조인 방법에는 크게 세 가지가 있다.
1. Nested Loop Join (NL Join)
2. Sort Merge Join
3. Hash Join
Nested Loop Join
구현
for row_a in table_a:
for row_b in table_b:
if row_a.column = row_b.column:
do_something()Nested Loop Join은 단순한 이중포문으로 구현된다.
여기서 바깥 for문에서 쓰이는 table_a를 outer라고 하고 이를 driving되는 테이블이라고 한다. 먼저 접근하는 테이블이다.
안쪽의 table_b는 inner 테이블이다. driving 되는, driven 테이블이다.
예시
select /*+ ordered use_nl(e) */
e.empno, e.ename, d.dname, e.job, e.sal
from dept d, emp e
where 1=1
and e.deptno = d.deptno /* 1 */
and d.loc = 'SEOUL' /* 2 */
and d.gb = '2' /* 3 */
and e.sal >= 1500 /* 4 */
order by sal desc
;dept 테이블은 pk가 deptno이고,
dept_loc_idx - dept_loc을 인덱스로 가진다.
emp 테이블은 pk가 empno이고,
각각 emp_deptno_idx - deptno, emp_sal_idx - sal을 인덱스로 가진다.
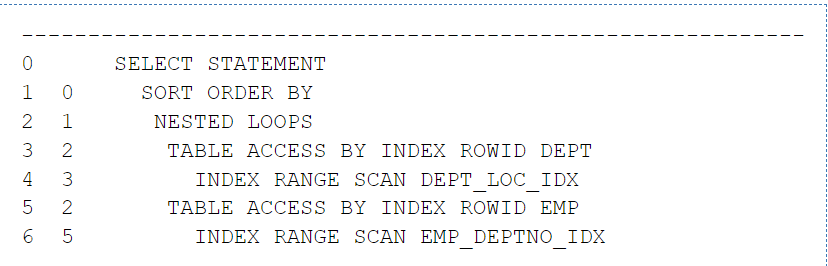
조건절의 deptno가 dept의 pk이고 인덱스이기 때문에 (pk는 자동으로 인덱스 생성) dept가 드라이빙 된다.
또한 loc도 인덱스이기 때문에 loc으로 인덱스 범위 스캔을 할 것으로 예상할 수 있다.
- dept_loc_idx로 loc='SEOUL'인 레코드에 접근한다.
- 그 레코드의 rowid로 dept 테이블 액세스해 gb='2'를 만족하는 레코드를 고른다.
- 그 레코드의 deptno를 가지고 emp 테이블을 index range scan 한다.
- scan 된 rowid로 emp 테이블에 액세스해서 sal >= 1500 인 레코드를 찾는다.
- 그렇게 찾은 레코드들을 정렬해서 결과를 리턴한다.
이 조인 예시에서 세 개의 부하 지점이 있다.
첫번째는 loc='SEOUL'인 레코드를 찾아서 gb를 보기 위해 테이블에 접근하는 부분에서이다.
이 부분에서 random access가 발생하는데 만약에 gb의 선택도가 너무 높다면, 그리고 이와 같은 검색이 빈번하다면 인덱스를 loc + gb로 결합하는 방안도 고려해야 한다.
두번째는 gb='2' 필터링 이후 deptno로 emp를 index range scan 할 때이다. loc='SEOUL', gb='2' 조건을 만족하는 deptno가 여럿이면 이 스캔이 빈번하게 일어날 것이다. emp의 deptno 인덱스의 height가 높다면 그것도 문제가 될 수 있다.
세번째는 emp_deptno_idx를 읽고 리프 블록마다 emp 테이블에 접근하는 지점으로, 이것도 random access로써 부하가 될 수 있다. 게다가 그렇게 겨우겨우 액세스 해서 레코드를 막상 까보니까 sal >= 1500인 게 별로 없다면 emp_deptno_idx에 sal을 추가하는 방안도 고려할 필요가 있다.
특징
-
NL join은 Random Access 위주의 조인 방식이다. 인덱스 구성이 아무리 완벽하더라도 대량의 데이터에는 장사 없다.
-
조인을 한 레코드씩 순차적으로 진행한다. 다른 두 조인 방식은 전체적으로 진행하기 때문에 필요한 레코드에 비해 시간을 많이 잡아먹을 수도 있지만 NL Join은 부분범위처리를 할 경우 레코드별로 진행을 조금 할 수도 많이 할 수도 있다. 즉 먼저 액세스 되는 테이블의 처리 범위에 따라 전체 일량이 결정된다.
-
다른 조인 방식에 비해 인덱스 구성 전략이 특히 중요하다. 인덱스 칼럼 구성 방식에 따라 조인 효율이 크게 달라진다.
종합적으로, NL Join은 소량의 데이터를 주로 처리하거나 부분범위처리가 가능한 온라인 트랜잭션 환경(OLTP)에 적합한 조인 방식이라고 할 수 있다.
Sort Merge Join
구현
NL Join은 두 테이블 중 뭘 outer로 두고 뭘 inner로 두는지에 따라 효율이 달라진다.
조건절에서 먼저 outer 테이블에서 조인할 레코드들을 걸러야 하는데 별로 못 거르면 그대로 inner 테이블과 조인해서 그만큼 스캔하기 때문이다.
게다가 inner 테이블의 인덱스 선두 칼럼에 조인 칼럼이 없으면 index range scan을 할 수 없기 때문에 full scan을 할 수 밖에 없다.
이때 옵티마이저는 nl join이 아닌 다른 방법을 수행한다.
소트 머지 조인은 두 단계로 나뉘어서 실행된다.
- 소트 단계: 양쪽 집합을 조인 칼럼 기준으로 정렬한다.
- 머지 단계: 정렬된 양쪽 집합을 서로 합병(merge)한다.
oracle의 경우 outer 테이블 쪽 조인 칼럼이 인덱스 칼럼이라면 소트를 하지 않고 조인할 수 있다.
오라클은 조인 조건의 연산자가 부등호이거나 조인 조건이 없어도 sort merge join으로 처리할 수 있지만 SQL Server는 조인 연산자가 '='일 때만 할 수 있다.
예시

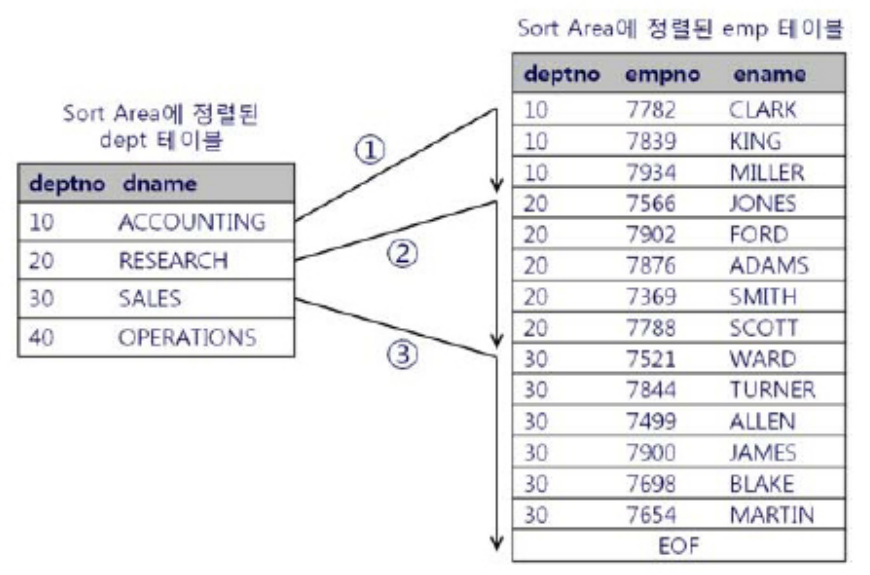
deptno가 10인 레코드에서 출발해서, emp 테이블을 deptno=10인 부분을 읽다가 10이 아닌 부분이 나오면 멈추고 dept 테이블의 레코드를 하나 밑으로 내린다.
그리고 20부터 시작해서 아까 멈췄던 지점(그림에선 사번 7566)부터 다시 조인한다.
특징
1. 조인하기 전에 양쪽 집합을 정렬한다.
대용량의 경우 NL Join을 쓰면 Random Access 때문에 비효율적일 수 있어서 Sort Merge Join이 그 대안이 될 수 있다.
근데 Sort Operation 때문에 너무 대용량이어도 안 된다.
인덱스로 조인하거나 클러스터형 인덱스 혹은 IOT의 경우 미리 정렬이 되어있기 때문에 정렬을 안 하고도 가능하다.
2. 부분적으로, 부분범위처리가 가능하다.
부분적으로 가능하다. outer 집합이 조인 칼럼 순으로 미리 정렬된 상태에서 사용자가 일부 로우만 fetch하다가 멈춘다면 outer집합을 끝까지 읽지 않아도 된다. 문제에서 sort merge join이 아예 부분범위처리가 불가능하다고 한다면 그건 틀린 보기일 것이다.
3. 테이블별 검색 조건에 의해 전체 일량이 좌우된다.
NL Join은 outer 집합의 매 건마다 inner 집합을 탐색한다. 따라서 outer 집합에서 조인 대상이 되는 건수에 따라 전체 일량이 좌우된다. 그러나 sort merge join은 테이블별 검색 조건, 즉 양쪽 집합의 전체 크기가 얼마나 줄어드냐에 따라 전체 일량이 정해진다.
4. 스캔 위주의 조인 방식이다.
조건절로 각 집합을 만들 때 Random access가 발생하고 나선, 스캔 위주의 조인 방식이다. 다만 이때 Random access 가 너무 많이 발생하면 sort merge join을 안 하느니 못하다.
Hash Join
Hash Join은 두 조인 방법이 효과적이지 못한 상황을 해결하고나 나온 방식이다.

Hash Join은 둘 중 작은 집합을 읽어 해시 영역에 조인 칼럼을 입력으로 받아 레코드 데이터를 출력하는 해시 맵(=해시 테이블)을 생성하고, 반대쪽 집합을 읽으면서 조인 칼럼을 해시 맵에 입력해 데이터를 찾아보며 조인하는 방법이다.
여기서 해시 맵을 생성하는 작은 집합은 build input, 나중에 해시 맵을 사용하는 큰 집합을 probe input이라고 한다.
- 더 작은 집합(=build input)을 읽어 해시 맵을 만든다. 해시 충돌에 대비해서 같은 해시값을 가지는 데이터들은 연결리스트로 연결한다.
- probe input을 스캔한다.
- 스캔한 데이터의 조인 칼럼을 해시 함수에 입력해서 build input의 레코드를 얻어 조인한다.
Hash Join은 NL Join처럼 Random access 부하도 없고 Sort Merge Join처럼 정렬하는 부담도 없다.
다만 해시 맵을 만드는 게 좀 부담되는데, 그래서 Build input이 적어야 효과적이다. 만약에 해시 맵을 만드는 데 필요한 메모리가 부족하면 디스크 공간까지 써서 왔다갔다 하기 때문에 비효율적이다.
build input이 작은 것도 중요하지만 해시 키 값, 조인으로 사용되는 칼럼에 중복값이 없어야 한다.
많으면 해시 체인이 많이 발동해서 연결리스트 탐색 시간이 길어진다.
해시 테이블을 만드는 단계는 전체범위처리를 해야 하지만 반대쪽 probe input을 스캔하는 단계는 부분범위처리가 가능하다.
Build Input이 가용 메모리를 초과할 때
Hash Join은 해시 맵을 만드는 데 쓰이는 메모리가 충분하도록 build input이 작아야 한다.
build input이 너무 크면 in-memory hash join이 불가능해지는데, 그땐 Grace hash join이라는 방식을 사용한다. Grace Hash Join은 Divide & Conquer 방식이기도 하다.
1. 파티션 단계 (Divide)

초기 상태. 두 테이블을 버퍼의 크기대로 나눈다.
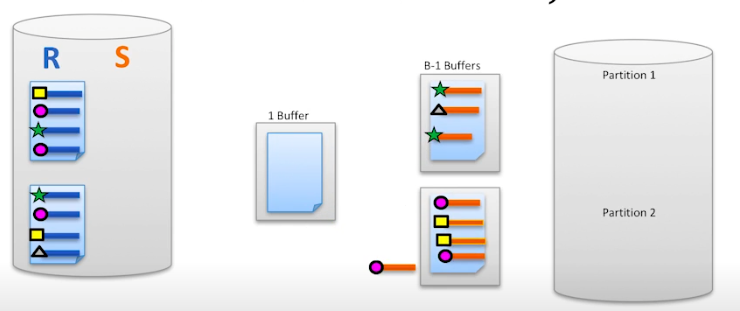
입력 버퍼 (1 Buffer로 표기됨)에서 해시 함수를 적용하여 출력 버퍼(B-1 Buffer로 표기됨)로 옮긴다. 이때 반환되는 해시 값에 따라 동적으로 파티셔닝을 실시한다.
이 단계에서 양쪽 집합을 모두 읽어 디스크 상의 Temp 공간(위 그림의 버퍼들)에 일단 저장해야 하므로 in-memory hash join보다 성능이 떨어진다.
위의 초록별과 검은삼각형은 partition1으로, 아래 버퍼의 분홍원과 노란네모는 partition2로 간다.
최종 결과는 다음과 같다.

2. 조인 단계 (Conquer)
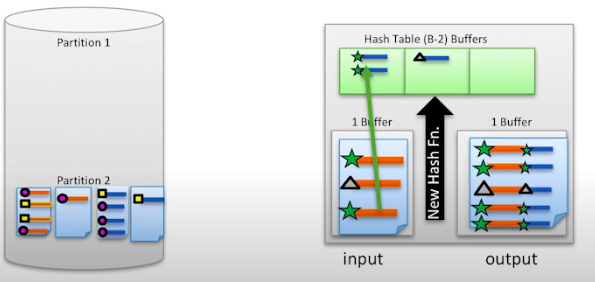
일반적인 hash join에서는 작은 테이블을 기준으로 해시 맵을 만들지만 grace hash join에서는 작은 파티션이 기준이 된다.
위 그림에서 output이 일단 완성이 됐으므로 결과 집합에 추가한다.
partition2도 같은 과정을 거친 후 join을 종료한다.
Build Input 해시 키에 중복이 많을 때의 비효율
해시 알고리즘은 충돌이 많아지면 선형 탐색과 성능이 같아진다. 이 경우 NL Join과 별 다를 바 없어진다.
Hash Join 사용 기준
Hash Join이 효율적일 때는 다음과 같다.
한 쪽 테이블이 가용 메모리에 담길 정도로 작아야 함.
Build Input 쪽 조인 칼럼에 중복 값이 없어야 함.
Hash Join이 사용되는 때는 다음과 같다.
1. 조인 칼럼에 적당한 인덱스가 없을 때
이 경우 inner 테이블을 full scan 할 수 밖에 없으므로 NL Join이 비효율적이다.
2. inner 테이블로 조인 액세스가 너무 많을 때
그게 다 random access이므로 좋지 않다.
3. 두 테이블이 너무 클 때
정렬하기에 너무 크면 Sort Merge Join은 정답이 아닐 수 있다. 물론 둘 다 너무 커서 build input으로 쓸만한 테이블이 없다면 이것도 문제다.
4. 수행빈도가 낮을 때
Hash Join은 I/O보단 CPU가 사용이 많이 된다. 그게 I/O Bound인 다른 Join보다 빠른 이유도 되긴 하지만 자주 쓰면 안 되는 이유이기도 하다. 또한 해시 맵은 조인할 때만 쓰고 버려지는 것이기 때문에 자주 쓰면 메모리가 낭비되는 효과를 불러온다.
따라서 수행빈도가 높은 쿼리에 Hash Join을 사용하면 CPU와 메모리 사용률을 크게 증가시키고, 메모리 자원을 확보하기 위한 각종 래치 경합이 발생해서 시스템 동시성을 떨어뜨릴 수 있다.
결론적으로, Hash Join은 수행빈도가 낮고 쿼리 수행시간이 오래 걸리며 대용량 테이블을 조인할 때 사용해야 한다.
이를 만족시키는 건 주로 OLAP 환경이다. OLTP라고 해서 Hash Join을 못 쓰는 건 아니지만 이 조건에 부합하는지 체크해봐야 한다.
