추론 통계
모집단에 대한 어떤 미지의 양상을 알기 위해 통계학을 이용해 추측하는 과정.
추정과 가설 검정으로 나뉜다.
추정
통계적 추론: 모집단에 대해 모르는 것을 알아내려고 통계학을 이용하여 추측하는 과정. 추정과 가설검정으로 나뉨.
점 추정: 특별한 값 하나를 추정
근데 이거는 솔직히 말이 안 됨.
구간 추정: 이 안에 있을 것이다 하는 구간을 추정
이건 좀 해볼만 하다.
신뢰도: 그 구간 안에 있을 확률
대수의 법칙: 시행 횟수가 많을 수록, 표본이 클 수록 오차 줄어든다.
중심극한정리: 표본이 많을 수록 확률 분포가 정규 분포에 가까워짐.
구간 추정
일정 확신으로 모수가 포함될 구간을 추정하는 것이다.
어떤 구간에 몇 퍼센트 확률로 평균치가 존재한다는 것이다.
표본을 조사하고, 거기서 나온 표본표준편차와 분포로 모집단의 평균을 추측해볼 수 있다.
점 추정량과 오차한계를 활용하여 신뢰 구간을 산출한다. (오차 한계 = )
신뢰 구간: 모수가 특정 확률로 포함될 것이라고 주장하는 범위.
신뢰 수준: 신뢰 구간에 실제로 모평균이 있을 확률
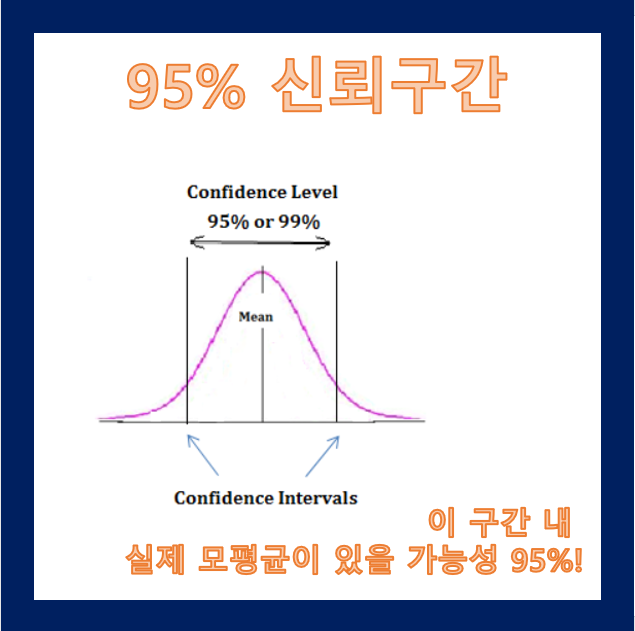
예를 들어 내가 어떤 표본을 조사했고, 그 데이터로 전체의 평균을 구하려고 한다.
시간이 없어 작게 조사했고, 따라서 데이터가 t분포를 따른다고 가정한다.
먼저 신뢰 수준을 정한다. 내가 100% 들어맞는 구간이나 점 추정을 할 수는 없으니, '이만 하면 됐다' 싶은 확률을 선정한다. 일반적으로 95%으로 설정한다.
t분포에서 합이 95%가 되는 구간은 이라고 하자.
나는 가 가 되게 하는 각 모평균 예상치 - 하한과 상한을 구하고 싶다.
분포에서 이므로 이다. 이 식에서 가운데에 모평균 만 남기면
이다. 와 는 각각 표본평균과 표본표준편차로, 구할 수 있는 값이며 도 t분포표를 보면 나온다. 이 값들만 식에 넣으면 모평균이 95% 확률로 있을만한 구간을 구할 수 있다.
이는 z분포일 때도 적용 가능하다. 식은 동일하며, 단지 분포표를 무엇을 볼 것인지만 다르다.
표본이 어떤 분포를 따르냐에 따라 혹은 으로 모평균의 신뢰 구간을 구할 수 있다.
모분산을 알면 그냥 z분포를 쓰면 된다. (근데 모분산을 알면 평균도 알텐데, 평균도 모르면서 모분산을 아는 경우는 거의 없다.)
표본이 많이 없더라도 표본이 30개를 넘어가면 중심극한정리에 의해 정규분포를 따르므로 z분포를 써도 된다.
표준 오차
표준 오차 = 이다. 표준 오차와 표준편차를 알면 몇 개의 데이터를 샘플로 뽑아야 하는지 알 수 있다.
