이 글은 Hadoop: What you need to know를 번역한 것입니다.
2006년 야후에서 검색 플랫폼을 향상시키기 위해 썼던 한 방법부터 시작해 아파치 오픈소스 프로젝트, 그리고 세계의 큰 기업체에서 사실상의 표준으로 자리잡기까지 하둡은 데이터 프로세싱과 기업의 데이터 웨어하우스에 혁명을 가져왔다. 하둡은 수많은 성공적인 스타트업을 태어나게 했으며 많은 회사들이 하둡으로 성공 스토리를 기록하였다. 이런 폭발적인 성공으로 인해 불확실하고 과대포장되고 혼란스럽고 먼지만 휘날리는 이들이 정착하기 시작하였고, 조직들은 하둡의 혁신적인 접근법을 활용하기에 적합하거나 적합하지 않은 때를 잘 이해하기 시작하였다.
하둡이 왜 존재하는지, 왜 중요한 기술인지, 어떻게 동작하는지, 그리고 어떻게 써야 하는지의 예시 등을 알아볼 것이다. 이 기사의 끝에 가선 HDFS, 맵리듀스, YARN 같은 기술의 기초에 대해 이해하게 될 것이지만 세세한 부분까지 파고들진 않을 것이다.
하둡과 하둡 에코시스템 소개
누가 하둡에 관해 이야기한다면 대개 아파치 하둡 프로젝트만을 두고 하는 이야기가 아니라 하둡과 같이 작동하는 다른 프로젝트들의 에코시스템과 같은 아파치 하둡 기술에 대해 이야기한다. 비유하자면 누가 운영체제로 리눅스를 쓴다 말하면 그 사람은 리눅스만 쓰는 게 아니라 리눅스 커널에서 돌아가는 수천 개의 어플리케이션도 쓴다는 말이다.
코어 아파치 하둡
코어 하둡은 데이터 분산 컴퓨팅을 위한 소프트웨어 플랫폼과 프레임워크이다. 하둡은 연산 작업들을 실행하는 장기적인 실행 시스템이라는 점에서 플랫폼이다. 플랫폼을 쓰면 개발자들이 모든 작업들에 대해 인프라를 처음부터 다시 구축할 필요가 없어져서 어플리케이션과 분석을 배포하기가 쉬워진다. 하둡은 데이터 어플리케이션과 데이터 분석을 개발하는 개발자들에게 시스템의 복잡한 것들을 숨겨서 추상화 된 레이어들을 제공한다는 점에서 프레임워크이다.
코어 아파치 하둡 프로젝트는 세 개의 컴포넌트로 나뉘는데 이들로 나머지 에코시스템을 구축한다.
HDFS (Hadoop Distributed File System)
한 대 이상의 컴퓨터 (즉, 분산된 방식의) 들에서 데이터를 저장하는 파일 시스템으로, 높은 처리량, 안정성, 확장성을 위해 설계되었다.
YARN (Yet Another Resource Negotiator)
하둡 리소스를 위한 관리 프레임워크로, CPU, RAM, 디스크 공간 사용량을 추적해서 프로세스가 부드럽게 실행되도록 한다.
MapReduce
분산 방식으로 데이터를 처리하고 분석하기 위한 일반화된 프레임워크이다.
HDFS는 수백, 수천개의 컴퓨터들에 걸쳐 많은 양의 데이터를 저장할 수 있다. 하지만 하둡은 YARN과 MapReduce를 이용해 많은 데이터를 저장하고 처리할 수 있게 하는데 이는 그저 데이터를 저장하기만 하는 전통적인 저장소(예: NetApp이나 EMC)나 연산하기만 하는 슈퍼컴퓨터(예: Cray)와 반대된다.
하둡 에코시스템
하둡 에코시스템은 하둡 위에서 혹은 하둡과 같이 돌아가는 도구와 시스템의 집합이다. 하둡과 "같이" 돌아간다는 것은 도구나 시스템이 하둡과 목적을 달리 하지만 사용자가 이를 활용할 수 있다는 뜻이다. 하둡 "위에서" 돌아간다는 것은 도구나 시스템이 코어 하둡을 활용하고 하둡 없이도 작동할 수 있다는 뜻이다. 공식적인 에코시스템의 리스트를 관리하는 사람은 아무도 없으며 에코시스템은 새롭게 추가되는 도구와 버려지는 낡은 도구와 함께 계속 바뀐다.
핵심 기술들을 지원되는 하나의 플랫폼으로 묶어둔 몇 가지 하둡 "배포판" (리눅스 배포판이 여러 개인 것처럼) 이 있다. Cloudera, Hortonworks, Pivotal과 MapR과 같은 제공자들은 모두 배포판을 가지고 있으며 회사에 어떤 제공자가 맞을지는 특정 유즈 케이스나 필요성에 달렸다.
통상적으로 하둡 "스택"이라는 것은 하둡 플랫폼과 프레임워크, 그리고 특정 유즈 케이스를 위해 선택된 에코시스템 도구들의 집합으로 구성되며 컴퓨터 클러스터 위에서 실행된다.
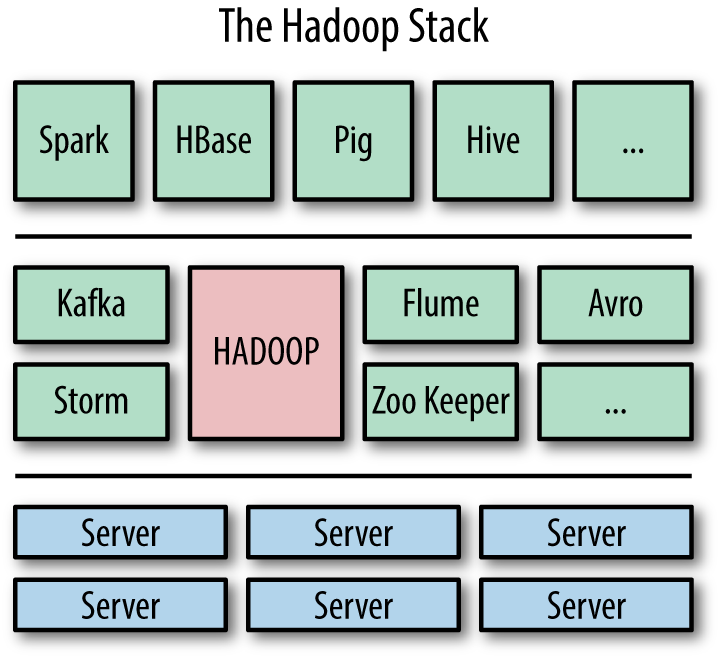
그림 1-1. 하둡(빨간색)은 하둡 에코시스템의 "커널"(초록색)과 같이 가운데에 위치한다. 에코시스템을 구성하는 다양한 구성요소들은 모두 서버들의 클러스터 위에서 동작한다.(파란색)
하둡과 에코시스템은 새로운 방식이다. 다음에서 살펴도록 한다.
하둡은 분산 시스템이 아닌 척을 한다
하둡은 분산 시스템이다. 네트워크 연결을 통해 소통하는 여러 연산 리소스 (서버, 컴퓨터 혹은 노드들) 클러스터의 사용을 조정한다는 뜻이다. 분산 시스템은 사용자들이 한 문제에서 풀 수 없는 문제를 풀 수 있는 힘을 부여해준다. 분산 시스템은 한 기계에서 저장할 수 있는 것보다 더 많이 저장할 수 있고 한 기계에서 처리하는 것보다 훨씬 빨리 처리한다. 하지만, 이렇게 되면 복잡도가 늘어나게 되는데 왜냐하면 클러스터에 있는 컴퓨터끼리 서로 소통을 해야 되고, 시스템은 더 많은 컴퓨터를 사용하면서 늘어나는 실패도 관리해야 하기 때문이다. 이들은 분산 시스템을 사용하면서 생기는 어쩔 수 없는 단점이다. 분산 시스템을 쓰고 싶어서 쓰는 게 아니라 쓸 수 밖에 없어서 쓰는 것이다.
하둡은 싱글 시스템과 꼭 닮은 외관(그림 1-2)을 제공하면서 사용자에게 분산 시스템이 아닌 척을 잘 한다. 사용자는 컴퓨터들을 조정하거나 실패를 수동적으로 관리하는 대신 데이터 분석에만 집중할 수 있어서 삶이 한 층 편해진다.
자바로 쓰여진 하둡 맵리듀스 코드의 스니펫을 보라 (예제 1-1). 자바 프로그래머가 아니더라도 코드를 읽고 무슨 일이 일어나고 있는지 대강 알 수 있을 것이다.
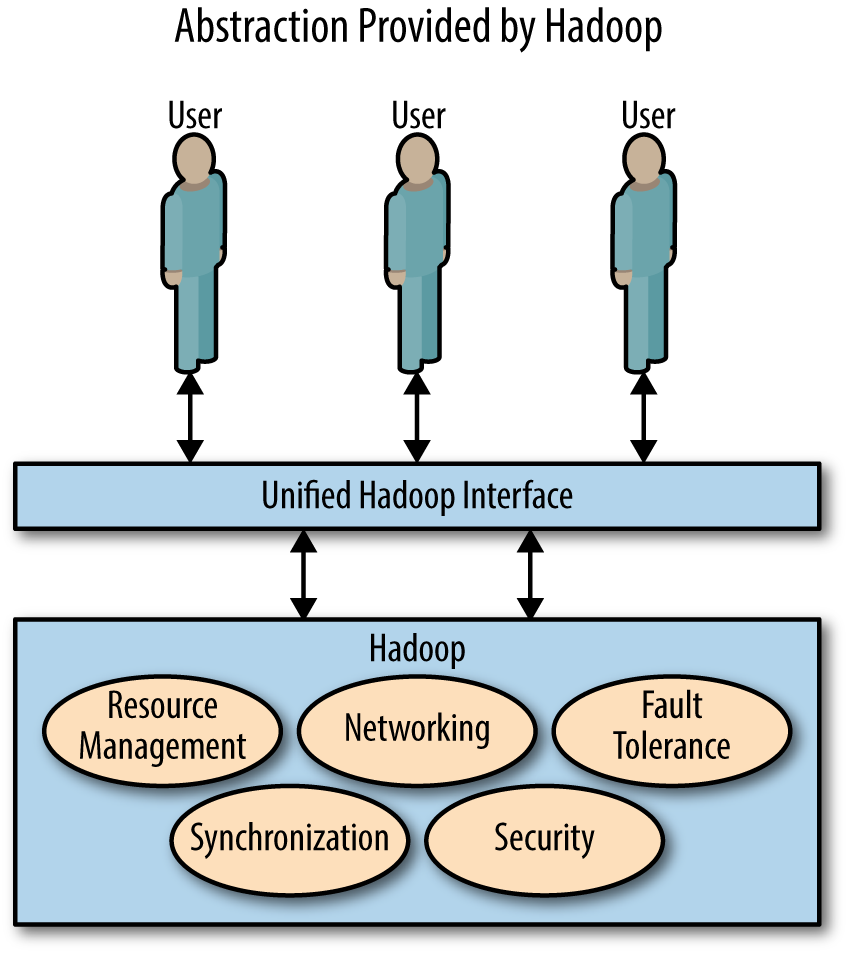
그림 1-2. 하둡은 통일된 추상 API를 분산 시스템 위에다 제공함으로써 분산 컴퓨팅의 무지막지한 디테일을 유저한테서 숨긴다.
예제 1-1. 자바로 쓰여진 맵리듀스 잡으로 단어 세기 예제
....
// 이 코드 블록은 맵 단계에서 해야할 일을 정의한다.
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
// 텍스트의 한 줄을 단어들로 나눈다.
StringTokenizer itr = new StringTokenizer(value.toString());
// 각 단어를 리듀서로 보낸다.
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
// "이 단어 본 적 있어!"
context.write(word, one);
}
}
....
// 이 코드 블록은 리듀스 단계에서 해야할 일을 정의한다.
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
// 단어에 대해서 우리가 단어를 본 횟수를 센다
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
// "나 이 단어 *result*번 봤어!"
context.write(key, result);
}
.... 이 코드는 단어 세기로, 맵리듀스의 기본 예제이다.
맵리듀스는 모든 것들을 정렬할 수 있는데 이 간단한 예제에선 텍스트의 바디를 받아서 텍스트에서 등장한 단어들과 등장한 횟수의 리스트를 반환해준다.
이 코드 어디에도 클러스터의 사이즈나 분석되는 데이터의 크기가 언급되지 않는다 예제 1-1의 코드는 다른 조치 없이 10,000개의 노드 하둡 클러스터나 노트북에서 돌아갈 수 있다. 똑같은 코드로 20페타바이트의 웹사이트 텍스트와 이메일 하나를 처리할 수 있다 (그림 1-3).
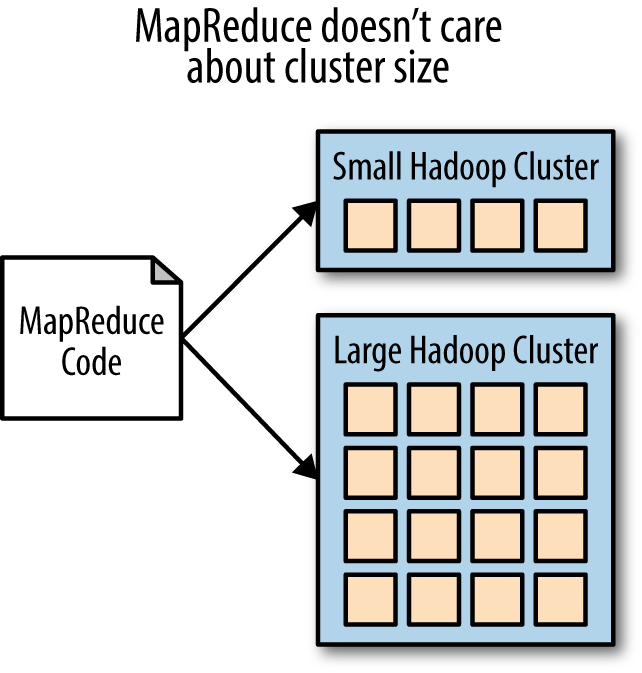
그림 1-3. 맵 리듀스 코드는 클러스터 사이즈와 관계 없이 똑같이 동작하고 똑같이 생겼다.
이는 코드를 휴대할 수 있도록 만들어서 개발자가 맵리듀스 잡을 큰 클러스터로 보내기 전에 샘플 데이터로 테스트할 수 있다는 뜻이다. 클러스터나 클러스터의 크기가 나중에 바뀌어도 코드가 바뀔 필요 없다. 또한, 이는 개발자에게 분산 시스템의 복잡성을 추상적으로 보이게 한다. 이렇게 하면 더 쉽게 개발할 수 있다. 에러를 만들 기회도 적어지고, 자동적으로 실수에도 대처할 수 있고, 코드를 적게 써도 된다. 이전의 분산 컴퓨팅 프레임워크에 대비되는 평균적인 소프트웨어 개발자들의 하둡 접근성이 하둡이 인기가 많아지는 주요 이유 중 하나이다.
이제 예제 1-2의 명령어들을 보자. 이는 하둡의 저장소 레이어로서 동작하는 파일시스템인 HDFS와 소통하는 것이다.
예제 1-2. HDFS 명령어 샘플
[1]$ hadoop fs -put hamlet.txt datz/hamlet.txt
[2]$ hadoop fs -put macbeth.txt data/macbeth.txt
[3]$ hadoop fs -mv datz/hamlet.txt data/hamlet.txt
[4]$ hadoop fs -ls data/
-rw-r–r– 1 don don 139k 2012-01-31 23:49 /user/don/data/
caesar.txt
-rw-r–r– 1 don don 180k 2013-09-25 20:45 /user/don/data/
hamlet.txt
-rw-r–r– 1 don don 117k 2013-09-25 20:46 /user/don/data/
macbeth.txt
[5]$ hadoop fs -cat /data/hamlet.txt | head
The Tragedie of Hamlet
Actus Primus. Scoena Prima.
Enter Barnardo and Francisco two Centinels.
Barnardo. Who's there?
Fran. Nay answer me: Stand & vnfold your selfe
Bar. Long liue the King여기서 HDFS 사용자가 하는 일은 두 개의 텍스트 파일을 HDFS로 로드하는 것이다. 하나는 햄릿이고 하나는 맥베스이다. 사용자가 (1)에서 오타를 내서 (3)에서 "mv" 커맨드로 datz/에서 data/로 바꿨다. 그리고, (4)에서 사용자가 data/ 폴더에 뭐가 들어있는지 리스트 했고 이전에 있던 율리우스 카이사르의 각본인 caesar.txt와 같이 들어있는 것을 확인할 수 있다. 마지막으로, (5)에서 사용자는 햄릿 파일이 실제로 잘 있는지 알아보려고 처음 몇 줄을 확인하려 한다.
맵리듀스 잡 코드 작성이 추상적인 것처럼 HDFS와 상호작용하는 것도 그렇다. HDFS 커맨드 어딜 봐도 데이터가 어떻게 그리고 어디에 있는지에 대한 정보가 나타나있지 않다. 사용자가 하둡 HDFS 커맨드를 제출하면 사용자가 모르는 동안 뒤에서 수많은 일들이 일어난다. 때론 결과를 얻기 위해 수십번의 네트워크 커뮤니케이션이 일어난 것도 모른 채 사용자가 결과를 받아보기도 한다.
예를 들어 사용자가 HDFS로 새 파일 몇 개를 옮겨야 할 때 HDFS는 각 파일들을 여러 개의 블록으로 나누어 컴퓨터들에게 나누어준다. 각 블록을 세 번씩 복사해서 파일들이 어디 있는지 등록한다. 이 분산과 복사의 결과로 하둡 클러스터의 컴퓨터 중 한 대가 실패하더라도 데이터를 잃지 않을 뿐 아니라 사용자가 이슈가 있는지도 모르게 된다. 사용자가 알지도 못한 채, 그리고 데이터 손실도 없는데도 커맨드 도중에 컴퓨터가 꺼지는 중대한 오류가 있었을 수도 있다. 이것은 하둡의 내결함성(fault tolerance)의 근간이 된다. (하둡은 몇몇 고립된 오류에도 계속 돌아갈 수 있다는 것들 뜻함).
하둡은 리소스 관리 (YARN), 데이터 저장소 (HDFS), 연산(MapReduce) 같이 일반적인 작업들을 관리하는 분산된 플랫폼을 제공하는 방식으로 병렬성을 추상화한다. 이런 구성요소 없이는 맵리듀스 잡이나 HDFS 커맨드를 할 때마다 내결함성과 병렬성을 만족시키도록 프로그래밍해야 하고 이것은 굉장히 어려운 일일 것이다.
하둡은 선형적으로 확장된다.
하둡은 선형적 확장성을 잘 유지한다. 선형적 확장이란 분산 시스템의 한 면이 확장되면 다른 면도 일대일로 확장된다는 뜻이다. 하둡은 더하는 방향으로 확장된다. (커지지 않는다) 이로써 사용자는 이미 조재하는 시스템에 새롭거나 더 강력한 것들을 덧붙일 수 있다. 예를 들어 냉장고를 키운다는 것은 더 큰 냉장고를 사서 이전 것을 버린다는 뜻이다. 더한다는 것은 냉장고를 하나 더 사서 이전 것 옆에 둔다는 뜻이다.
그림 1-4는 하둡 어플리케이션의 확장성에 대한 예시를 보여주고 있다.
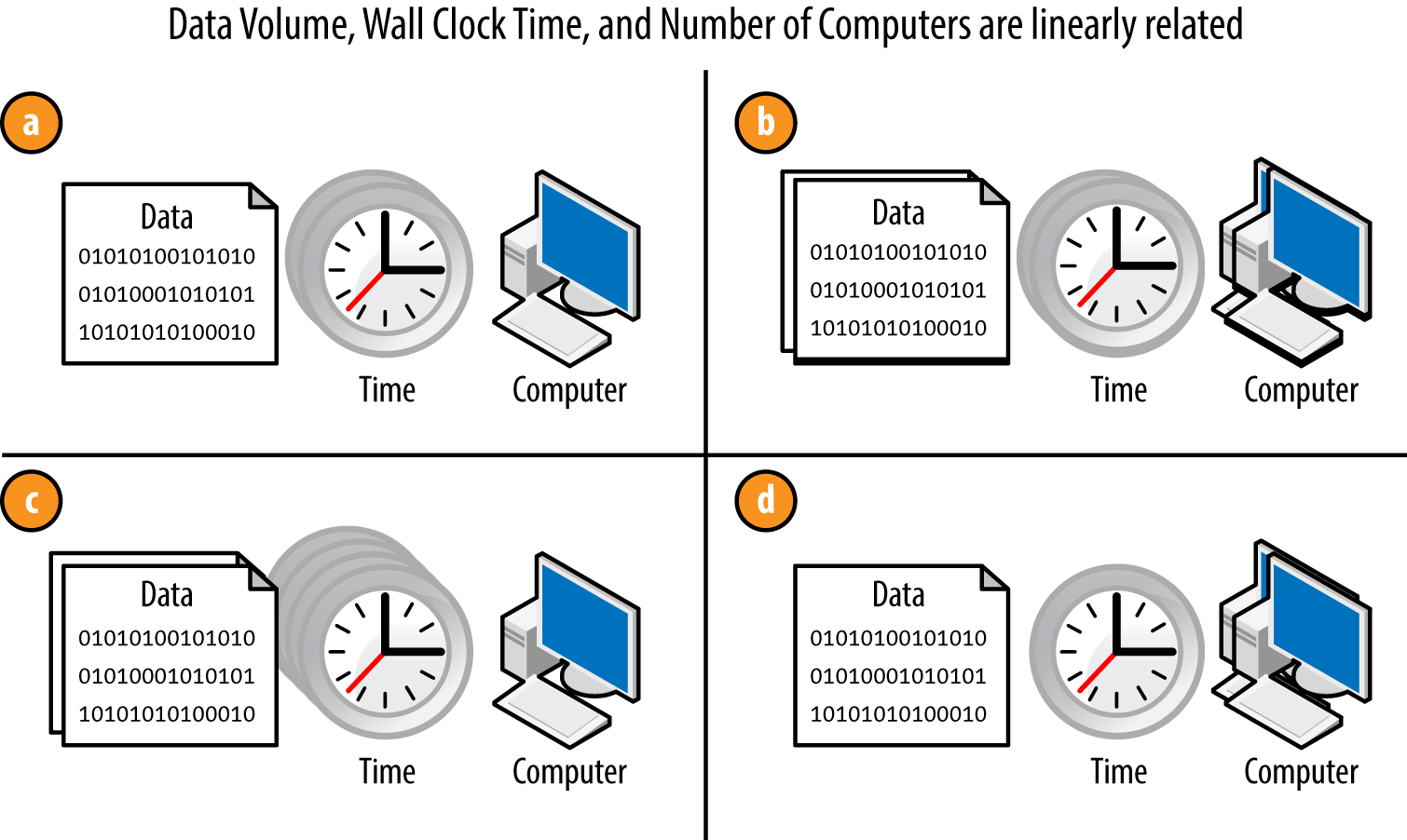
하둡의 선형 확장성; 데이터의 양 혹은 컴퓨터의 수를 바꾸면서 하둡 어플리케이션을 돌리는 데 드는 시간에 영향을 줄 수 있다.
그림 1-4a가 다음과 연관되어 있다고 하자:
- 그림 1-4b에서 데이터의 양과 컴퓨터의 수를 그림 1-4a의 두 배로 늘리면서 걸리는 시간을 똑같게 하였다. 데이터가 시간이 지남에 따라 많아지더라도 처리 시간을 똑같게 하려면 이 규칙이 중요하다.
- 그림 1-4c에서 데이터의 양을 두 배로 하고 컴퓨터의 수를 똑같이 해서 처리 시간이 두 배가 되었다.
- 그림 1-4c와 반대로 그림 1-4d에선 데이터 크기를 늘리지 않고 컴퓨터의 수를 두 배로 하자 시간이 반으로 줄었다.
이 규칙들을 응용하자면 예를 들어:
- 만일 두 배의 데이터를 저장하고 두 배의 성능을 내고 싶다면 컴퓨터를 네 배로 두어야 한다.
- 처리하는데 한 달 걸릴 데이터가 한 시간이 걸린다면, 일 년 걸릴 데이터는 12시간 걸린다.
- 클러스터의 반을 꺼버리면, 데이터는 반만큼 저장할 수 있고 처리시간은 두 배가 된다.
HDFS에 데이터를 저장할 땐 이 간단한 규칙들이 적용된다. 컴퓨터의 수를 두 배로 하면 두 배의 데이터를 저장할 수 있다.
하둡에서 노드의 수, 저장소의 양, 잡 루틴은 선형적인 관계로 엮여있다. 확장이 선형적 관계에 있다면 미래에 필요한 게 무엇일지를 정확히 예측할 수 있고 프로젝트가 커지더라도 예산을 벗어나지 않는다는 것을 알 수 있기 때문에 이는 중요하다. 선형적 관계가 있으면 옛날 시스템으로 어떻게 해야 하는지 고민할 필요 없이 그저 클러스터에 컴퓨터 한 대 더 추가하면 된다.
최근에 Spotify의 빅 데이터 팀에 있을 때 사람들이랑 같이 나눴던 이야기가 좋은 예시가 된다. 스포티파이는 다음 해에 데이터가 얼마나 증가할지 예측해서 메인 하둡 클러스터를 확장하기 위해 필요한 추가분을 알아낼 수 있었다. 3개월 전에 스포티파이의 클러스터 사용량이 꽉 찼는데, 간단한 수학으로 얼마나 많은 노드를 구매해야 하는지를 알아냈다. 지금까지 이들은 혼란을 피하기 위해 요구사항을 미리 잘 알아내고 있고, 계산하기가 간단하기 때문에 이렇게 쉽게 할 수 있었던 것이다.
하둡은 상용 하드웨어에서 돌아간다
하둡이 상용 하드웨어에서 돌아간다는 이야기를 들어봤을 것이다. 이는 하둡이 획기적이고 시작하기 쉬운 이유이다. 하둡은 야후에서 기존의 하드웨어에서 돌리기 위해 만들어졌다. 하지만 오늘날의 하둡에선 상용 하드웨어가 여러분이 처음 떠올리는 그것과는 조금 다르다.
하둡에서 상용 하드웨어라는 말은 클러스터를 구성할 때 쓰는 그냥 옛날 CPU, RAM, 하드 드라이브, 네트워크같이 특이할 것 없는 하드웨어를 말한다. 이들은 운영체제, 자바, 여러분이 이용하는 웹서버를 판매하는 하드웨어 제공자가 주는 도구들을 돌리기 위한 리눅스 컴퓨터들이다. 즉, 일반적인 목적을 가진 컴퓨터일 뿐 특별한 기술을 필요로 하지 않는다.
여러분이 쓰는 하드웨어에 엄청난 유연성을 준다. 성능과 가격을 두고 경쟁하는 그 어느 판매사들한테서 컴퓨터를 살 수도 있고 이미 있는 컴퓨터의 목적을 바꿔도 되고, 노트북에서도 돌릴 수 있으며, 특정 플랫폼을 우선시하는 데에 발목 잡힐 일이 없다. 나중에 하둡을 그만 사용하더라도 그 하드웨어를 되팔거나 다른 목적에 사용할 수 있다는 장점이 있다.
하지만 상용적이라는 말이 값싸거나 일반 사용자용이라는 생각은 하지 말자. 최신 하둡 클러스터는 하둡 작업들을 돌리기 위해 최적화된 하드웨어를 사용한다. 하둡 노드의 하드웨어와 다른 서버용 하드웨어의 큰 차이점은 병렬처리를 통해 처리량을 늘리기 위해 한 새시에 하드 드라이브가 12에서 24개로 많다는 것이다. HBase나 많은 코어를 가지는 시스템을 사용하는 클러스터들은 일반적인 컴퓨터보다 RAM도 더 많이 필요할 것이다.
그래서, "상용적이다"라는 말엔 비싸지 않고 얻기 쉽고, 하둡 클러스터 하드웨어가 특별한 목적을 위해 설계될 필요가 없다는 의미가 담겨있긴 하지만, 그렇게 평범하고 쌀 필요는 없다.
하둡의 좋은 점으로 하이엔드 하드웨어든 로우엔드 하드웨어든 잘 돌아간다는 점이 있지만 어떤 것을 살 지에 대해선 알고 있어야 한다. 최고를 위해 불필요한 프리미엄을 붙여 사는 것이 그 돈으로 컴퓨터 몇 대 더 사는 것보다 효율적이지 않을 수도 있다.
하둡은 정형화되지 않은 데이터를 다룬다
예제 1-1에서 자바 코드로 텍스트를 처리했다. 데이터를 처리할 자바 코드만 작성하면 되므로 텍스트의 분석으로 할 수 있는 것은 무궁무진하다. 관계형 데이터베이스와 다른 기본적인 차이점이다. 관계형 데이터베이스에선 데이터를 옮길 때 열(column)들로 맞춰서 자료형을 확실히 정의해야 한다. 그래서 관계형 모델은 비정형 데이터를 잘 다루는 패러다임이 아니다.
이 말은 당신이 여태 분석할 수 없었던 데이터를 분석할 수 있다는 뜻이다. 비정형 데이터의 예로는 종이 문서의 PDF 스캔본, 사진, 음성파일, 영상 등이 있다. 비정형 데이터는 정말 처리하기 어렵지만 큰 가치가 있다. 하둡은 그 가치를 데이터에서 뽑아낼 수 있다.
하지만 여기서 중요한 것이 있다. 프로그래밍 언어와 맵리듀스와 같은 분산 컴퓨팅 프레임워크로 비정형화 된 데이터를 처리하는 것은 관계형 데이터베이스에서 쿼리 날리는 데 SQL 쓰는 것처럼 쉽지 않다. 이는 하둡이 가지는 가장 큰 "비용"이다. 더 많은 일을 위해서 코드에 집중해야 한다. 하둡을 고려하고 있는 조직이라면 관계형 데이터베이스 프로젝트랑 다른 인력이 필요하다. 하둡을 이용해서 비정형 데이터를 처리할 순 있지만 그게 쉽지는 않다.
하둡이 비정형 데이터만을 위한 것은 아니다. 많은 사람들은 정형화 된 데이터를 처리하기 위해 하둡을 사용한다. 하둡의 장점을 활용할 수 있기 때문이다. 하둡은 텍스트, 이메일, 고객 피드백, 메시지 등을 포함하는 정형 데이터를 처리하는 데 유용하게 쓰일 수도 있다.
하둡에선 데이터를 로드하고 질문은 나중에 한다.
하둡과 NoSQL은 읽기 시점 스키마(schema-on-read) 라는 단어를 세상에 알렸다. 분석을 위해 파일시스템에서 데이터를 읽을 때 데이터의 본질(스키마)이 시스템 저장소에 들어있는 게 아니라 그때그때 추론된다는 뜻이다. 이는 쓰기 시점 스키마(schema-on-write) 과 반대되는 성격이다. 쓰기 시점 스키마에선 데이터가 저장되는 시점에 스키마가 분석적인 플랫폼의 형태로 쓰여진다 (그림 1-5). 관계형 데이터베이스는 데이터를 저장할 때 데이터베이스에게 데이터가 어떤 성질을 가지고 있는지 말해야 하기 때문에 쓰기 시점 스키마 성질을 가진다. ETL에선 (관계형 데이터베이스에서 데이터를 가져오는 과정) 데이터를 원본 형태에서 데이터베이스가 이해하고 저장할 수 있도록 데이터를 변환하는 것이 중요하다. 반면 하둡은 읽기 시점 스키마로, 맵리듀스 잡이 데이터를 읽을 때에 데이터를 이해한다.
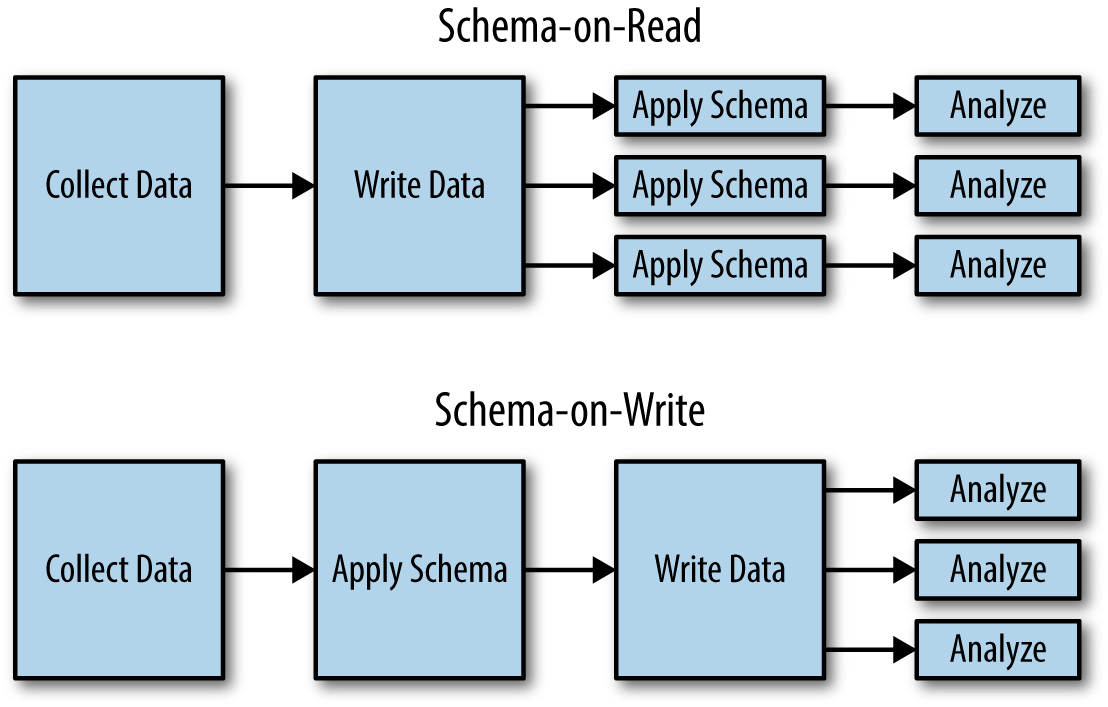
읽기 시점 스키마는 스키마를 이해하거나 어떠한 형태로 변환하기 이전에 데이터를 저장소에 쓰는 쓰기 시점 스키마와 다르다. 위에선 데이터의 성질에 대한 해석이 미루어지지만 밑에선 데이터가 분석될 때마다 해석되어야 한다.
읽기 시점 스키마의 장점
읽기 시점 스키마는 기초적인 아이디어로 보이지만 그동안 관계형 데이터베이스에서 하는 "원래 이런 거야"에서 벗어나는 과감한 시도이다. 이는 큰 이점을 가져다 준다. 데이터를 원본 그대로 쉽게 저장할 수 있다. 따라서 데이터는 어플리케이션과 시스템에서도 바이트가 수정되지 않을 수 있다. 데이터를 원본 형태로 유지하는 것의 위력은 데이터를 처리할 때 절대로 무시할 수 없다.
데이터를 먼저 탐색하는 능력
로우 데이터를 다루는 것은 데이터 프로세싱의 닭-달걀 문제를 해결한다. 데이터로 뭘 하기 전에는 데이터로 뭘 할지를 모른다. 이 사슬을 끊어버리기 위해서 데이터를 탐색해야 한다. 그러나 데이터가 처리되는 곳에 놓아보는 것말곤 효율적인 방법은 없다. 하둡과 읽기 시점 스키마는 데이터를 어떻게 처리해야 할 지 생각할 필요 없이 데이터를 하둡의 HDFS에 원본 형태의 데이터를 저장할 수 있다. 그 다음 맵리듀스로 데이터를 쪼개서 분석하는 코드를 작성할 수 있다. SQL 데이터베이스에선 어떤 처리를 할 것인지 생각해봐야 한다. 그래야 스키마를 작성하고 ETL 프로세스를 설정할 수 있기 때문이다. 하둡은 이 단계를 스킵하고 데이터 작업을 더 빨리 할 수 있게 해준다.
스키마와 ETL 유연성
다음 장점은 생각을 바꿀 때 드는 비용이 최소화된다는 것이다. 데이터 탐색을 하고 데이터에서 가치 창출을 어떻게 할 지 알아내고 나면 원래 예상했던 것과 다른 방향으로 가야 할 수도 있다. 쓰기 시점 스키마 패러다임을 따라서 데이터를 SQL 데이터베이스에 저장했더라면 그림판으로 다시 되돌아가서 ETL 프로세스랑 스키마를 새로 짜거나, 혹은 새 프로세스를 이전 거에 억지로 구겨넣게 될 수도 있다. 그런 상황에선 데이터를 시스템에 다시 새로 넣는 아주 힘든 작업을 하곤 했을 것이다. 하둡의 읽기 시점 스키마에선 로우 데이터는 그대로 있고 맵리듀스 잡에서 데이터 처리하는 방법을 달리 하면 된다. 데이터를 새로 쓸 필요도 없고 이미 제 할 일 잘 하고 있는 프로세스를 바꿀 필요도 없다. 데이터 프로세싱에서 결정내리는 것은 아주 무섭다. 하둡은 이를 프로젝트 도중 나중에 할 수 있도록 해줍니다. 나중에 문제를 더 잘 알게 되고 언제 적용해야 할지 알 수 있을 때 말이다.
로우 데이터는 모든 잠재적 가치를 지니고 있다
또 다른 장점으로는 데이터의 어떤 부분을 중요하게 볼 지를 바꿀 수 있다는 것이다다. 시간이 지나면서 데이터의 다른 부분이 중요해질 수 있다. 지금 중요하게 생각하는 부분만 처리하게 되면 나중에 힘들어질 것이다. 불행하게도 나중에 뭐가 중요해질지 미리 안다는 것은 불가능한 일이다. 그러니 가장 최고의 옵션은 혹시 모르니 원본 데이터를 저장하고 있는 것이다. 데이터에서 잘 밝혀지지 않은 부분이 나중 가서 유용해질 수도 있으니 데이터를 축적해두시길 바란다. 사이버보안에서 포렌식 분석은 가장 좋은 예시 중 하나이다. 데이터 분석가는 사건 이후에 위협이나 침입에 대해 연구할 수 있다. 공격 이전이나 공격이 이뤄지는 도중에는 어떤 데이터가 유용하게 쓰일지 확실하지가 않다. 할 수 있는 일은 데이터를 최대한 많이 모아 정리해서 나중에 효율적으로 조사하는 것 뿐이다.
사람들이 다 자기 코드가 완벽한 줄 알지만 동시에 그렇지 않다는 것도 알고 있다. ETL 프로세스는 나중 가서 엄청 크고 복잡한 코드가 될 수 있고 그러면 버그에 취약해진다. 로우 데이터를 유지한다면 다시 돌아가서 버그가 고쳐진 후 다시 처리할 수 있다. 이전의 쓰기 시점 스키마 시스템에서는 다시 돌아가서 데이터를 고치고 다시 써야 하기 때문에 컴퓨터가 노는 시간이 생길 수 밖에 없었다. 이러한 장점으로 실수를 잘 견뎌낼 수 있을 뿐 아니라 프로세스 초기 단계에서 있을 많은 위기를 감수함으로써 좀 더 재밌는 단계로 빨리 넘어갈 수 있다.
데이터를 원하는 방식으로 다룰 수 있는 능력
마지막으로 가장 좋은 점은 로우 데이터를 활용하는 읽기 시점 스키마는 필수가 아니라는 점이다! 하둡 클러스터에 향상된 ETL 파이프라인을 두고 쓰기 시점 스키마의 장점을 취하는 걸 아무도 말리지 않는다. 케이스 바이 케이스로 의견을 정할 수 있고 둘 다 할 수 있는 선택지는 언제든 있다. 반대로 관계형 데이터베이스로는 읽기 시점 스키마를 하기가 쉽지가 않고 한 가지 방법으로 밖에 할 수 없다.
하둡 분산 파일 시스템에 저장된 데이터는 분산되어 있고, 확장 가능하며, 오류에 대처할 수 있다
하둡 분산 파일 시스템(HDFS)은 많은 데이터를 분산해서 저장하는 방법을 제공한다. 이는 데이터 파일들을 시스템과 프레임워크에 제공하기 위해 하둡의 다른 구성요소들과 같이 동작한다. 현재 몇몇 크러스터들은 수백 페타바이트의 저장용량을 가진다.
네임노드가 쇼를 하고 데이터노드가 모든 일을 한다
HDFS는 "마스터 앤 슬레이브" 아키텍쳐로 구현되어 있는데 마스터인 네임노드(NameNode)와 여러 개의 슬레이브, 데이터노드(DataNode)로 이루어져있다. 데이터노드라는 프로그램은 각 데이터 노드에 있는 데이터를 관리하고 각 노드마다 데이터노드가 하나씩 있다. 체크포인트 노드와 예비 네임노드도 있는데 HDFS가 동작하는데 가장 중요한 일을 하는 것은 네임노드와 데이터노드 두 가지이다.
네임노드는 세 가지 중요한 일을 한다. 네임노드는 데이터가 어디 있는지 알고 있다. 클라이언트에게 데이터를 어디로 보낼지 알려주고 어디서 받아올지 알려준다. 클라이언트는 HDFS에 연결돼서 어떤 식으로든 상호작용하는 프로그램이다. 클라이언트 코드는 맵리듀스, 커스텀 어플리케이션, HBase 등 HDFS를 사용하는 것들이다. 그러는 동안 뒤에서 데이터노드는 데이터를 클라이언트에게 전송하고 디스크에 저장하는 일들을 한다.
HDFS에서 혹은 HDFS로 데이터를 전송하는 것은 두 프로세스로 이루어진다.
- 클라이언트가 네임노드와 연결해서 어떤 데이터노드가 내 데이터를 가져올 수 있는지 혹은 데이터를 어디로 보내야 할지 물어본다.
- 그 다음 클라이언트는 네임노드가 알려준 데이터노드와 연결해서 네임노드의 개입 없이 데이터노드에게 데이터를 주고 받는다.
이 작업은 오류에도 안전하고 확장 가능한 방식으로 이루어진다. 그림 1-6은 HDFS 커맨드 뒤에서 일어나는 의사소통을 나타내고 있다.
이것이 뒤에서 일어나는 일의 전부지만 꼭 알아둬야 할 것은 네임노드가 단 하나라는 것이다. 하나의 네임노드로 큰 데이터를 보내거나 받을 수 없다. 대신 데이터는 여러 데이터노드로 나눠진다. 이렇게 하면 단순히 노드 하나의 대역폭이 아닌 네트워크 대역폭과 함께 확장이 가능하다.
네임노드는 또한 데이터의 복사본을 추적한다. 필요 시 데이터노드에게 복사본을 더 만들도록 시킨다.
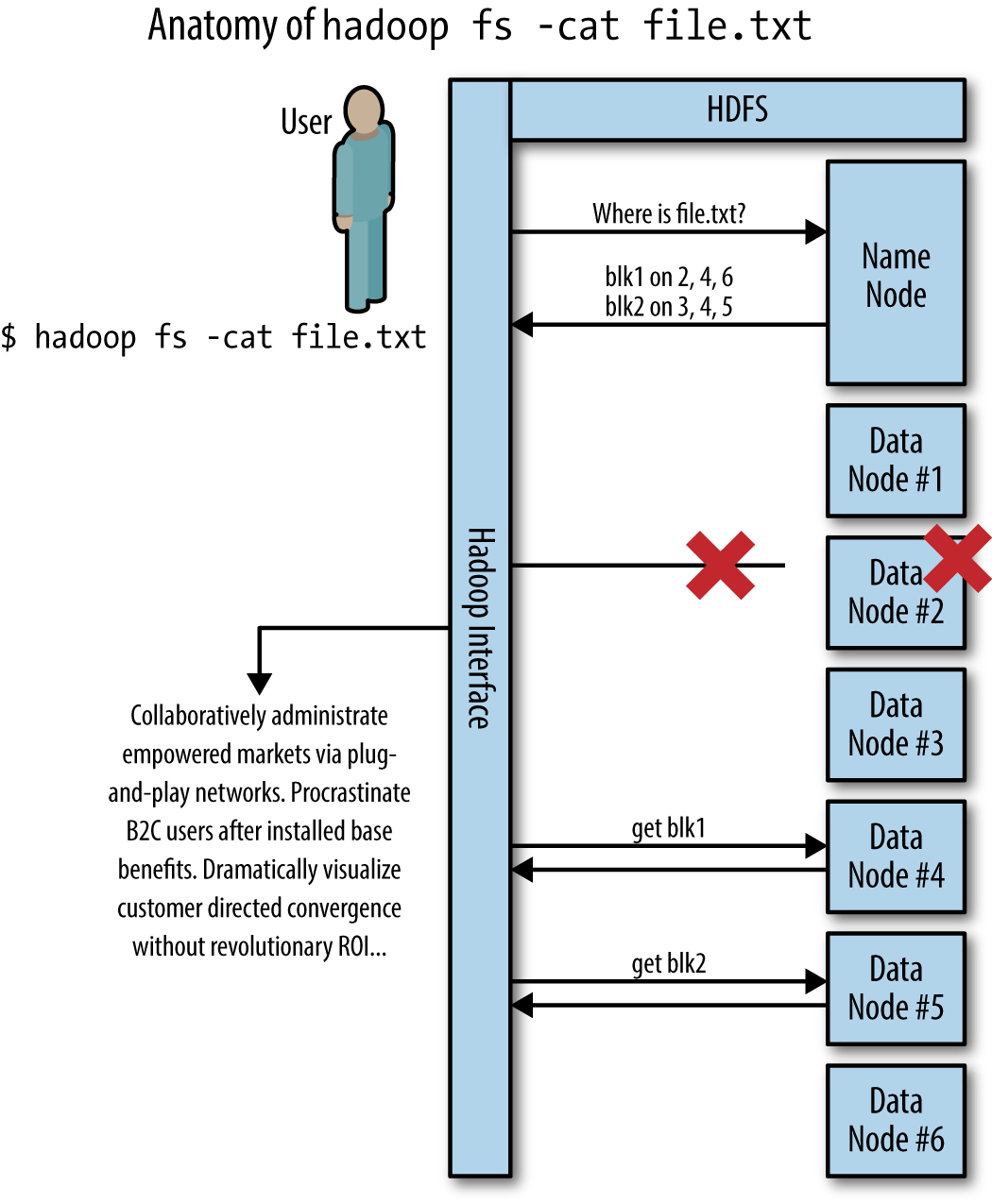
그림 1-6. HDFS 커맨드, hadoop fs -cat file.txt의 구조. HDFS 파일인 "file.txt"는 사이즈 때문에 blk1, blk2 두 개의 블록으로 나뉜다. 이 블록들은 클러스터의 여러 노드에 걸쳐 저장된다. 데이터노드 #2에서 엄청 큰 오류가 발생해서 blk1을 얻어오는 명령이 실패한다. 하둡은 blk1을 데이터노드 #4에서 가져와서 일을 성공시킨다.
HDFS 는 파일을 세 군데에 저장한다
기본값으로 HDFS는 파일 복사본 세 개를 클러스터 어딘가에 랜덤하게 저장한다. 이 세 개는 백업본이 아니다. 이들 모두 일급 파일로 클라이언트가 접근할 수 있다. 사용자가 복사본이 세 개인 것을 모를 뿐이다. 오류가 발생해서 복사본이 일시적으로 두 개만 존재하는 상황이 발생했을 때, 네임노드와 데이터노드가 상황을 처리하기 때문에 사용자는 그 상황을 알 수가 없다 (그림 1-6).
HDFS가 기반하고 있는 구글 파일 시스템 (GFS) 논문이 발표됐을 때, 많은 사람들이 GFS가 한 선택에 혼란해하였는데 시간이 지나면서 이해하기 시작했다. 사람들이 궁금해했던 것 중 하나는 파일 세 개를 복사해서 갖고 있는다는 점이다. 왜 구글은 그런 선택을 하였을까?
첫째로, 데이터의 복사본 세 개를 들고 있는 것은 굉장히 비효율적이다. 공간 효율이 33% 밖에 되지 않는다. 시스템에 3테라바이트짜리 하드가 있다면 1테라 밖에 못 싣는 것이다. 10페타바이트를 실으려면 가격은 굉장히 비싸진다. 여러 대의 컴퓨터에 불필요한 방식으로 데이터를 저장하는 분산 저장 접근법 중 80% 효율성을 찍는 것들이 많다.
하지만 수많은 실험을 거친 후에 이런 비용을 능가하는 복사본을 두는 것에도 좋은 점이 있다는 사실이 밝혀졌다. 첫쨰로 네트워크 대역폭과 데이터 지역성이라는 개념을 살펴보자. 데이터 지역성이란 데이터를 네트워크를 통해 이동시키지 않고 갖고 있을 수 있는 데이터 처리의 성질이다.
데이터가 GFS/HDFS에 저장되는 방식과 전통적인 분산 저장 시스템을 비교해보자. 전통적인 저장 시스템은 데이터 스트라이프나 패리티 비트를 사용해서 효율을 높인다. 스트라이핑에서 파일은 작은 조각으로 쪼개져 저장소에 나눠진다. HDFS에선 반대로 데이터를 잘게 나누지 않고 연속된 큰 덩어리의 블록으로 나눈다.
스트라이핑을 하는 전통적인 저장 시스템은 높은 IOPS에서 파일 하나를 얻기엔 좋을 것 같지만 큰 스케일의 데이터 분석에선 기본적으로 결점이 있다. 문제는 스트라이핑 기법으로 나뉘어진 파일들을 읽어 내용을 분석하려면 클러스터 안의 각 장소에서 파일을 다 모아서 재구성해야 한다. 그렇게 되면 네트워크 사용량을 요구하게 되고 데이터가 지역성을 가지기란 불가능해진다. 반면 파일을 연속된 덩어리로 저장하는 대신 복사본 세 개를 둔다면, 클라이언트가 파일을 분석할 준비가 되어 있을 때 파일을 다시 구성할 필요가 없다. 처리과정이 그 한 덩어리에서 이루어질 수 있기 때문이다. 클라이언트는 네트워크 이용해서 데이터를 전송할 필요 없이 데이터가 있는 그 컴퓨터에서 분석을 실행할 수 있다 (데이터 지역성). 데이터 지역성은 네트워크에 가해지는 압박감을 드라마틱하게 줄여줘서 데이터 프로세싱을 더 많이 할 수 있게 해준다. 즉 높은 확장성을 지녔다는 이야기다. 맵리듀스가 한꺼번에 수천 개의 파일을 처리하고 있을 때 이 확장성은 저장소의 밀집도와 높은 IOPS의 가격을 뛰어 넘는다.
스트라이핑 대신 하나의 연속된 덩어리로 파일을 저장한다면 그 덩어리가 오류 때문에 없어질 것을 대비해서 복사본을 저장할 필요가 있다. 하지만 왜 하필 2개, 4개가 아닌 3개일까? 3개인 이유는 실험적으로 딱 알맞기 때문이다. 그 이유는 내결함성과 퍼포먼스 두 가지이다. 내결함성 측면은 분명하다. GFS/HDFS는 한꺼번에 컴퓨터 두 대를 잃어도 데이터가 손실되지 않는다. 네임노드가 데이터노드에게 남아있는 복사본을 복사해서 다시 세 개로 만들기 때문이다. 퍼포먼스 상의 이점은 직관적으로 와닿지 않을 수 있다. 복사본이 많으면, 사용자가 세 개 중 어떤 복사본에도 액세스가 가능하기 때문에 더 많은 데이터 조각이 사용이 가능하다. 이것은 하나에 몰리는 현상을 줄여줄 수 있다. 한 파일에 몰리는 트래픽을 여러 컴퓨터에 나누기 때문이다. 같은 시간 같은 데이터로 여러 일을 수행할 때 중요하다. 원래의 질문에 답을 하자면, 복사본 두 개는 좀 위험하고 성능이 낮아질 수도 있다. 네 개는 데이터를 굉장히 잘 지키지만 한 개 더 추가할만큼의 성능을 보이지 않는다.
HDFS의 파일은 수정될 수 없다
HDFS느 수많은 컴퓨터에 수많은 양의 데이터를 잘 저장하지만 처리량과 확장성을 위해서 파일 수정과 같은 몇몇 기능을 희생할 수 밖에 없다. HDFS을 처음 사용하는 사람들은 일급 어플리케이션 (마이크로소프트의 워드까지도) 으로 수정이 안 되는 등 HDFS를 일반적인 저장소처럼 쓰지 못한다며 실망을 표한다. 사용자는 하둡 커맨드와 프로그래밍 인터페이스를 쓸 수 밖에 없다. 이 기능을 희생하면서, HDFS의 설계자들은 HDFS가 해야할 일을 간단하고 쉽게 할 수 있도록 유지한다.
파일을 한 번 쓰면 그게 끝이다. 파일은 삭제할 때까지 그 내용을 고스란히 갖고 있을 것이다. 이렇게 하면 HDFS가 여러 방면에서 쉬워진다. 가장 큰 장점은 HDFS가 동기화된 수정을 할 필요가 없다는 뜻이다. 분산 시스템에서 이를 구현하기는 꽤 어렵다.
모든 의도에 대해서 HDFS의 파일은 파일 안의 레코드가 아닌 데이터셋이라는 건물의 벽돌이며, 원자성을 지닌다. 이런 구현 때문에 데이터 수집과 어플리케이션을 파일을 수정하는 게 아닌 폴더에 파일을 추가하는 방식으로 설계해야 한다.
네임노드는 HDFS의 아킬레스건일 수도 있다.
큰 힘에는 큰 책임이 따른다. 네임노드는 모든 것을 알기 때문에 굉장히 중요하다. 하지만 그 중요성 때문에 여러가지 방법을 오류가 난다.
SPOF는 하둡에서 크게 비판받는 것 중 하나이다. SPOF는 Single Point Of Failure라는 뜻으로 분산 시스템에서 엄청 치명적이다. 전통적인 HDFS에서 네임노드는 SPOF 특성을 가진다. 네임노드에서 오류가 나거나 사용이 불가능하면 HDFS 전체를 쓸 수 없게 되기 때문이다. 이는 HDFS가 가지고 있는 데이터가 없어진다는 뜻이 아니라, 데이터가 어디 있는지 찾을 수 없기 때문에 데이터를 얻는 것이 불가능해진다는 뜻이다. 연락처를 잃어버려도 전화번호로 전화는 걸 수 있는 것과 같다.
네임노드가 못 쓰게 되는 일을 줄이는 방법이 몇 있다 (이를 NameNode High Availability, 혹은 NameNode HA - 네임노드 고가용성이라고 부른다). 하지만, 이 방법은 결국 복잡성을 증가시키게 되고 고장나면 고치기 어렵게 된다. 야후에서 하둡의 아버지 중 한 명이자 Hortonworks (하둡 제공자) 의 설립자인 Eric Baldeschweiler은 가끔 네임노드를 고가용성 설정에 대해 걱정하는 게 이해가 안 된다고 말했다. 일반적인 네임노드 설정은 구현도 간단하고 고치기도 쉽기 때문이다. 자주 고장날진 몰라도 고치는 데 걸리는 시간은 짧다. 네임노드를 고쳐본 직원과 적절한 모니터링이라면 몇 분 내로 고칠 수 있다. 네임노드를 고가용성으로 만들지 말지는 그냥 고려해볼 사항이다. NameNode HA가 무조건 요구되는 사항이라고 생각하지 말길 바란다. 하지만 NameNode HA에 상당한 노력이 들어가고 있기 때문에 새로운 하둡 릴리즈마다 더 쉬워지고 안정성이 생기고 있다.
YARN은 하둡을 위한 클러스터 리소스를 할당한다
YARN은 2012년 초에 하둡의 공식적인 일부분이 되었고 이는 하둡의 새로운 2.x 릴리즈의 주요 기능이었다. YARN은 하둡의 중요한 갭을 매꿔서 하둡이 새로운 영역에도 효율적으로 사용될 수 있게 하였다. 이 갭은 컴퓨터들 사이에서 클러스터 리소스 (연산이나 메모리 등)을 어떻게 나눠줄지 정하는 리소스 협상을 말한다.
YARN 이전에는 대부분의 리소스 협상을 각 컴퓨터 시스템 레벨에서 각각의 운영체제가 맡아서 했다. 이 방법에는 눈에 보이지 않는 위험이 많다. 운영체제가 클러스터 레벨에서의 거대한 계획을 이해하지 못하고 있기 때문에 어떤 어플리케이션과 작업이 어떤 리소스를 가져갈 지 최상의 결정을 내리지 못했다. YARN은 이 갭을 작업을 클러스터 전체에 똑똑하게 나눠줘서 각 컴퓨터에게 어떤 일을 해야 하고 어떤 리소스를 가져야 하는지를 알려준다.
YARN을 준비하고 실행시키는 것은 일반적으로 하둡 클러스터 설치와 같이 이루어지며 HDFS와 같이 "하둡을 돌린다"는 것과 동의어이다. 사실 요즘의 하둡 클러스터는 모두 YARN을 돌리고 있다.
개발자는 YARN에 대해서 그렇게 많이 알 필요가 없다
YARN이 백그라운드에서 모든 일을 해결하며 딱히 하둡 개발자가 맨날 YARN과 상호작용할 필요가 없다는 것이 제일 큰 장점이다. 대부분 개발자는 맵리듀스나 다른 프레임워크의 API와 일한다. 리소스 협상은 그 뒤에서 일어나는 일이다. 프레임워크가 자체적으로 YARN과 상호작용하며 리소스를 요청하고, 개발자도 모르게 이를 활용한다.
YARN에 쓰는 시간의 대부분은 문제가 발생했을 때이다. (어플리케이션이 충분한 리소스를 얻지 못한다거나 클러스터가 제대로 활용되지 않을 때) 이런 문제를 해결하는 것은 시스템 관리자의 몫이지 개발자의 몫이 아니다.
YARN은 개발자의 수명을 늘리고 하둡의 진입장벽을 낮추는 데 빛을 발한다.
맵리듀스는 데이터 분석을 위한 프레임워크이다
맵리듀스는 클러스터 내 컴퓨터의 HDFS에 저장된 데이터를 분석하기 위한 일반화된 프레임워크이다. 맵리듀스는 분석 개발자가 거대한 분산 시스템의 성질을 아예 모르더라도 코드를 작성할 수 있게 해준다. 분석 개발자는 데이터를 분석하고 싶어한다. 네트워크 프로토콜이나 내결함성에 대해 걱정하고 싶어하는 개발자는 없기 때문에 이는 굉장히 유용하다.
맵리듀스 자체는 구글 엔지니어들이 2004년 논문에서 설명한 분산 컴퓨팅의 패러다임이다. 해당 논문의 저자는 많은 양의 데이터를 상용 하드웨어에 분산시켜 분석하기 위한 방법을 분산 시스템의 수많은 복잡한 점들을 가리는 방식으로 설명하고 있다.
하둡의 맵리듀스는 맵리듀스 (원래 야후가 구현한 것) 개념을 구현한 한 예시이다. CouchDB, MongoDB, Riak NoSQL 데이터베이스는 데이터 요청을 위해 하둡의 맵리듀스와는 아무 연관 없는 그들만의 맵리듀스를 구현하였다.
맵과 리듀스는 비공유의 성질을 가진다
하둡에서 들어봤을 만한 다른 이름들(Pig, Hive, ZooKeeper 등)과는 달리 맵리듀스는 실제로 프로세스를 나타내고 있다. 맵리듀스는 "맵"과 "리듀스"의 두 가지 주요 처리 단계를 말한다. 맵리듀스 잡에선 분석 개발자는 맵 단계와 리듀스 단계에서 쓰이는 코드를 작성한다. 그 다음 하둡은 그 코드를 가져다 데이터에 병렬적이고 확장 가능한 방법으로 적용한다. 맵 단계는 각 레코드를 자세히 들여다보며 레코드 별로 변형하는 작업을 수행한다. 이전에는 답할 수 없던 질문에도 답을 하기 위한 하둡의 유연성은 맵과 리듀스 단계에서 코드를 커스터마이징할 수 있게 한다. 맵과 리듀스가 있으면 데이터로 무엇이든 할 수 있다.
이번 부분에서는 이 글의 다른 부분보다 더 깊게 기술적인 부분으로 파고 들 것이다. 이는 하둡과 맵리듀스가 기존 것들과 다른 중요한 부분에 대해 설명한다. 기술적으로 디테일한 부분이 잘 이해가 가지 않는다면 너무 매달리지 말길 바란다. 맵리듀스가 선형적 확장성에 큰 이점이 있다는 점에만 집중하길 바란다.
프로그래밍에서 맵이란 어떤 함수 (절대값이나 대문자로 만들기 같은)를 리스트의 모든 원소에 적용해서 그 리스트의 결과들을 반환하는 것을 뜻한다. 예제 1-3에서 하둡이 아닌 맵의 예제를 확인할 수 있다.
예제 1-3. 파이썬 맵의 두 가지 예제
# 수들이 담긴 리스트에 "abs" 함수(절대값)를 적용한다
map(abs, [1, -3, -5, 0, 4])
# [1, 3, 5, 0, 4]를 반환한다
# 문자열이 담긴 리스트에 대문자 함수를 적용한다
map(lambda s: s.upper(), ['map', 'AND', 'Reduce'])
# ['MAP', 'AND', 'REDUCE']를 반환한다맵에 관해 흥미로운 부분이 있다. 맵 함수가 적용되는 순서는 중요하지 않다는 것이다. 첫번쨰 예에서 우리는 abs 함수를 리스트에서 세번째, 첫번째, 두번째 그 다음 네번째 원소에 적용시켰다거나 또 다른 순서로 적용했더라도 똑같은 결과를 받아볼 수 있었을 것이다.
이제, 1조 개의 정수 리스트에 맵 함수를 적용한다고 가정하자 (하나의 컴퓨터에선 엄청 오랜 시간이 걸릴 것이므로 여러개의 컴퓨터에 나누어야 한다). 적용되는 순서는 상관이 없으므로, 분산 시스템에서 가장 어려운 문제 중 하나인 서로 다른 컴퓨터에서 일이 끝나는 순서를 통일시키는 문제를 피할 수 있다. 분산 시스템에서 이 개념은 비공유라고 불린다. 비공유는 기본적으로 각 노드가 하는 일은 다른 노드에 독립적이고 다른 데이터 노드와 아무것도 공유하지 않으면서 일을 할 수 있다는 것을 뜻한다.
결과적으로 데이터 노드를 추가함으로써 오버헤드 없이 시스템을 확장할 수 있다. 비공유와 데이터 지역성은 이론적으로 한계가 없는 선형적 확장성을 열었고 이게 맵리듀스가 잘 작동하는 이유이다.
그래서, 맵리듀스 잡에서 맵 단계는 HDFS의 데이터를 처리하는 비공유 접근법이다. 맵리듀스 개발자는 한 레코드에 시키는 것같은 코드(예제 1-3에서의 람다 표현식이나 abs 함수같은)를 짜고 맵리듀스는 이를 데이터셋의 모든 레코드에서 돌릴 수 있는지를 알아낸다. 하지만 예제 1-3의 파이썬에서의 맵과는 달리 맵리듀스의 맵은 키/값 쌍을 출력하도록 되어 있다. 키/값 쌍은 연결된 데이터의 집합으로, 키는 유니크한 표식자가 되고 값은 데이터 자체가 된다. 맵리듀스 프레임워크는 이 같은 키들을 가지는 쌍들을 모아서 그 값들을 같은 키를 가지는 리듀스 함수에게 보낸다.
맵리듀스에서 리듀스는 맵 단계의 결과를 받아서 키로 묶고 키 그룹에서 총합, 세기, 평균 내기 등의 연산을 실행한다. 맵과 같이, 리듀스라는 단어는 여러 언어에서 사용되는 프로그래밍 언어이다. 전통적인 리듀스 연산은 함수를 매개변수로 받는다 (맵과 같이). 하지만 맵과 다른 점은 함수가 나가 아니라 두 개라는 점이다. 리듀스는 리스트의 앞에서 두 개의 원소에 매개변수로 받은 함수를 적용하고, 결과를 받아서, 그 함수를 그 결과와 다음 원소에 적용하고, 이를 반복한다. 예제 1-4에서 하둡이 밖에서의 리듀스의 예시를 확인할 수 있다.
# sum the numbers using a function that adds two numbers
reduce(lambda x, y: x + y, [1, 2, 3, 3])
# returns 9
# find the largest number by using the +max+ function
reduce(max, [1, 2, 3, 3])
# returns 3
# concatenate the list of strings and add a space between each token
reduce(lambda x, y: x + ' ' + y, ['map', 'and', 'reduce'])
# returns 'map and reduce'하둡에서 리듀스는 파이썬 예제에서의 전통적인 리듀스보다 더 일반적이지만 리스트를 받아서 그 리스트 전체에 대해 계속해서 어떠한 처리 과정을 반복한다는 개념은 동일하다. 한 값을 뽑아낼 수도 있고 (max 예시처럼) 출력의 크기를 줄이지 않으면서 새로운 형태의 배열을 생성하기도 한다. (문자열 이으는 예시에서처럼)
맵리듀스가 어떻게 동작하는지 맵과 리듀스 함수에 대한 설명을 코드 없이 요약해놓았다. 이 요약은 맵리듀스의 표준 예제인 "단어 세기" 이다 (예제 1-1의 자바 코드에서 봤던 것). 이 프로그램은 텍스트의 단어 수를 센다:
맵
- 텍스트 한 줄을 입력으로 가져온다
- 공백을 기준으로 나눈다
- 각 단어를 일반화한다 (대문자, 기호 제거)
- 각 단어를 키로 1을 값으로 출력한다. 이는 "'하둡'이란 단어를 한 번 봤다"는 뜻이다.
리듀스
- 키와 1들을 입력으로 가져온다.
- 단어를 세기 위해 1들을 다 더한다.
- 총합을 출력한다. 이는 "'하둡'이란 단어를 X번 봤다"는 뜻이다.
하둡이 대신 해주는 수만가지 일들이 있다. 맵 함수부터 리듀스 함수까지 맵리듀스가 어떻게 데이터를 얻는지 ("섞기와 정렬"이라 불리는) 의 과정을 생략하였다. 맵리듀스가 극단적으로 연산에서의 확장성을 얻기 위해 비공유의 접근방식을 사용한다는 것을 기억해야 한다. 대신 개발자가 일반적인 목적의 프로그램을 짤 수 없고 맵과 리듀스 관점에서만 코딩해야 한다는 단점이 있다. 맵리듀스는 맵과 리듀스 함수를 병렬화하는 방식만을 알고 있다.
데이터 지역성은 하둡이 확장성을 가지는 이유 중 하나이다
비공유 방식으로 연산 확장을 잘 할 수 있게 된다. 하지만 병목현상을 한 번 고치면 그 다음 것으로 계속 넘어가야 한다. 이때 그 다음 병목현상이란 클러스터의 네트워크의 확장성을 말한다.
전통적인 데이터 처리 시스템에서 저장소와 연산은 분리됐었다. 이런 시스템에서는 데이터는 아주 빠른 네트워크를 통해 컴퓨터로 옮겨져서 처리되었다. 데이터를 네트워크를 통해 옮기는 것은 네트워크를 쓰지 않고 움직이는 것에 비해 많은 시간이 든다. 데이터를 데이터가 있는 곳에서 처리하는 것이 대안으로 떠올랐다. (데이터 지역성을 말한다. 그림 1-7을 보자.)
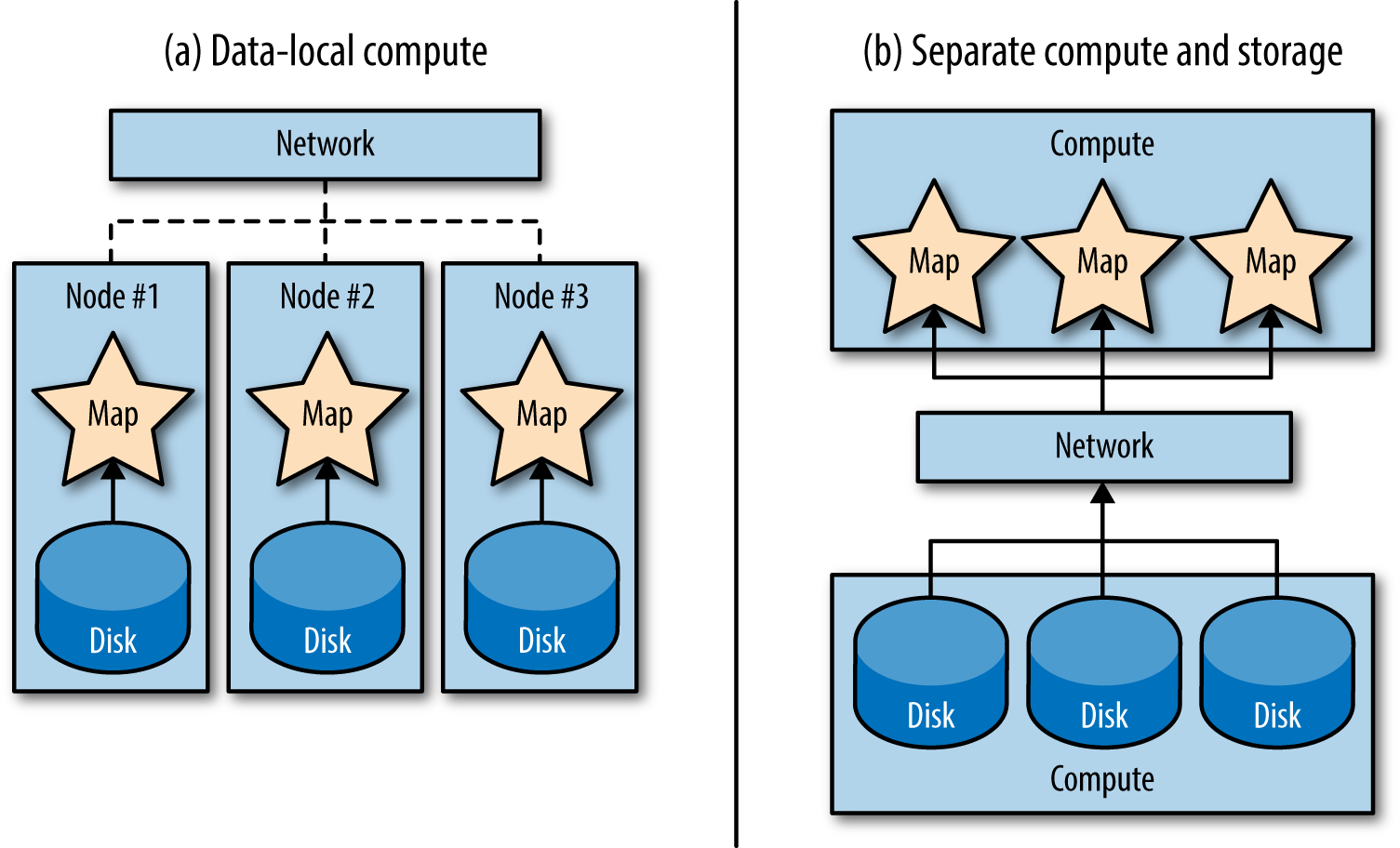
그림 1-7. 데이터 지역성은 대부분의 기존 큰 데이터 시스템이 따르던 저장소와 연산을 분리하는 방식에서 큰 변화를 시도한다. (a) 데이터-지역 연산에서 맵 작업들은 네트워크를 전혀 사용하지 않고 로컬 디스크에서 데이터를 가져온다. (b) 연산과 저장소가 분리된 환경에선 데이터를 처리하고 싶을 때마다 모든 데이터가 네트워크를 통해 이동한다.
데이터 지역성은 쉬운 아이디어 같지만 데이터를 네트워크로 옮기지 않고 거기서 바로 처리한다는 개념은 새로운 것이다. 하둡은 이 접근 방식을 사용한 최초의 범용 시스템이다. 연산을 위해 명령어들을 옮기는 것 (맵과 리듀스 함수의 코드를 담고 있는 컴파일 프로그램인데, 엄청 작다) 을 네트워크로 옮기는 것이 페타바이트의 데이터를 그 프로그램이 있는 곳으로 옮기는 것보다 빠르다.
데이터 지역성은 네트워크를 선형적 확장에서의 병목현상이 된다고 취급하여 이를 제거한다. 각 데이터가 있는 수많은 컴퓨터로 작은 프로그램이 이동한다. 여기서 데이터의 대부분은 컴퓨터를 떠나지 않아도 되는 데이터이다. 비공유 방식과 함께 하둡이 수천 수만 노드로 확장될 수 있게 한다.
다시 HDFS로 돌아가자. HDFS는 맵리듀스를 지원하기 위해 만들어졌고 여기서의 핵심 디자인이 없이는 맵리듀스가 데이터 지역성을 완성하지 못할 것이다. 파일을 크고 연속적인 덩어리로 저장하는 것으로 맵 작업이 네트워크로 여러 디스크나 컴퓨터에서 데이터를 가져올 필요 없이 하나의 디스크에서 작업할 수 있다. 또한, HDFS가 복사본 세 개를 만들기 때문에 한 두 개의 복사본들이 다른 일 하느라 바쁘더라도 노드가 호스트에서 바로 연산할 확률도 높인다.
맵리듀스의 대체제는 있다
맵리듀스는 사용자들에게 충분히 추상적이지 않은 경우가 많은데, 이는 역설적으로 분산 연산에서 많은 디테일한 부분들을 추상화하기 위함이다. 하지만 컴퓨터 과학자들은 추상화하고 추상화하는 것을 좋아하며 맵리듀스를 아파치 크런치, 캐스캐이딩, 스캘딩 (맵리듀스에서 맵과 리듀스의 사용을 추상화하는 데이터 파이프라인 기반의 연산 툴들) 같은 프레임워크와 아파치 피그 (데이터플로우 언어)와 같은 고수준의 언어, 아파치 하이브 (SQL 같이 생긴 언어)와 함께 사용하기 쉽게 만들 수 있었다. 많은 경우에서 맵리듀스는 맵리듀스 기반 연산의 어셈블리어와 같다.
다 그렇듯 추상화에도 비용이 든다. 세부적인 것을 너무 많이 가리는 것도 위험하다. 최악의 경우 코드가 난해해져서 성능에도 영향을 끼칠 수 있다. 사용자에게 필요한 데이터 플로우의 제어와 제어할 수 있는 힘을 얻기에 맵리듀스의 코드가 최고의 방법인 때가 있다. 하지만 항상 맵리듀스에서 모든 걸 해결하게 되는 것을 조심해야 한다. 더 높은 수준의 추상화를 위한 시간과 장소가 있다.
맵리듀스는 "느리다"
맵리듀스에 대한 반복적인 비판 사항으로는 느리다는 것이다. 느리다는 것이 무슨 말일까?
첫째로 맵리듀스는 어떤 일을 할 때마다 드는 고정된 시간이 존재하는데 이는 무시할 수 없을 정도이다. 데이터를 로드하고 쓰는 것을 빼면 거의 아무런 일도 하지 않는 맵리듀스 작업은 실행 시 30에서 45초가 걸린다. 이 지연시간 때문에 그때 그때 필요한 일이나 반복적으로 분석해야 하는 일을 하기가 어렵다. 할 때마다 45초가 드는 것은 개발자에게는 큰 일이다. 사용자가 행동을 취할 때마다 분석이 실행되는 프로그램은 개발하기가 불가능하다.
둘째로 맵리듀스는 디스크를 엄청 쓰고 읽는데 (한 맵리듀스 작업 당 7번까지) 디스크를 쓴다는 건 컴퓨터가 할 수 있는 가장 비싼 작업 중 하나이다. 디스크에 쓰는 작업은 대부분 내결함성에 이득이 되고 컴퓨터 하나가 죽어도 맵리듀스 작업을 다시 시작할 필요가 없게 한다.
맵리듀스의 동작은 시간이 많고 작업이 주기적으로 돌아가야 할 때, 즉 배치로 돌아갈 때 좋다. 맵리듀스는 배치 처리를 잘한다. 맵리듀스는 대량의 데이터를 처리하고 취합하는 일을 선형적으로 확장할 수 있는 방식으로 진행하는 데에 엄청난 잠재력이 있다. 예를 들어 하루에 한 번 협업 필터링 추천 엔진을 돌리고 로그 기록하고 모델 학습시키는 일이 자주 있다. 이는 배치에 적합하다. 데이터가 많고 결과를 그때그때 업데이터하면 되기 때문에 배치로 쓰기 적절하다. 하지만 모든 사람들이 배치로 일하길 원하는 것은 아니다.
오늘날 실시간 스트림 처리에 대한 관심이 많다. 이는 배치랑 기본적으로 다르다. 아파치 스톰은 실시간 스트림 처리를 위한 초기 무료 오픈소스 중 하나인데 이는 원래 트위터의 내부 시스템이었다. 스파크 스트리밍 (스파크 플랫폼의 일부인 스트리밍의 마이크로배치 접근법), 아파치 삼자 (아파치 카프카 위에서 만들어진 스트리밍 프레임워크) 같은 다른 기술들도 사용된다. 스톰과 나머지 스트리밍 기술들은 이동하는 데이터를 확장 가능하고 튼튼한 방식으로 처리하는 데 좋다. 그래서 맵리듀스와 같이 사용되기도 한다. 배치로 했을 때의 맹점을 커버할 수 있기 때문이다.
실시간으로 처리할 수 있다면, 왜 모두가 스트리밍을 하지 않을까? 스트리밍 패러다임은 장기적 상태의 저장이나 대량의 데이터를 취합하는 데 있어 문제가 있다. 간단히 생각해서 배치가 잘하는 건 못한다. 그래서 두 기술이 상호보완적인 것이다. 스트리밍과 배치의 조합 (특히 맵리듀스와 스톰)은 람다 아키텍쳐라 불리는 아키텍쳐 패턴의 근간이며 이는 데이터를 배치 시스템과 스트리밍 시스템의 두 갈래로 보낸다. 스트리밍 시스템은 실시간 어플리케이션을 만족시키면서 가장 최신의 데이터를 다룬다. 배치 시스템은 주기적으로 돌아가서 장기적으로 취합된 정확한 결과를 가져다 준다. http://lambda-architecture.net에서 더 자세한 내용을 확인할 수 있다.
기본적으로 우리가 이전에 이야기 했던 프레임워크 (피그, 하이브, 크런치, 스캘딩, 캐스캐이딩) 등은 맵리듀스 위에서 만들어졌고 맵리듀스의 한계점을 그대로 갖는다. 고수준임을 유지하면서 인터랙티브한 ad hoc 분석에 더 잘 알맞는 무료 오픈소스 엔진이 몇몇 만들어졌다. 클라우데라의 임팔라는 거대 병렬 처리 (Massively Parallel Procesing, MPP) 에 SQL을 구현했으며 이들 중 초기에 해당한다. 지난 10년 간 독점 분산 데이터베이스가 임팔라를 사용하였다 (Greenplum, Netezza, Teradata 등). 아파치 Tez는 좀 더 일반화 된 맵리듀스를 구현하였다. 스파크는 반복적인 분석이 맵리듀스로 느려지지 않고 더 빨리 돌아갈 수 있도록 메모리를 똑똑하게 사용한다. 이 프레임워크들에 대한 주목도가 증가하고 있다.
맵리듀스는 큰 배치를 전달하는데 좋고 확장 가능성도 지닌다. 맵리듀스는 엄청 빠르진 않지만 길게 보면 많은 일을 해결할 수 있다.
요약
- 하둡은 HDFS, 맵리듀스, YARN과 하둡 에코시스템으로 이루어져 있다.
- 하둡은 분산 시스템이지만 사용자에게 그 사실을 숨긴다.
- 하둡은 선형적으로 확장된다.
- 하둡은 특별한 하드웨어를 필요로 하지 않는다.
- 하둡으로 비정형 데이터를 분석할 수 있다.
- 하둡은 쓰기 시점 스키마가 아닌 읽기 시점 스키마이다.
- 하둡은 오픈 소스이다.
- HDFS는 데이터를 잃는 위험을 최소화하여 많은 데이터를 저장할 수 있다.
- HDFS는 작업하는데 제한이 있을 수가 있다.
- YARN은 지능적으로 클러스터에 작업을 나누어 준다.
- YARN은 뒤에서 모든 일을 하지만 하둡 개발자와 딱히 접점이 없다.
- 맵리듀스는 비공유 접근 방식으로 데이터 지역성이란 장점을 취해 많은 양의 데이터를 처리할 수 있다.
- 맵리듀스보다 좋은 일을 하는 기술들이 있지만 다 맵리듀스보다 좋은 건 아니다.
