https://tnsgh0101.medium.com/query-document-relevence-ranking-model-596c8571b84
A Deep Relevance Matching Model for Ad-hoc Retrieval (DRMM)
The major contributions of this paper include
- 의미적, 관련성 매칭의 차이점을 지적하고 그에따른 모델 구조 설명
- 관련성 매칭에 대한 3가지 핵심요인을 따른 새로운 모델 제안
- 기존 방식의 단점과 제안한 모델(DRMM)의 장점 분석
Introduction:
-
랭킹 시스템에서 일반적인 딥러닝 모델은 두 text의 매칭문제로 바라보았습니다.
-
이에 논문은 모델 접근법에 따라
-
표현중심(representation-forcused) 모델(DSSM, ARC-I)
-
상호작용중심(Interaction-focused) 모델(Deep Match, ARC-II)
로 구분하고 이에 따른 모델 아키텍쳐를 설명합니다. -
논문은 딥러닝이 좋은 성과를 내지못한 이유가 제안되었던 접근 방식들이, 의미론적 매칭을 위한, 표현중심 모델링이기 때문이라고 주장 하였습니다.
-
논문은 retrival task는 기존의 의미적 매칭 접근법과 근본적으로 다르며 관련성 기준으로 매칭시켜야 한다고 주장합니다
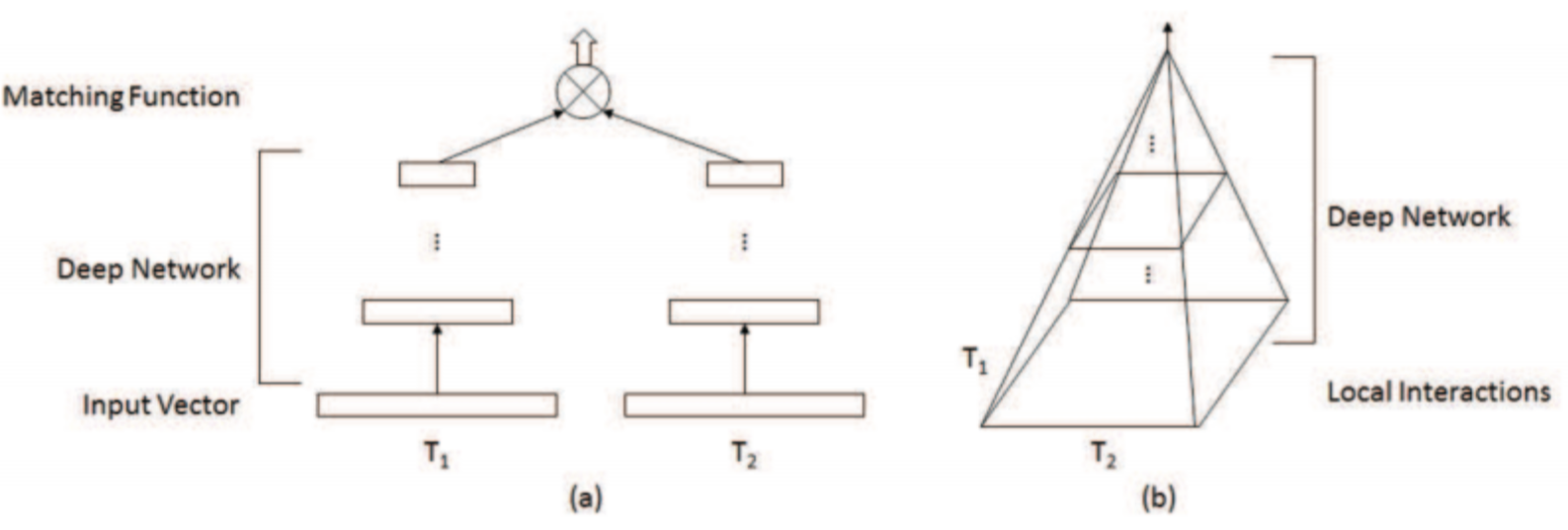
(a)representation-focused (b)Interaction-focused
-
표현중심 모델
- 각 text의 의미를 잘 표현하는 구조에 집중하여
- 검색어와 검색결과의 의미를 매칭시키는데 집중합니다.
- 검색어와 검색 결과를 각각 input으로 모델에 입력 → 대칭적 아키텍쳐
-
상호작용 중심 모델
- 두 text의 상호작용을 계층적으로 배워
- 관련성을 매칭시키는데 집중합니다.
- 검색어와 검색결과의 연산을 거쳐 계층적인 일치도를 파악→ 피라미드형 아키텍쳐
Ad-hoc retrieval as a matching problem:
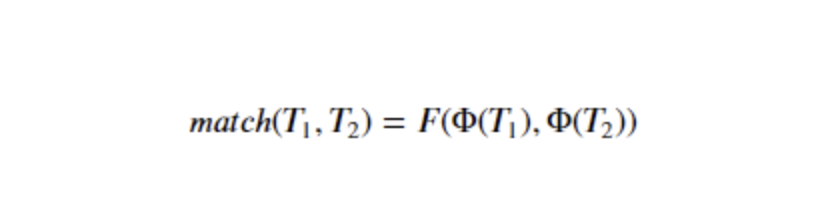
- Φ는 word2vec처럼 text를 vector로 표현하는 함수
- 𝐹는 계산된 벡터 표현으로부터 점수를 계산하는 함수
- 접근법에 따라 함수 또한 달라지는데, 일반적으로 표현중심모델은 문장의 벡터표현이 중요하기 때문에 상대적으로 Φ부분이 복잡하고, 상호작용 중심 모델의 경우는 두 텍스트 사이의 상호작용을 계층적으로 파악하려 하기에 𝐹부분이 복잡합니다.
semantic matching VS relevance matching의 차이:
- paraphrase identification, question answering, automatic conversation와 같은 NLP task에서의 매칭은 주로 semantic matching으로 접근합니다.
- semantic matching
- similarity matching signals
: 서로 다르게 표현된 문장들이 같은 의미를 가지는지 다른 의미를 가지는지 식별할 수 있어야 합니다. (예: 니 밥은 먹었나? = 진지 드셨어요?) - compositional meanings
: 의미론적 매칭을 요구하는 작업의 텍스트 데이터는 일반적으로 문법 구조를 가진 자연어 문장으로 구성되어 있습니다. 이는 문법 구조를 포착할 수 있는 모델링이 유리하다는것을 의미합니다. - Global matching requirement
: 두 텍스트를 전체적인 의미를 유추한뒤 텍스트를 매칭시켜야 합니다.
- similarity matching signals
- relevance matching
- Exact matching signals
: 두 텍스트의 의미론적 관련성 신호가 중요하긴 하지만 비교하는 텍스트의 정확한 일치신호가 훨신더 강력한 신호로 다루어야 합니다. Fang and Zhai)는 의미적으로 비슷한 용어를 여러번 일치시키는 것보다 정확히 같은 용어의 신호를 다루는것이 관련성 점수에 기여한다고 하였습니다. 이는 BM25와 같은 전통적인 머신러닝방법이 잘 작동하는 이유이기도 합니다. - Query term importance
: 일반적으로 검색어는 키워드 기반입니다 이는 검색어에서 단어가 ‘and’관계이며 상대적인 중요도가 존재한다는 것입니다. (예: ‘비트코인 뉴스’라는 검색어는 ‘비트코인’과 ‘뉴스’라는 키워드로 이루어져있으며 중요도는 ‘비트코인’ < ‘뉴스’로 해석할 수 있습니다) - Diverse matching requirement
: 검색 결과의 문서는 매우 길어질 수 있으며 문서 길이에 대해 서로 다른 가설이있어 다양한 요구 사항이 발생합니다.- Verbosity Hypothesis: 긴 문서는 짧은 문서와 유사하지만 많은 단어를 담고 있다. 이 경우 짧은 문서에 집중된 주제가 있다고 가정하면 관련성 일치가 Global해야 합니다.
- Scope Hypothsis : 긴 문서는 여러개의 관련없는 짧은 문서로 구성되어 있다. 이 경우 관련성 일치는 문서의 어느 부분에서나 발생할 수 있으며 문서 전체가 쿼리와 관련 될 필요는 없다고 합니다.
- Exact matching signals
이를 볼때 기존 방식은 대부분 의미론적 매칭에 가까우며, 검색서비스에서는 관련도 추론이 더욱 적합합니다.
Deep Relevance Matching Model:
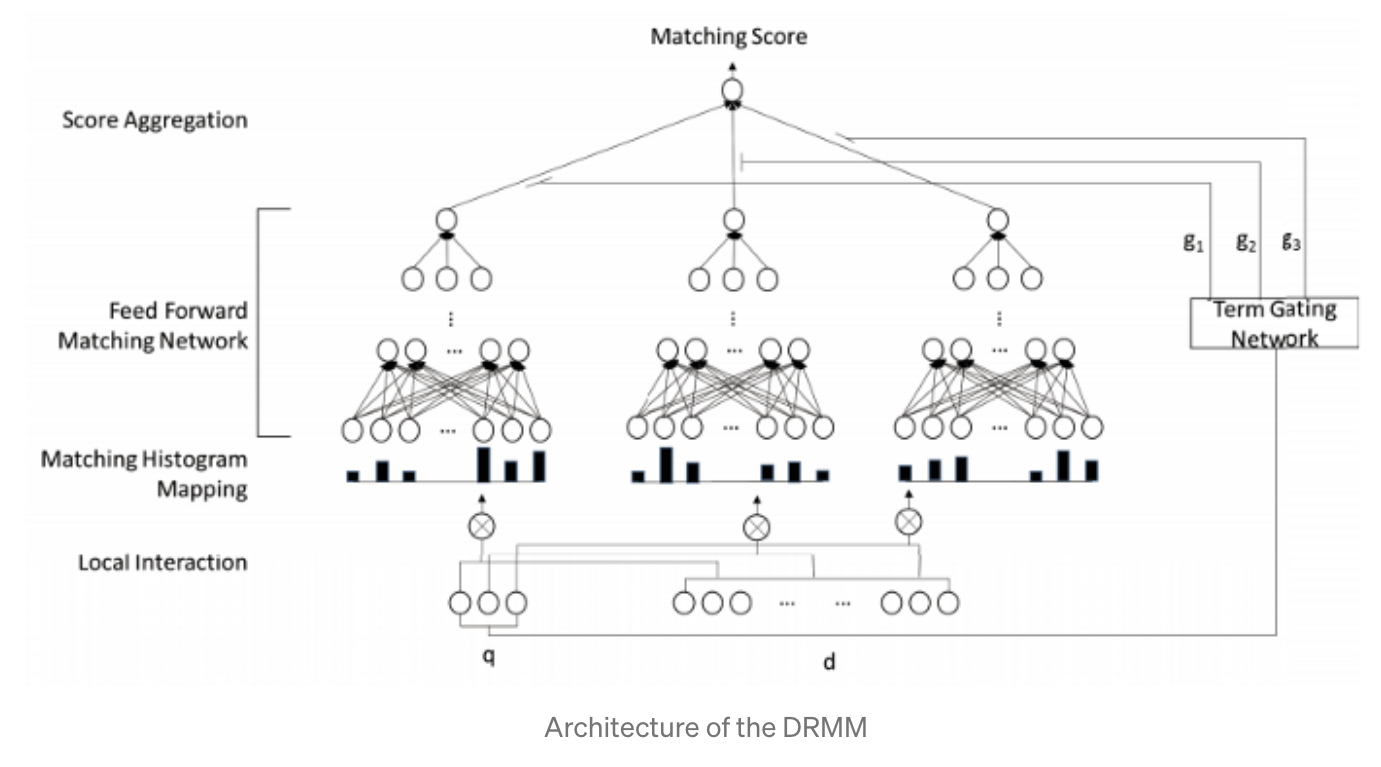
- ^q와 w^d는 pretrained word2vec으로 표현된 term vector
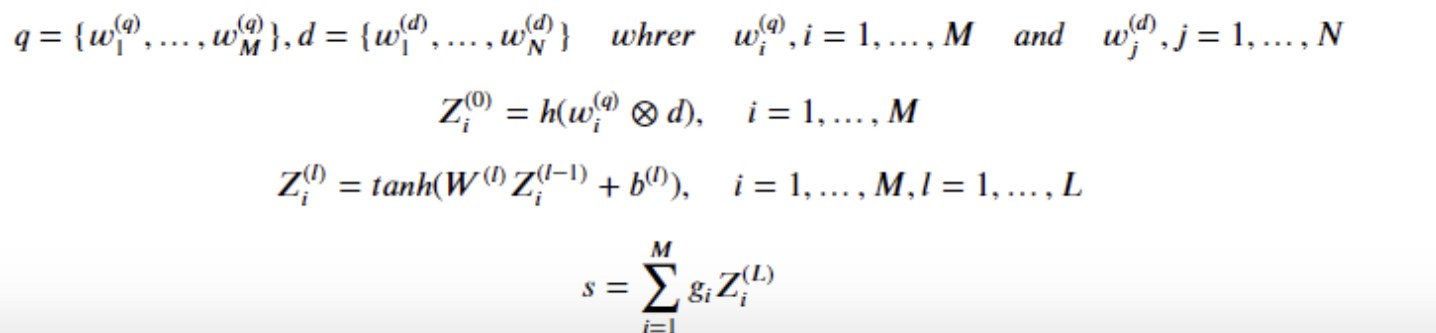
Local Interaction (𝑤⊗𝑑)
- ⊗는 interaction operator입니다. 거창해보이지만 pretrained word2vec모델로 표현된 단어들의 cos 유사도입니다…즉, 검색어와 검색결과의 각 단어들마다 유사도 행렬을 구합니다.
- pretrained word2vec를 사용하는 이유는 ground truth보다 Large scale unlabeled text collection에서 학습된 표현이 정확도가 높았고 전체 모델의 복잡성을 낮추기 위해서라고 합니다.
Matching Histogram Mapping ℎ(𝑥)
- 가변길이 tensor를 고정길이로 구간입니다. 논문에 따르면 Local Interaction에서 구한 유사도 행렬이 위에 서술한 Diverse matching requirement를 만족하지 못하기 때문에 잠재적으로 유사도 행렬이 적합하지 않을수 있다고 합니다.
→ 그러므로 DRMM은 히스토그램을 채택하여 위치보다 신호의 강도를 그룹화 합니다. - 예를들어 코사인 유사도를 0.5마다 그룹화하면 {[−1, −0.5), [−0.5, −0), [0, 0.5), [0.5, 1), [1, 1]}라는 5개의 그룹이 나옵니다.
→ 여기서 Exact matching signals 요구사항을 만족시키기 위하여 정확한 일치 신호인 [1, 1]그룹을 명시적으로 표현합니다.
예) 이때 검색어에서 “car”라는 단어와 문서의 “car, rent, truck, bump, injunction, runway”라는 단어들의 유사도가 (1, 0.2, 0.7, 0.3, −0.1, 0.1)라고 계산되었다면 그룹화한 유사도 히스토그램은 [0, 1, 3, 1, 1]으로 표현됩니다.
계산된 히스토그램을 그대로 사용할 수 있지만 한번의 계산을 거쳐 좀더 좋은 정보로 바꿉니다.
- Count-based Histogram (CH)
각 구간에 속한 유사도들의 빈도를 히스토그램으로 사용합니다. 그냥 위에 구한 히스토그램을 그대로 사용하는것입니다. - Normalized Histogram (NH)
Count-based Histogram를 정규화 해서 절대 갯수가 아닌 상대 갯수정보를 사용합니다. - LogCount-based Histogram (LCH)
Count-based Histogram에 로그함수를 적용하여 범위를 줄여 모델이 곱셈관계를 더 쉽게 배울수 있게 합니다.
정리하자면 히스토그램을 채택함으로써 정확한 매칭과 유사한 매칭신호를 명확하게 구분하고 가변길이 벡터를 패딩없이 고정길이 벡터로 표현합니다.
Feed forward Matching Network 𝑍=𝑡𝑎𝑛ℎ(x)
이 구간에서는 계층적 일치 패턴을 학습합니다. 기존에는 CNN을 사용함으로써 계층적 패턴을 학습하려 했습니다. 이러한 모델은 (Local)Receptive Field가 있는 Conv unit을 사용하고 일치 패턴에서 위치 규칙을 학습합니다. 즉 Global matching requirement를 만족하므로 의미론적 매칭 모델에서 잘 작동합니다.
하지만 논문은 검색어에서 위치 규칙성이 없을 수 있으므로 CNN은 적합하지 않다고 판단하여 MLP를 채택합니다. 이에 DRMM은 위치보다 강도에 신호의 강도에 중점을 두어 더욱 유리하다고 합니다.
