나이브 베이즈
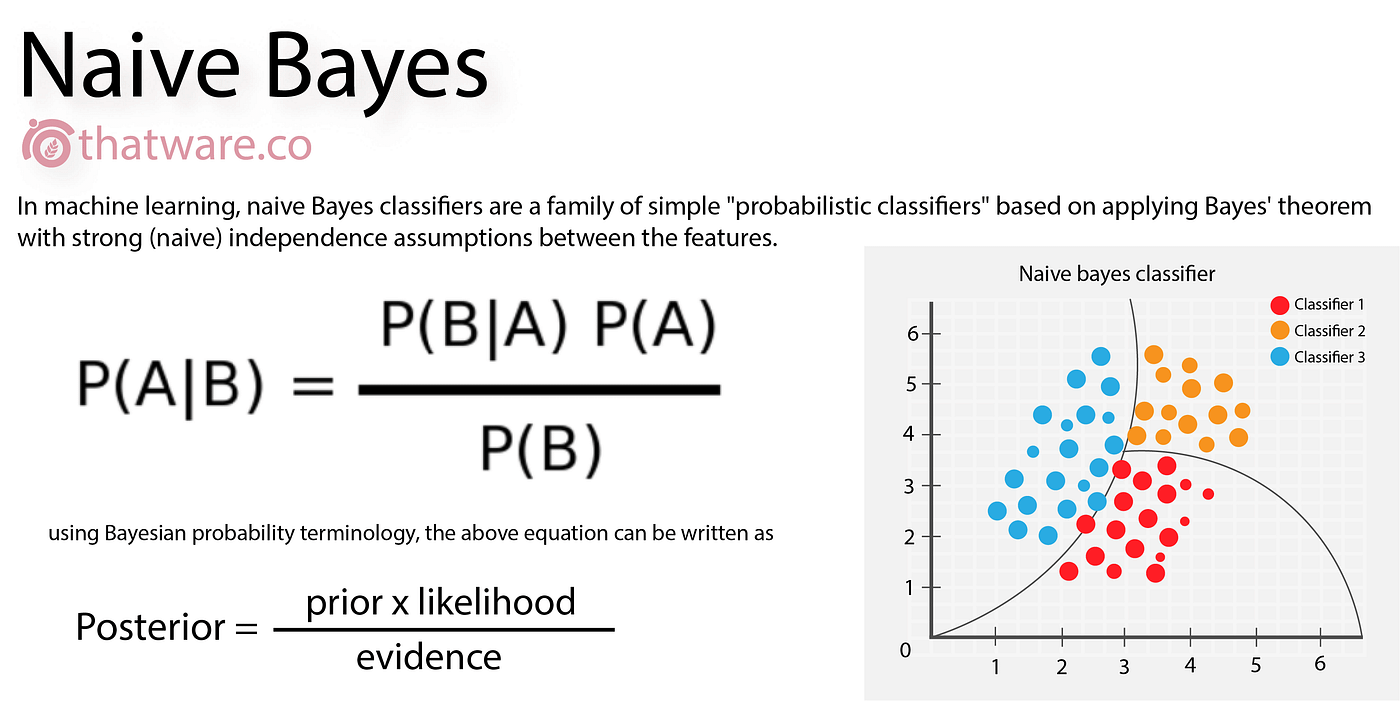
Bayes 법칙에 기반한 분류 기법
각 클래스에 속할 확률이 독립이라고 가정
현실적이지 않기 때문에 naive 라는 이름 붙음
각 클래스에 속할 확률(사후확률)을 구하고 거기서 가장 큰 확률을 가지는 클래스로 분류하는 전략.
베이즈 정리에서 분모 지우고 만 씀
(왜냐면 분모는 어차피 로 똑같고 분자만 비교하면 되기 때문)
Laplace Smoothing
데이터에서 샘플이 없어서 확률이 0이고, 그래서 전체 결과가 0이 나오는 경우. 작은 값을 더해줌
Underflow
아주 작은 확률이 있는 경우에는 컴퓨터가 다룰 수 있는 수의 범위를 넘을 수도 있음. Exp나 Log를 활용
Feature 개수가 증가
기하급수적으로 많은 데이터가 필요함
특징
장점
가장 단순한 지도 학습
적은 양의 데이터로 가능
잡음, 누락에 강하다.
연속형보다는 이산형에서 높은 성능
단점
연속형 수치 많으면 이상적이지 않음 -> 이산화 필요
조건부 확률이 0이 되는 문제
사이즈 적으면 Overfitting 문제
