Feature Engineering
Feature Engineering이 중요한 이유
작고 덜 복잡한 모델로도 성능 좋게 낼 수 있음
- more flexibility
- simpler models
- better results
Feature Engineering 기법들
상관 계수
회귀 계수 p-value
의사 결정 트리
Feature Selection
- Feature 쳐내기
Feature Extraction
- raw data를 변환하거나 원래 있는 데이터를 바꿈
Feature Construction
- raw data에서 새로운 feature 만들기
- feature extraciton과 달리 수작업으로 이루어짐
Feature Learning
머신 러닝에서 Feature engineering 순서
select data -> preprocess data -> transform data -> model data
Underfitting / Overfitting
Machine Learning의 목표: "일반적인 패턴"
데이터의 패턴을 '일반화'하여 앵간~한 모델을 만들어야 함.
그러지 못하면? 데이터에 없는, 실제로 모델이 활용되어야 하는 곳에서 생성되는 최신 데이터에 적용을 못한다. (학습 데이터에만 의존하게 됨)
학습 오류: 학습 데이터로 테스트할 때 오류
일반화 오류: 기본 데이터 분포에서 새로운 데이터를 추출, 모델에 적용할 때 예상되는 오류
예측 오류: 테스트 데이터로 학습할 때 오류
학습: 학습 오류와 일반화 오류의 간극을 줄이는 것
일반화 오류는 예측 오류로 추정함
편향과 분산
편향: 예측값이 정답과 얼마나 다른가? - under fitting 야기
분산: 예측값들이 서로 얼마나 흩어져 있는가? - over fitting 야기
입력 변수, 출력 변수가 많아지면 모델이 복잡
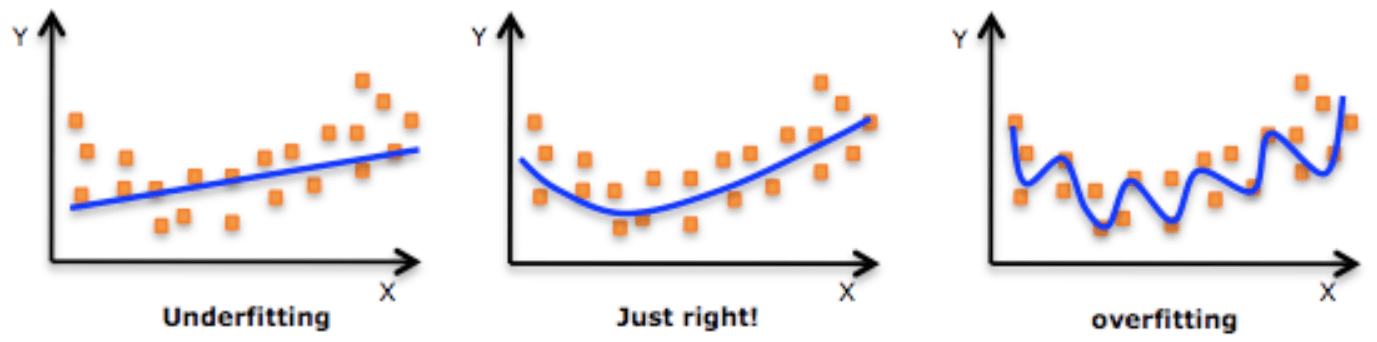
Underfitting
모델이 너무 단순해서 입력 데이터로부터 충분히 학습하지 못하는 현상
대응
deep learning의 경우 학습 시간을 늘린다.
더 복잡한 모델을 구성한다
모델에 추가 Feature 도입
regularization 사용하지 않거나 영향을 줄인다.
Overfitting
지금 보고 있는 데이터를 너무 잘 맞춤 (train data 는 진짜 성능 잘 나오는데 test나 valid data는 성능 안 좋음)
주어진 입력 데이터에 비하여 모델의 복잡도가 너무 높아 입력 데이터의 잡음까지 Fitting
대응
너무 복잡해지기 전에 학습 멈춘다. (실험으로 찾는 수 밖에)
데이터 추가한다
모델의 복잡도 낮춘다
일부 feature 제거
regularization 활용
앙상블 모델 활용
