파이썬의 데이터 표현
기본 통계 데이터 생각해보기
평균, 분산, 표준편차, 중앙값 등이 있다. 우선 평균 먼저 계산해보자!
평균은 숫자들의 합을 숫자의 총 개수로 나눈 값이다. 아래는 예제 코드이다.
total = 0
count = 0
numbers = input("Enter a number : (<Enter Key> to quit)")
while numbers != "":
try:
x = float(numbers)
count += 1
total = total + x
except ValueError:
print('NOT a number! Ignored..')
numbers = input("Enter a number : (<Enter Key> to quit)")
avg = total / count
print("\n average is", avg)
/-----------------------------------------------------------/
# 출력
코드 실행
Enter a number : (<Enter Key> to quit) 1
Enter a number : (<Enter Key> to quit) 2
Enter a number : (<Enter Key> to quit) 3
Enter a number : (<Enter Key> to quit)
average is 2.0배열 활용해보기
배열은 하나의 객체에 데이터 값이 여러 개 들어있는 형태이다. 파이썬에서는 리스트로 기능을 제공한다.
X = [x1, x2, x3,....xn] 그렇다면 사용자가 입력한 데이터로 배열을 만들어보자!
# 2개 이상의 숫자를 입력받아 리스트에 저장하는 함수
def numbers():
X=[] # X에 빈 리스트를 할당합니다.
while True:
number = input("Enter a number (<Enter key> to quit)")
while number !="":
try:
x = float(number)
X.append(x) # float형으로 변환한 숫자 입력을 리스트에 추가
except ValueError:
print('>>> NOT a number! Ignored..')
number = input("Enter a number (<Enter key> to quit)")
if len(X) > 1: # 저장된 숫자가 2개 이상일 때만 리턴
return X
X=numbers()
print('X :', X)
/----------------------------------------------------------------------/
# 출력
Enter a number (<Enter key> to quit) 1
Enter a number (<Enter key> to quit) 2
Enter a number (<Enter key> to quit) 3
Enter a number (<Enter key> to quit) 4
Enter a number (<Enter key> to quit) 5
Enter a number (<Enter key> to quit)
X : [1.0, 2.0, 3.0, 4.0, 5.0]해당 코드를 보면 변수 X에 빈 리스트를 할당하여 초기화한 후 리스트의 append 메서드를 이용해 원소를 계속 추가하는 것을 알 수 있다. 다른 언어의 배열과 달리 파이썬은 가변적인 형태를 가지고 있다. 즉, 파이썬 리스트는 동적 배열(Dynamic Array)이다.
리스트와 배열
엄밀하게 개념을 구분하자면, 선형적 데이터를 다루는 자료구조인
list와array는 서로 다르다. 아래 링크를 참고하면 차이점을 알 수 있다.
리스트와 배열의 차이
리스트와 배열의 차이
- list는 별도의 import가 필요 없지만 array를 사용하기 위해서는 import 해주어야 한다. 파이썬에서 array는 built-in이 아니다.
- list 안의 element 사이에 다른 타입의 자료형이 허용된다. 숫자로만 이루어진 list에 문자열 element를 추가할 수 있다. 그러나 array는 처음부터 element의 유형을 지정해서 생성하며, 지정되지 않은 다른 타입의 element 추가가 허용되지 않는다. 이러한 array의 특성은 다음에 나오는 NumPy에도 동일하게 적용된다.
import array as arr
mylist = [1, 2, 3] # 이것은 파이썬 built-in list이다.
print(type(mylist))
mylist.append('4') # mylist의 끝에 character '4'를 추가
print(mylist)
mylist.insert(1, 5) # mylist의 두번째 자리에 5를 끼워넣는다.
print(mylist)
myarray = arr.array('i', [1, 2, 3]) # 이것은 array다. import array를 해야 쓸 수 있다.
print(type(myarray))
# 아래 라인의 주석을 풀고 실행하면 에러가 난다.
#myarray.append('4') # myarray의 끝에 character '4'를 추가
print(myarray)
myarray.insert(1, 5) # myarray의 두번째 자리에 5를 끼워넣는다.
print(myarray)
/--------------------------------------------------------------------------------/
# 출력
<class 'list'>
[1, 2, 3, '4']
[1, 5, 2, 3, '4']
<class 'array.array'>
array('i', [1, 2, 3])
array('i', [1, 5, 2, 3])시그마 표현하기
평균값을 for문을 이용해 쉽게 구현해보자!
total = 0.0
for i in range(len(X)):
total = total + X[i]
mean = total / len(X)
print('sum of X: ', total)
/------------------------/
# 출력
sum of X: 15.0중앙값
중앙값(median)은 주어진 숫자를 크기 순서대로 배치할 때 가장 중앙에 위치하는 숫자로 숫자의 개수가 홀수이냐 짝수이냐에 따라 값이 달라질 수 있다.
- 만약 숫자가 1, 2, 3, 6, 7, 9, 10 이라면, 중앙값은 6
- 만약 숫자가 1, 2, 3, 7, 7, 10 이라면, 중앙값은 (3 + 7) / 2 = 5
이걸 코드로 구현할 때 조건은 아래와 같다.
- n이 홀수이면 n/2을 반올림한 순서의 값이 중앙값
- n이 짝수라면 n/2번째 값과 ((n/2) + 1) 번째 값의 평균
def median(nums): # nums : 리스트를 지정하는 매개변수
nums.sort() # sort()로 리스트를 순서대로 정렬
size = len(nums)
p = size // 2
if size % 2 == 0: # 리스트의 개수가 짝수일때
pr = p # 4번째 값
pl = p-1 # 3번째 값
mid= float((nums[pl]+nums[pr])/2)
else: # 리스트의 개수가 홀수일때
mid = nums[p]
return mid
print('X :', X)
median(X) # 매개변수의 값으로 X를 사용함
/------------------------------------------------------------/
# 출력
X : [1.0, 2.0, 3.0, 4.0, 5.0]
3.0표준편차와 평균
1) 평균
def means(nums):
total = 0.0
for i in range(len(nums)):
total = total + nums[i]
return total / len(nums)
means(X)
/-----------------------------/
# 출력
3.02) 표준편차
avg = means(X)
def std_dev(nums, avg):
texp = 0.0
for i in range(len(nums)):
texp = texp + (nums[i] - avg)**2 # 각 숫자와 평균값의 차이의 제곱을 계속 더한 후
return (texp/len(nums)) ** 0.5 # 그 총합을 숫자개수로 나눈 값의 제곱근을 리턴
std_dev(X,avg)
/-------------------------------=========------------------------------------------/
# 출력
1.4142135623730951Numpy
NumPy는 Numerical Python의 줄임말로, 과학 계산용 고성능 컴퓨팅과 데이터 분석에 필요한 파이썬 패키지이다. 기본 제공되는 패키지가 아니기 때문에 pip를 이용해 설치해야한다.
pip install numpy파이썬의 모듈, 패키지, pip?
NumPy의 장점
- 빠르고 메모리를 효율적으로 사용하여 벡터의 산술 연산과 브로드캐스팅 연산을 지원하는 다차원 배열 ndarray 데이터 타입을 지원
- 반복문을 작성할 필요 없이 전체 데이터 배열에 대해 빠른 연산을 제공하는 다양한 표준 수학 함수를 제공
- 배열 데이터를 디스크에 쓰거나 읽을 수 있다. (즉 파일로 저장할 수 있다.)
- 선형대수, 난수발생기, 푸리에 변환 가능, C/C++ 포트란으로 쓰여진 코드를 통합
NumPy를 사용하기 위해서는 ndarray 객체를 만들어야한다. ndarray 객체를 이용하면 파이썬에서 사용하는 대규모 데이터 집합을 n차원 배열로 담을 수 있다. ndarray 객체는 arange()와 array([])로 만들 수 있다.
import numpy as np
# 아래 A와 B는 결과적으로 같은 ndarray 객체를 생성
A = np.arange(5)
B = np.array([0,1,2,3,4]) # 파이썬 리스트를 numpy ndarray로 변환
# 하지만 C는 좀 다를 것이다.
C = np.array([0,1,2,3,'4'])
# D도 A, B와 같은 결과를 내겠지만, B의 방법을 권장
D = np.ndarray((5,), np.int64, np.array([0,1,2,3,4]))
print(A)
print(type(A))
print("--------------------------")
print(B)
print(type(B))
print("--------------------------")
print(C)
print(type(C))
print("--------------------------")
print(D)
print(type(D))
/------------------------------------------------------------/
# 출력
[0 1 2 3 4]
<class 'numpy.ndarray'>
--------------------------
[0 1 2 3 4]
<class 'numpy.ndarray'>
--------------------------
['0' '1' '2' '3' '4']
<class 'numpy.ndarray'>
--------------------------
[0 1 2 3 4]
<class 'numpy.ndarray'>C의 경우 '4'가 하나 들어갔을 뿐인데 0, 1, 2, 3이 모두 문자열로 바뀌었다.
왜 문자열로 변경될까?
문자열이 정수형 타입보다 범위가 크기때문에 더 큰 범위를 갖고 있는 문자열로 변경된다.
크기
ndarray.sizendarray.shapendarray.ndimreshape()
size, shape, ndim는 각각 행렬 내 원소의 개수, 행렬의 모양, 행렬의 축(axis)의 개수를 의미한다. reshape() 메서드는 행렬의 모양을 바꿔준다. 주의할 점은 모양을 바꾸기 전후 행렬의 총 원소 개수(size)가 맞아야 한다.
A = np.arange(10).reshape(2, 5) # 길이 10의 1차원 행렬을 2X5 2차원 행렬로 바꿔봅니다.
print("행렬의 모양:", A.shape)
print("행렬의 축 개수:", A.ndim)
print("행렬 내 원소의 개수:", A.size)
/--------------------------------/
# 출력
행렬의 모양: (2, 5)
행렬의 축 개수: 2
행렬 내 원소의 개수: 10사이즈가 맞지 않는 경우
A = np.arange(10)
print('A: ', A)
B = np.arange(10).reshape(2,5)
print('B: ', B)
C = np.arange(10).reshape(3,3) # 이 줄에서 에러가 날 것이다.
print('C: ', C)
/-------------------------------------------------------/
# 출력
A: [0 1 2 3 4 5 6 7 8 9]
B: [[0 1 2 3 4]
[5 6 7 8 9]]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_16/2976122378.py in <module>
3 B = np.arange(10).reshape(2,5)
4 print('B: ', B)
----> 5 C = np.arange(10).reshape(3,3) # 이 줄에서 에러가 날 것입니다.
6 print('C: ', C)
ValueError: cannot reshape array of size 10 into shape (3,3)type
NumPy 라이브러리 내부의 자료형들은 파이썬 내장함수와 동일하다.
- NumPy :
numpy.array.dtype - 파이썬 :
type()
A= np.arange(6).reshape(2, 3)
print(A)
print(A.dtype)
print(type(A))
print("-------------------------")
B = np.array([0, 1, 2, 3, 4, 5])
print(B)
print(B.dtype)
print(type(B))
print("-------------------------")
C = np.array([0, 1, 2, 3, '4', 5])
print(C)
print(C.dtype)
print(type(C))
print("-------------------------")
D = np.array([0, 1, 2, 3, [4, 5], 6]) # 이런 ndarray도 만들어질까?
print(D)
print(D.dtype)
print(type(D))
/---------------------------------------------------------------/
# 출력
[[0 1 2]
[3 4 5]]
int64
<class 'numpy.ndarray'>
-------------------------
[0 1 2 3 4 5]
int64
<class 'numpy.ndarray'>
-------------------------
['0' '1' '2' '3' '4' '5']
<U21
<class 'numpy.ndarray'>
-------------------------
[0 1 2 3 list([4, 5]) 6]
object
<class 'numpy.ndarray'>
/tmp/ipykernel_16/130055213.py:19: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
D = np.array([0, 1, 2, 3, [4, 5], 6]) # 이런 ndarray도 만들어질까요?D = np.array([0, 1, 2, 3, [4, 5], 6], dtype=object) # warning 메시지를 보고 이렇게 바꾸자.
print(D)
print(D.dtype)
print(type(D))
/------------------------------------------------------------------------------------/
# 출력
[0 1 2 3 list([4, 5]) 6]
object
<class 'numpy.ndarray'>특수 행렬
- 단위행렬
- 0 행렬
- 1 행렬
# 단위행렬
np.eye(3)
/--------/
# 출력
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])# 0 행렬
np.zeros([2,3])
/-------------/
# 출력
array([[0., 0., 0.],
[0., 0., 0.]])# 1행렬
np.ones([3,3])
/------------/
# 출력
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])브로드캐스트
NumPy의 강력한 연산 기능 중 하나인 브로드캐스트(broadcast) 연산이다.
브로드캐스트
A = np.arange(9).reshape(3,3)
A
/---------------------------/
# 출력
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])# ndarray A에 2를 상수배 했을 때,
A * 2
/------/
# 출력
array([[ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16]])# ndarray A에 2를 더했을 때,
A + 2
/------/
# 출력
array([[ 2, 3, 4],
[ 5, 6, 7],
[ 8, 9, 10]])이렇게 ndarray와 상수, 또는 서로 크기가 다른 ndarray끼리 산술연산이 가능한 기능을 브로드캐스팅이라고 한다.
슬라이스와 인덱싱
# 3 X 3 행렬의 첫번째 행을 구해보자.
A = np.arange(9).reshape(3,3)
print("A:", A)
B = A[0]
print("B:", B)
/-----------------------------/
# 출력
A: [[0 1 2]
[3 4 5]
[6 7 8]]
B: [0 1 2]A[:-1]
/-------/
# 출력
array([[0, 1, 2],
[3, 4, 5]])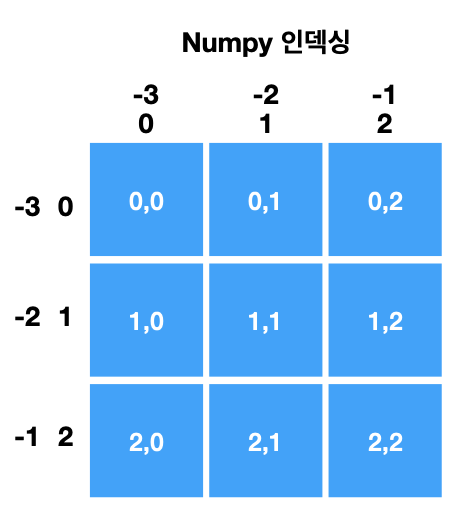
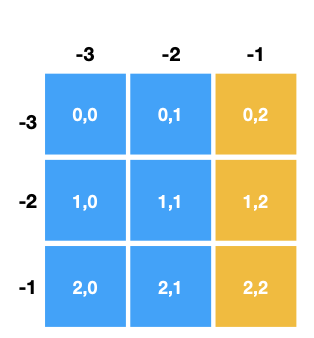
# 이 슬라이싱의 결과는
print(A[:,2:])
print("--------------")
print(A[:,1:])
print("--------------")
print(A[:,:])
print("--------------")
# 이 슬라이싱의 결과와 동일
print(A[:,-1:])
print("--------------")
print(A[:,-2:])
print("--------------")
print(A[:,-3:])
/---------------------/
# 출력
[[2]
[5]
[8]]
--------------
[[1 2]
[4 5]
[7 8]]
--------------
[[0 1 2]
[3 4 5]
[6 7 8]]
--------------
[[2]
[5]
[8]]
--------------
[[1 2]
[4 5]
[7 8]]
--------------
[[0 1 2]
[3 4 5]
[6 7 8]]random
NumPy에서도 다양한 의사 난수를 지원한다.
np.random.randint()np.random.choice()np.random.permutation()np.random.normal()np.random.uniform()
print(np.random.random()) # 0에서 1사이의 실수형 난수 하나를 생성
print(np.random.randint(0,10)) # 0~9 사이 1개 정수형 난수 하나를 생성
print(np.random.choice([0,1,2,3,4,5,6,7,8,9])) # 리스트에 주어진 값 중 하나를 랜덤하게 골라준다.
/-----------------------------------------------------------------------------------------/
# 출력
0.3916264789856341
1
9# 무작위로 섞인 배열을 만들어 준다.
# 아래 2가지는 기능면에서 동일하다.
print(np.random.permutation(10))
print(np.random.permutation([0,1,2,3,4,5,6,7,8,9]))
데이터 행렬 변환
데이터별 NumPy표현법
- 소리 데이터 : 1차원 array로 표현한다. CD음원파일의 경우, 44.1kHz의 샘플링 레이트로 -32767 ~ 32768의 정수 값을 갖는다.
- 흑백 이미지 : 이미지 사이즈의 세로X 가로 형태의 행렬(2차원 ndarray)로 나타내고, 각 원소는 픽셀별로 명도(grayscale)를 0~255 의 숫자로 환산하여 표시한다. 0은 검정, 255는 흰색이다.
- 컬러 이미지 : 이미지 사이즈의 세로 X 가로x3 형태의 3차원 행렬이다. 3은 Red, Green, Blue계열의 3 색을 의미한다.
- 자연어 : 임베딩(Embedding)이라는 과정을 거쳐 ndarray로 표현될 수 있다. 블로그의 예시에서는 71,290개의 단어가 들어있는 (문장들로 이루어진) 데이터셋이 있을때, 이를 단어별로 나누고 0 - 71,289로 넘버링했다. 이를 토큰화 과정이라고 한다. 이 토큰을 50차원의 word2vec embedding 을 통해 [batch_size, sequence_length, embedding_size]의 ndarray로 표현할 수 있다.
링크
이미지의 행렬 변환
1) 픽셀과 이미지
이미지는 픽셀이라고 부르는 수많은 점으로 구성되어 있다.
- 각각의 픽셀은 R, G, B 값 3개 요소의 튜플로 색상이 표시
- 흰색(W) : (255,255,255)
- 검정색(B) : (0, 0, 0)
- 빨간색(R) : (255, 0, 0)
- 파란색(B) : (0, 0, 255)
- 녹색(G) : (0, 128, 0)
- 노란색(Y) : (255, 255, 0)
- 보라색(P) : (128, 0, 128)
- 회색(Gray) : (128, 128, 128)
- 흑백의 경우에는 Gray 스케일로 나타내는데, 0~255 범위의 숫자 1개의 튜플 값
- Color는 투명도를 포함하는 A(alpha)를 포함해 RGBA 4개로 표시하기도 한다.
2) 이미지 라이브러리
- matplotlib
- PIL
이미지 조작에 쓰이는 메서드
- open :
Image.open() - size :
Image.size - filename :
Image.filename - crop :
Image.crop((x0, y0, xt, yt)) - resize :
Image.resize((w,h)) - save :
Image.save()
Pandas
판다스 특징
- NumPy기반에서 개발되어 NumPy를 사용하는 애플리케이션에서 쉽게 사용 가능
- 축의 이름에 따라 데이터를 정렬할 수 있는 자료 구조
- 다양한 방식으로 인덱싱(indexing)하여 데이터를 다룰 수 있는 기능
- 통합된 시계열 기능과 시계열 데이터와 비시계열 데이터를 함께 다룰 수 있는 통합 자료 구조
- 누락된 데이터 처리 기능
- 데이터베이스처럼 데이터를 합치고 관계 연산을 수행하는 기능
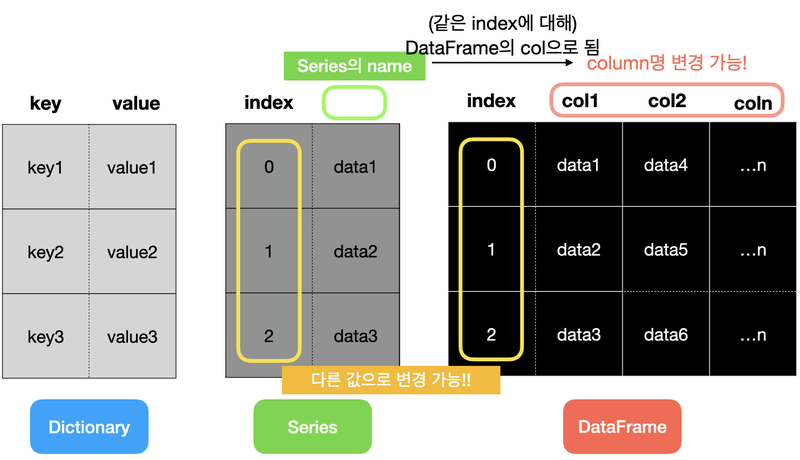
Series
Series는 일련의 객체를 담을 수 있는, 1차원 배열과 비슷한 자료 구조이다. 따라서 배열 형태인 리스트, 튜플, 딕셔너리를 통해서 만들거나 NumPy 자료형(정수형, 실수형 등)으로도 만들 수 있다.
import pandas as pd
ser = pd.Series(['a','b','c',3])
ser
/------------------------------/
# 출력
0 a
1 b
2 c
3 3
dtype: objectDataFrame
DataFrame은 표(table)와 같은 자료 구조입니다. Series는 한 개의 인덱스 컬럼과 값 컬럼, 딕셔너리는 키 컬럼과 값 컬럼과 같이 2개의 컬럼만 존재하는데 비해, DataFrame은 여러 개의 컬럼을 나타낼 수 있다.