
관계 대수와 SQL
관계 대수는 관계 데이터베이스에서 릴레이션을 조작하기 위한 절차적 언어이다. 즉, 원하는 데이터를 얻기 위해 어떤 연산을 어떤 순서로 수행할 것인지를 수학 공식처럼 명시함으로써 릴레이션을 도출할 수 있다. 관계 대수에는 일반 집합 연산자와 순수 관계 연산자가 있으며, 이들은 모두 릴레이션을 입력으로 받아 릴레이션을 출력한다.
SQL은 관계 데이터베이스에서 데이터를 정의하고 조작하기 위한 선언적인 언어이다. 즉, 원하는 데이터가 무엇인지만 선언하면 DBMS가 알아서 최적의 방법으로 질의를 수행한다. SQL에는 데이터 정의어 (DDL), 데이터 조작어 (DML), 데이터 제어어(DCL) 등의 구성요소가 있으며, 이들은 모두 릴레이션에 대한 연산을 표현한다.
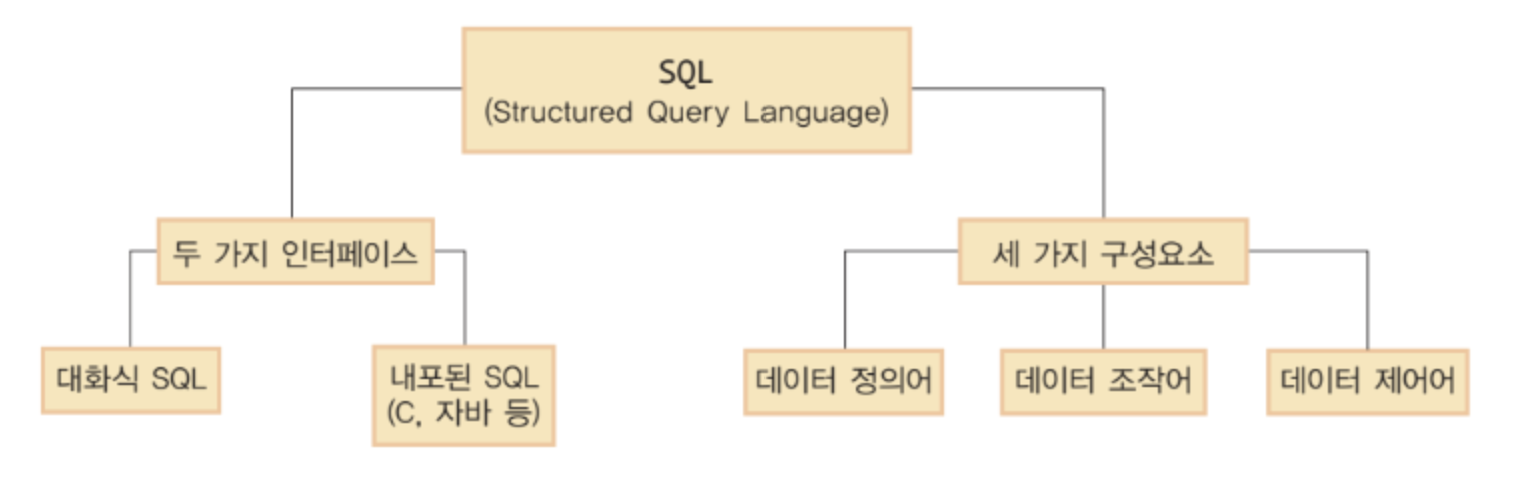
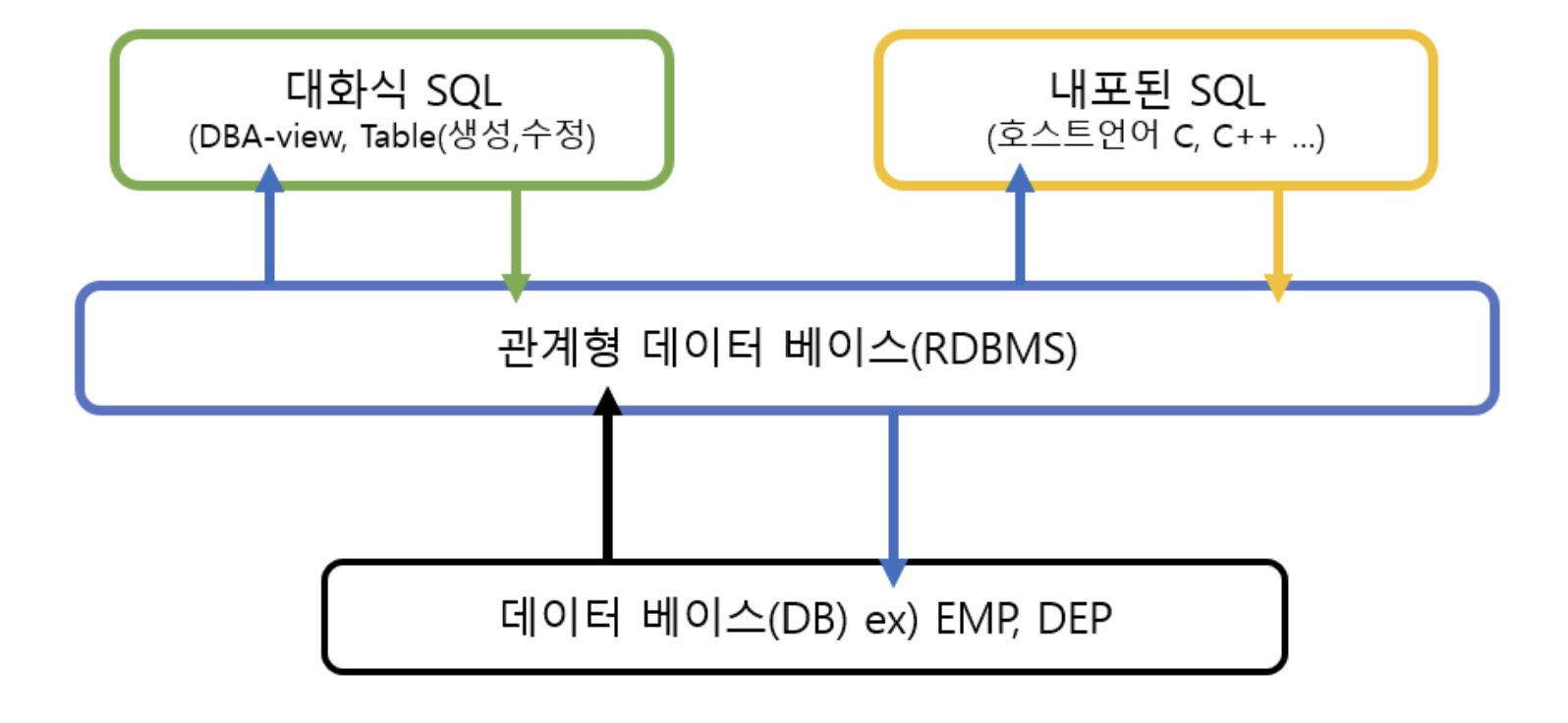
관계 대수와 SQL은 서로 밀접한 관계에 있다고 볼 수 있다. 애초에 관계 대수의 업그레이드 버전이 SQL 이기 때문이다. SQL 은 관계 대수의 한계를 극복하고, 관계 데이터베이스에서 다양한 데이터를 쉽고 강력하게 조작할 수 있도록 해준다. 이주 쉽게 비유하자면, 수학 공식과 같은 관계 대수식을 프로그래밍 언어처럼 구성한게 SQL 이라고 보면된다.
데이터 정의어
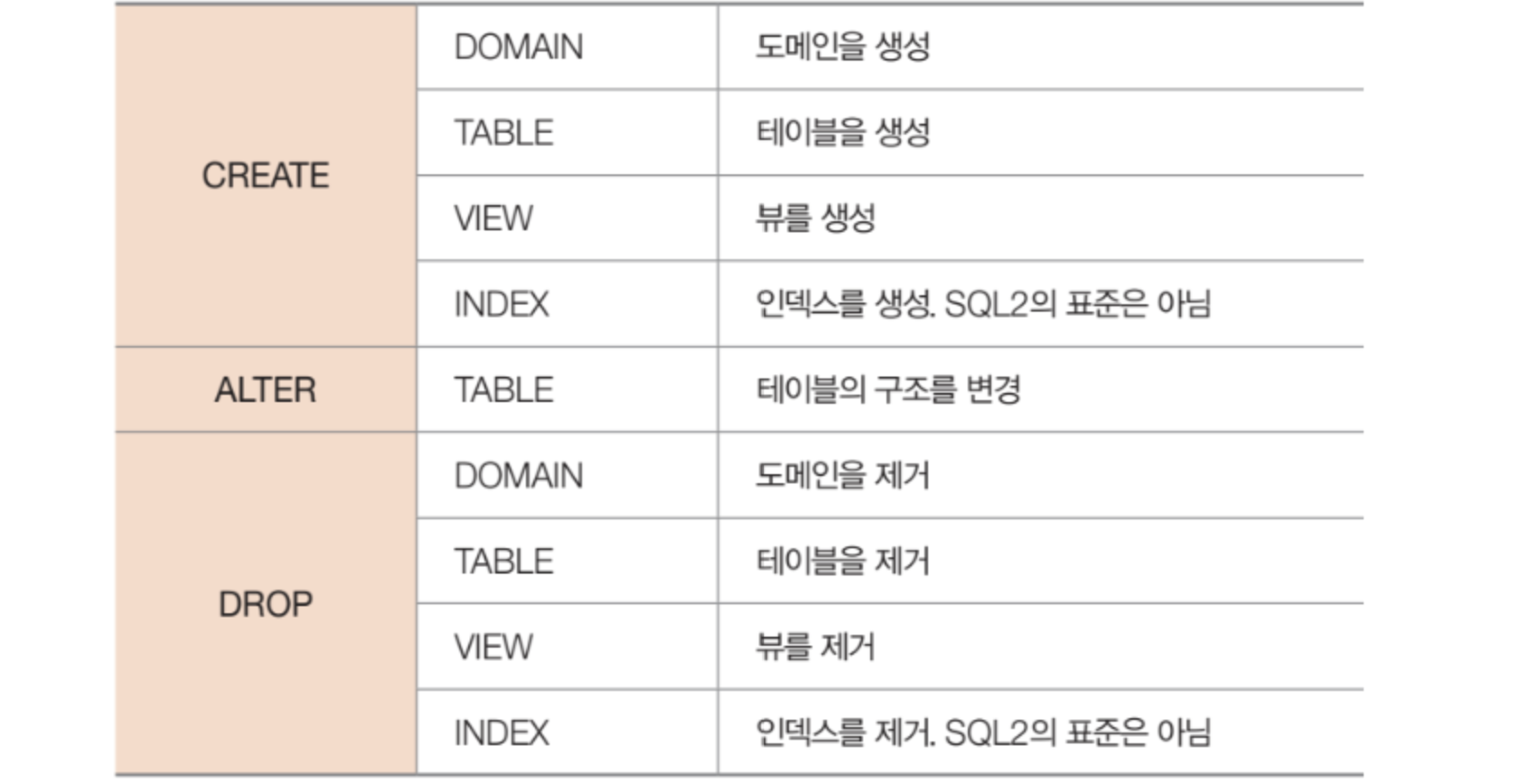
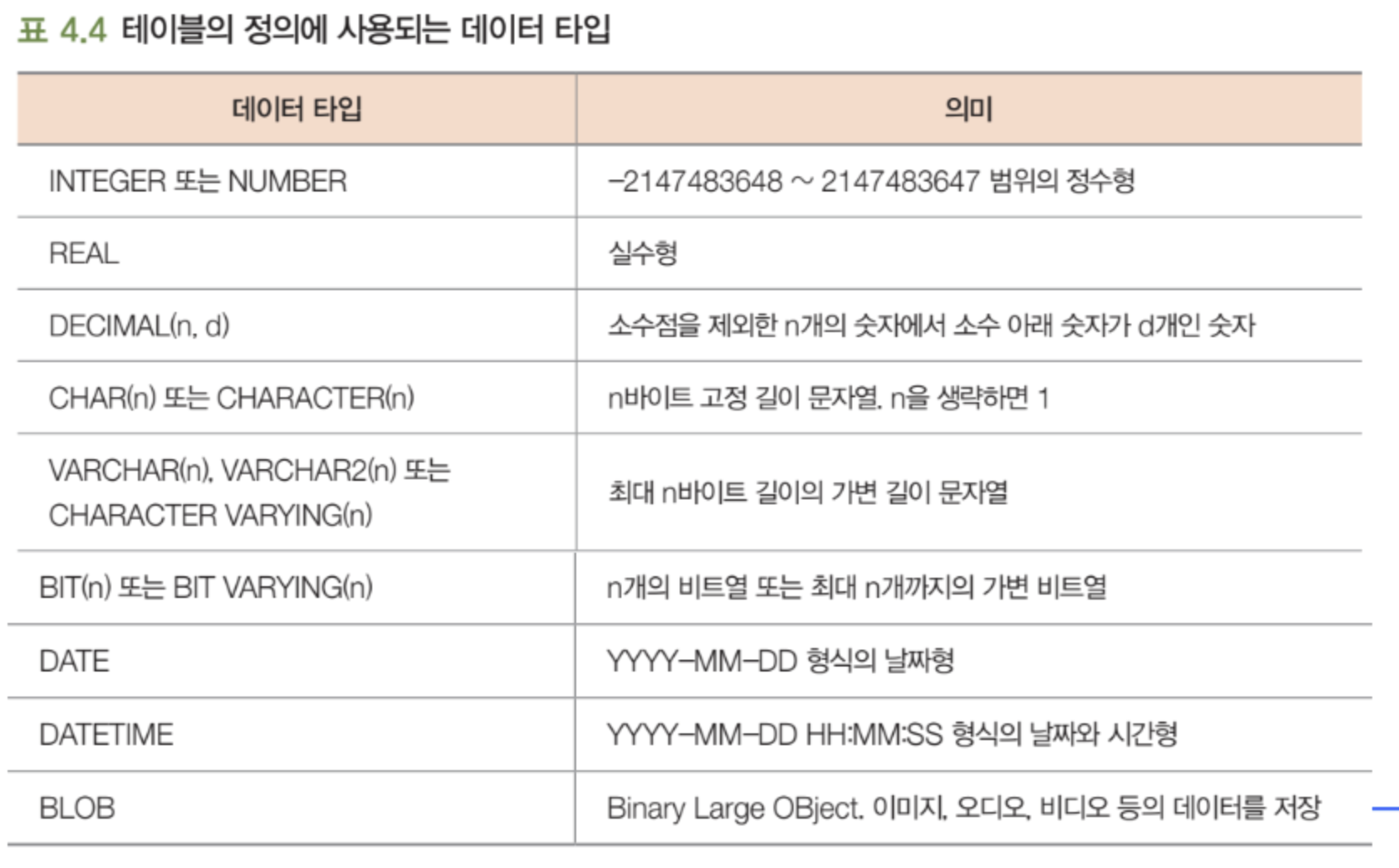
데이터 정의어는 데이터베이스 스키마를 생성하고 제거하는 언어이다. 테이블이 어떠한 애트리뷰트들을 가질 것인지, 기본키는 무엇인지, 외래키는 무엇이며 어떤 테이블을 참조하는지 등을 선언할 수 있다.
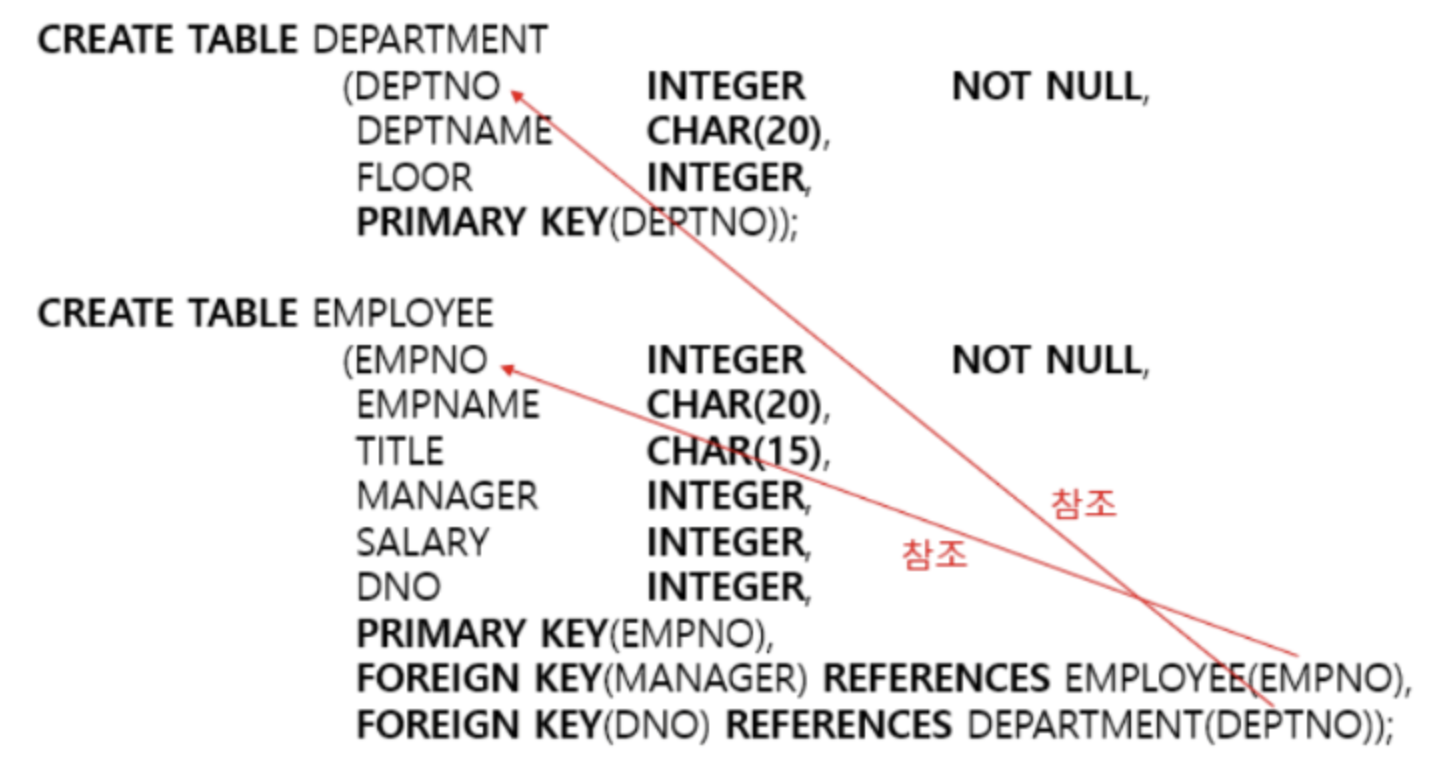
위의 예시는 하나의 테이블을 새로 만드는 과정이다.
DEPTNO INTER라고 하면, 컬럼 이름은 DEPTNO이고 도메인은 INTEGER라는 뜻이다. FOREIGEN KEY (DNO) REFERENCES DEPARTMENT (DEPTNO)는 외래 키는 DNO이며, 참조하는 기본 키는 DEPARTMENT 테이블의 DEPTNO라는 뜻이다.
✅ 테이블 제거
DROP TABLE DEPARMENT;
✅ 테이블 구조 변경
ALTER TABLE EMPLOYEE ADD COLUMN PHONE CHAR (13);
✅ 인덱스 생성
CREATE INDEX EMPNO_IDX ON EMPOLYEE (DNO);
✅ 도메인 생성
CREATE DOMAIN DEPTNAME CHAR (15) DEFAULT '개발';🔸
제약 조건
➡️ NOT NULL
컬럼에 널을 허용하지 않는 경우
➡️ UNIQUE
🔸 어떤 컬럼이 기본 키로 지정되지 않은 후보 키 (대체 키)임을 명시
🔸 해당 컬럼에는 중복되는 값이 들어오면 안됨.
🔸 한 테이블에 기본 키는 한 개만 지정할 수 있지만, UNIQUE는 여러 개 명시 가능
➡️ DEFAULT
컬럼에 특정 값을 디폴트 값으로 지정
➡️ CHECK
컬럼이 가질 수 있는 값들의 범위를 지정

➡️ 기본 키 제약조건
🔸 테이블의 기본 키를 명시
🔸 각 테이블마다 최대한 한 개의 기본 키를 지정할 수 있음
🔸 기본 키에는 자동적으로 인덱스가 생성됨
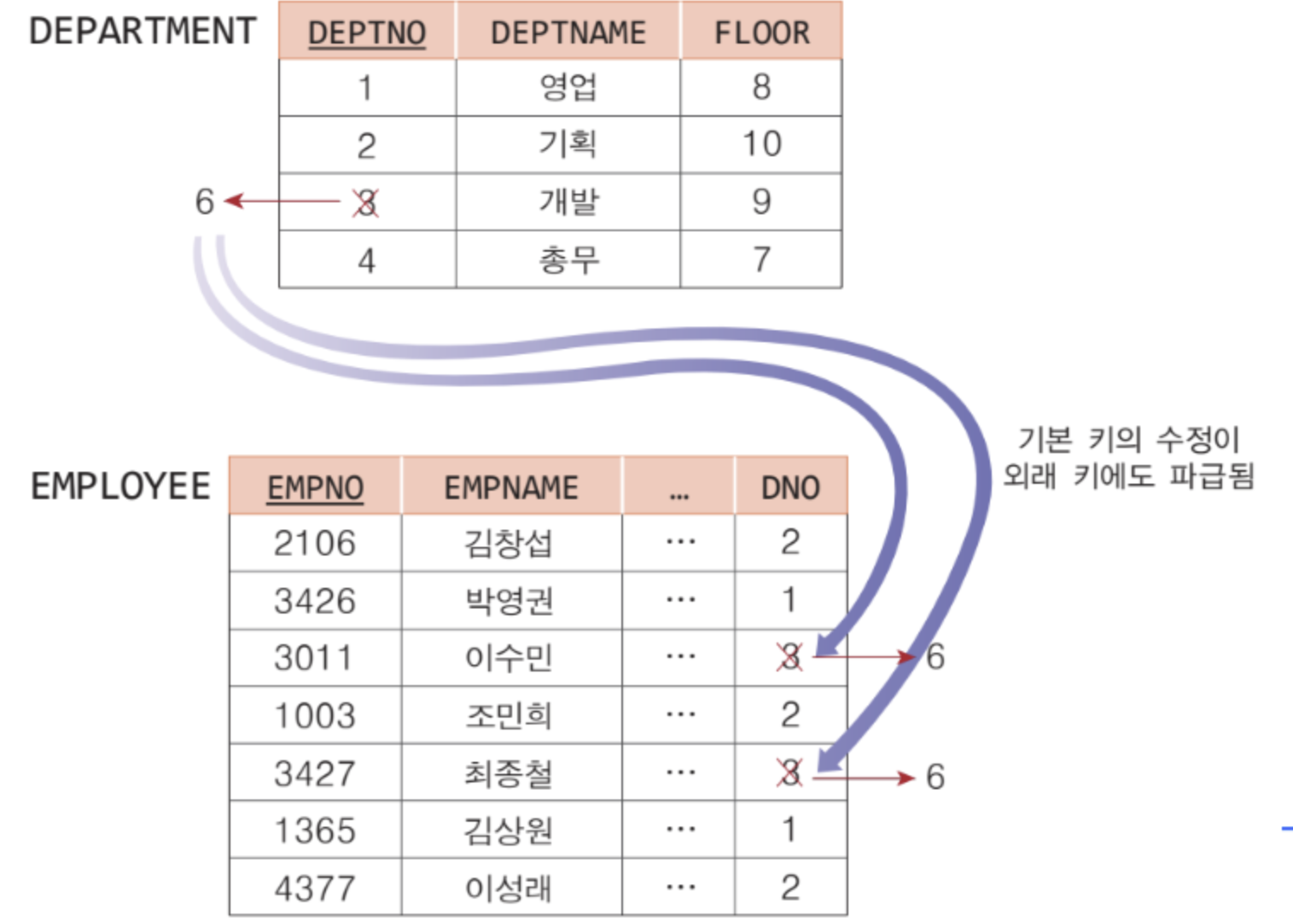
➡️ 참조 무결성 제약조건
🔸 외래 키를 구성하는 컬럼, 참조되는 테이블과 기본 키를 명시
참조 무결성 제약조건에서 참조되는 컬럼은 참조되는 테이블에서 동일한 데이터 타입을 가지면서 기본 키로 정의되어 있어야 함.


➡️ 무결성 제약조건의 추가 및 삭제
ALTER TABLE STUDENT ADD CONSTRAINT SRUDENT_PK PRINARY EKY (STNO);
ADD CONSTRAINT : 제약조건 추가
STUDENT_PK : 제약조건 이름
PRIMERY KEY (STNO) : STNO를 기본 키로 지정
ALTER TABLE STUDENT DROP CONSTRAINT STUDENT_PK;
SELECT 문
✅ 관계 데이터베이스에서 정보를 검색하는 SQL문
✅ 관계 대수의 셀렉션과 의미가 완전히 다름
✅ 관계 대수의 셀렉션, 프로젝션, 조인, 카디션 곱 등을 결합한 것
🟨 기본적인 구조
🔸 SELECT-FROM-WHERE 블록
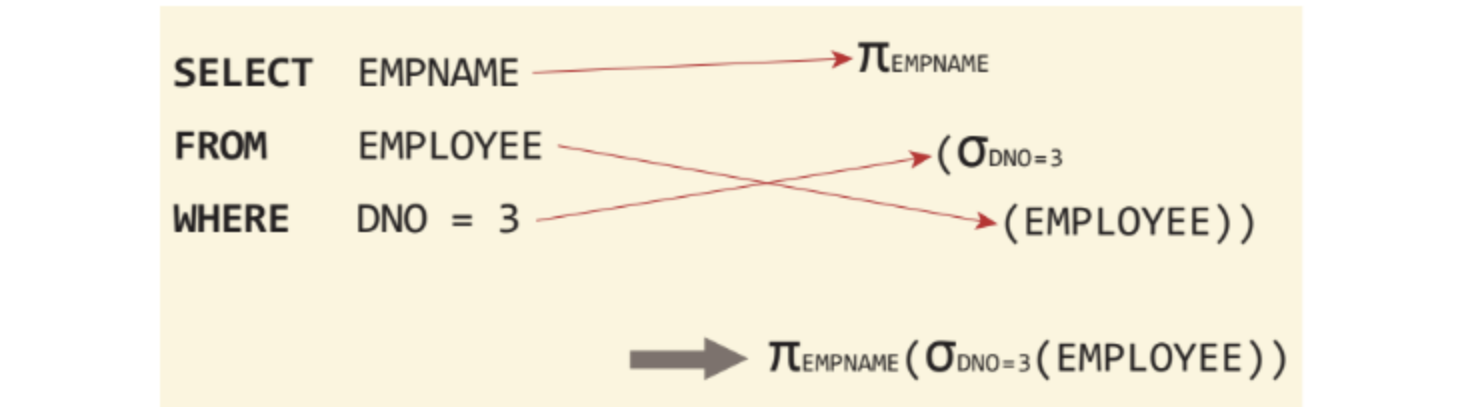
- FROM 절에 명시된 테이블에서
- WHERE 절의 프레디키트를 적용하여 만족하는 튜플들을 골라내어 ()
- SELECT 절에 열거된 컬럼들만 해서 결과로 반환

SELECT 이름, 학년
FROM 학생
WHERE 학과 = '컴퓨터'
✅ SELECT 문에서 SELECT 절과 FROM 절만 필수적이고, 나머지는 선택사항

➡️ SELECT 절
🔸 질의 결과에 포함하려는 컬럼들의 리스트를 열거
🔸 관계 대수의 프로젝션 연산에 해당
🔸 사용자가 DISTINCT 절을 사용해서 명시적으로 요청했을 때만 중복을 제거
SQL에서는 기본적으로 중복을 포함해서 결과를 반환한다!
➡️ FROM 절
🔸 질의에서 필요로 하는 테이블들의 리스트를 열거
➡️ WHERE 절
🔸 관계 대수의 셀렉션 연산의 셀렉션 조건 (프레디키트)에 해당
🔸 FROM 절에 열거한 테이블에 속하는 컬럼들만 사용해서 조건을 표현해야 함

➡️ 중첩된 질의
🔸 다른 질의의 WHERE 절에 포함된 SELECT 문
➡️ GROUP BY
🔸 GROUP BY에 명시된 컬럼에서 동일한 값을 갖는 튜플들을 그룹으로 묶음
➡️ HAVING
🔸 튜플들의 그룹이 만족해야 하는 조건
➡️ ORDER BY
🔸 결과 튜플들의 정렬 순서를 명시
🟨 별칭 (Alias)
서로 다른 테이블에 동일한 이름을 가진 컬럼이 속해 있을 때 컬럼의 이름을 구분하는 방법

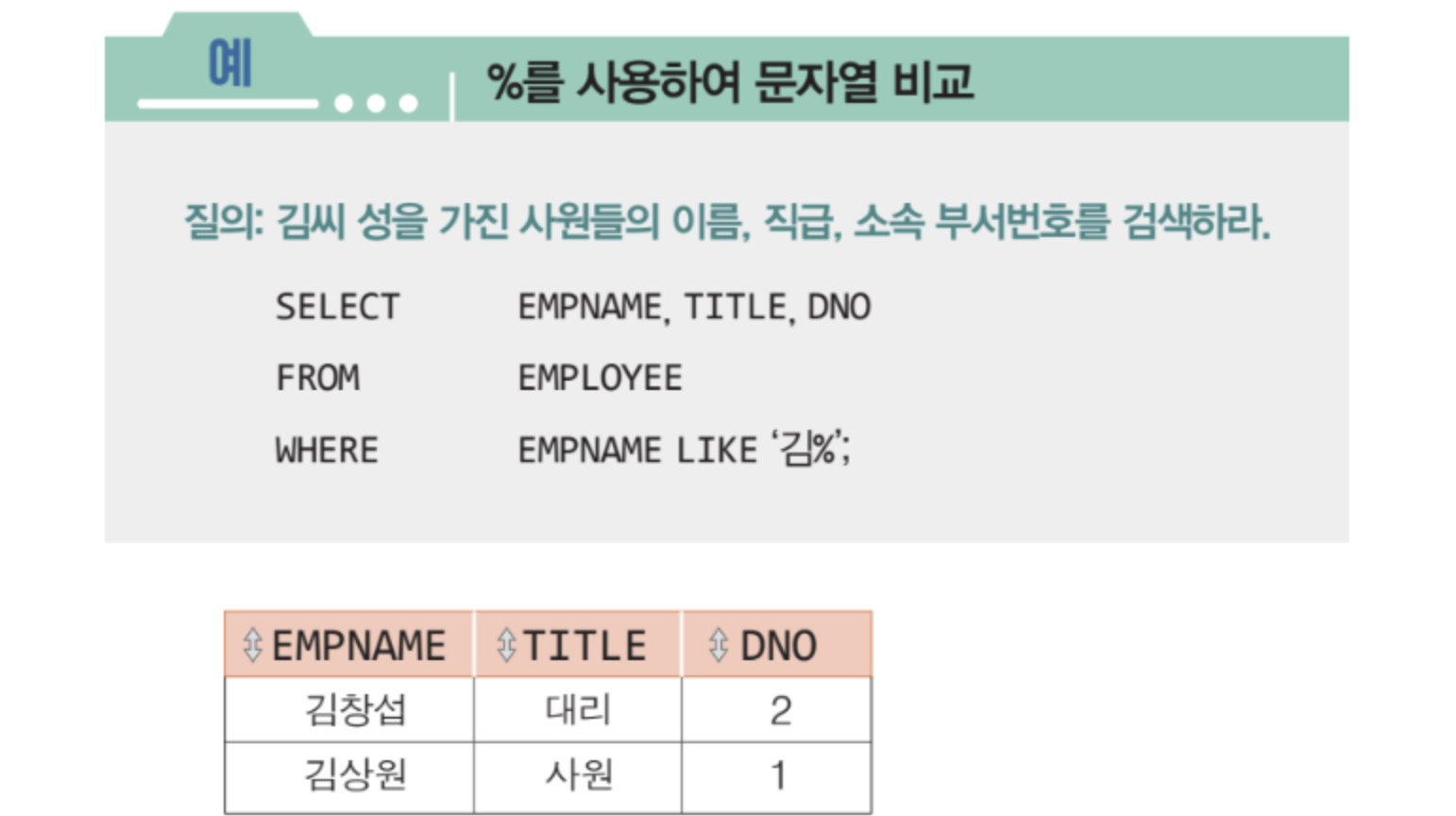
🟨 LIKE 연산자
문자열을 비교하는 연산자이다.
% : 0 ~
_ : 1 char
김% : 성이 김씨인 모든 이름
김_ : 성이 김씨인 외자 이름
김__ : 성이 김씨인 세글자 이름
like는 위의 연산자들과 함께 사용할 수 있다.

SELECT CUSTNAMR
FROM CUSTOMER
WHERE ADDRESS LIKE '% 동대문구 %';

days = {SR, RT STRING, R, %R%, RR, RTR}
(1) : SR, RT, STRING, R, %R%, RR, RTR -> 모두 출력
(2) : SR, RR
(3) : R
(4) : %R%
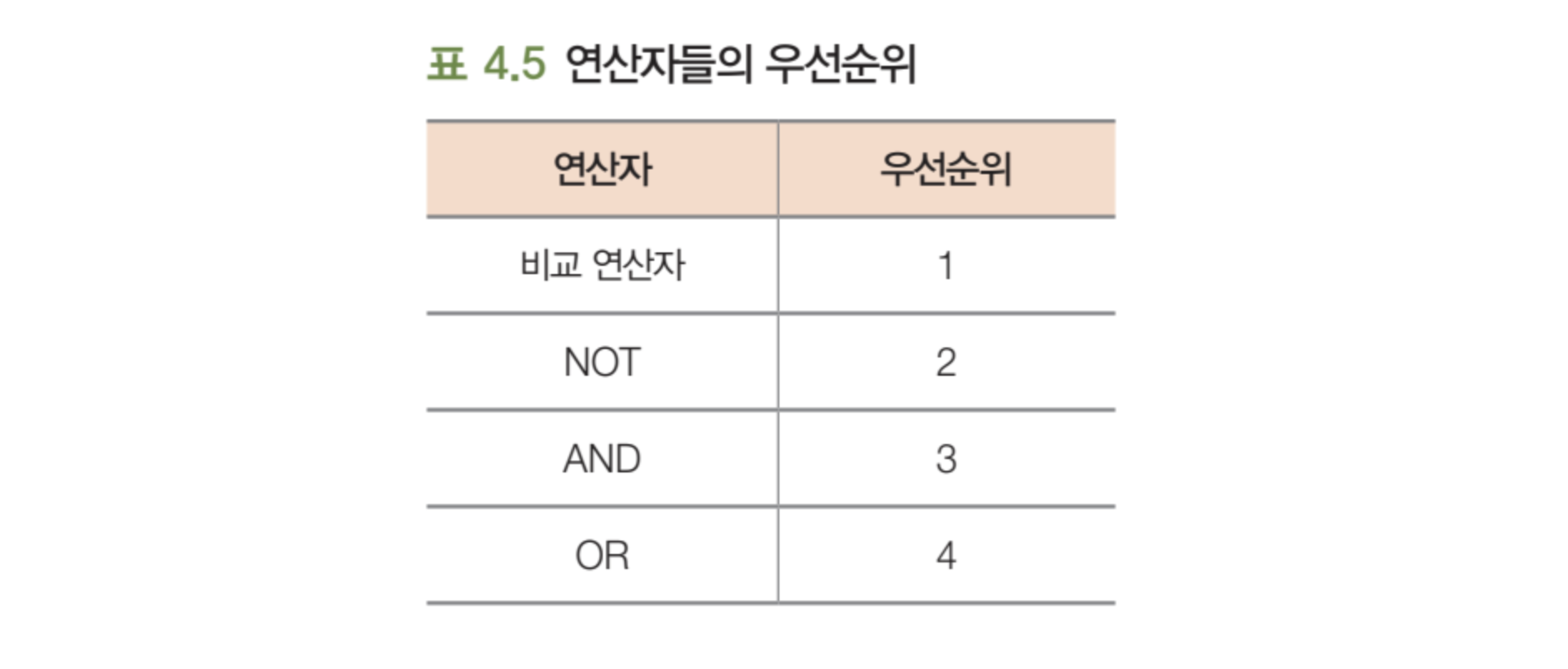

SQL에서는 != 대신 <> 를 사용한다.
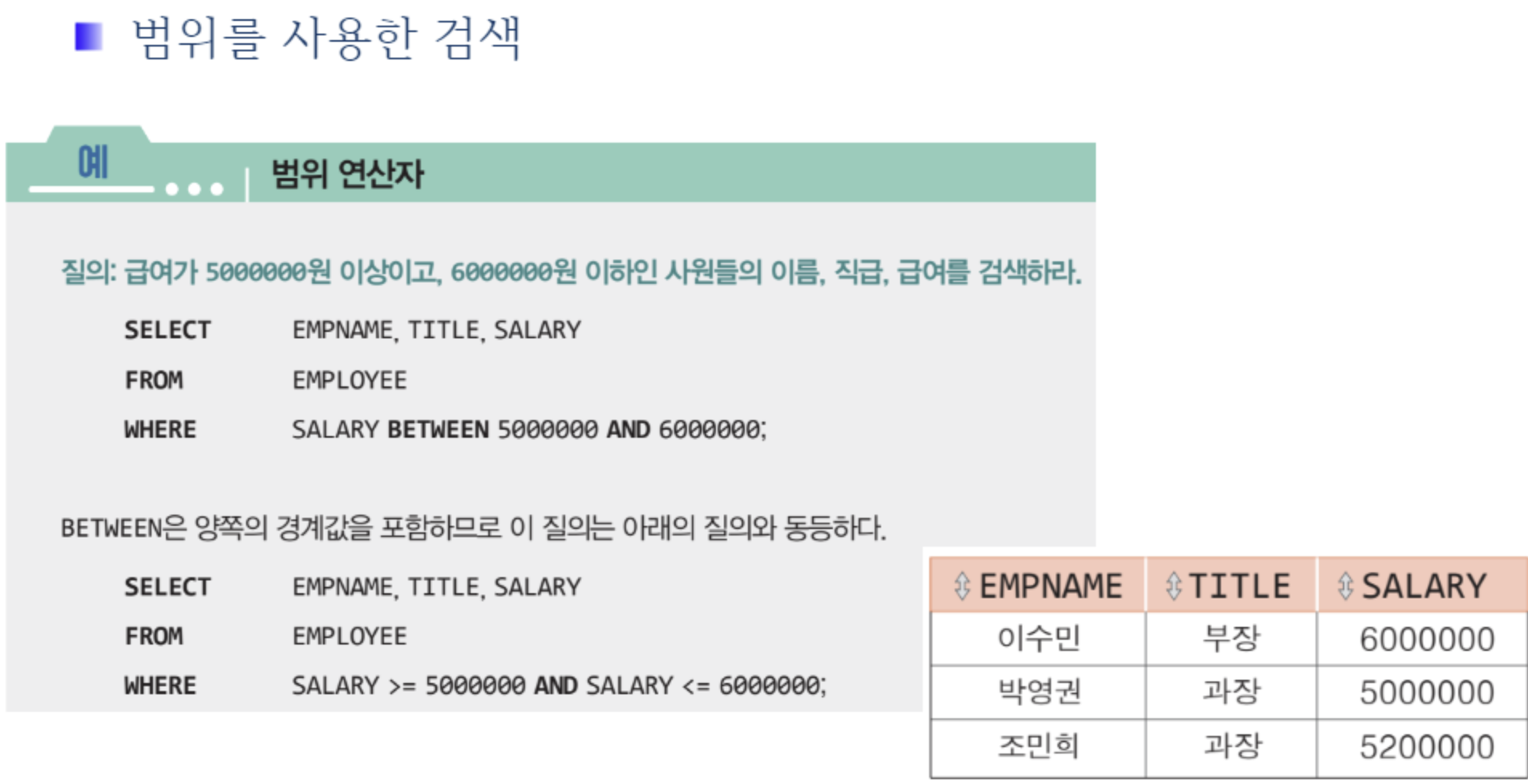
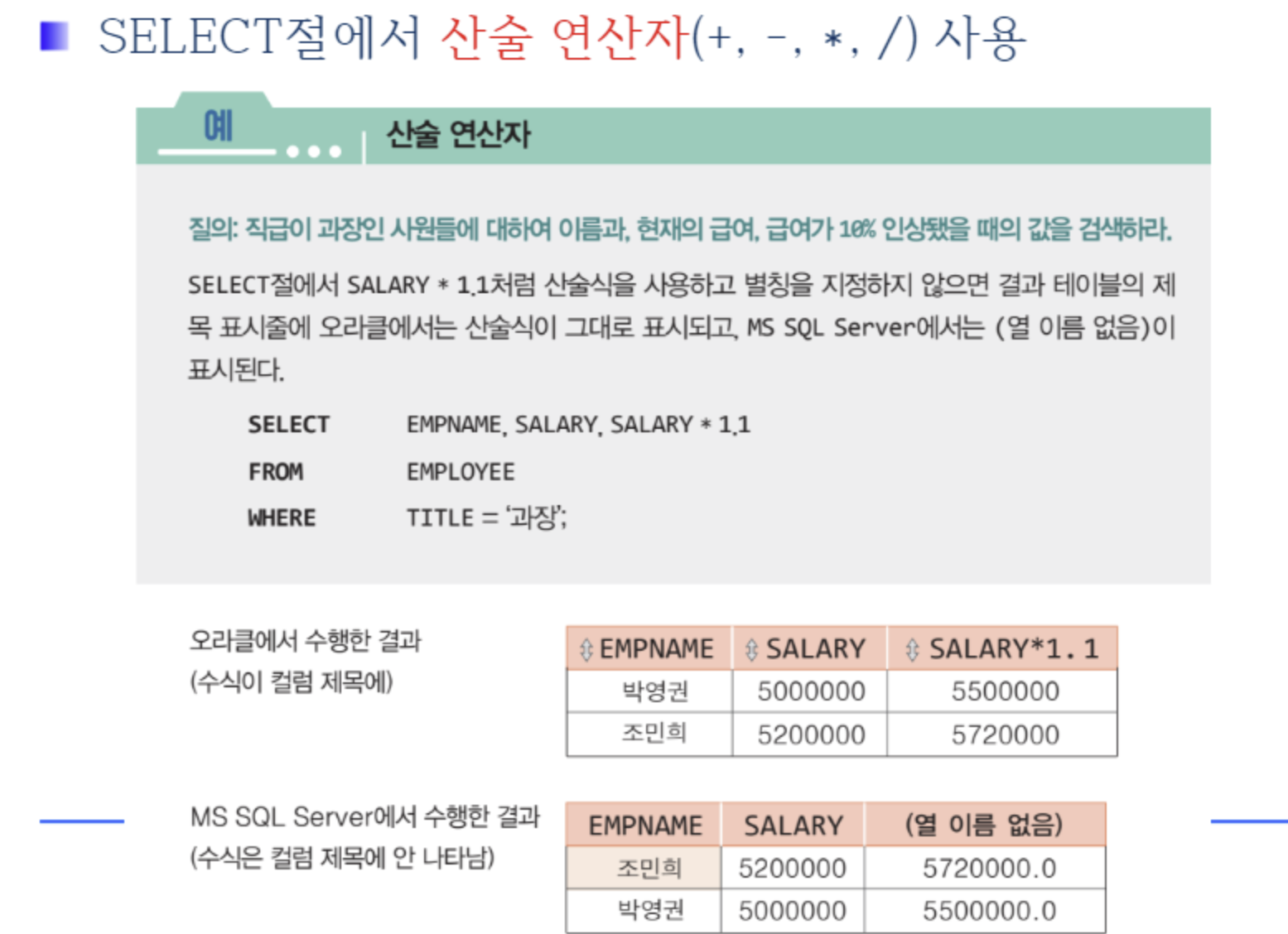
🟨 NULL
🔸 null을 포함한 다른 값과 null을 산술 연산하면 결과는 null이다
🔸 COUNT ( * ) 를 제외한 집단 함수들은 null을 무시함
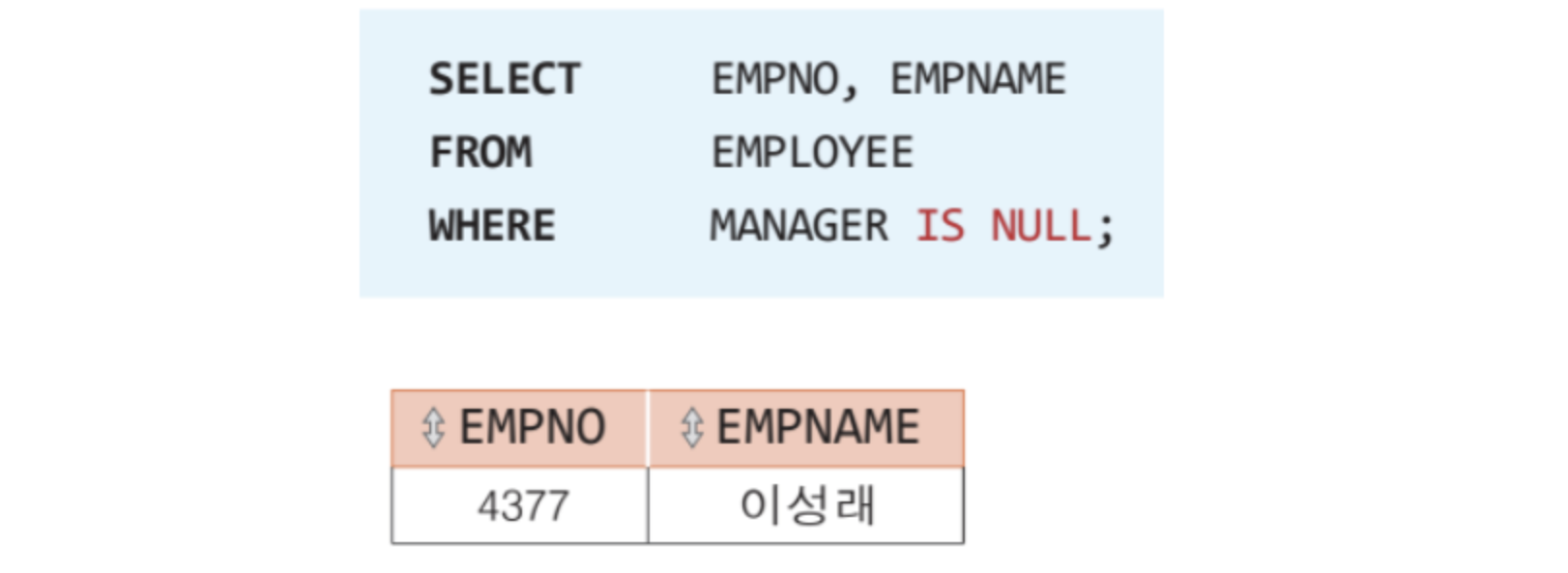
어떤 컬럼에 들어 있는 값이 null인가 비교하기 위해서
'DNO=NULL' 처럼 나타내면 안된다

null과 비교하기 위해서는 IS 연산자를 사용해야 한다.
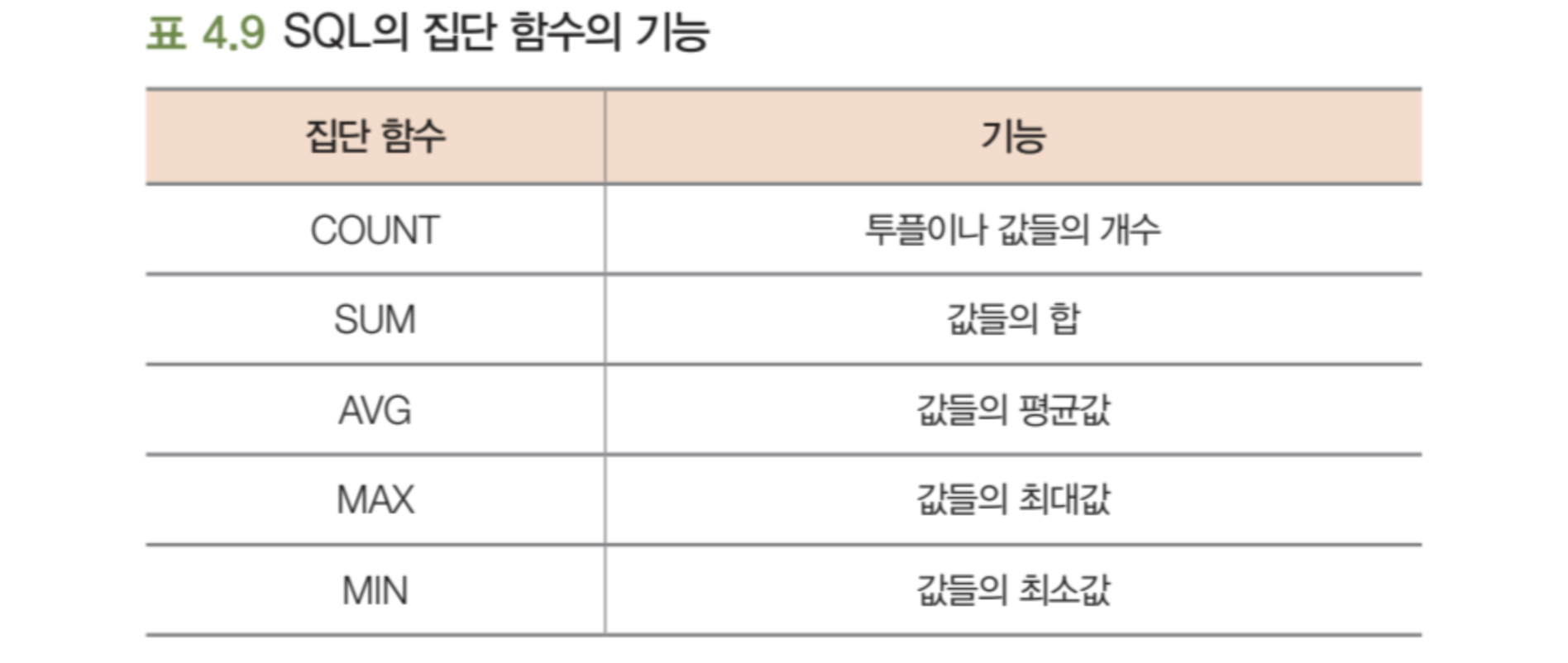
집단 함수
🔸 데이터베이스에서 검색된 여러 튜플들의 집단에 적용되는 함수
🔸 COUNT ( * ) 를 제외하고, 한 테이블의 한 개의 컬럼에 적용되어 단일값을 반환함
🔸 SELECT 와 HAVING 에만 나타날 수 있음
🔸 COUNT ( * ) 를 제외하고는 null을 제거한 후 남아 있는 값들에 대해서 집단 함수 적용
🔸 DISTINCT가 집단 함수 앞에 사용되면 집단 함수가 적용되기 전에 중복을 먼저 제거
질의 : 모든 사원의 평균 급여와 최대 급여를 검색해라
SELECT AVG(SALARY) AS AVGSAL, MAX(SALARY) AS MAXSAL
FROM EMPLOYEE;

COUNT

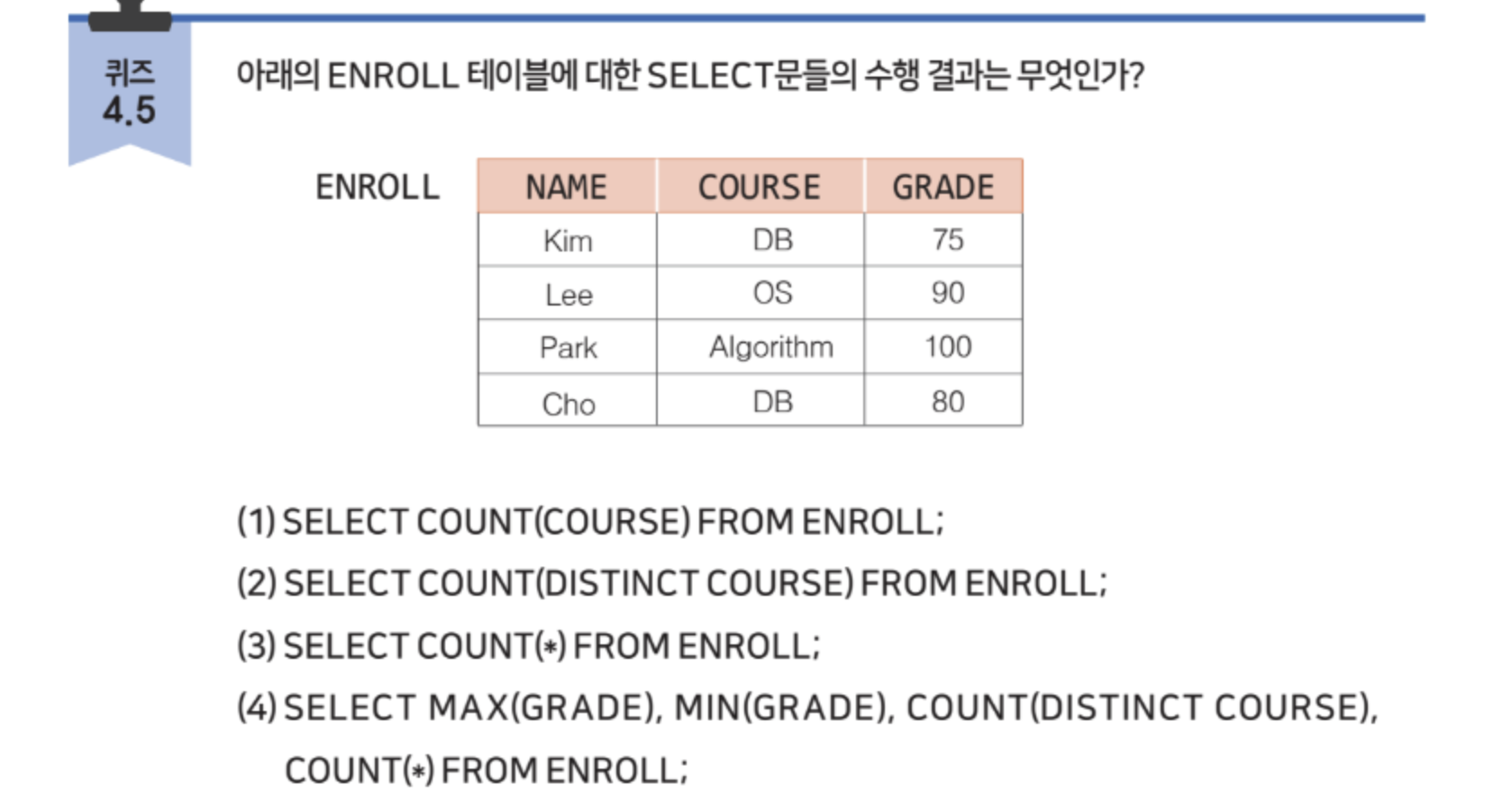
(1) : 4
(2) : 3
(3) : 4
(4) : 100, 75, 3, 4
그룹화
✅ GROUP BY에 명시된 컬럼들 중 동일한 값을 갖는 튜플들이 각각 하나의 그룹으로 묶임
✅ 이 컬럼들을 그룹화 컬럼 (grouping column)이라고 함
✅ 그룹화를 했을 때는 SELECT 절에는 그룹화에 사용된 컬럼, 각 그룹마다 하나의 값을 갖는 컬럼, 집단 함수만 나타날 수 있음
하나의 그룹이 두 개 이상의 값을 가지면 에러 발생

부서 번호로 그룹화를 하였는데 모든 사원의 번호를 출력하려고 하니 에러가 발생하는 것이다. 따라서 해당 구문이 올바르게 수행될 수 있도록 하려면,
SELECT DNO, AVG(SALARY)
FROM EMPLOYEE
GROUP BY DNO;
로 수정해야 한다. 이렇게 되면 부서 별 평균 급여를 출력할 수 있다.

HAVING
✅ 그룹화 컬럼에 같은 값을 갖는 투플들의 그룹에 대한 조건을 나타내고, 이 조건을 만족하는 그룹들만 질의 결과에 나타남
✅ HAVING 절에 나타나는 컬럼은 반드시 GROUP BY 절에 나타나거나 집단 함수에 포함되어야 함

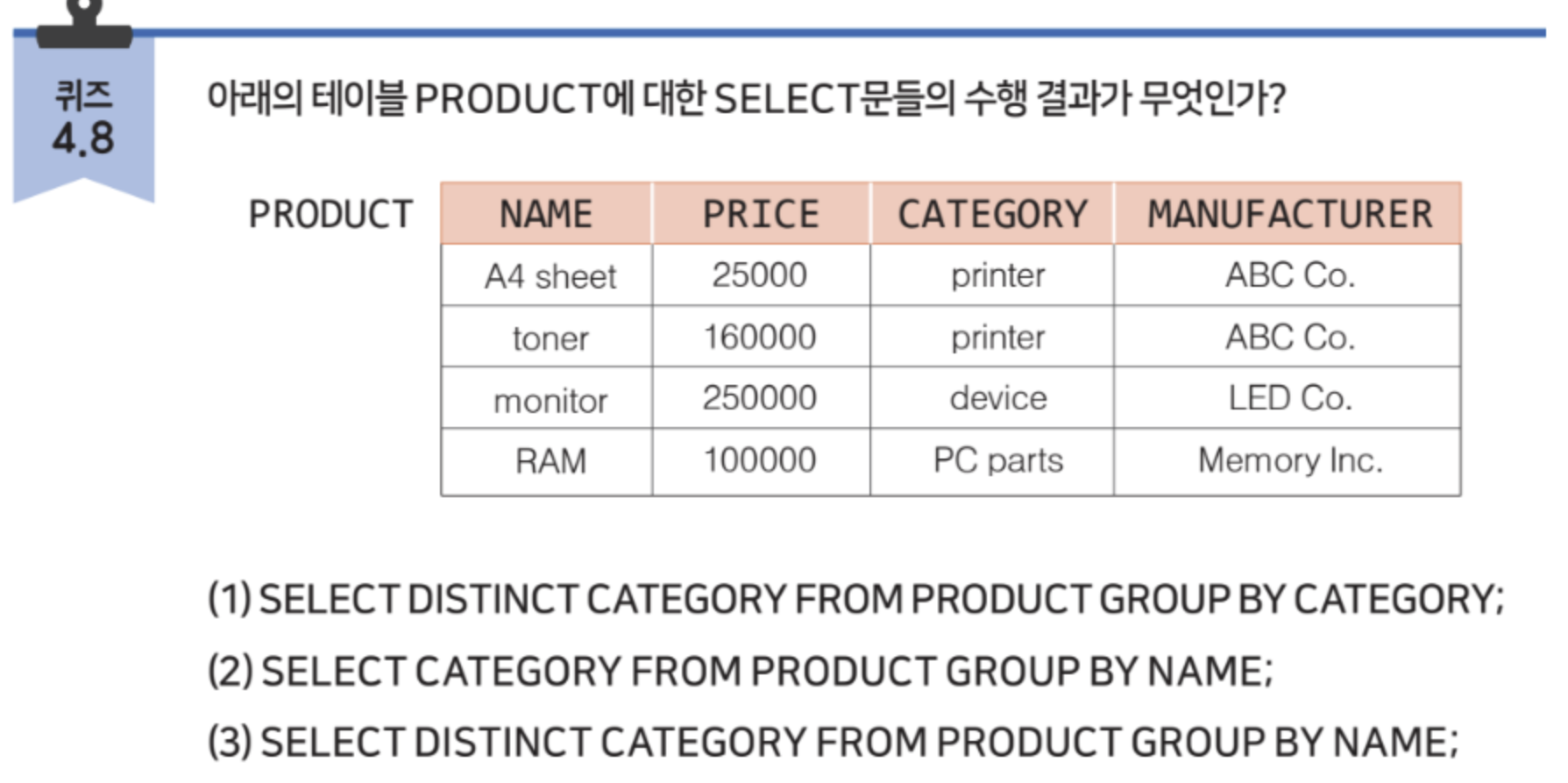
(1) : printer, device, PC parts
(2) : printer, printer, device, PC parts
(3) : printer, printer, device, PC parts
NAME으로 그룹화를 하였을 때,
A4 sheet - printer
toner - printer
moniter - device
RAM - PC parts 로 묶이게 된다.
이때, 두 개의 printer는 각각 다른 NAME과 매칭되어 있으므로 서로 다른 카테고리라고 인식되고, DISTINCT를 명시해도 제거되지 않는다.
SELECT NAME FROM PRODUCT GROUP BY CATEGORY;
-> 에러 발생 : 카테고리로 그룹화하였을 때, printer가 두 개의 값을 가지기 때문
ORDER BY
✅ 사용자가 SELECT 문에서 질의 결과의 순서를 명시하지 않으면 DBMS에 따라 결과가 나타나는 순서가 다름
✅ ORDER BY에서 하나 이상의 컬럼을 사용하여 검색 결과를 정렬할 수 있음
✅ 디폴트 정렬 순서는 오름차순 (ASC)
✅ DESC를 지정하여 정렬 순서를 내림차순으로 지정할 수 있음
null은 오름차순에서는 가장 마지막에 나타나고, 내림차순에서는 가장 앞에 나타남. 가장 큰 값으로 간주한다고 생각하면 편하다!
