https://the-dev.tistory.com/31
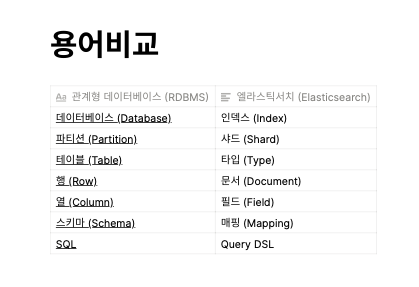
1. 관계형 데이터베이스 vs 엘라스틱서치
인덱스 (Index)
- 데이터 저장공간
- 하나의 인덱스는 하나의 타입만 가짐
- 동시에 여러 개의 인덱스를 검색하는 것도 가능
- 분산 환경으로 구성 시, 하나의 인덱스가 여러 노드에 분산 저장 및 관리됨
- 인덱스의 이름은 반드시 소문자로
- 인덱스가 없는 상태에서 데이터를 삽입하면 그 정보를 바탕으로 인덱스가 자동 생성됨
샤드 (Shard)
- 색인된 데이터가 나뉘어 저장되는 물리적 공간 내 파티션
- 다수의 샤드로 문서를 분산 저장함으로써 데이터 손실 위험을 최소화
타입 (Type)
- 엘라스틱서치 6.1버전부터 하나의 인덱스에는 하나의 타입만 사용 가능
- 인덱스의 논리적 구조
문서 (Document)
- 데이터가 저장되는 최소 단위
- JSON 포맷으로 저장됨
- 하나의 문서는 다수의 필드로 구성
- 문서 안에 문서도 가능
필드 (Type)
- 문서를 구성하기 위한 속성 (DB의 Column같은 개념)
- 하나의 필드는 다수의 데이터 타입을 가질 수 있음
매핑 (Mapping)
- 문서의 필드와 필드의 속성을 정의하고 그에 따른 색인 방법을 정의하는 프로세스
- 매핑 정보에 여러 가지 데이터 타입을 지어할 수 있지만 필드명을 중복 사용할 수 없음
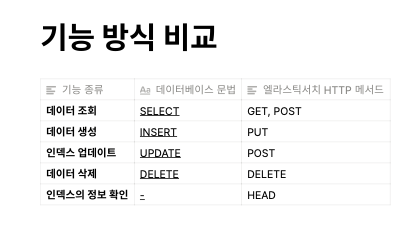
2. 엘라스틱서치의 특징
-
NoSQL (No Structured Query Language)
-
분산 처리를 통해 빠른 검색 가능
-
HTTP를 통해 JSON형식의 Restful API 이용
-
RDBMS에서 LIKE 검색할 때와 달리 검색어의 대소문자에 유연
-
비정형 데이터도 검색 가능
-
분석 통계 유용
-
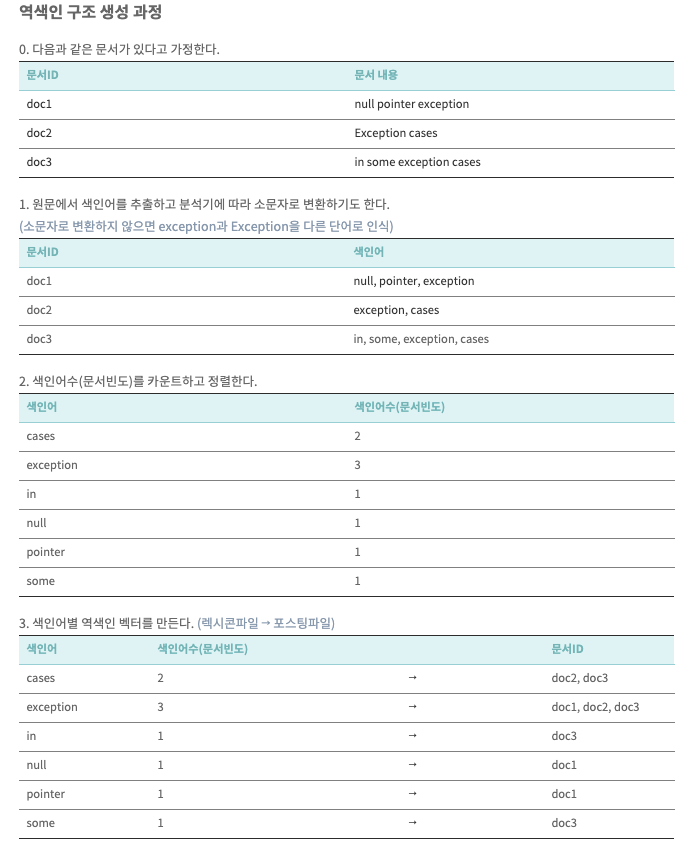
역색인 구조
-
키워드를 통해 문서를 찾아내는 방식
-
책 뒷편의 색인된 키워드를 이용해 역으로 본문(문서)를 찾는 방식
-
검색이 매우 빠르다!!
-
-
스키마리스(Schemaless; 인덱스(→ 데이터베이스) 가 없더라도 문서를 추가하면 인덱스를 자동생성 - 비권장)
└ 엘라스틱서치에서 문자열은 단순 문자열(keyword)과 형태소 분석이 가능한(text)타입으로 구분하는데 자동 생성은 둘 다 생성해 버리므로 공간낭비가 심하고 데이터 구조가 복잡할 수록 검색 품질이 저하될 수 있음
└ action.auto_create_index를 false로 설정해서 끌 수 있음
-
전문 검색(Full-text Search; 내용 전체를 색인해서 특정 단어가 포함된 문서를 검색) 가능
-
멀티테넌시(Multi-tenancy; 상이한 인덱스일지라도 동일한 필드명을 대상으로 검색 가능)
-
트랜잭션과 롤백 기능을 제공하지 않으므로 데이터 손실의 위험도 있음
-
업데이트 명령 시, 기존 내용을 삭제하고 새로 생성하는 방식

재밌는게 재밌는거다