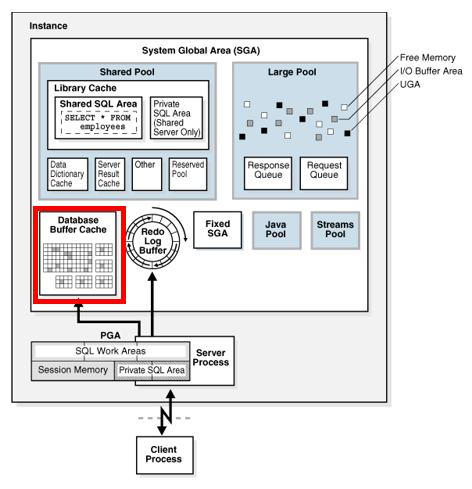
오라클에서 I/O는 블록 단위로 이루어진다.
일반적인 경우, 블록을 하나씩 읽지만 (single block read) 테이블 전체를 다 읽어야 하는 full scan 시에는 여러개 씩 읽는다. (multi block read)
(Dirty 버퍼를 데이터 파일에 기록하는 과정도 multi block read 를 통해 이루어진다.)
액세스하는 블록의 수는 SQL 성능을 좌우한다.
옵티마이저는 이를 줄이는 방향으로 동작한다.
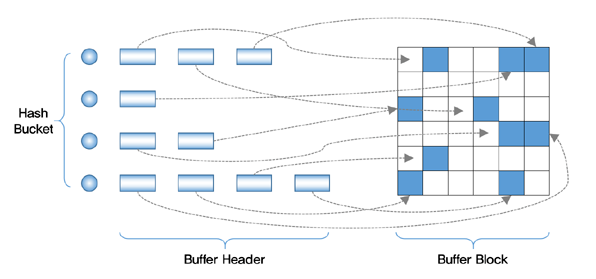
DB 버퍼 캐시의 구조
블록은 저마다 주소를 하나씩 가지고 있는데, 이를 DBA(Data Block Address)라고 한다.
서버 프로세스는 사용하려고 하는 블록의 주소가 주어지면, 이를 먼저 캐시 버퍼에서 찾아본다.
블록 주소를 이용하여 버퍼 헤더(=블록 헤더)를 찾을 수 있는데, 이 버퍼 헤더 안에 버퍼 내 블록의 주소를 얻을 수 있다.
만약 찾지 못한다면, 블록 주소를 따라 디스크에 접근해서 찾아야 한다.
이후 그 블록을 다시 해시에 저장한다.
오라클은 이 해시 자료 구조를 해시 버킷이라고 부르며, 해시 충돌을 피하기 위해 연결 리스트로 체이닝을 한다.
즉, DBA의 해시값이 같은 버퍼 헤더들은 연결리스트로 연결되어 있으며 이를 버퍼 체인이라고 한다.
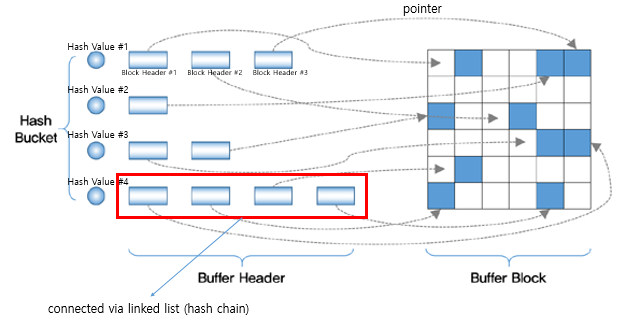
캐시 버퍼 체인
각 해시 체인은 래치(latch)가 보호하며, 이를 cache buffers chain이라고 한다.
래치는 뮤텍스, 세마포어와 같은 Lock 메카니즘이다.
하나의 cache buffers chains 래치는 여러 개의 해시 체인을 동시에 관리한다.
즉, 여러 체인이 한 래치를 나눠쓴다.
만약 어떤 프로세스가 어떤 DBA를 통해 한 해시 체인에 접근하려면 래치를 획득해야 한다.
래치를 접근하면 다른 프로세스는 그 체인에 접근하지 못한다.
이런 방식을 사용하지 않으면 해시 버킷에서 버퍼를 추가하거나 뺄 때 문제가 생긴다.
버퍼 체인에 접근했다면 블록 헤더를 찾아간다.
캐시에 버퍼 넣고 빼기
DB 버퍼 캐시는 LRU 알고리즘으로 관리된다.
현재 사용하려는 블록이 캐시 버퍼에 없다면,
나중에 또 쓰일 때를 대비해서 그 블록을 캐싱해야 한다.
하지만 버퍼 캐시의 공간은 한정적이다.
공간이 모자르다면 누군가는 나가야 하는데,
이때 최근에 쓰인 시각이 가장 늦은 버퍼가 나가게 된다.
RowId로 블록 접근하기
- rowid에서 얻은 DBA를 해시 함수에 넣어서 버퍼 캐시의 특정 버퍼 체인에 접근한다.
- 체인에 접근하기 위해 래치를 얻을 때까지 기다린다.
- 래치를 얻었다면 DBA에 알맞은 버퍼 헤더를 순차적으로 찾고 헤더에 걸린 Lock을 푼다.
다른 프로세스가 해당 버퍼를 너무 점유하고 있으면 busy buffer wait 상태가 돼서 긴 잠에 빠진다. - 이후 rowid의 맨 뒤에 있던 데이터 번호로 레코드에 접근할 수 있다.
- 래치를 얻어서 내가 버퍼에 걸은 lock을 해제한다.
여기서 알 수 있는 사실은, 버퍼 하나에 접근하는데 경합 지점이 세 번 있다는 것이다.
(버퍼 체인 들어갈 때 래치 얻기 / 버퍼 Lock / 읽고 나서 버퍼 Lock 해제 위해 래치 얻기)
버퍼 핸들을 통해 버퍼를 '고정'해두면 그 버퍼를 접근하기 위해 래치를 얻을 필요가 없어진다.
자세한 내용은 아래를 참고하면 된다.
버퍼 핸들이란 무엇인가
