SS-hashtag-recommendation-project
1.Query-Document Relevance Ranking model
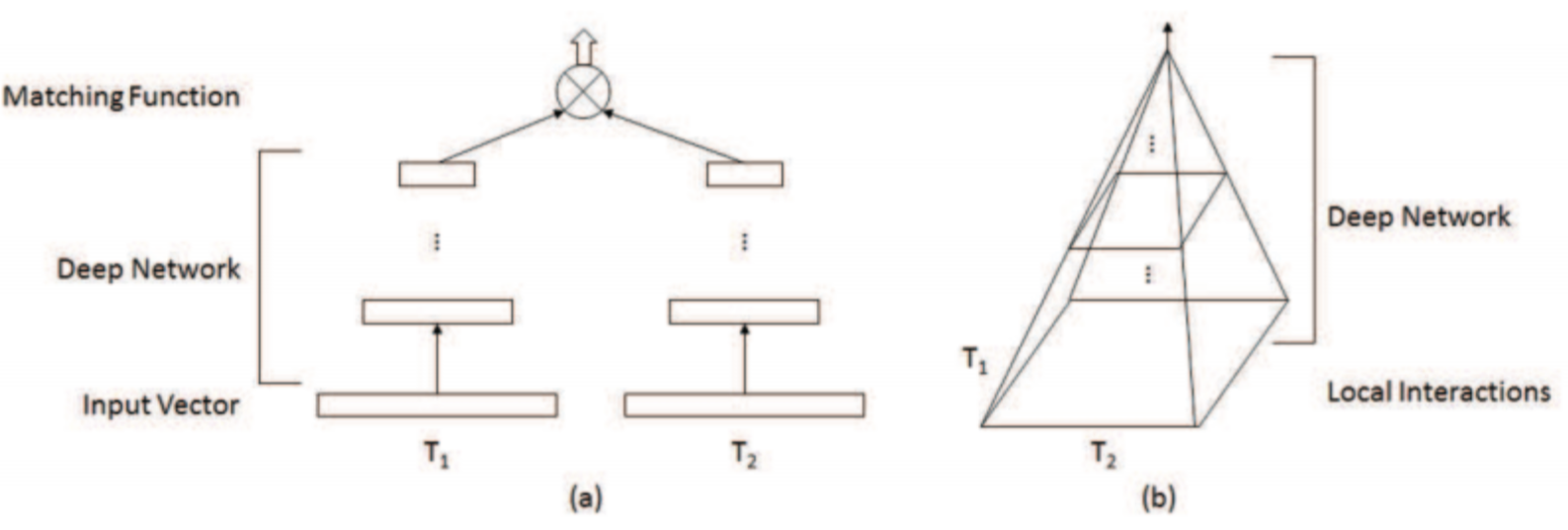
https://tnsgh0101.medium.com/query-document-relevence-ranking-model-596c8571b84The major contributions of this paper include의미적, 관련성 매칭의 차이점을 지적하
2.여러 유사도 계산 기법을 text similarity에 도입한 결과 refers

Text Similarities : Estimate the degree of similarity between two texts
3.Different embeddings+ Word Mover Distance 😊😊
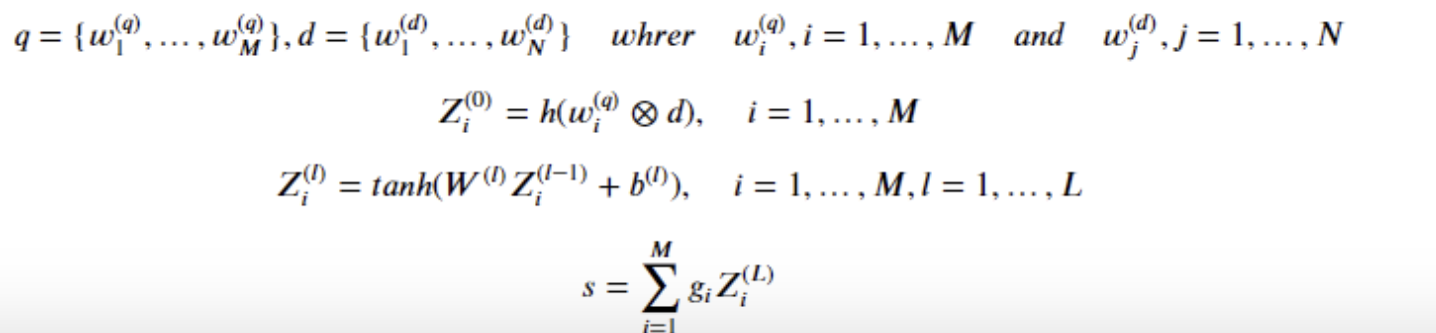
Obama speaks to the media in IllinoisThe president greets the press in ChicagoObama speaks media Illinoispresident greets press Chicago위의 두 문장의 경우, 공통
4.Different embeddings+ LDA + Jensen-Shannon distance 😊
LDA has many uses:Understanding the different varieties topics in a corpus (obviously),Getting a better insight into the type of documents in a corpus
5.spherical k means for document clustering
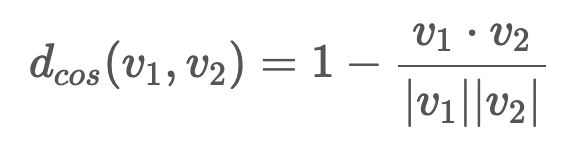
references:https://lovit.github.io/nlp/machine%20learning/2018/10/16/spherical_kmeans/https://github.com/lovit/clustering4docskmeans 는 유클리드
6.clustering references
기본적인 clustering 기법들: https://yamalab.tistory.com/118NMF topic modeling: https://medium.com/towards-artificial-intelligence/topic-modeling-wi
7.생성 모델링
출처: 미술관에 GAN 딥러닝확률 모델의 관점으로 보면 생성 모델은 데이터 셋을 생성하는 방법을 기술한 것이 모델에서 샘플링하면 새로운 데이터를 생성할 수 있다.생성 모델은 확률적이어야 한다.(예)말 이미지를 생성하는 모델을 만든다고 하자.이 모델은 말의 외관을 결정하
8.Similar Image Retrieval using Autoencoders
It turns out that encoded representations (embeddings) given by the encoder are magnificent objects for similarity retrieval.With such a condensed enc
9.VAE research
https://towardsdatascience.com/variational-autoencoders-as-generative-models-with-keras-e0c79415a7ebAn autoencoder is basically a neural network
10.ANNS(Approximated nearest neighbor search)
https://yamalab.tistory.com/132?category=747907벡터간의 유사도 계산은 엄청난게 오래걸리고, 이를 실시간으로 처리하기에는 너무 오래걸린다벡터를 색인한다는 것은 유사 벡터를 빠르게 찾을 수 있는 데이터 구조를 구축하는 것을 의
11.벡터 필드를 사용한 텍스트 유사도 검색
https://www.elastic.co/kr/blog/text-similarity-search-with-vectors-in-elasticsearch기존 정보 검색에서는 텍스트를 숫자 벡터로 나타낼 때 어휘의 각 단어에 하나의 차원을 지정하는 것이 일반적입니다
12.Elastic search
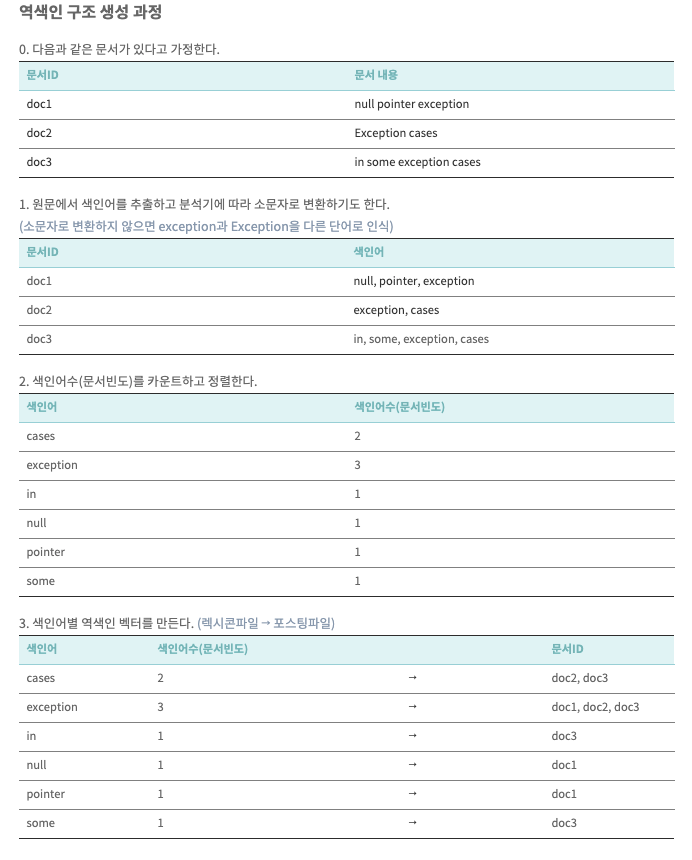
https://the-dev.tistory.com/31 1. 관계형 데이터베이스 vs 엘라스틱서치 인덱스 (Index) 데이터 저장공간 하나의 인덱스는 하나의 타입만 가짐 동시에 여러 개의 인덱스를 검색하는 것도 가능 분산 환경으로 구성 시, 하나의 인덱스가 여
13.BM25
https://littlefoxdiary.tistory.com/12BM25(a.k.a Okapi BM25)는 주어진 쿼리에 대해 문서와의 연관성을 평가하는 랭킹 함수로 사용되는 알고리즘으로, TF-IDF 계열의 검색 알고리즘 중 SOTA 인 것으로 알려져 있
14.Approximate nearest neighbor methods and vector models

https://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup출처: spotify engineering lead slideshare S
15.Self Supervised Representation Learning in NLP
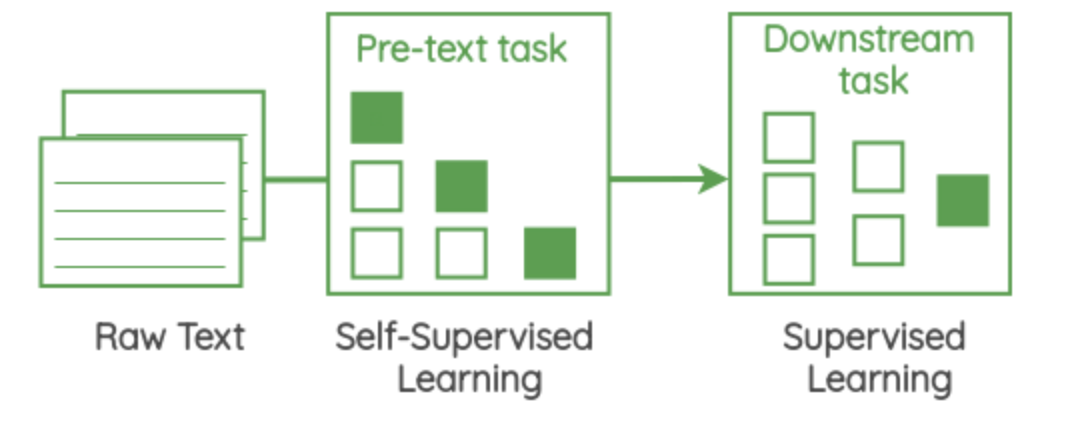
Language Models have existed since the 90’s even before the phrase “self-supervised learning” was termed.At the core of these self-supervised methods