부분범위처리에 따르면, Array가 빨리 채워질 수록 결과를 빨리 받아볼 수 있다.
Array가 빨리 채워진다는 건 ArraySize가 작을 수도, Array에 채울 데이터가 많은 것일 수도 있다.
데이터의 양이 같다고 가정했을 때,
ArraySize는 Fetch Call 횟수에 영향을 준다.
적당한 ArraySize는 상황에 따르다.
만약 전체 데이터를 다운 받아야 하는 상황이라면 ArraySize는 큰 것이 좋다.
Fetch Call의 횟수를 줄일 수 있기 때문이다.
다만 앞의 데이터만 좀 보다가 멈추는 프로그램이라면 작은 것이 좋다.
불필요하게 많은 데이터를 전송하고 버리는 비효율을 줄일 수 있기 때문이다.
전자의 경우, ArraySize를 크게 설정할 수록 Fetch Call 횟수가 줄어 네트워크 부하가 감소하고, 쿼리 성능이 향상된다.
뿐만 아니라 읽어야 할 블록 개수까지 줄어든다.
1. ArraySize와 블록 I/O 감소
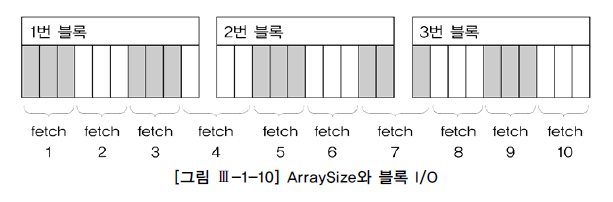
위는 ArraySize=3인 경우이다.
fetch call은 10번 일어나고, 블록 액세스는 12번 일어난다.
1번 블록이 지금 fetch 1~4에서 계속 반복해서 액세스되고 있다.
만일 ArraySize를 10으로 줄인다면
fetch call은 3번, 블록 액세스도 3번이 될 것이다.
30으로 하면 fetch call 1번, 블록 액세스 3번이 된다.
따라서 온라인 조회 기능을 만들 때는
적당한 ArraySize를 설정하고, 페이지 단위로 데이터를 조회하는 것이 성능에 큰 영향을 끼친다.
2. 분산 쿼리
분산된 DB를 조인할 때 성능을 높이는 전략은 조인할 테이블을 줄이는 것이다.
SQL에 조건문이 있어서, 조인된 테이블에서 모든 자료가 쓰이는 게 아니라면
로컬 DB에서 조건문을 실행해서 꼭 필요한,
네트워크로 보내야 하는 행만 보내서 조인하면 성능이 향상된다.
분산 쿼리의 성능을 높이는 핵심 원리는, 네트워크를 통한 데이터 전송량을 줄이는 데에 있다.
3. 사용자 정의 함수/프로시저
사용자 정의 함수나 프로시저는 컴파일 된 형태가 아니라 VM 위에서 돌아간다.
때문에 VM - DBMS 간의 context switching 이 발생하기 때문에 속도가 느려진다.
그래서 앵간한 건 빌트인함수로 구현을 하는 게 좋다.
대용량 조회 쿼리에선 함수를 남발하지 않고, 가급적 조인 또는 스칼라 서브쿼리로 변환하는 게 좋다.

안녕하세요 좋은글 잘읽고갑니다