관계 데이터 모델에는 두 가지의 정형적인 언어가 지원된다.
-
관계 해석
: 원하는 데이터만 명시하고 질의를 어떻게 수행할 것인가는 명시하지 않는 선언적인 언어이다. 흔히 말하는 비절차적 언어로서, 컴퓨터가 직접 실행할 수 있는 형태는 아니다. 따라서 관계 해석으로 표현된 질의를 관계 대수나 SQL로 변환하는 추가적인 작업이 필요하다. -
관계 대수
: 각각의 관계 연산자들이 수행되는 순서를 명시하는 절차적 언어이다. 우리가 관계 데이터베이스에서 사용하는 SQL의 이론적인 기초가 바로 관계 대수이다. 따라서 관계 DBMS는 SQL 질의를 DBMS 내부에서 관계 대수식으로 변환한 후 이를 바탕으로 최적의 질의 수행을 찾는다.
관계 대수
관계 대수 연산을 통해 기존의 릴레이션들로부터 새로운 릴레이션을 생성한다. 관계 대수식에 다른 연산자들을 적용하여 보다 복잡한 관계 대수식을 점차적으로 만드는 것이 가능하다. 따라서 관계 대수 연산 과정에서 생성된 중간 결과 릴레이션은 또 다른 관계 대수 연산자의 입력으로 사용되는 것이 가능하다.
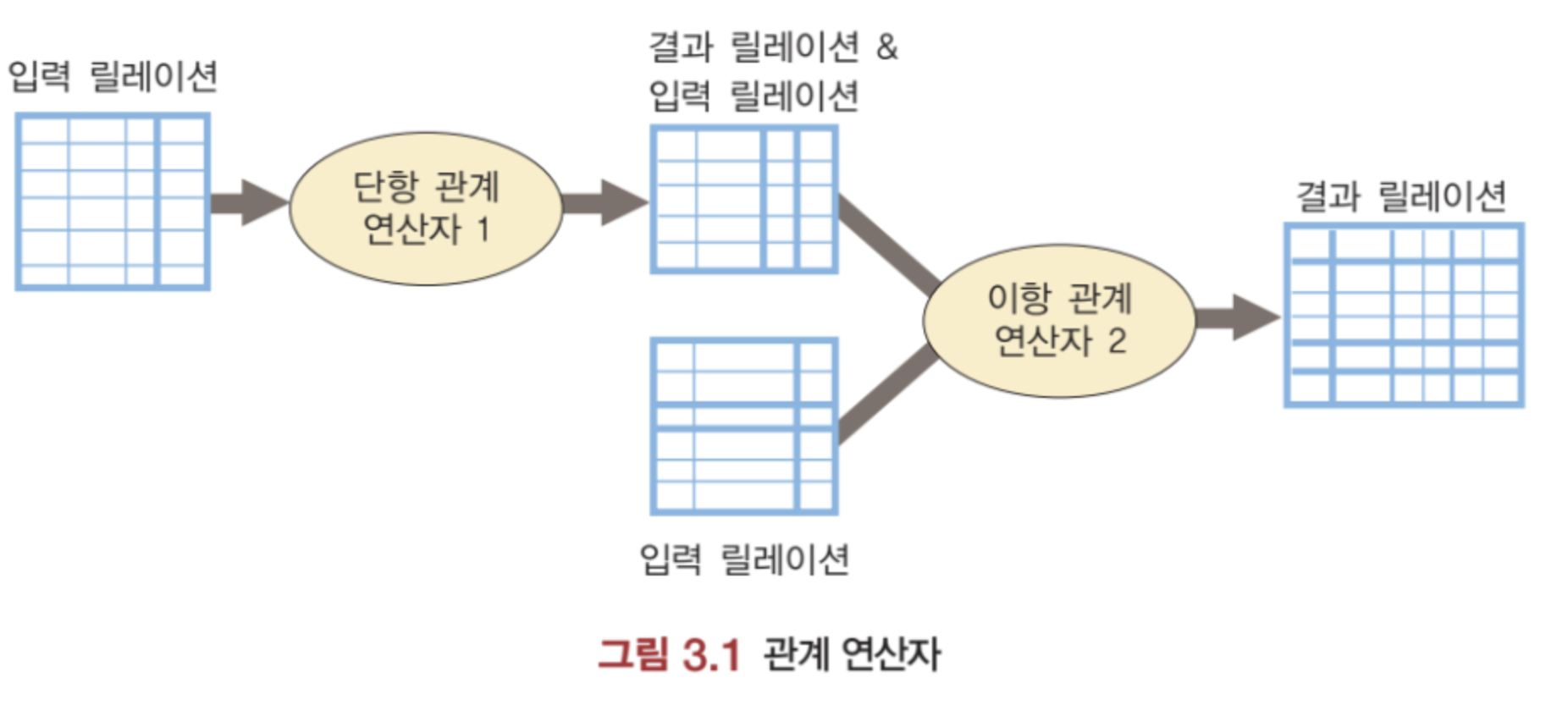
관계 대수의 8대 연산자
8대 관계 연산자란, 관계형 데이터베이스에서 자주 사용되는 8가지 기본적인 연산자들을 의미한다. 이러한 연산자들은 데이터베이스의 기초적인 연산들이며, 관계형 데이터베이스에서 매우 중요한 개념이다. 관계 연산자들을 잘 이용하고 사용함으로써, 데이터베이스의 질의를 보다 효율적으로 수행할 수 있기 때문이다.
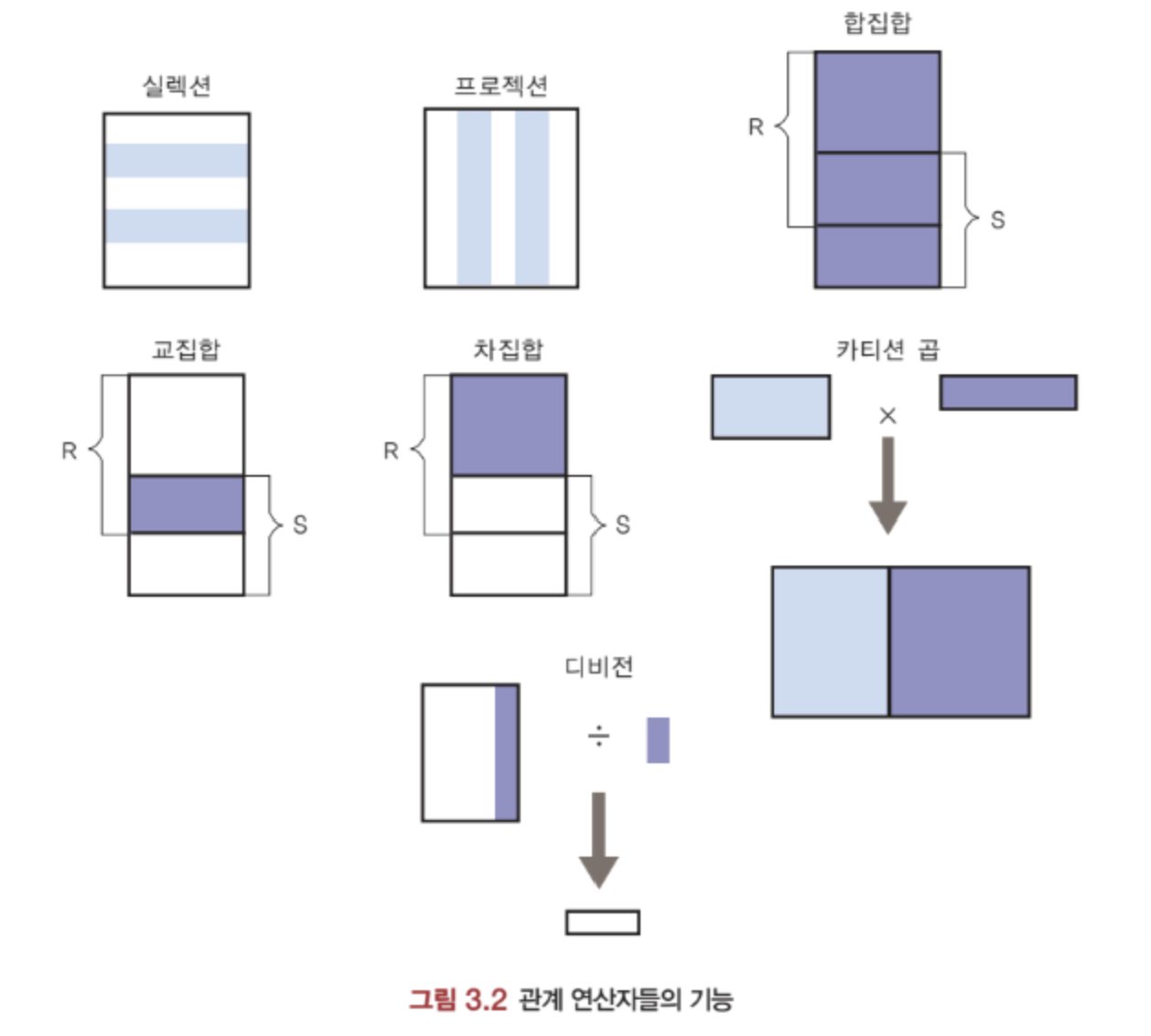
🟨 셀렉션 : 테이블에서 한 개 끄집어낸다
🟨 프로젝션 : 학생 테이블에서 특정한 학번, 이름만 출력
🟨 합집합 : union. 중복되는 것을 제외하고 테이블을 합친다
🟨 교집합 : 겹치는 것만 테이블로 생성
🟨 차집합 : A - B 결과 테이블
🟨 카티션 곱 : 나올 수 있는 모든 조합의 경우의 수
🟨 조인 : 결합
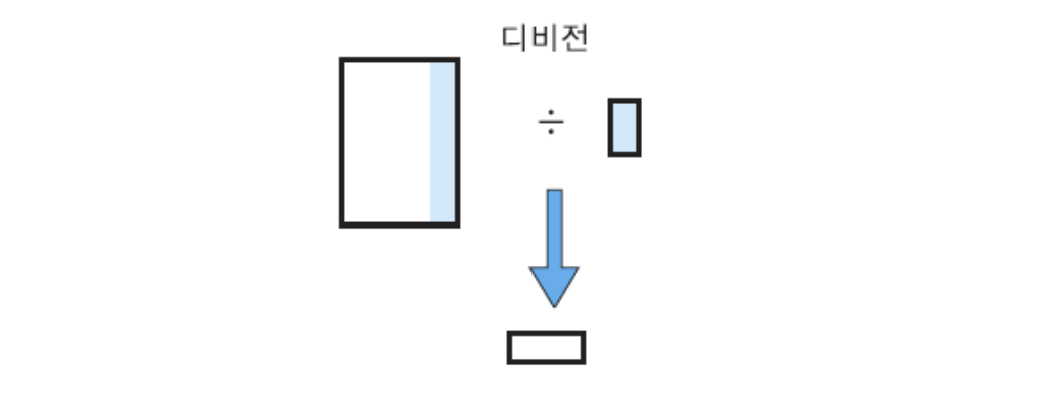
🟨 디비전 : 분할
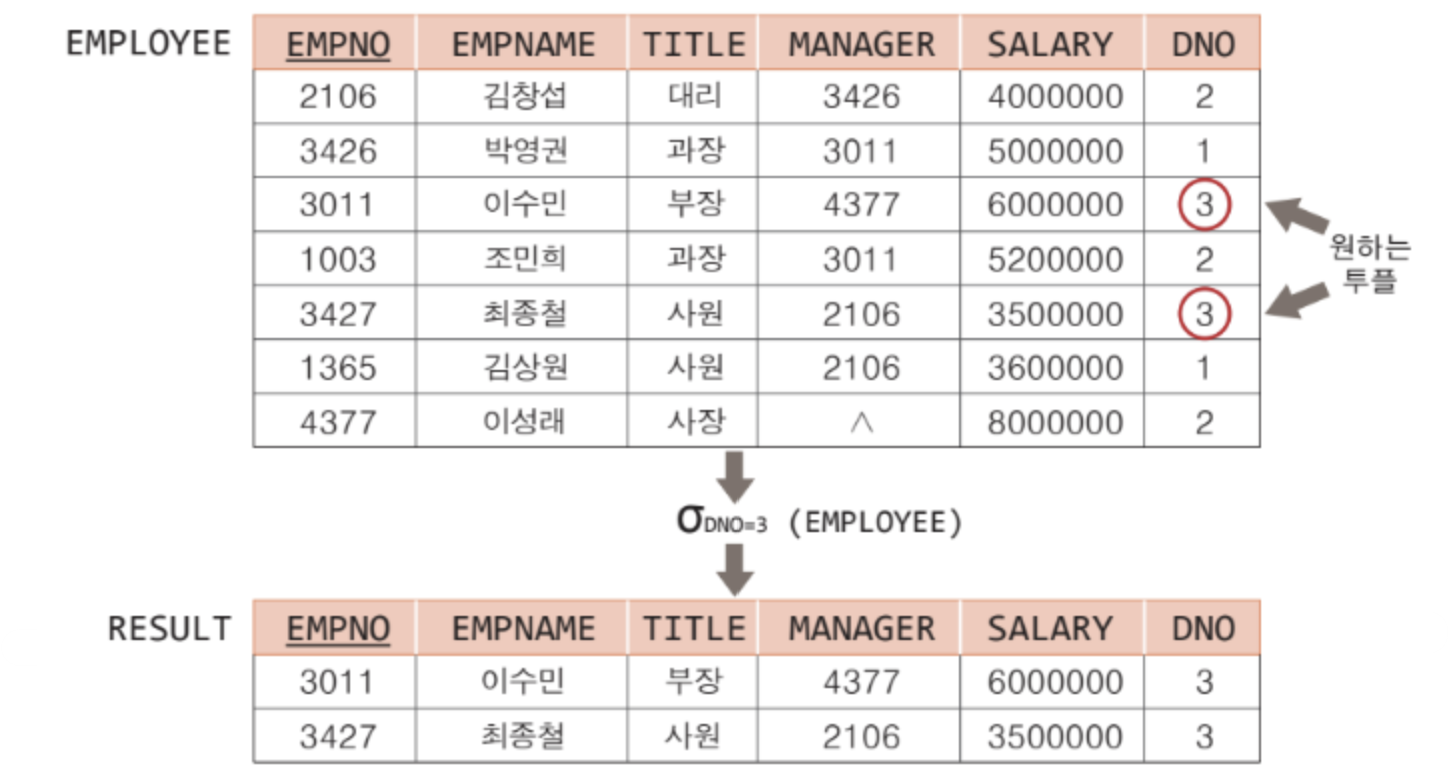
셀렉션 연산자

✅ 원하는 조건을 만족하는 튜플을 도출함
✅ (sigma) 로 연산자를 표현
✅ 셀렉션 조건을 predicate 라고 함
(EMPLOYEE) : EMPLOYEE 테이블에서 DNO가 3인 투플을 도출
프로젝션 연산자
✅ 원하는 조건을 만족하는 애트리뷰트들을 도출함
✅ 로 연산자를 표현
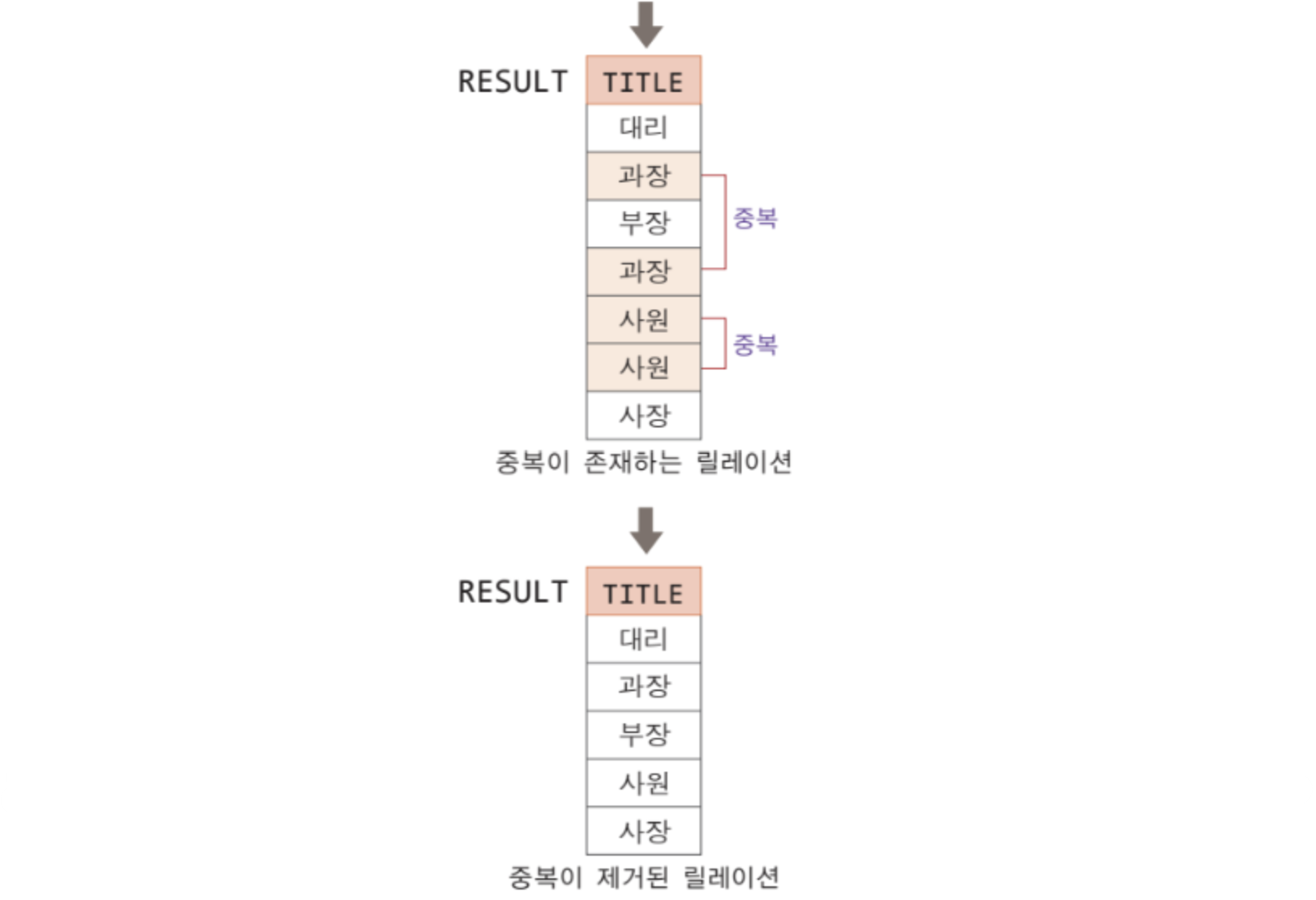
✅ 중복되는 값들은 제거
보통 셀렉션의 결과 릴레이션에는 중복되는 값이 애초에 존재할 수 없음.
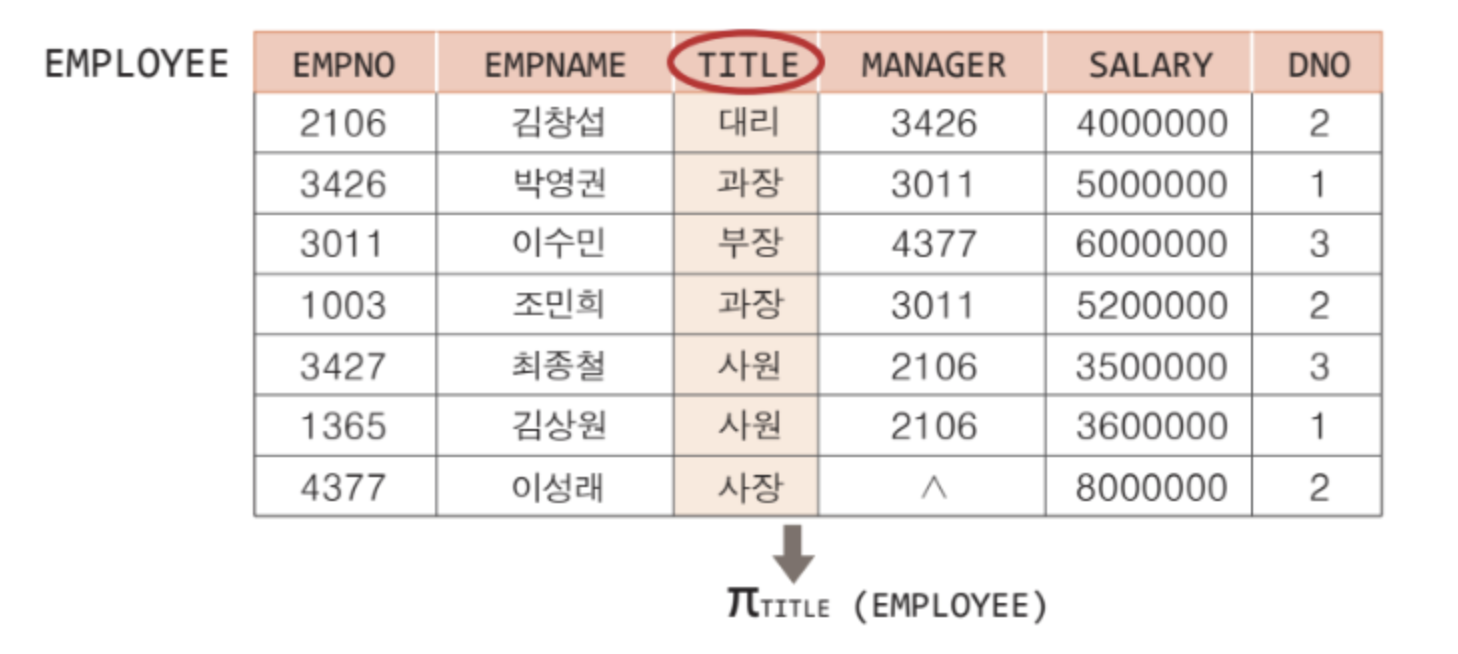
(EMPLOYEE) : EMPLOYEE 테이블에서 TITLE 컬럼 도출
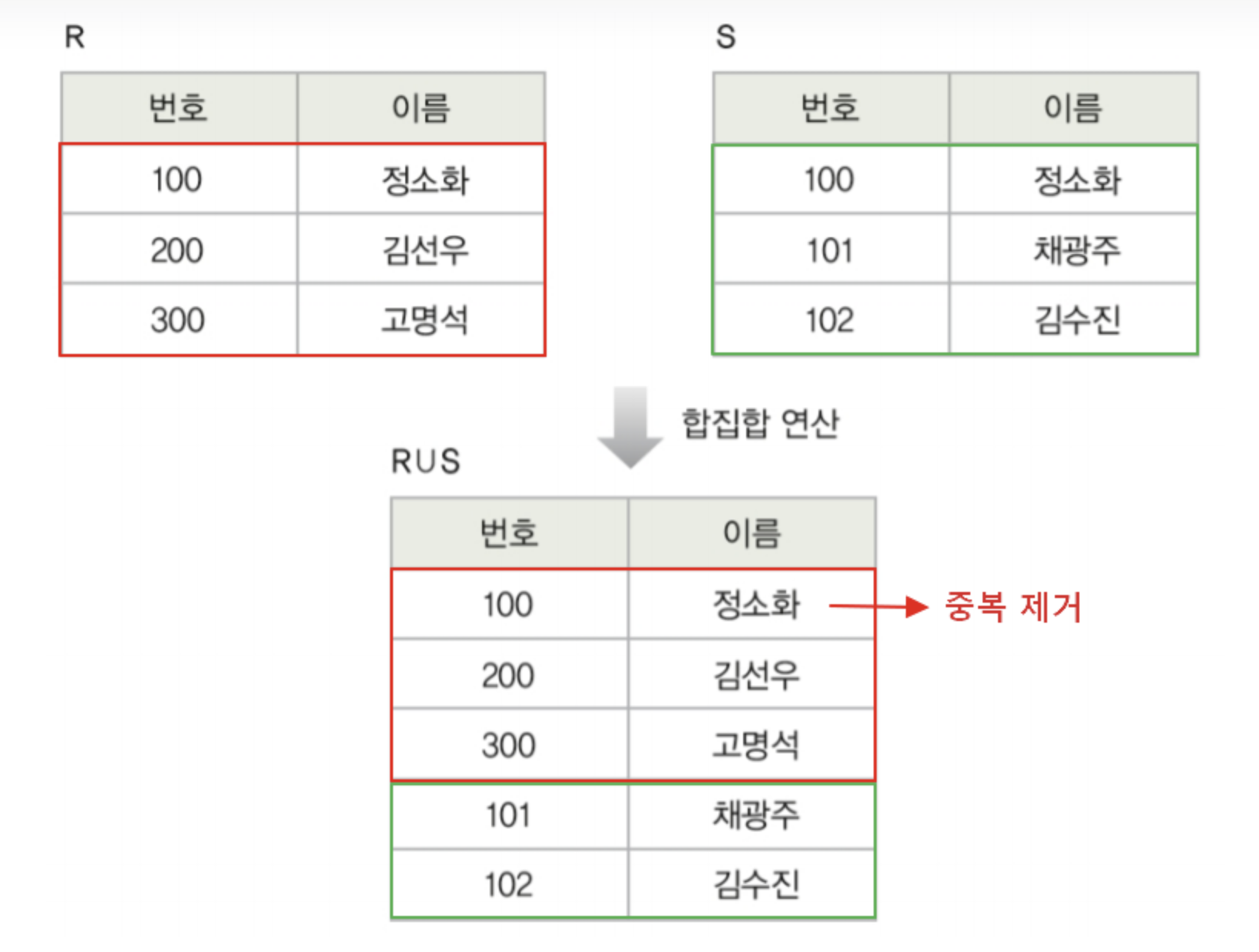
합집합 연산자
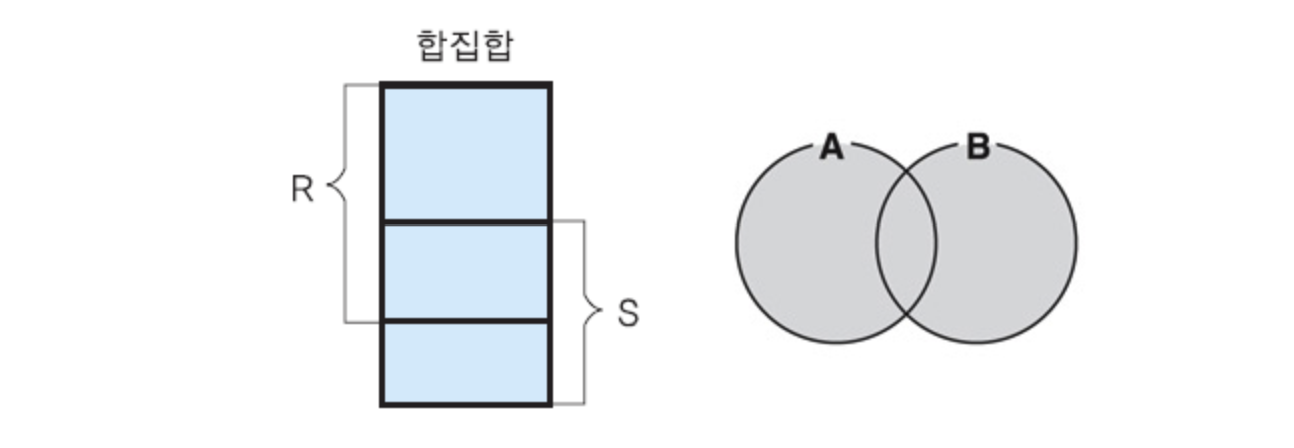
✅ 두 릴레이션의 튜플들을 합침
✅ 합친 결과 릴레이션에서 중복된 투플들은 제외됨
✅ 로 연산자를 표현
✅ 합집합은 합집합 호환 조건이 맞아야만 실행할 수 있다.
✅ 카디날리티 : max (n, m) <= C (T) <= n + m
n과 m 은 각각 R과 S의 카디날리티이다. T 는 결과 릴레이션.
Info
합집합 호환 (union compatible)
서로 다른 테이블에 union 하는데 있어, 차수가 다르거나 도메인이 다르면 안된다. 이 규칙은 합집합, 차집합, 교집합에 모두 적용된다.
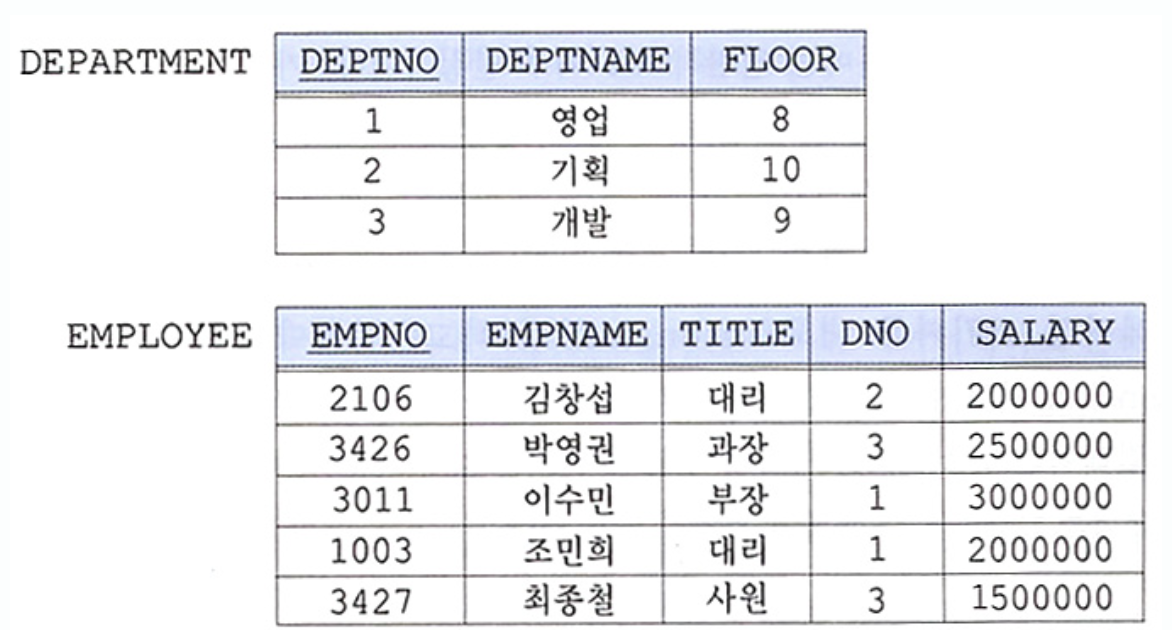
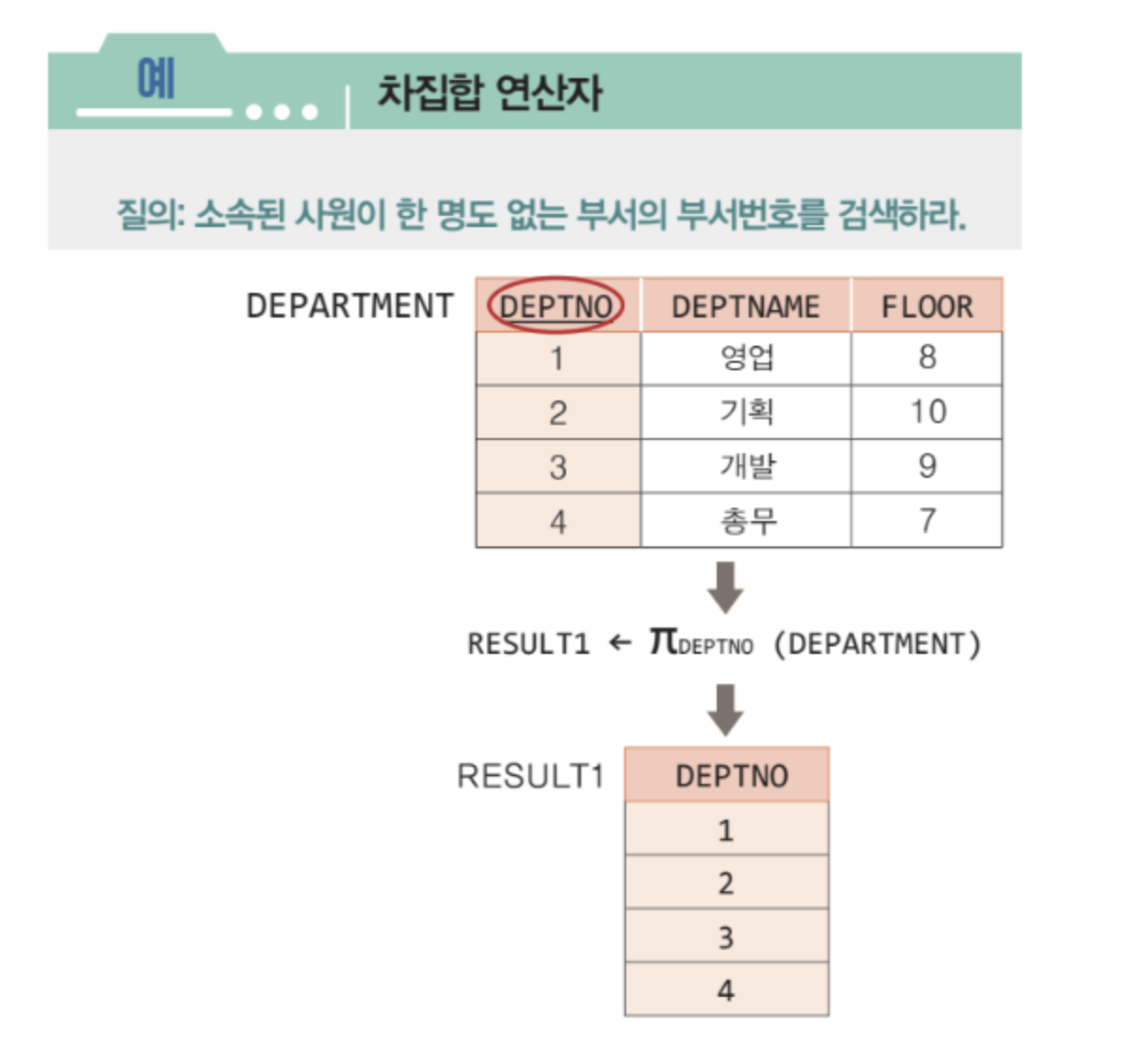
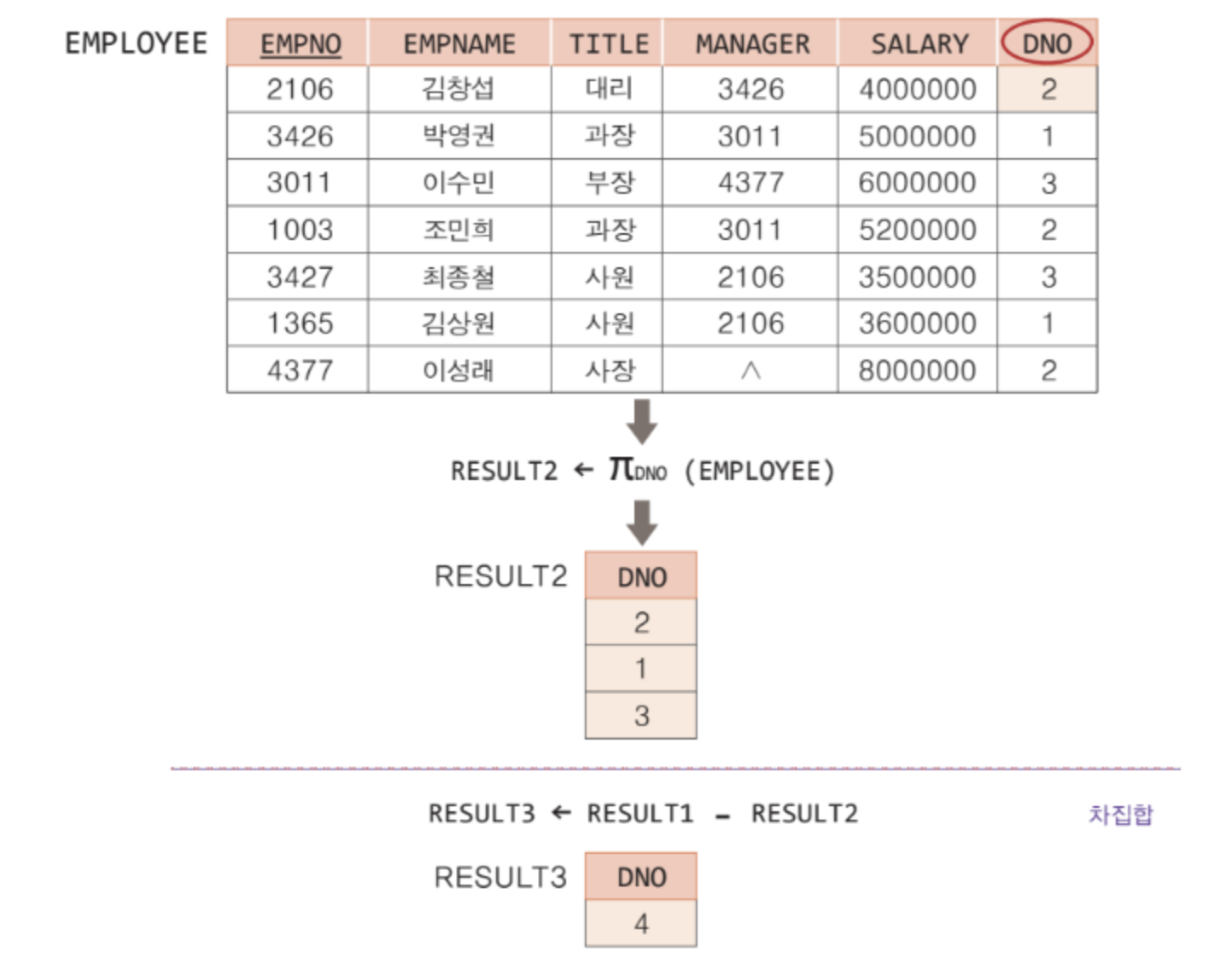
예를 들어, 아래의 EMPLOYEE 릴레이션과 DEPARTMENT 릴레이션은 기본적으로 차수가 다르므로 합집합 호환 조건에 맞지 않는다고 볼 수 있다.
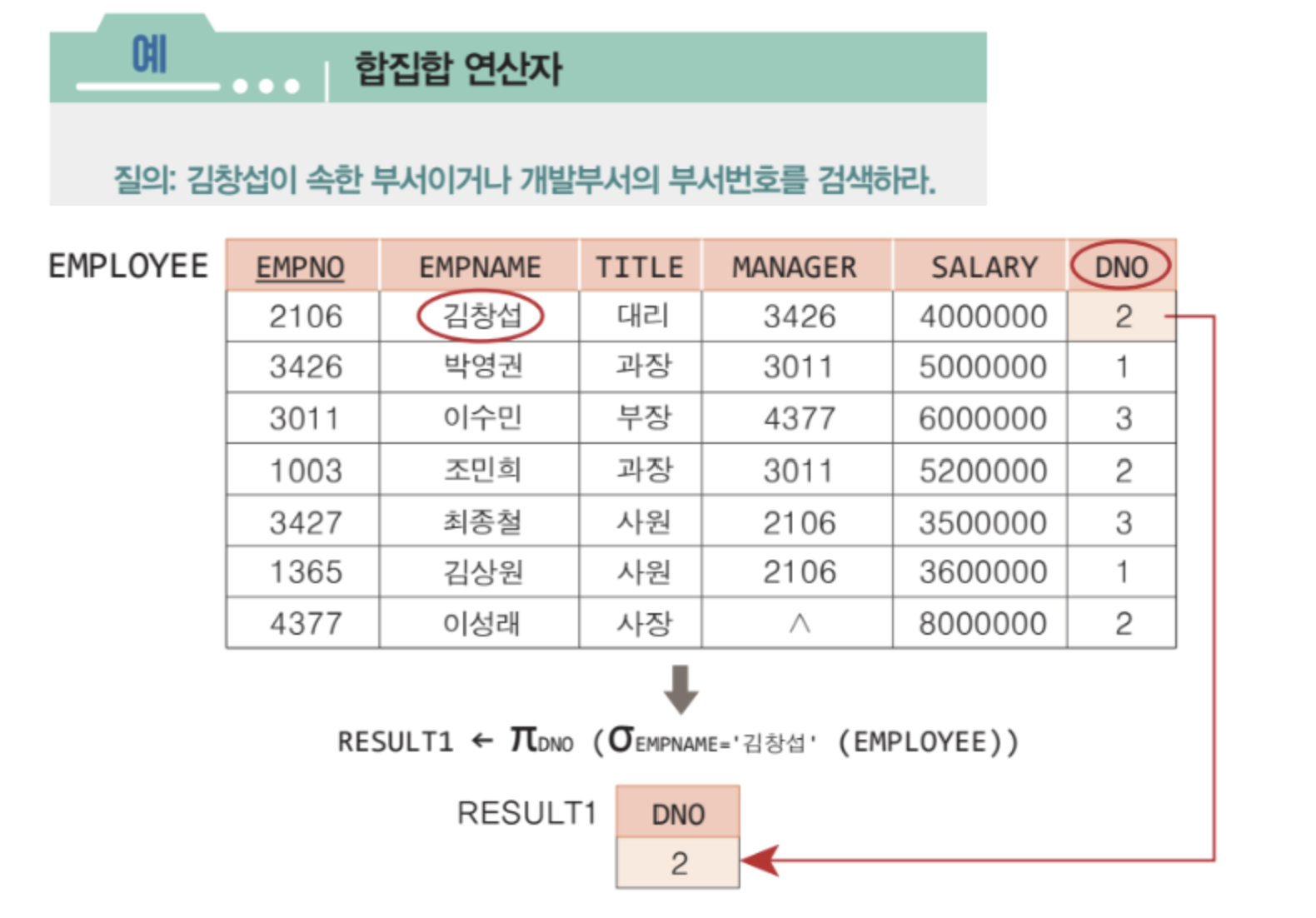
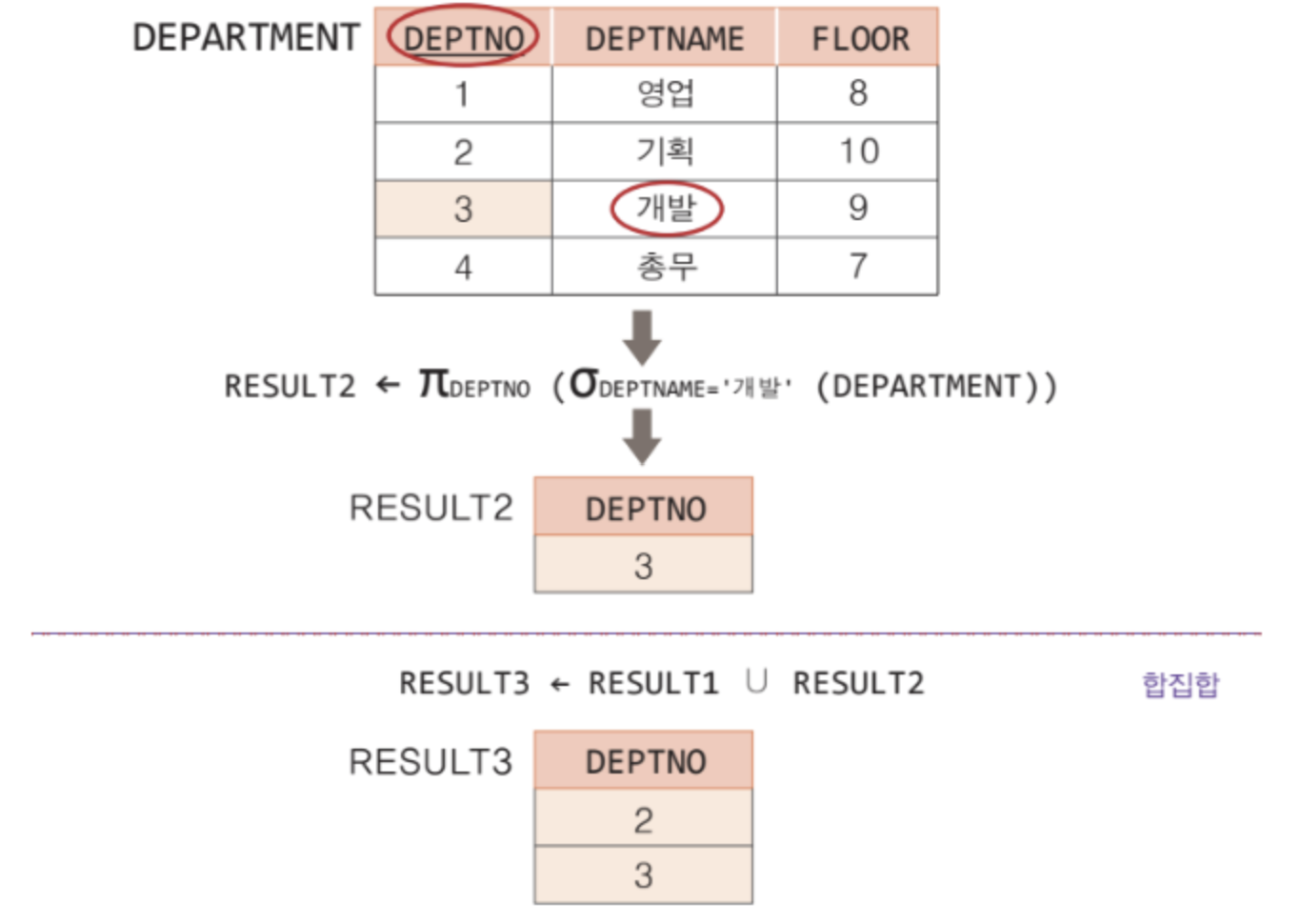
그러나 EMPLOYEE 릴레이션에서 DNO를 프로젝션한 결과 릴레이션과 DEPARTMENT 릴레이션에서 DERPTNO를 프로젝션한 결과 릴레이션이 있다고 하자. 두 결과 릴레이션은 차수가 같고 도메인이 같으므로 합집합 호환 조건을 만족한다.
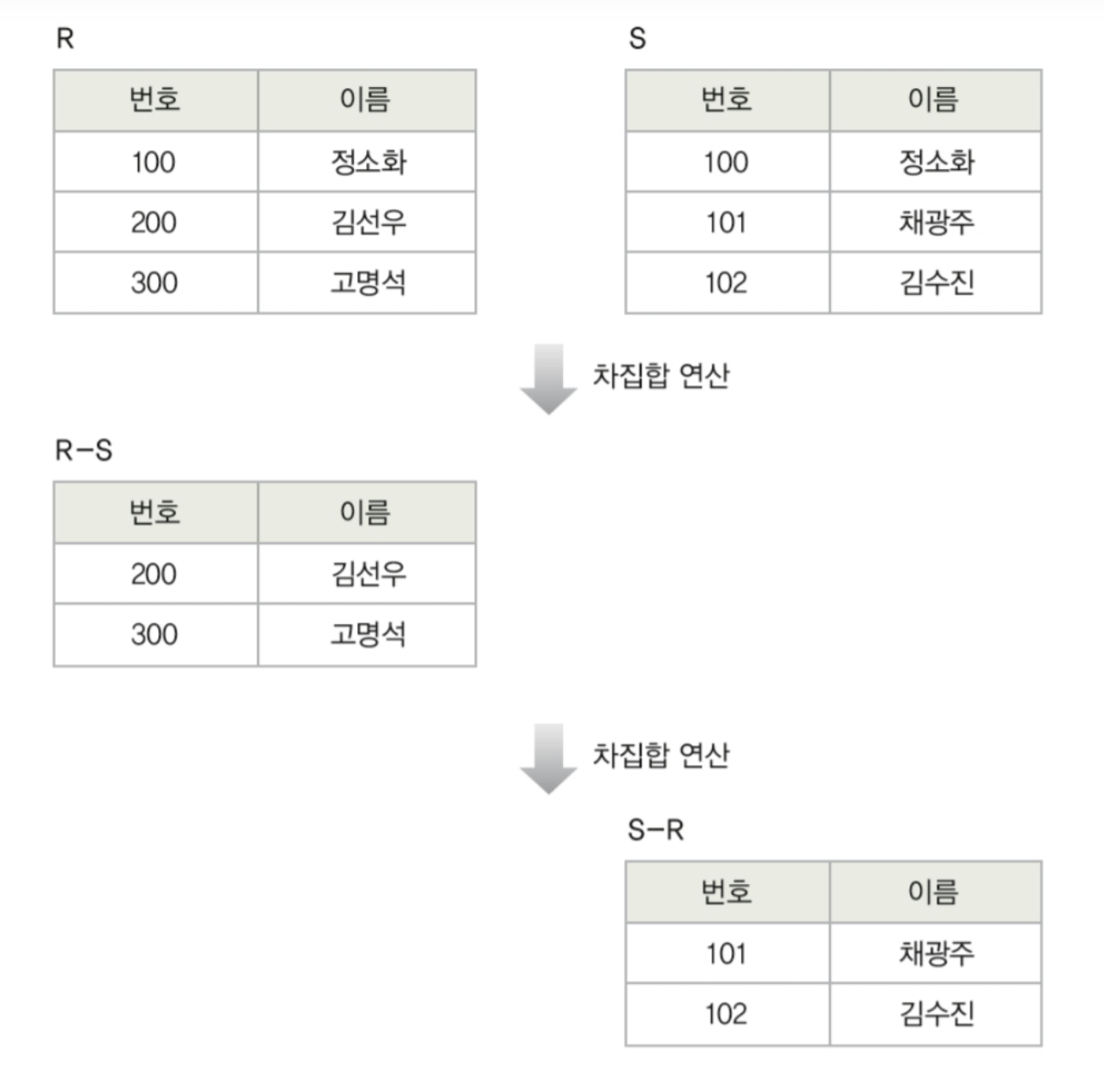
차집합 연산자 -
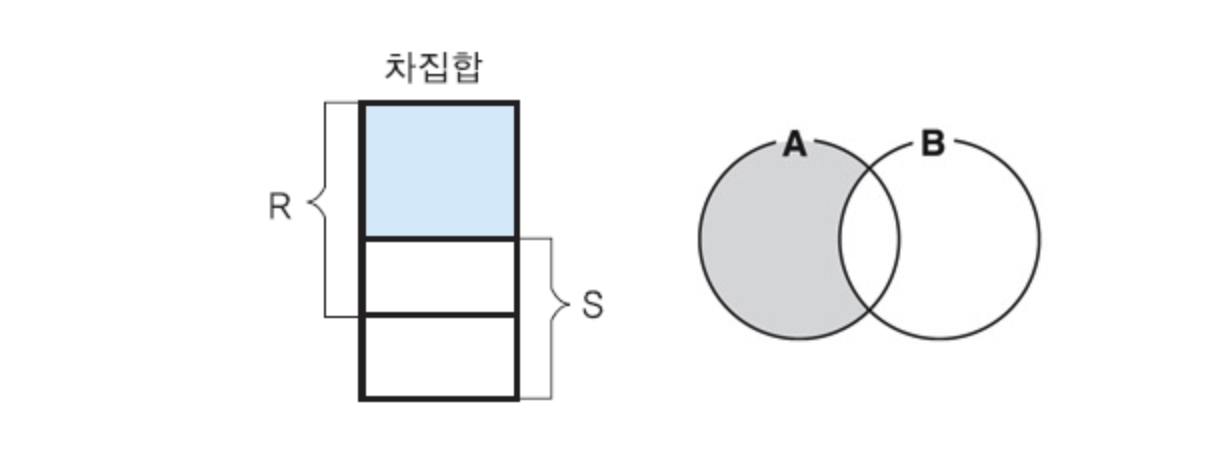
✅ 두 릴레이션의 튜플들의 겹치지 않는 부분만을 도출
✅ - 로 연산자를 표현
✅ 카디날리티 (R - S) : <= C(T) <= C(R)
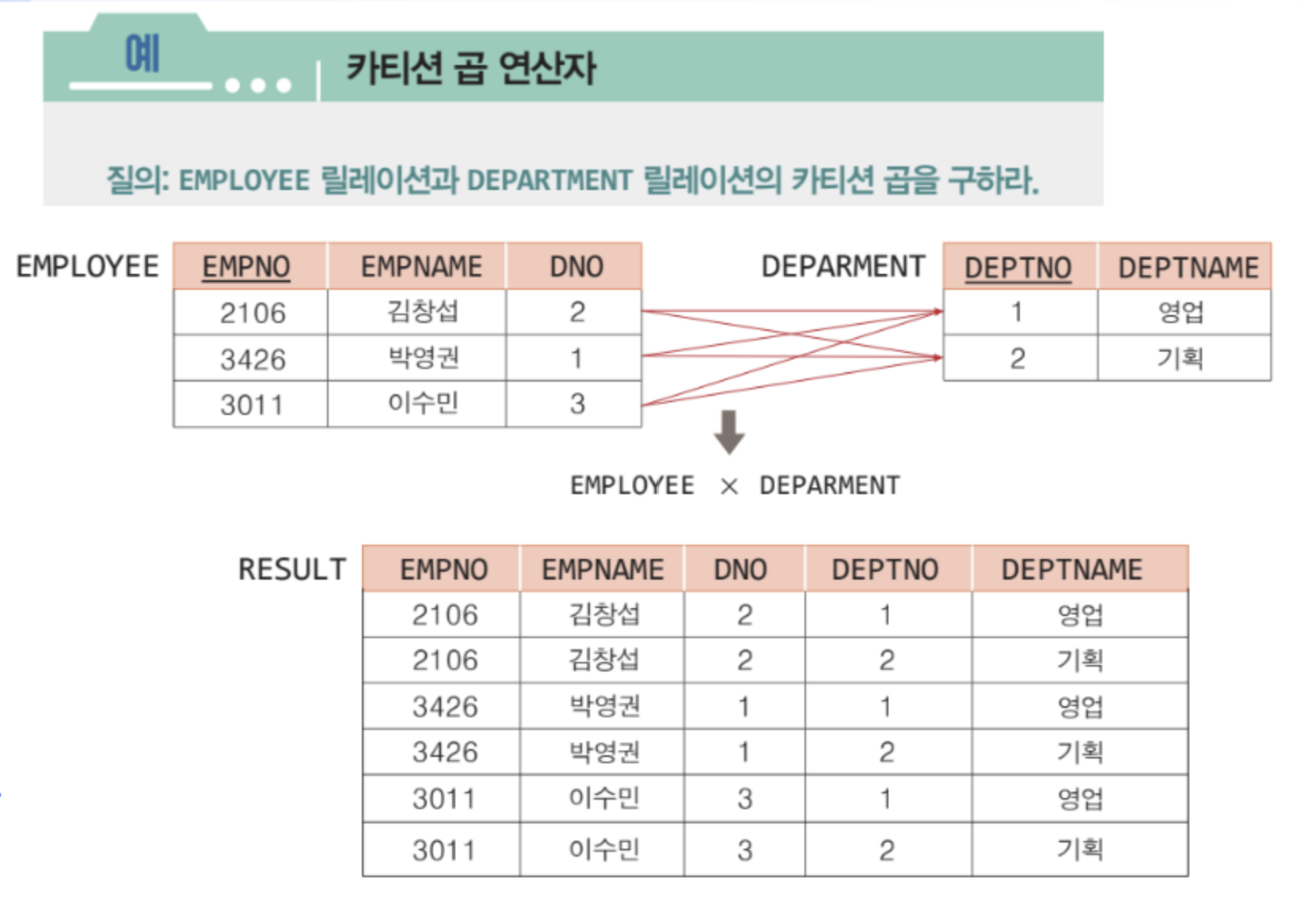
카디션 곱 연산자 x
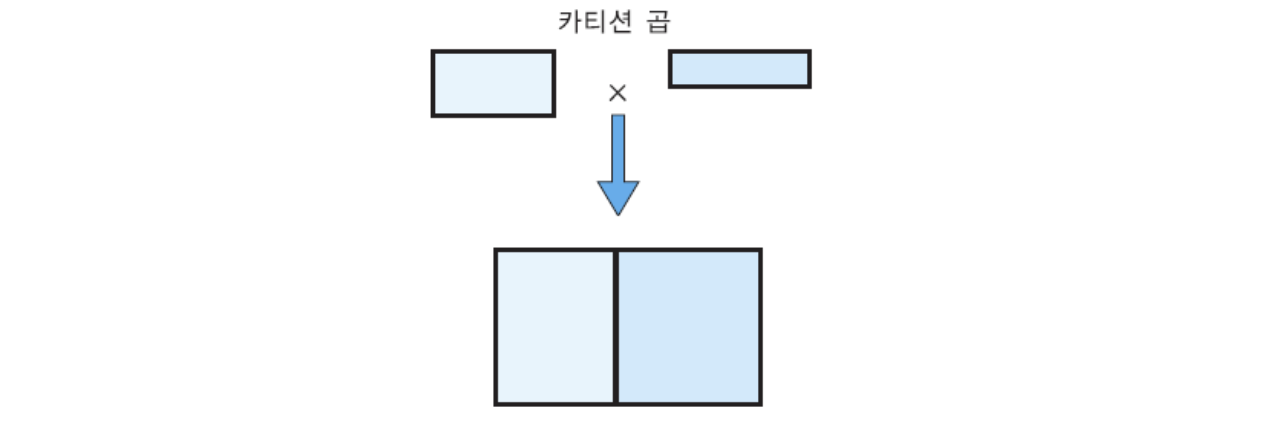
✅ 두 릴레이션에서 가능한 모든 조합을 만들어주는 연산자
✅ 두 테이블로 만들 수 있는 모든 경우의 수를 나타내는 전체 집합을 도출
✅ 결과 릴레이션이 너무 커져서 오버헤드가 발생할 수 있기에 유용한 연산자는 아님
✅ x 로 연산자를 표현
✅ 카디날리티는 n * m
관계 대수의 완전성
✅ 셀렉션, 프로젝션, 합집합, 차집합, 카디션 곱은 관계 대수의 필수적인 연산자
✅ 다른 관계 연산자들은 이 필수 연산자를 두 개 이상 조합하여 표현할 수 있음
✅ 임의의 질의어가 적어도 필수적인 관계 대수 연산자들만큼의 표현력을 갖고 있으면 관계적으로 완전 (relationally complete) 하다고 말함
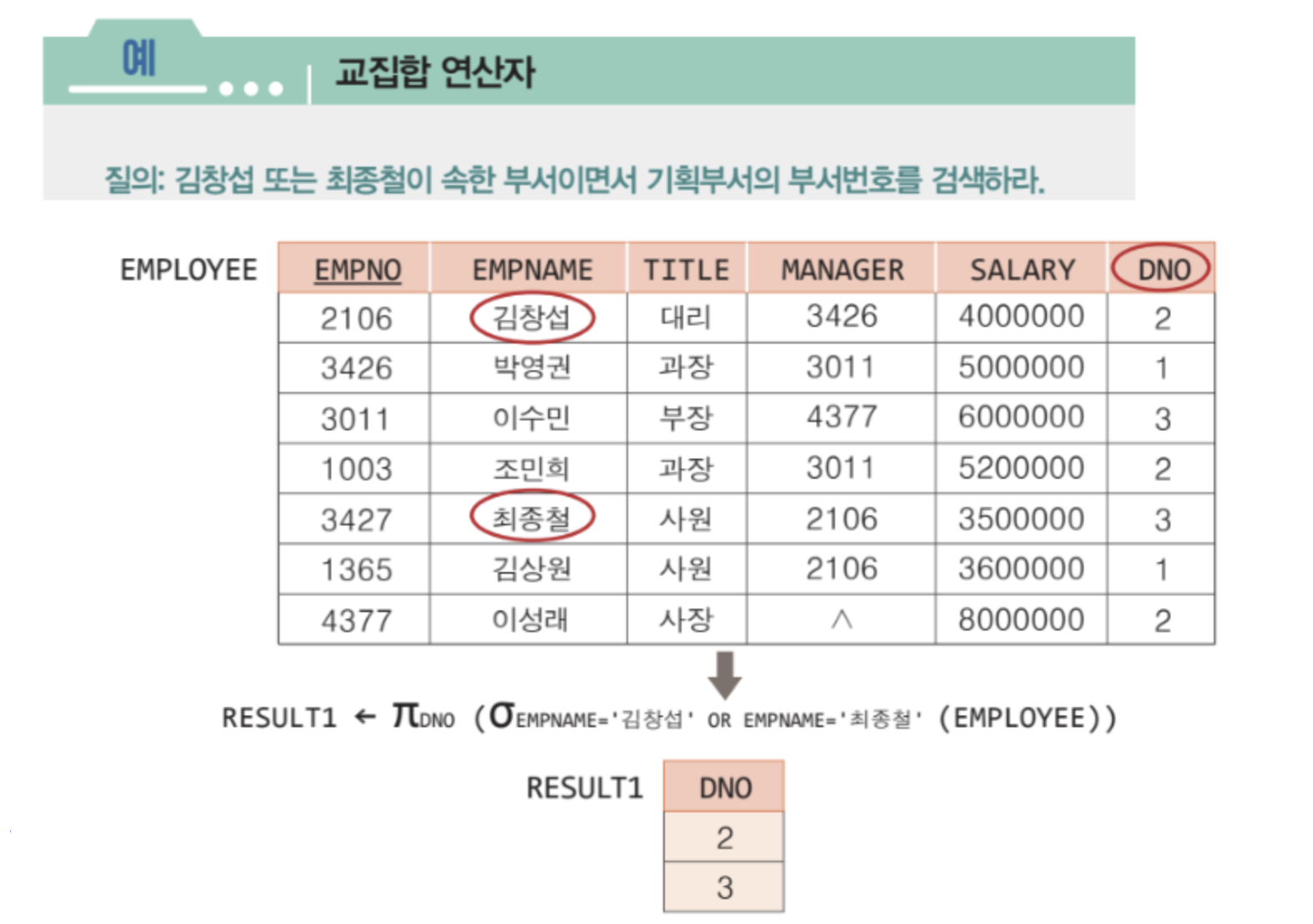
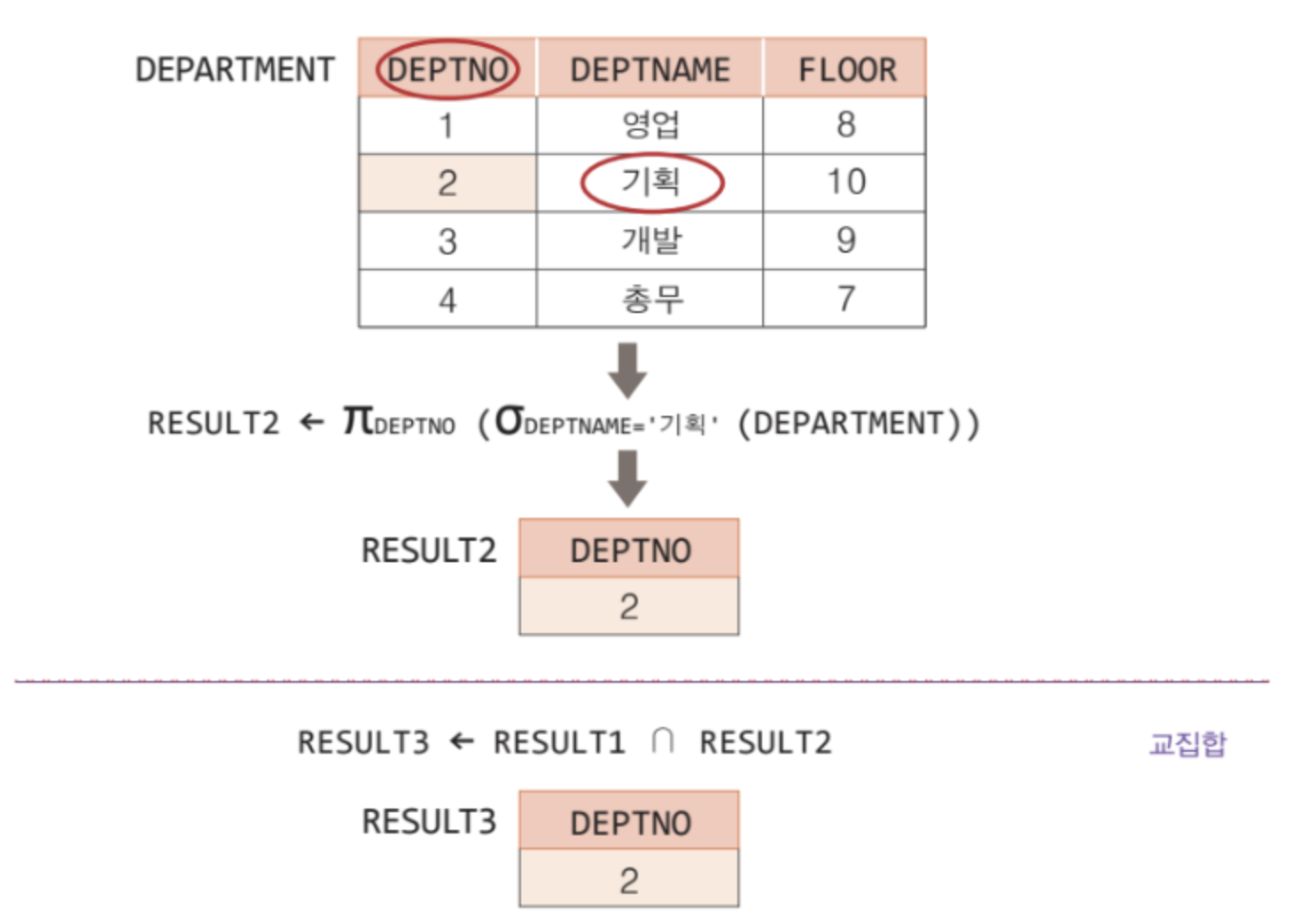
교집합 연산자
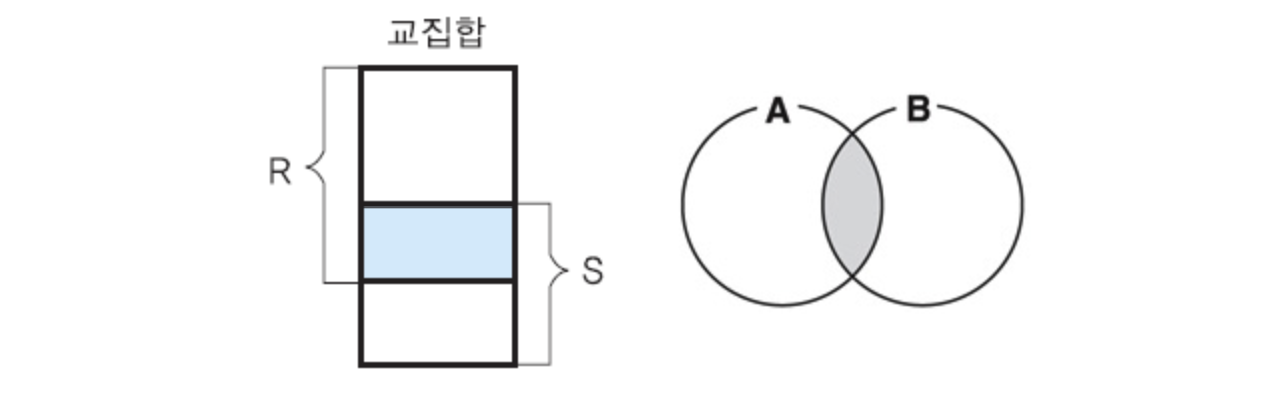
✅ 두 릴레이션 투플들의 겹치는 부분만을 도출
✅ 로 연산자를 표현
✅ 카디날리티 : <= C(T) <= min (R, S)
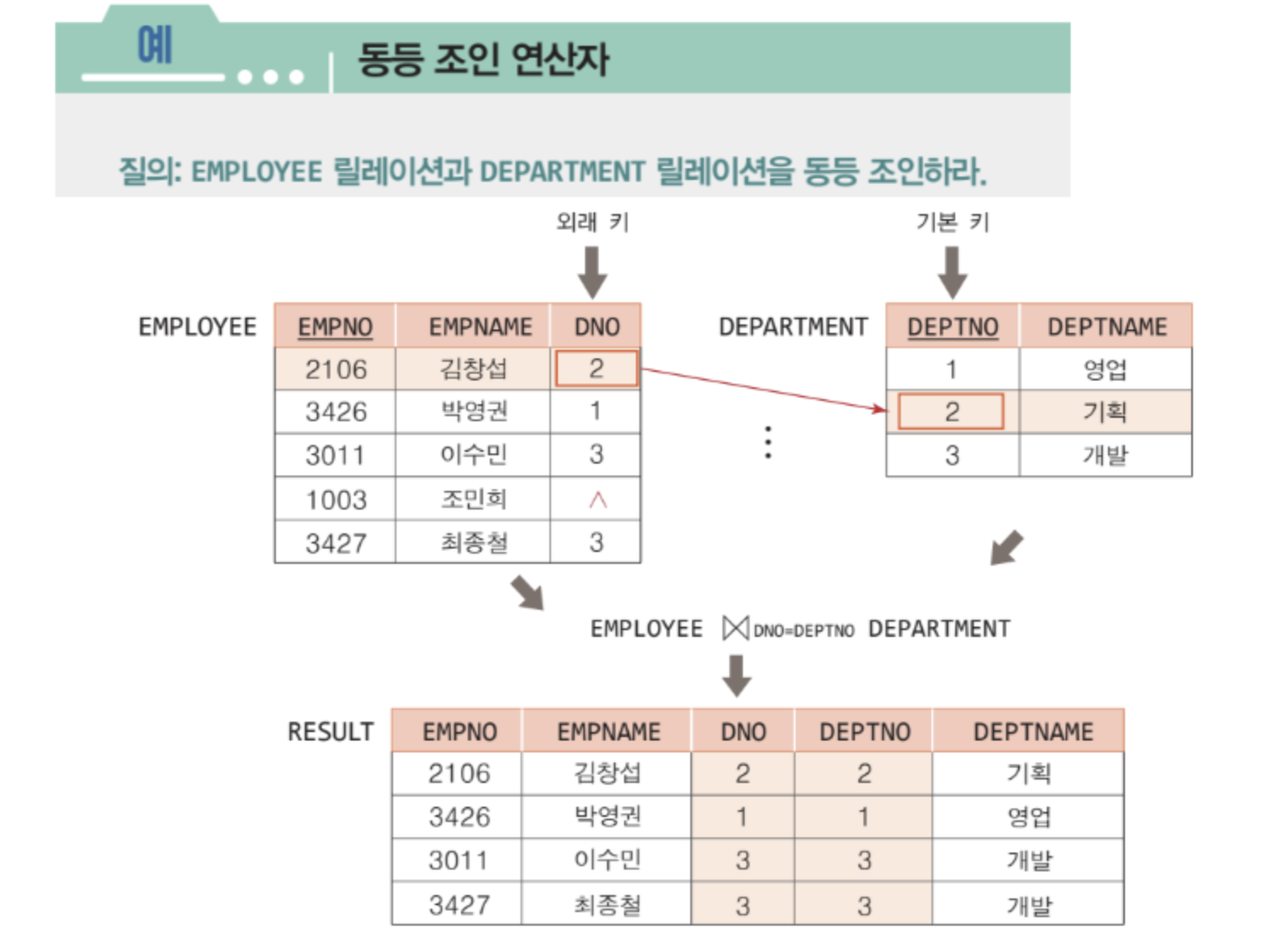
조인 연산자 ⋈
✅ 두 개의 릴레이션으로부터 연관된 투플들을 결합하는 연산자
✅ ⋈ 로 연산자를 표현
✅ 조인 연산자는 다음과 같이 연산 방식에 따라 여러 조인으로 나뉜다.
➡️ 세타 조인 (theta join)
➡️ 동등 조인 (equi join)
➡️ 자연 조인 (natural join)
➡️ 외부 조인 (outer join)
➡️ 세미 조인 (semi join)
세타 조인 & 동등 조인
✅ 세타 조인은 두 릴레이션에서 공통된 애트리뷰트를 기준으로
비교 연산자 ( =, <>, <=, <, >=, >) 를 사용하여 조건을 만족하는 튜플을 결합함
✅ 동등 조인은 세타 조인 중 비교 연산자가 = 인 조인이다.
즉, 두 릴레이션에서 공통된 애트리뷰트의 값이 같은 튜플들을 결합하는 것이다.
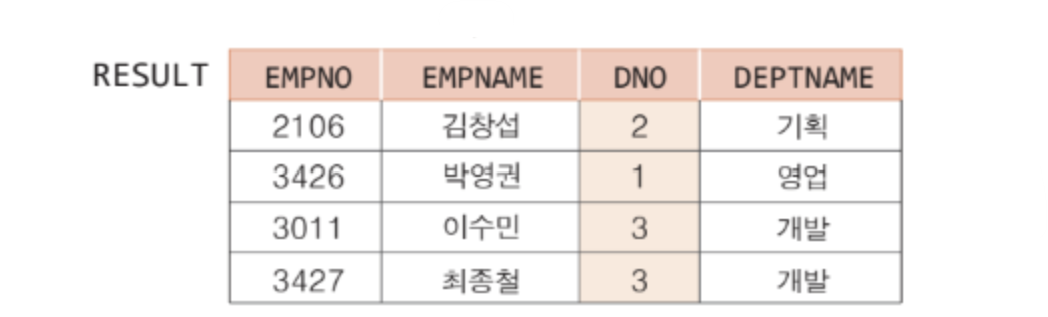
자연 조인
✅ 동등 조인의 결과 릴레이션에서 조인 애트리뷰트를 제외한 조인 (중복 필드 제거)
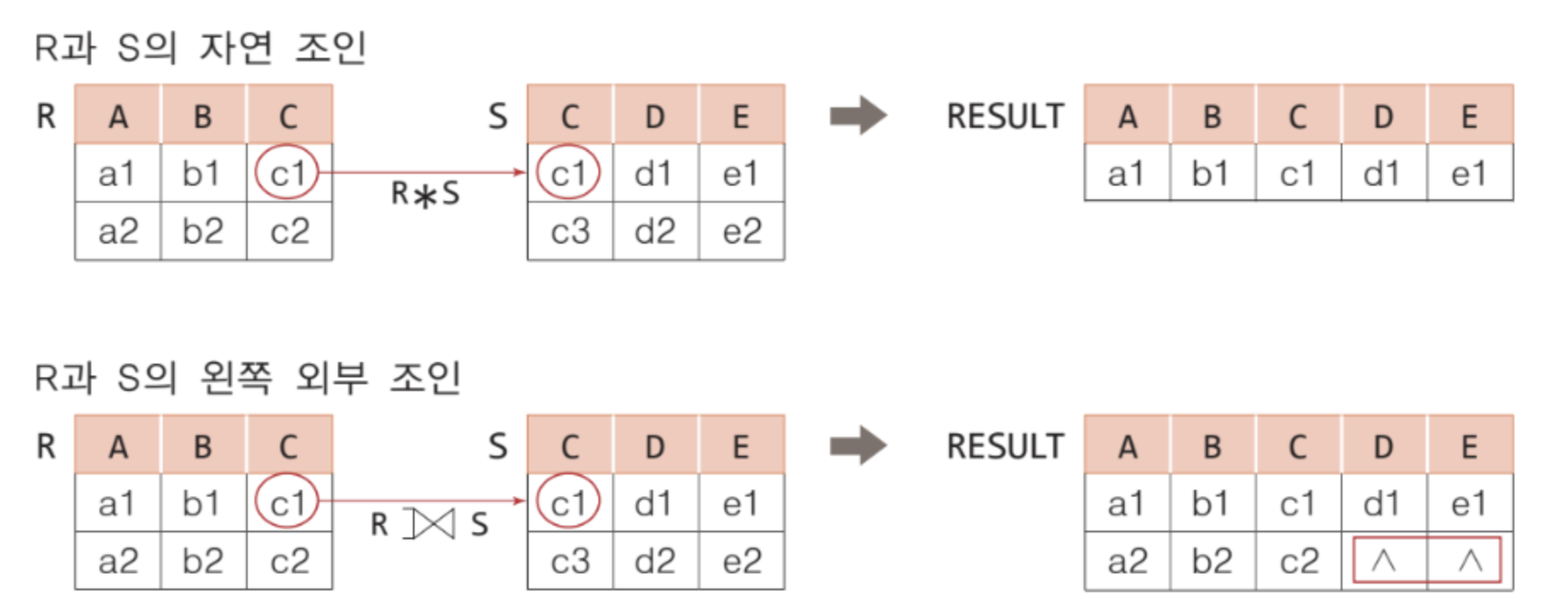
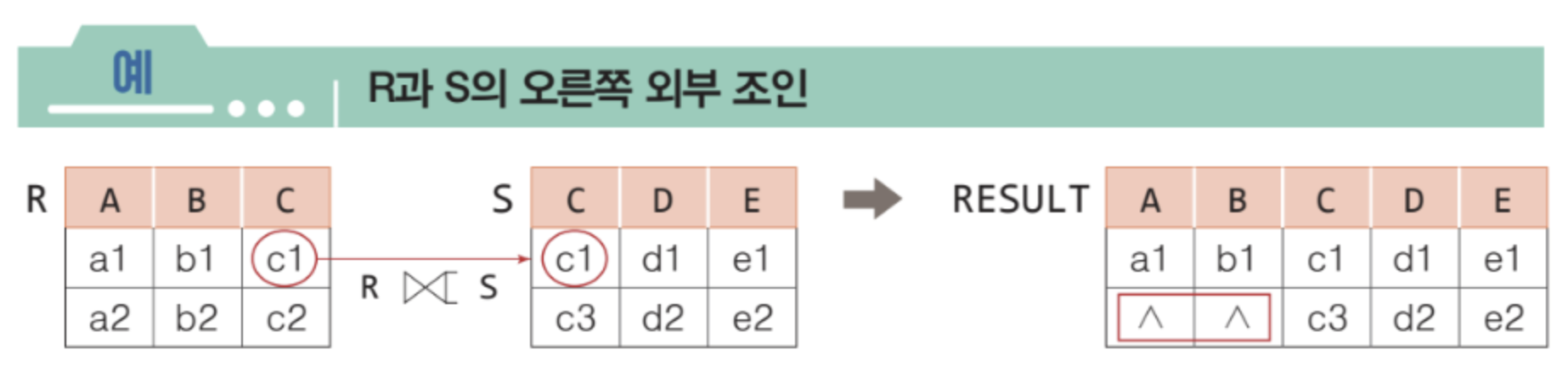
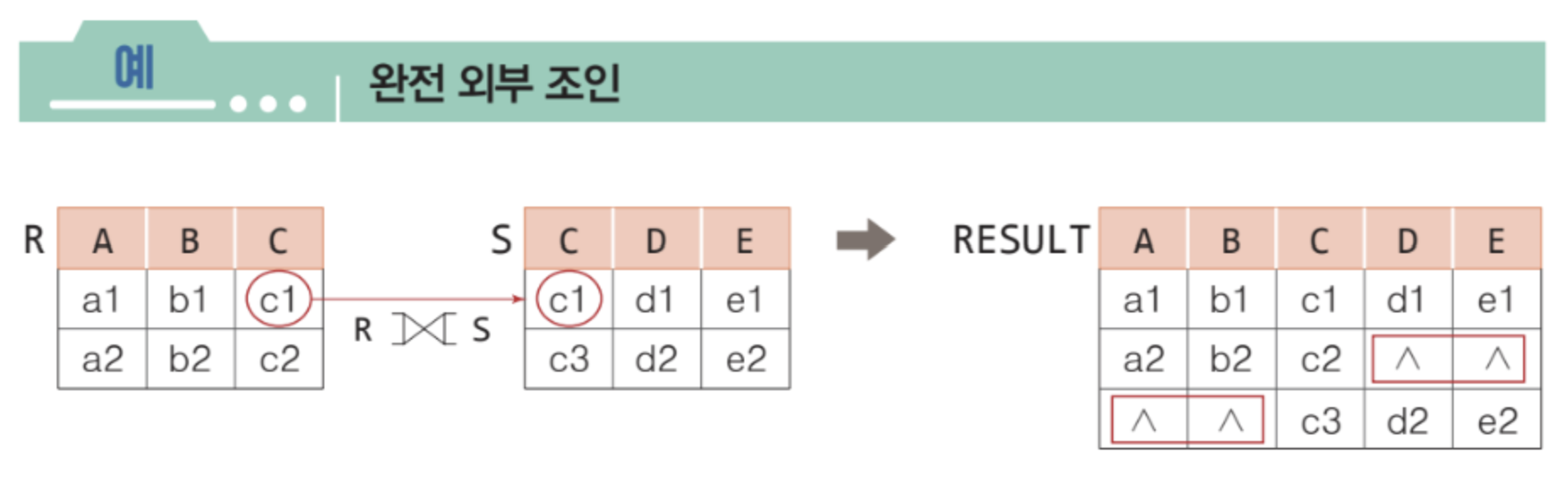
외부 조인
✅ null 값이 들어있는 튜플들을 다루기 위해서 확장한 조인
✅ 일반적인 조인은 두 릴레이션에 대응되는 튜플이 없을 경우, 그 튜플을 결과에 포함시키지 않는다. 하지만 외부 조인은 대응되는 튜플이 없어도 결과에 포함시키고, 상대 애트리뷰트 값은 null 로 채운다.
✅ 외부 조인에는 어느 릴레이션을 기준으로 null 로 채우는지에 따라 3가지로 나뉜다.
➡️ 왼쪽 외부 조인 (left outer join)
➡️ 오른쪽 외부 조인 (right outer join)
➡️ 완전 외부 조인 (full outer join)
디비전 연산자
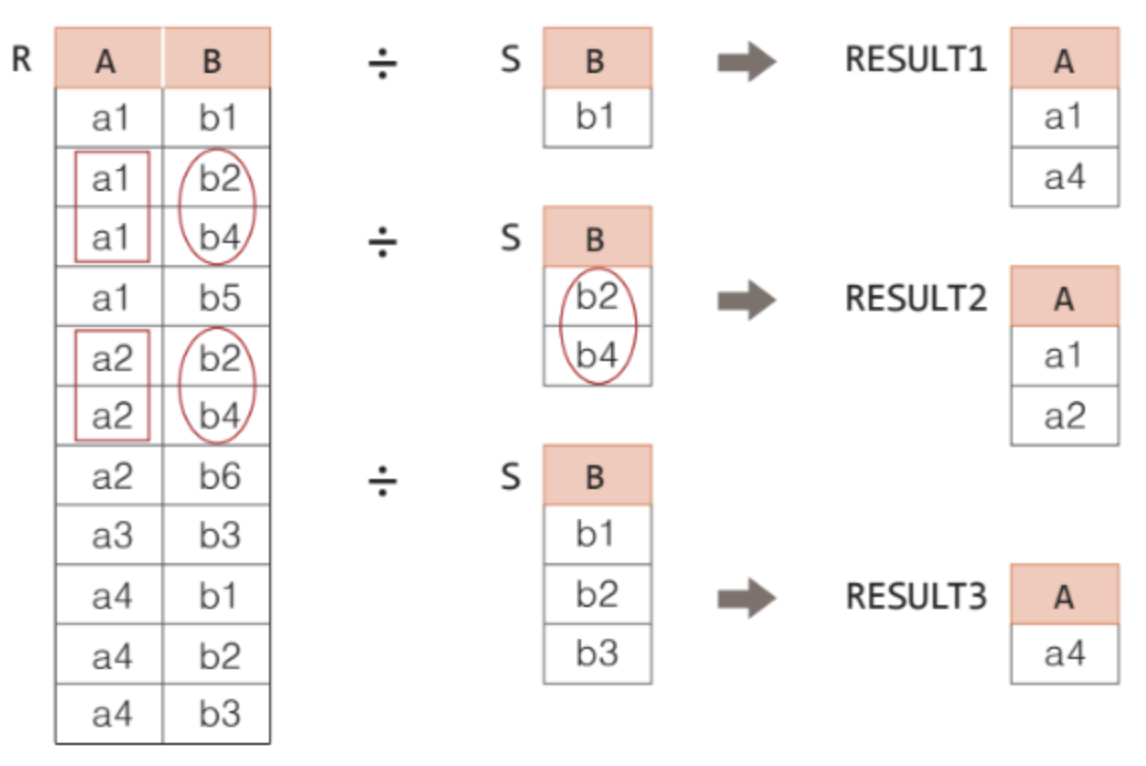
✅ 한 테이블에서 다른 테이블의 모든 값을 가지고 있는 행들을 찾아주는 연산자
✅ '모든 ~에 대해 ~하는' 형태의 질의에 사용될 수 있음
✅ 디비전은 나누는 테이블의 열의 개수만큼 결과 테이블의 열의 개수가 줄어든다
✅ 로 연산자를 표현
관계 대수의 한계
🟧 관계 대수는 산술 연산을 할 수 없음
🟧 집단 함수를 지원하지 않음
🟧 정렬을 나타낼 수 없음
🟧 데이터베이스를 수정할 수 없음 (기존값 변경 불가)
🟧 프로젝션 결과에 중복된 값을 나타내는 것이 필요할 수 있는데 이를 명시하지 못함
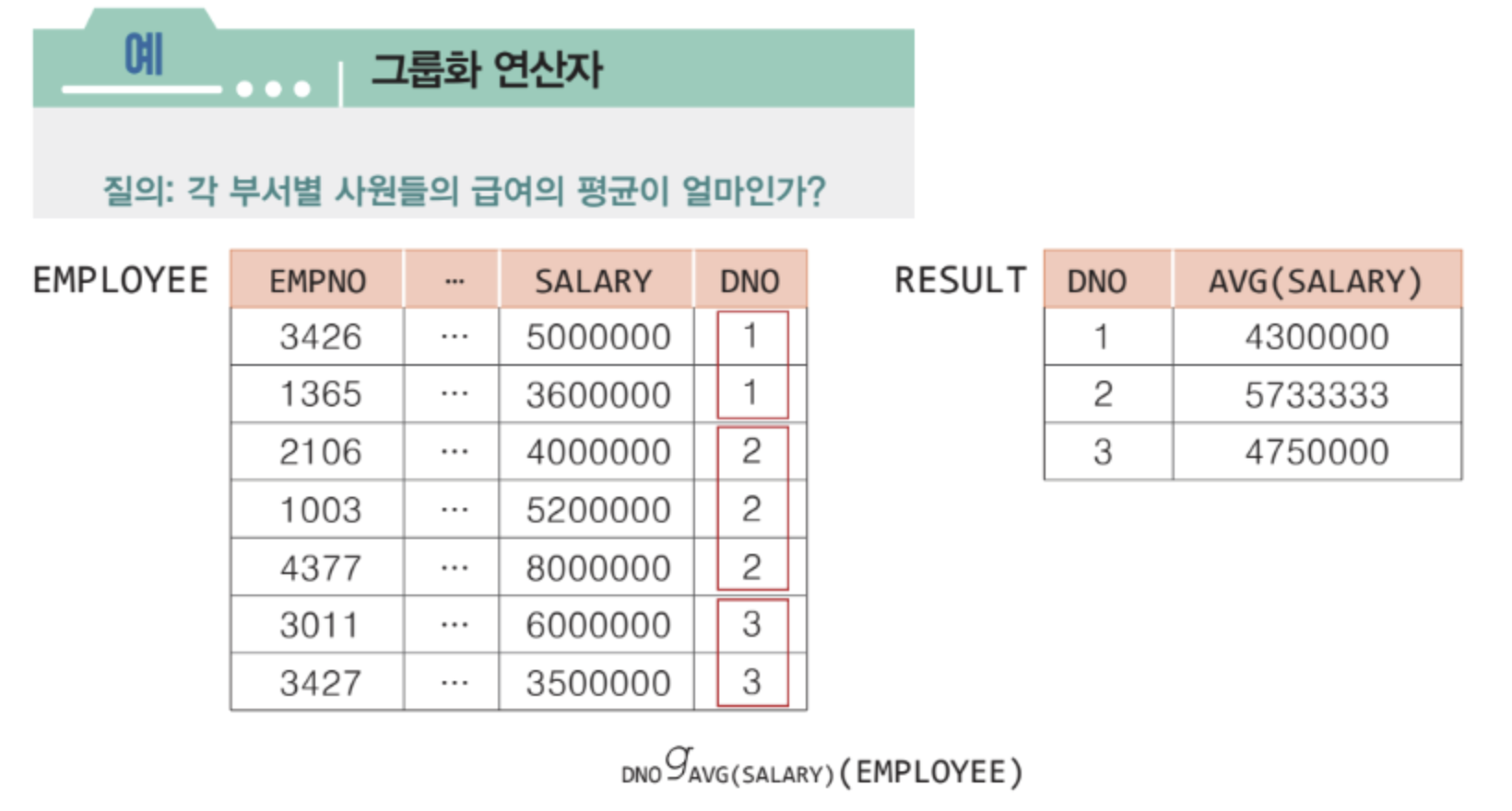
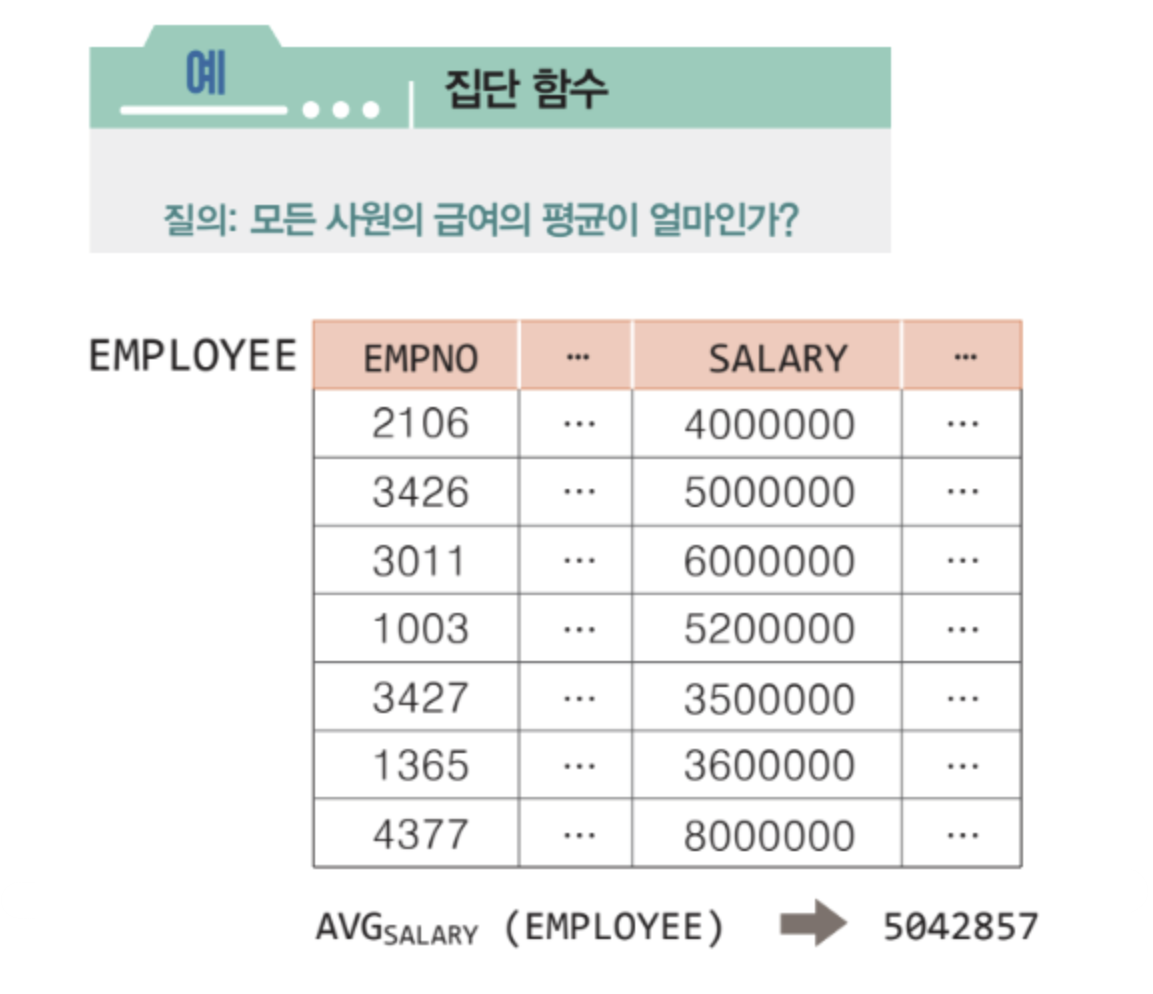
집단 함수
✅ 한 릴레이션에서 특정 속성들의 값들에 대해 총합, 평균, 최대, 최소, 개수 등의 연산을 수행하는 함수
✅ 관계 대수의 표현력을 높이기 위해 새로 추가된 연산자
✅ 집단 함수는 각 그룹에 대해 독립적으로 적용되며, 그룹화 연산자와 함께 사용된다.
✅ AVG, SUM, MIN, MAX, COUNT
그룹화
✅ 한 릴레이션에서 특정 애트리뷰트들의 값에 따라 튜플들을 여러 그룹으로 분류하고, 각 그룹에 대해 집단 함수를 적용하는 연산자
✅ 그룹화 연산자는 G 로 표기됨