Intro: 연구실 생활의 시작
이번 겨울방학부터 SDLA (Semiconductor Devices Lab for AI)에서 학부 연구생 인턴 생활을 시작하게 되었다.
본격적인 출근에 앞서 정규원 교수님과 면담을 가졌고, AI 반도체의 현재와 미래, 그리고 연구자로서 가져야 할 태도에 대해 깊이 있는 조언을 들을 수 있었다. 유선규, 최우석 교수님의 세미나 내용까지 통합하여, 앞으로 연구를 진행함에 있어 방향을 잃지 않도록 기록해둔다.
1. AI 반도체, 왜 필요한가? (The End of Moore's Law)
반도체 역사를 돌아보면, 무어의 법칙(Moore's Law)은 지난 수십 년간 전자 공학의 찬란한 혁명을 이끌어 온 이정표의 역할을 했다.
하지만 무어의 법칙이 흔들리기 시작한 건 이미 오래전 일이다. 트랜지스터를 작게 만들면 성능이 좋아진다는 공식(Dennard Scaling)이 깨지면서, 발열 문제로 인해 더 이상 클럭 스피드(Clock Speed)를 높이기 어려운 상황이 되었다. 인텔과 같은 기업들은 이에 대응해 코어 수를 늘리거나(Multi-core), 집적도를 극한으로 올리는 방식으로 성능을 유지해 왔다.
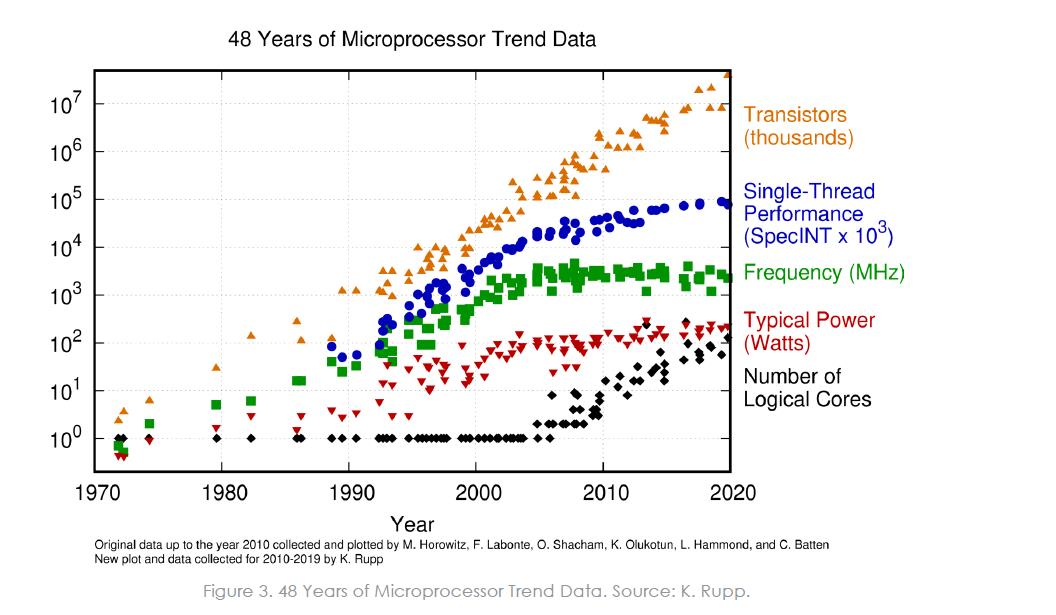
그러나 이제는 그마저도 물리적/경제적 한계에 봉착했다. 더 이상 단순히 집적도만 높이는 방식으로는 성능 개선이 어렵다. 설상가상으로 AI 혁명이 터지면서 전례 없는 고성능/저전력 하드웨어 수요가 폭발했다. 지금은 기존의 방식을 답습하는 것이 아니라, 완전히 새로운 패러다임이 필요한 시점이다.
2. AI 반도체의 정의와 분류
'AI 반도체'라는 용어 자체가 최근에 등장했기 때문에 아직 학계와 산업계에서 혼용되고 있다. 아직 체계적으로 정립되지 않은 분야지만, 나름대로 정리해 보면 다음과 같다.

- 1세대: GPU (Graphics Processing Unit)
- 원래는 그래픽 처리를 위한 병렬 연산 장치였다. 하지만 딥러닝의 핵심인 행렬 연산(Matrix Multiplication)에 적합하다는 것이 밝혀지며 초기 AI 붐을 이끌었다.
- 2세대: NPU (Neural Processing Unit)
- 구글의 TPU, 애플의 Neural Engine 등. AI 연산에 불필요한 기능을 덜어내고 효율을 극대화한 전용 칩셋이다.
- 3세대: Neuromorphic & PIM (Processing-in-Memory)
- Digital PIM: HBM-PIM, AiM 처럼 메모리 내부에서 연산을 수행하는 방식.
- Analog PIM / Neuromorphic: Synaptic devices, Memristor(RRAM, PCM), FeFET() 등을 활용해 소자 레벨에서 아날로그 연산을 수행하거나 뇌를 모사하는 방식.
기본적인 발전 방향은 "AI 연산의 병목 해결 및 전력 소모 최소화"다.
"AI가 전기를 너무 많이 먹는다"는 문제의식은 모두가 공유하고 있다. 이를 해결하기 위해 누군가는 더 효율적인 발전기를 연구하고, 아키텍처 레벨에서 구조를 바꾸려는 사람도 있다. 그리고 소자 연구자들은 가장 밑단의 소자 구조를 바꿔서 이 문제를 해결하려 한다.
3. Industry vs Academic
SDLA를 포함한 많은 대학 연구실들은 3세대, 그리고 그 이후를 바라보는 소자 연구를 수행한다.
과거 20~30년 전에는 대학 랩실과 삼성/하이닉스 같은 기업의 연구 환경(장비)에 큰 차이가 없었다고 한다. 하지만 지금은 다르다. 기업의 최첨단 미세 공정 장비는 대학이 도저히 따라갈 수 없는 수준이다. 따라서 역할 분담이 명확해졌다.
- Industry: 당장의 수율과 양산을 고민하고, 미세 공정의 극한을 추구한다.
- Academic: 산업에 바로 적용되는 기술보다는, 5년, 10년 뒤의 패러다임을 바꿀 Next Idea를 제시해야 한다. 기업이 하지 못하는, 미래 세대에 영감을 줄 수 있는 선행 연구가 대학의 몫이다.
4. 폰 노이만 병목과 PIM의 태동
현재 컴퓨터 구조의 근간인 '폰 노이만 구조(Von Neumann Architecture)'는 CPU(연산)와 메모리(저장)가 분리되어 있다.
과거에는 이 구조 덕분에 각 분야가 빠르게 발전할 수 있었다.
Applications - Compilers - OS - Architecture - Circuits - Devices/Physics
각 레이어가 철저하게 추상화(Abstraction)되어 있었기 때문에, 하드웨어 엔지니어는 물리만, 소프트웨어 엔지니어는 코딩만 파면 됐다. 하지만 요즘은 이 레이어 간의 경계가 희미해지고 있다. 하드웨어 디자인을 하려면 위쪽 레이어를 알아야 하고, 소프트웨어를 하려면 하드웨어 특성을 알아야 한다.
가장 큰 문제는 '데이터 병목(Bottleneck)'이다.
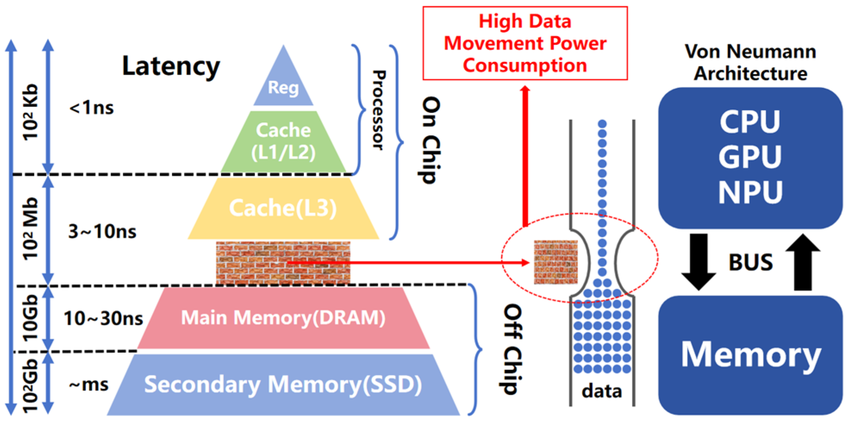
데이터를 저장하는 곳과 처리하는 곳이 분리되어 있는데, AI 연산은 데이터 양이 너무 많다. 왔다 갔다 하느라 에너지를 다 쓴다. CPU 안에 캐시 메모리(SRAM)가 있지만 용량이 부족하고, DRAM은 너무 멀리 있다. 현재 가속기에서도 메모리 관련 에너지 소모가 70% 이상을 차지한다. 이를 해결하기 위해 SRAM을 3D로 적층하거나(On-chip), DRAM과 프로세서 사이의 거리를 좁히는 시도 등 다양한 approach 들이 존재한다.
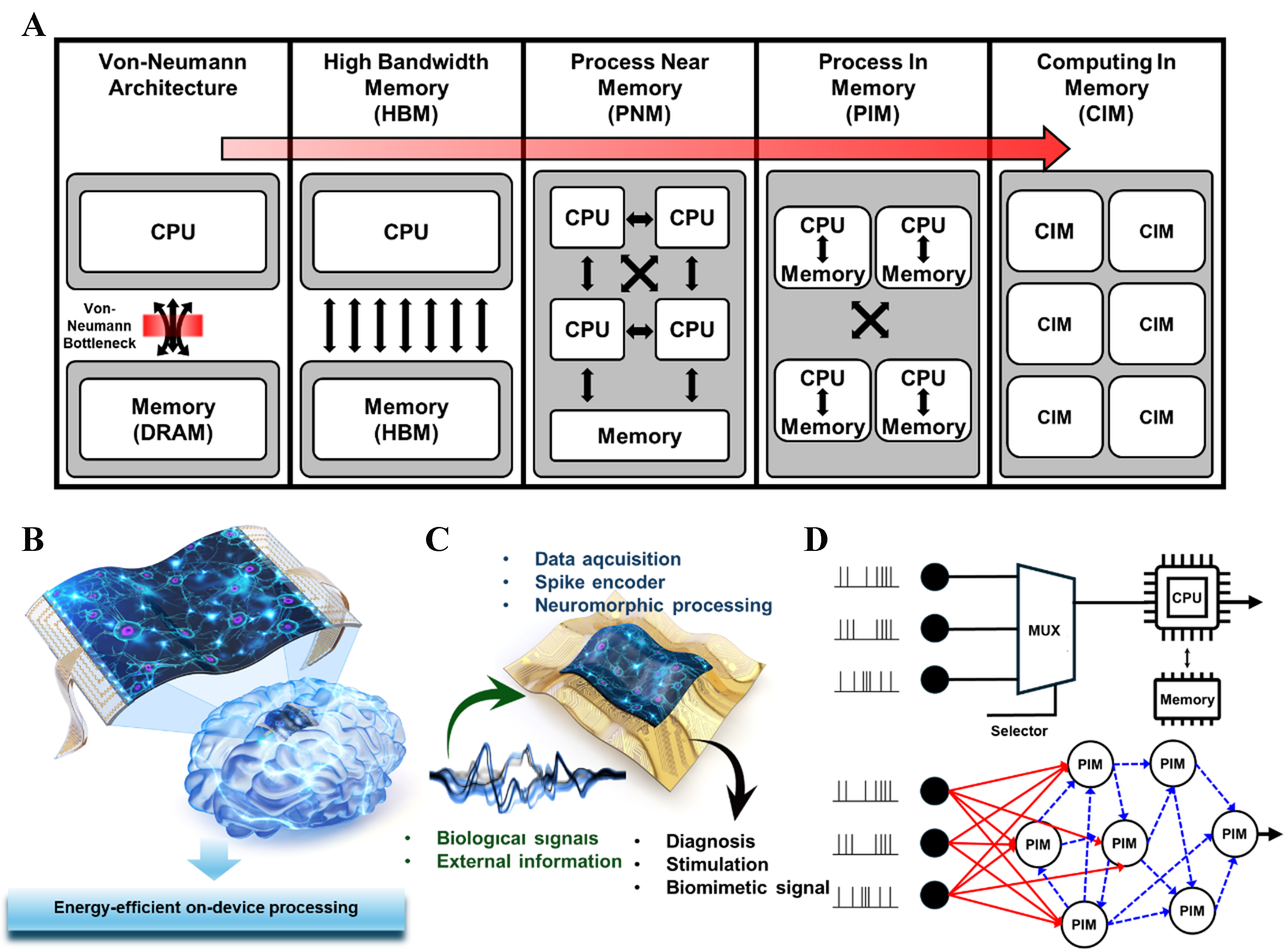
삼성전자 등 메모리 기업들은 PIM(Processing-in-Memory), 즉 메모리가 연산까지 수행하는 구조에 도전하고 있다. 아직 전체 판을 바꿀 정도의 파급력은 아니지만, 메모리의 위상이 단순 저장소에서 연산 장치로 바뀌고 있는 것은 분명하다.
5. 뉴로모픽의 난제와 기회: Next 폰 노이만은 누구인가?
뉴로모픽은 인간의 뇌가 굉장히 훌륭한 아키텍처라는 점에서 착안하여, 이를 모사해 전력 효율을 극대화하려는 시도다.
물론 인간의 뇌는 단순한 사칙연산 속도 면에서는 컴퓨터보다 느릴지 모른다. 하지만 복잡한 정보를 처리하고 추론하는 '특정 영역'에 있어서만큼은 약 20W의 전력만으로 작동하는 궁극의 저전력 고효율 시스템이다.
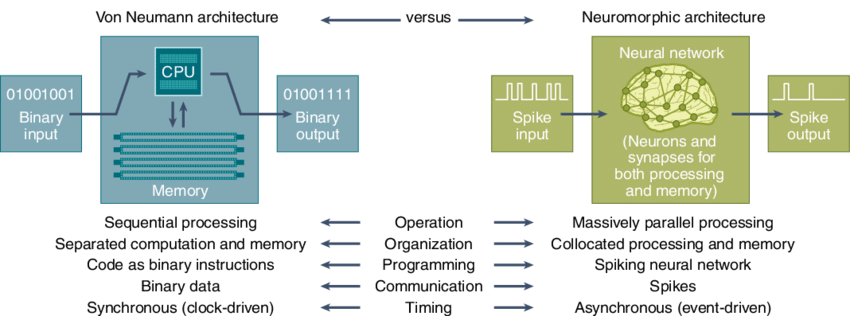
핵심은 구조에 있다. 인간의 뇌는 메모리와 프로세서가 따로 존재하지 않는다. 이러한 'Memory-Processing Colocation' 혹은 'Non-Von Neumann' 구조가, 현재의 전력 효율 문제와 연산 병목을 해결하는 열쇠가 될 것이라는 접근이다. 이를 반도체로 구현하는 접근법(Approach)은 크게 두 가지 갈래로 나뉜다.
- 생체 모방(Bio-mimetic) 접근:
- 실제 생물학적 뇌의 작동 원리를 소자 레벨에서 그대로 모사하는 방식이다.
- 특정 임계치를 넘으면 신호를 전달하는 뉴런의 스파이킹(Spiking) 동작 등을 소자의 물리적 특성으로 구현하려 한다. (SNN 등)
- 아날로그 컴퓨팅(Analog Computing) 접근:
- 현재 AI 모델(DNN)의 핵심인 '행렬 연산(Matrix Multiplication)'을 효율적으로 처리하는 데 집중한다.
- 0과 1의 디지털 연산이 아니라, 전류나 전압의 물리적 법칙(옴의 법칙, 키르히호프의 법칙)을 이용해 데이터를 아날로그 방식으로 한 번에 처리한다.
물론 이 두 가지가 칼로 자르듯 완전히 나뉘는 것은 아니지만, 현재 연구는 크게 이 두 방향성을 가지고 전개되고 있다.
하지만 명확한 난제가 존재한다
이러한 이상적인 개념에도 불구하고, 상용화를 위해서는 넘어야 할 산이 많다.
-
정확도(Accuracy) 이슈: 아날로그 연산 특성상 미세한 노이즈와 에러가 누적된다. 이는 결국 거대 모델에서 전체 시스템의 정확도가 감소하는 치명적인 문제로 귀결된다. 과거에 아날로그 컴퓨팅이 디지털에게 왕좌를 내주고 역사 속으로 사라졌던 이유도 바로 이 '노이즈에 취약한 특성' 때문이었다.
-
ADC의 딜레마: 연산을 아날로그 하드웨어로 아무리 효율적으로 처리해도, 결국 결과를 읽어내기 위해 디지털로 변환(ADC: Analog-to-Digital Converter)하는 과정에서 막대한 전력을 소모하게 된다. 배보다 배꼽이 커질 수 있는 상황이다. 엄밀히 따져보면, 현재 컴퓨팅 생태계의 메인스트림(Mainstream)이 '디지털'로 구축되어 있기 때문에 발생하는 필연적인 비용이기도 하다.
-
알고리즘의 부재 (Mismatch): 이것이 핵심이다. 현재 AI의 주류인 딥러닝 모델(Back-propagation 등)은 소프트웨어(디지털) 상에서 잘 돌아가도록 발전했지, 하드웨어 친화적이지 않다.
"Breakthrough는 어디서 오는가?"
현재 많은 연구가 기존의 잘 동작하는 AI 모델을 억지로 하드웨어로 모사하는 식이다. 하지만 애초에 하드웨어에 맞지 않는 옷을 억지로 입히니 효율과 정확도가 떨어진다.
휴머노이드 로봇을 보자. 지금 제일 좋은 로봇도 격렬한 활동과 연산을 수행하면 배터리로 불과 몇 시간도 버티기 힘들다. 시스템 자체가 새로 짜여야 한다. 반도체 소자에서 혁신이 일어나야 한다는 점에는 모두가 동의하지만, 아무도 '무엇을(What)' 해야 하는지 명확히 모르는 상황이다. 이 길을 먼저 간 선구자가 없기 때문이다.
무엇보다 우리는 아직 인간의 뇌를 완전히 이해하지 못했다.
신호 처리가 정확히 어떻게 이루어지는지, 뉴런을 어떻게 모델링해야 하는지에 대해 학설이 갈리고 있다. 따라서 뇌를 있는 그대로 '복제'하는 것은 불가능에 가깝다.
과거 앨런 튜링과 폰 노이만이 그랬던 것처럼, 중요한 것은 생물학적 뇌의 단순한 모방이 아니라 '공학적 모델링'과 재해석이다. 폰 노이만 구조는 수십 년간 검증된 전자공학의 근본(Root)이다. 뉴로모픽이 압도적인 신뢰성과 성능을 증명하지 못한다면 메인스트림이 바뀌기는 쉽지 않다.
결국 Next 폰 노이만이 필요한 시점이다.
소자만 알아서도 안 되고, 코딩만 알아서도 안 된다. 하드웨어의 물리적 특성을 완벽히 이해하면서, 동시에 그에 맞춰 AI 알고리즘을 밑바닥부터 뜯어고칠 수 있는 사람. 판을 아예 다시 짤 수 있는 융합형 인재가 이 난제를 해결할 것이다.
6. SDLA의 연구 정체성: Silicon & Full-Stack
AI 소자를 연구하는 곳은 많다. SDLA의 차별점은 "실제 산업 표준인 '실리콘(Si)' 기반의 소자"를 연구한다는 점이다.
실리콘은 이종호 교수님(SMDL)의 표현을 빌리자면 '신의 선물'이라고 할 수 있을 정도로 완벽에 가까운 장점을 가진 재료다. 강의 때마다 교수님의 '실리콘 찬양'을 듣게 되는 이유이기도 하다. 무엇보다 가장 강력한 무기는 기존 CMOS 공정 인프라와 노하우를 그대로 활용할 수 있다는 점이다.
학계에서는 산화물 반도체(Oxide), 유리 기판, 유연(Flexible) 소자 등 다양한 신소재 연구가 활발하다. 하지만 양산성과 신뢰성 측면에서 '실리콘의 벽'을 넘기는 쉽지 않은 것이 현실이다. 전 세계 반도체 시장의 90% 이상이 실리콘 기반으로, TSMC나 삼성전자의 Fab이 전부 실리콘 공정에 맞춰져 있기 때문에, 실리콘 기반으로 개발된 소자는 즉시 양산 적용(Scale-up) 검토가 가능하다. 반면, 아무리 성능이 좋은 신소재라도 전용 생산 라인을 새로 깔아야 한다면 상용화 가능성은 급격히 낮아진다. 따라서 SI 기반 소자는 현실적이고 강력한 베이스이다.

또한 SDLA는 Full-Stack 연구를 지향한다.
회사는 설계, 공정, 소자, 분석 팀이 모두 분업화되어 있다. 하지만 이곳에서는:
- Problem Definition: 문제를 정의하고 가설 설정, 소자 설계
- Design & Fabrication: 서울대 반도체공동연구소(ISRC)에서 방진복을 입고 직접 공정 진행
- Measurement & Analysis: 결과 측정 및 피드백
소자 하나가 나오는 데 보통 1년이라는 긴 시간이 걸린다. 하지만 이 긴 호흡의 사이클을 온전히 내 손으로 컨트롤해 보는 경험은, 훗날 어떤 필드에 나가더라도 엔지니어로서 대체 불가능한 자산이 될 수 있다.
SDLA는 서울대 반도체공동연구소(ISRC)의 창립 멤버이신 이종덕 교수님부터 시작해, 과기부 장관을 역임하신 이종호 교수님(SMDL)으로 이어지는 30년 이상의 유서 깊은 연구실의 계보를 잇고 있다.
SK하이닉스와 삼성전자의 현직 사장단을 비롯해 국내에만 40명이 넘는 교수를 배출한 이 'SMDL 네트워크'는 반도체 씬에서 무시할 수 없는 거대한 자산이다. 정규원 교수님은 이종호 교수님의 제자로서, 논문들을 읽다보면 정규원 교수님의 박사과정 시절 무쌍(?)을 심심찮게 발견할 수 있다.
내가 느낀 연구실의 핵심 철학은 'Real Implementation(실제 구현/동작)'이다.
교수님께서는 면담 중에 이런 말씀을 하셨다.
"요즘 연구에 '뉴로모픽'이라는 양념만 뿌리는 식의 연구를 하는 사람이 많다.
정말로 이 문제를 해결하기 위해 실제 필요한 것이 무엇인지 치열하게 고민하는 사람은 많지 않은 것 같다."
이 말은 큰 울림을 주었다. 단순히 트렌드를 좇아 보여주기식 연구를 하는 것이 아니라, '진짜 문제'를 해결하는 연구를 해야 한다는 것. 나는 이 철학에 깊이 공감한다.
이종호 교수님이 바라보는 '뉴로모픽이 세상을 바꿀 것'이라는 강력한 비전(Vision)과, 정규원 교수님이 견지하는 '기존 소자와의 융합을 통한 현실적 해법'이라는 실용주의(Pragmatism).
나는 이 두 가지 시선을 모두 받아들이고 싶다. 뜬구름 잡는 소리가 아닌, 그렇다고 현실에만 안주하지 않는.
'연구를 위한 연구'가 아니라, 세상의 문제를 실제로 해결할 수 있는 연구자.
7. 연구자로서 갖춰야 할 태도
대학원 생활의 지침이 될 만한 조언들을 정리해 본다. 사실 이러한 조언들은 개인의 상황과 성향에 맞게 받아드리면 될 것 같다.
7.1 연구 주제의 선정.
대학원 생활 5~6년은 생각보다 길다. 단순히 지금의 트렌드라서 쫓아가는 것만으로는 그 긴 시간을 버티기 힘들다.
"내가 이 문제를 해결해서 세상에 어떤 기여를 하고 싶은가?"에 대한 스스로의 흥미와 확고한 철학이 있어야 지치지 않고 완주할 수 있다.
7.2. 성적표는 포트폴리오다
학부 성적표는 단순한 점수의 나열이 아니다. "내가 무엇에 관심이 있어서 어떤 테크트리를 탔는지"를 보여주는 포트폴리오다. 복수전공이든 부전공이든, 나중에 대학원이든 회사든 지원할 때 성적표는 나의 관심사와 성실함을 증명하는 가장 객관적인 자료가 된다.
과목을 선택할 때도 이 관점이 필요하다. '내가 남들에게 어떤 전문성을 가진 사람으로 보이고 싶은가?'를 고려하여 전략적으로 선택해야 한다.
- 수업: 전반적인 흐름을 훑고 학문적 베이스를 다지는 과정 (인증된 기록)
- 독학: 진짜 당장 필요해서 깊게 파야 하는 공부
수업은 때로 필요 없는 부분까지 외워야 하는 비효율적인 과정일 수 있다. 따라서 '보여주기 위한 기록'으로서의 수업과 '실질적인 실력 향상'을 위한 독학을 영리하게 구분할 줄 알아야 한다.
7.3. 설득의 기술 (Problem Finding & Selling)
연구의 핵심 역량은 세 가지다. 문제 발굴(Finding), 문제 해결(Solving), 그리고 설득(Selling).
공대에서는 문제를 푸는 법만 가르치지, 문제를 정의하고 남들에게 설명하는 법은 잘 가르치지 않는다. 정규원 교수님은 본인이 교수가 될 수 있었던 큰 이유 중 하나로 '독서'를 꼽으셨다. 꾸준한 독서를 통해 논리력을 키웠고, 덕분에 논문을 쓰거나 타인에게 내 논리를 설명하는 것이 상대적으로 수월했다고 한다.
"유기농 계란과 축사 계란의 영양성분은 사실 똑같다."
하지만 사람들은 '유기농'이라는 이미지와 스토리에 기꺼이 2배 비싼 값을 지불한다. 연구도 마찬가지다. 내가 푼 문제가 얼마나 가치 있는지, 남들을 설득하고 포장하는 능력(Marketing)이 없으면 빛을 보기 힘들다. 이를 위해서는 연구 설계 단계에서부터 큰 그림(Big Picture)을 그리는 연습을 해야 한다.
7.4. Coding + Physics
소자 하는 사람은 코딩을 싫어하고, 코딩하는 사람은 물리를 싫어한다. 둘 다 할 줄 아는 사람은 희소하다.
LLM의 발전으로 코딩의 기술적 장벽은 낮아졌다. 이제 중요한 건 관점이다. 물리를 아는 사람이 인공지능과 딥러닝에 대한 인사이트까지 갖춘다면 시너지가 날 것이다.
7.5. 대학원 이후의 진로: R vs D
결국 내가 하고 싶은 게 Research인가 Development인가?
남들이 가지 않은 길을 가며 가설을 검증하는 연구(Research)를 하고 싶은지, 아니면 기술을 고도화하여 제품을 만드는 개발(Development)을 하고 싶은지 개인적 성향의 관점에서 고민해보면 도움이 될 것이다.
Outro
뉴로모픽이나 AI 반도체라는 키워드가 트렌드라서 쫓는 것이 아니라, "내가 이 문제를 해결해서 세상에 어떤 기여를 할 것인가?"에 대한 철학을 가지고 연구에 임해야겠다.
명확한 방향이 없어 어렵지만 너무나 매력적인 분야이다.

좋은 글 잘 읽었습니다. 앞으로 다양한 인사이트 얻어가겠습니다.