1.
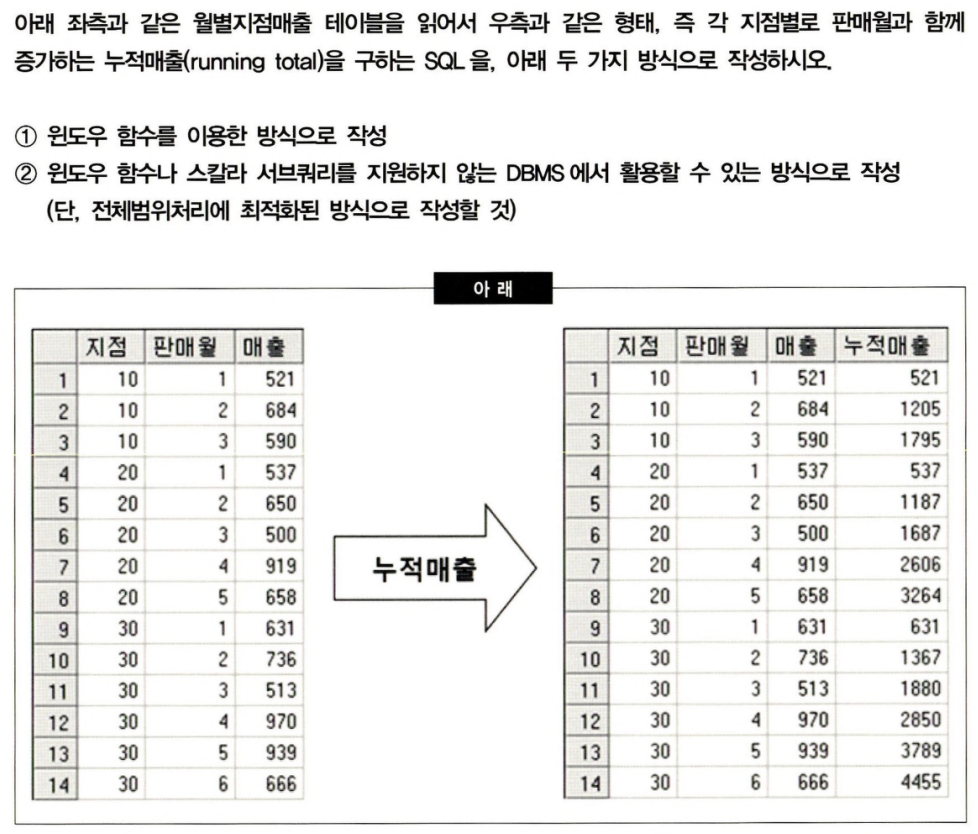
테이블 생성
create table monthly_sales (
id int primary key,
branch int,
month int,
sales int
);
insert into monthly_sales(id, branch, month, sales)
select 1, 10, 1, 521 from dual
union all
select 2, 10, 2, 684 from dual
union all
select 3, 10, 3, 590 from dual
union all
select 4, 20, 1, 537 from dual
union all
select 5, 20, 2, 650 from dual
union all
select 6, 20, 3, 500 from dual
union all
select 7, 20, 4, 919 from dual
union all
select 8, 20, 5, 658 from dual
union all
select 9, 30, 1, 631 from dual
union all
select 10, 30, 2, 736 from dual
union all
select 11, 30, 3, 513 from dual
union all
select 12, 30, 4, 970 from dual
union all
select 13, 30, 5, 939 from dual
union all
select 14, 30, 6, 666 from dual
;답
-- 1
select branch 지점, month 판매월, sales 매출, sum(sales) over (
partition by branch
order by month
rows between unbounded preceding and current row
) 누적매출
from monthly_sales;
-- 2
select a.branch 지점, a.month 판매월, a.sales 매출, sum(b.sales) 누적매출
from monthly_sales a, monthly_sales b
where a.branch = b.branch
and a.month >= b.month
group by a.branch, a.month, a.sales
order by a.branch, a.month;2.
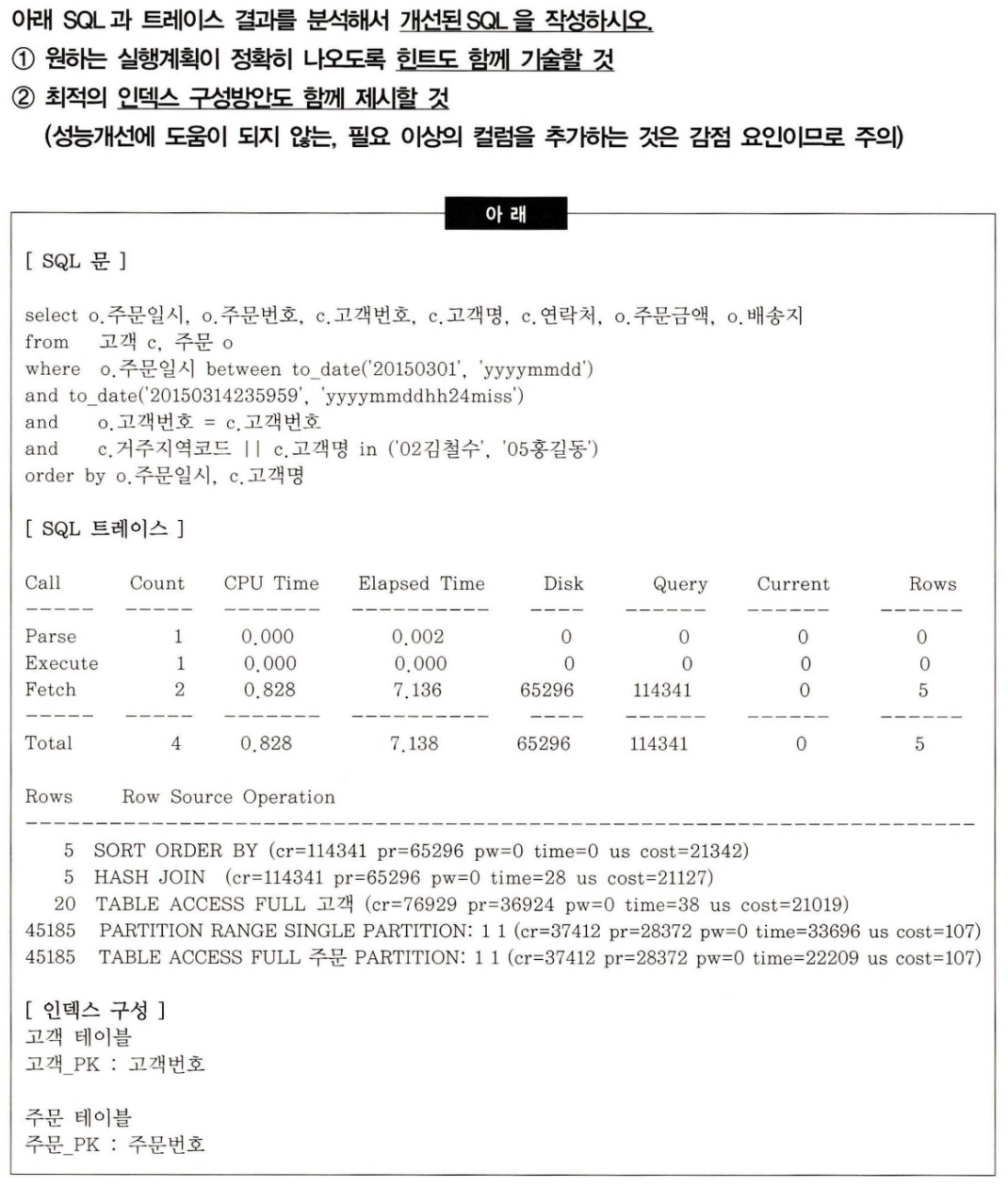
문제점
결과는 5개 밖에 안 되는데 주문 테이블에서 45185줄을 다 스캔해버린다.
게다가 고객 테이블은 고객 20명 밖에 안 된다.
02김철수, 05홍길동은 겹치지 않으므로 union all이 가능하다.
개선안
-
부분범위처리를 해준다.
NL Join을 사용하도록 하자. 게다가 고객이 전체 20명 밖에 안 되므로, 고객에 대해서 먼저 드라이빙 하도록 하자 (고객을 outer로) -
주문 테이블을 먼저 주문일시로 들어간다. full scan을 막기 위해 주문 테이블에 주문일시로 인덱스를 생성해준다.
-
in-list를 쓰면 고객 테이블을 full scan 하게 된다. use_concat 힌트를 사용해서 union all 로 유도한다.
-
고객을 최대한 거르기 위해서 거주지역코드와 고객명에 대해서 인덱스를 생성한다.
개선된 쿼리
고객_IX01: 거주지역코드, 고객명
주문_IX01: 고객번호, 주문일시 local
select /*+ leading(c) use_nl(o) index(c 고객_IX01) index(o 주문_IX01) use_concat */ ~
from 고객 c, 주문 o
where o.주문일시 between to_date('20150301', 'yyyymmdd')
and to_date('20150314235959', 'yyyymmddhh24miss')
and o.고객번호 = c. 고객번호
and (c.거주지역코드, c.고객명) in (('02', '김철수'), ('05', '홍길동'))
order by o.주문일시, c. 고객명3.
같은 데이터를 두 번 읽지 않고도 같은 결과집합을 출력하도록 아래 두 SQL 을 각각 재작성하시오
(단, 부분범위처리 불가능한 상황임. 즉, 전체범위처리 기준으로 튜닝할 것)
- '주문일자,의 데이터 타입은 문자형 8자리
- 거래 업체는 10,000개
- 월평균 주문건수는 100만 건
SQL1
select b.주문번호, b. 업체번호, b.주문일자, b.주문금액, a.총주문횟수, a. 평균주문금액, a. 최대주문금액
from (
select 업체번호, count(*) 총주문횟수, avg(주문금액) 평균주문금액, max(주문금액) 최대주문금액
from 주문
where 주문일자 like '201509%'
group by 업체번호
) a, 주문 b
where b. 업체 번호 = a. 업체 번호
and b.주문일자 like '201509%'
order by a. 평균주문금액 desc위 쿼리는 15년 9월에 있었던 모든 주문 건과 해당 업체의 9월 통계를 비교해 보는 데이터를 뽑는다.
(사실 의도는 모르겠다)
주문 데이터를 9월 통계치 뽑을 때 한 번, 전체 데이터 볼 때 한 번, 총 두 번 보는 문제가 있다.
select 주문번호, 업체번호, 주문일자, 주문금액,
count(*) over (partition by 업체번호) 총주문횟수,
avg(주문금액) over (partition by 업체번호) 평균주문금액,
max(주문금액) over (partition by 업체번호) 최대주문금액
from 주문
where 주문일자 like '201509%'
order by 평균주문금액 desc위와 같이 윈도우 함수를 쓰면 조인할 필요 없이 바로 쓸 수 있다.
SQL2
select b.주문번호, b.업체번호, b.주문일자, b.주문금액
from (
select 업체번호, max(주문번호) 마지막주문번호
from 주문
where 주문일자 like '201509%'
group by 업체번호
) a, 주문 b
where b.업체번호 = a.업체번호
and b.주문번호 = a.마지막주문번호2015년 9월의 업체별 마지막 주문 번호를 찾는다.
select 주문번호, 업체번호, 주문일자, 주문금액
from (
select row_number() over (
partition by 업체번호 order by 주문일자 desc
) rownum,
주문번호, 업체번호, 주문일자, 주문금액
from 주문
)
where rownum = 1윈도우 함수를 사용할 때 top K 알고리즘을 사용하려면 rank나 row_number를 사용하는 것이 좋다.
4.
주문일시로 스캔하기 때문에 이에 대한 인덱스가 필요하다.
또한 고객번호가 안 들어올 수 있기 때문에, 주문일시와 고객번호 + 주문일시를 둘 다 만들어 준다.
그리고 고객번호가 안 들어왔을 때를 대비해서 Null일 경우 고객번호 = 고객번호, 즉 항상 참인 걸로 유도한다.
create index 주문_IDX_01(고객번호, 주문일자) on 주문;
create index 주문_IDX_02(주문일자) on 주문;
select 고객번호, 주문일시, 주문금액, 우편번호, 배송지
from 주문
where 고객번호 = nvl(:고객번호, 고객번호)
and 주문일시 >= to_date(:from_date, 'yyyy.mm.dd')
and 주문일시 < to_date(:to_date, 'yyyy.mm.dd') + 1
order by 주문일자 desc5.
인덱스 구성안
고객 테이블에 고객상태코드로 스캔하고 소트 안 할 수 있도록
create index 고객_IDX_01 (고객상태코드, 등록일시, 고객번호) on 고객;
고객접속이력 테이블엔 (고객번호 + 접속일시) local 파티션 인덱스 추가.
파일로 출력
select /*+ all_rows leading(c) use_nl(h) */ *
from (
select c.고객번호, c.고객명, c.등록일시, c.연락처, c.주소, h.접속일시 최근접속일시,
row_number() over (
partition by c.고객번호 order by h.접속일시 desc
) rownum
from 고객 c, 고객접속이력 h
where c.고객상태코드 = 'AC'
and c.고객번호 = h.고객번호 (+)
and h.접속일시 >= trunc(add_months(sysdate, -1))
order by 등록일시, 고객번호
)
where rownum = 1조회
select /*+ first_rows(60) leading(c) use_nl(h) */ *
from (
select o.*,
rank() over (
partition by o.고객번호 order by h.접속일시 desc
) rank
from (
select *
from (
select 고객번호, 고객명, 등록일시, 연락처, 주소
from 고객
where 고객상태코드 = 'AC'
order by 등록일시, 고객번호
)
)
where rownum <= :page_no * 20
) o, 고객접속이력 h
where o.고객번호 = h.고객번호 (+)
and h.접속일시 >= trunc(add_months(sysdate, -1))
)
where rank = 1
and rownum >= (:page_no - 1) * 20
;1번을 풀고 나서 5번을 봐서인지 window 함수를 썼다.
정답을 보고 나서야 스칼라가 훨씬 낫다는 걸 간과했다는 사실을 알았다.
저렇게 조인해서 윈도우를 쓰면 나중에 소트 연산을 스킵할 수가 없다.
조회에서 페이징의 경우 일단 전체 로우의 개수는 고객상태코드가 AC인 고객과 같으니까 그만큼 뽑고 나서 페이징처리를 일단 해준다. 4페이지라면 사실 상위 80명만 보면 된다. 이렇게 하면 top n 알고리즘도 사용할 수 있을 것이다.
그 다음 최근접속일시를 스칼라 서브쿼리로 구해주면 소트 연산도 없이 정렬된 값을 받아볼 수 있다.
교재 정답에는 없는 내용이지만 조회 기능은 첫 몇 개만 본다고 나와있고 대개 3페이지 이내라고 했으니까 first_rows(60)으로 하면 좋을 것 같다.
6.
야간 배치 -> Hash Join을 쓰라는 말이다.
Hash Join을 쓴다고 하면, 해시 맵을 만드는 데 쓰일 Build Input 의 범위를 최대한 줄여야 한다.
월별 배송건수가 1000만인데 지금 6~8월 3달치를 보고 있으므로 3000만 건 정도 된다.
insert /*+ append */ into 주문배송 t
select /*+ leading(o d c) use_hash(d) use_hash(c) full(o) parallel(4) index_ffs(c) */
o.주문번호, o.주문일자, o.주문상품수, o.주문상태코드, o.주문고객번호, c.고객명, d.배송번호, d.배송일자, d.배송상태코드, d.배송업체번호, d.배송기사연락처
from 주문 o, 배송 d, 고객 c
where o.주문일자 between '20160601' and '20160831'
and o.주문번호 = d.주문번호
and o.주문고객번호 = c.고객번호주문_N3: 주문일자 -> Local Partition
배송_N3: 주문번호
