"Attention Is All You Need."
간지나는 이름과 함께 세상을 뒤집어 놓은 논문이자, 현대 AI의 알파이자 오메가가 된 Transformer의 본질에 대해 고찰한다.
Presenter : 김현준 (doctor3390@snu.ac.kr)
1. 인공지능이란 무엇인가?
본론에 앞서 인공지능의 정의에 대해 생각해 보자.
"AI is whatever hasn't been done yet."
- Tesler's Theorem
인공지능을 명확히 정의하기는 어렵다. 그동안 기계가 해결하지 못했던 난제를 해결해 내는 것이 곧 인공지능이었다. Transformer 역시 당시 기계 번역(Translation)이라는 Task에서 기존의 한계를 뛰어넘기 위해 등장했다.
2. 기존 RNN 모델의 한계
문장은 단순한 단어 묶음이 아니라, 순서(sequence)에도 정보가 포함된다는 점에서 시계열 데이터의 성질을 띤다. 즉, 번역 같은 NLP Task를 Combinational이 아닌 Sequential Logic으로 처리하려는 접근은 공학적으로 매우 자연스러운 생각이었다.
그래서 초창기에는 RNN(LSTM 등) 기반 모델들이 주류를 이뤘다. 하지만 여기에는 크게 두 가지 치명적인 약점이 있었다.
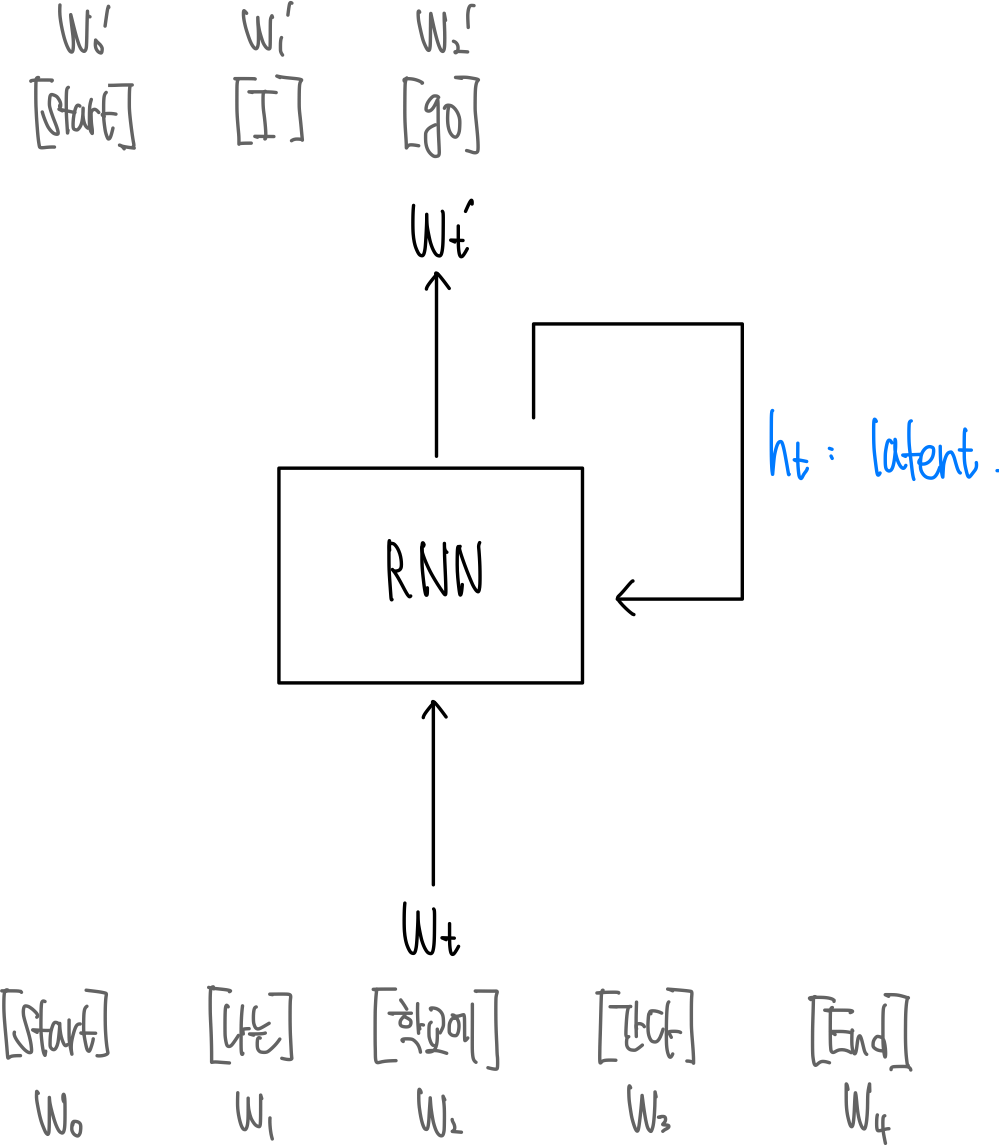 Translation with RNN
Translation with RNN
1) Long Term Dependency (장기 의존성 문제)
Latent vector가 입력 한 번마다 대략 배 감쇠한다고 가정해 보자. 번의 step이 지난 후, 초기 입력 단어의 정보는 배로 급격히 희석된다. (Vanishing Gradient)
즉, 문장의 맨 앞 단어가 문맥 이해에 결정적임에도 불구하고, 문장이 길어질수록 그 정보가 지수함수적으로 사라지는 것이다.
2) 느린 학습 속도 (Sequential Nature)
RNN은 순차적으로 데이터를 처리해야 한다. 개의 단어로 이루어진 문장을 학습하려면, 앞 단어의 계산이 끝나야 뒷 단어를 계산할 수 있다. 즉, 병렬 처리가 불가능하며 학습 시간 복잡도가 문장 길이에 비례한다. ()
3. 해결책: Attention
사실 Attention이라는 개념 자체는 이 논문 이전에도 존재했다 (Bahdanau et al., 2014). General 하게 Attention 이란, '주어진 Query에 대한 정보를 Value라는 Basis의 선형결합으로 다시 나타낸 것' 정도로 말할 수 있다.
하지만 이 논문은 기존의 복잡한 구조를 걷어내고, "Scaled Dot-Product Attention"이라는 간결한 방식을 제안하며 패러다임을 바꿨다.
직관적으로 해석해 보자.
- Query (): 내가 찾고자 하는 단어 (질의)
- Key (): 사전의 색인 (Label)
- Value (): 사전의 내용 (Actual Content)
- Dimension of Key (): 색인 벡터의 차원
우선 Scaled의 의미를 살펴보자. 수학적으로 내적을 하게 되면 차원이 커질수록 값의 분산(Variance)이 커지면서, Softmax가 한쪽으로 극단적으로 쏠리는 현상이 발생한다. 이를 방지하기 위해 로 나누어 정규화(Normalization)해 준 것이다.
는 두 벡터의 내적, 즉 유사도(Similarity)를 구하는 과정이다. 이를 Softmax에 통과시키면 '어떤 단어(Value)에 얼마나 집중(Attention)해서 정보를 가져올 것인가'에 대한 확률 분포가 나온다.
말하자면 "입력된 단어()가 자신과 연관된 를 찾아내고, 그에 해당하는 라는 기저(Basis)들의 조합을 통해 보다 추상적인 의미 공간(Latent Space)으로 자신을 재구성(Projection)하는 과정"이라고 할 수 있다.
이것은 실제 인간의 이해와도 맞닿아 있을 수 있다.
"무언가를 이해한다"는 것은 "대상을 표현할 수 있는 적절한 기저(Basis)를 찾아내는 행위"와 같다.
동일한 정보 공간(Space)을 Span한다고 가정했을 때, 더 뛰어난 이해력을 가진 사람은 다음과 같은 특징을 가진 기저 집합을 찾는다.
1. Compact: 더 적은 수의 기저만으로 대상을 설명한다. (압축 효율성)
2. Orthogonal: 기저들이 서로 독립적이다. (개념의 명확한 분리)
즉, 좋은 이해를 한다는 것은 "더 적은 메모리를 이용해 더 빠르게 세상을 recall 할 수 있는 '최적의 기저'를 갖추게 된다"는 뜻이다.
(이것이 곧 이해와 지능의 본질이다 라는 것이 본 세미나에서 몇 번에 걸쳐 논의된 것으로 이와 관련한 보다 자세한 이야기는 추후에 별도 포스트에서 다루도록 한다.)
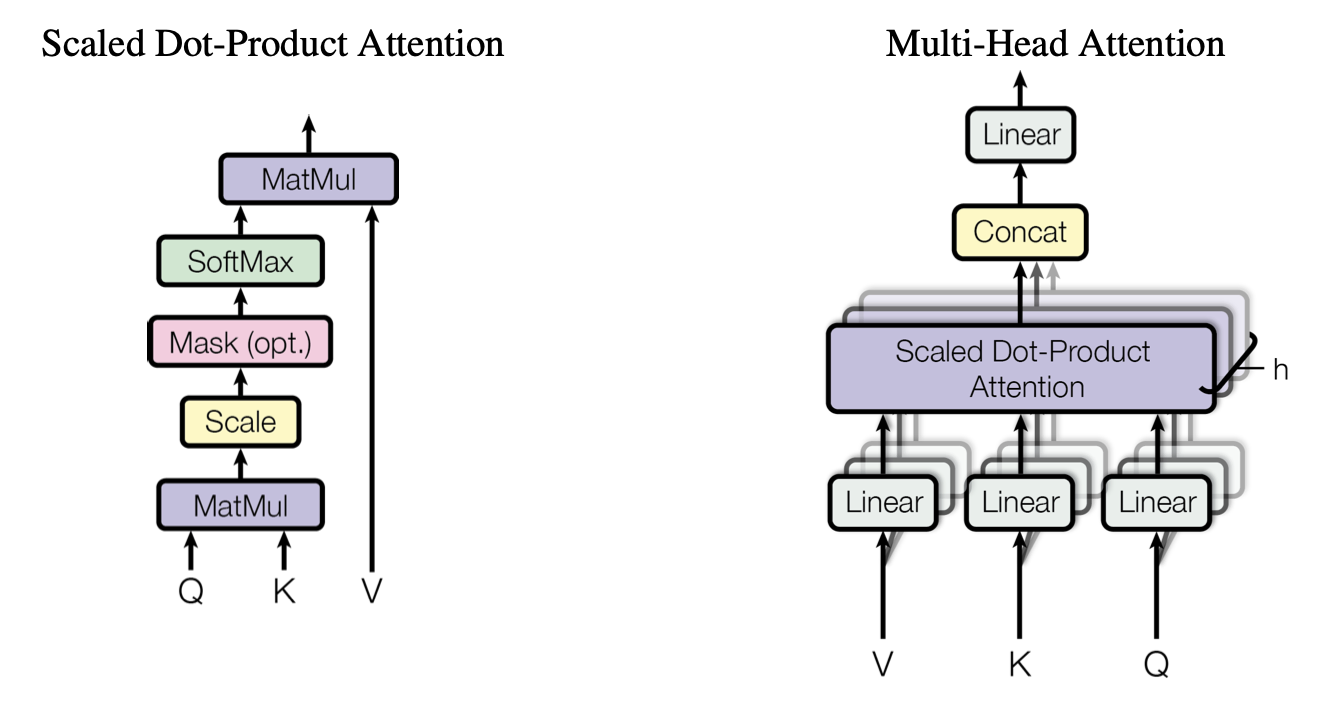 Figure 2: (left) Scaled Dot-Product Attention. (right) Multi-Head Attention
Figure 2: (left) Scaled Dot-Product Attention. (right) Multi-Head Attention
Attention 메커니즘이 를 설명하기 위한 최적의 기저()를 찾는 과정이라고 했다.
하지만, 복잡한 세상의 정보를 단 하나의 기저 집합만으로 완벽하게 설명할 수 있을까?
논문에서는 Multi-Head Attention을 도입하여 이 문제를 해결한다.
말 그대로 Attention을 여러 번(번) 병렬로 수행하는 것이다.
이것의 의미는 직관적으로 "대상을 다양한 관점(Multiple Perspectives)에서 해석하겠다"는 것이다.
예컨대 같은 문장을 보더라도 어떤 Head는 문법적 구조(Syntactic)에 집중하고, 어떤 Head는 의미적 관계(Semantic)에, 또 다른 Head는 시제나 화자에 집중하는 식이다.
마치 장님이 코끼리를 만질 때, 다리를 만지는 사람, 코를 만지는 사람, 귀를 만지는 사람의 정보를 모두 합쳐야(Concat) 비로소 온전한 코끼리의 형상이 나오는 것과 같다.
즉, 서로 다른 부분 공간(Subspace)으로 정보를 투영시켜, 정보의 입체성을 확보하는 전략이다.
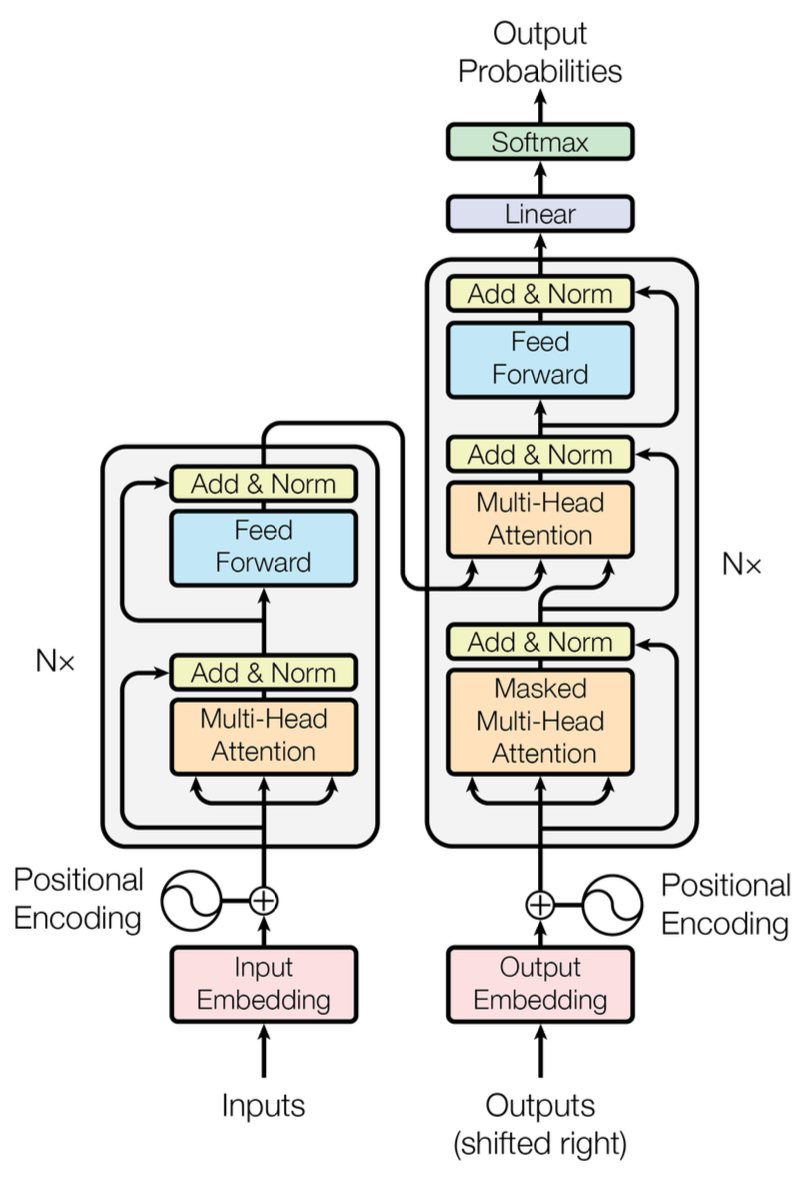
4. Transformer의 작동 원리
Transformer는 이 Attention을 겹겹이 쌓은 구조다.
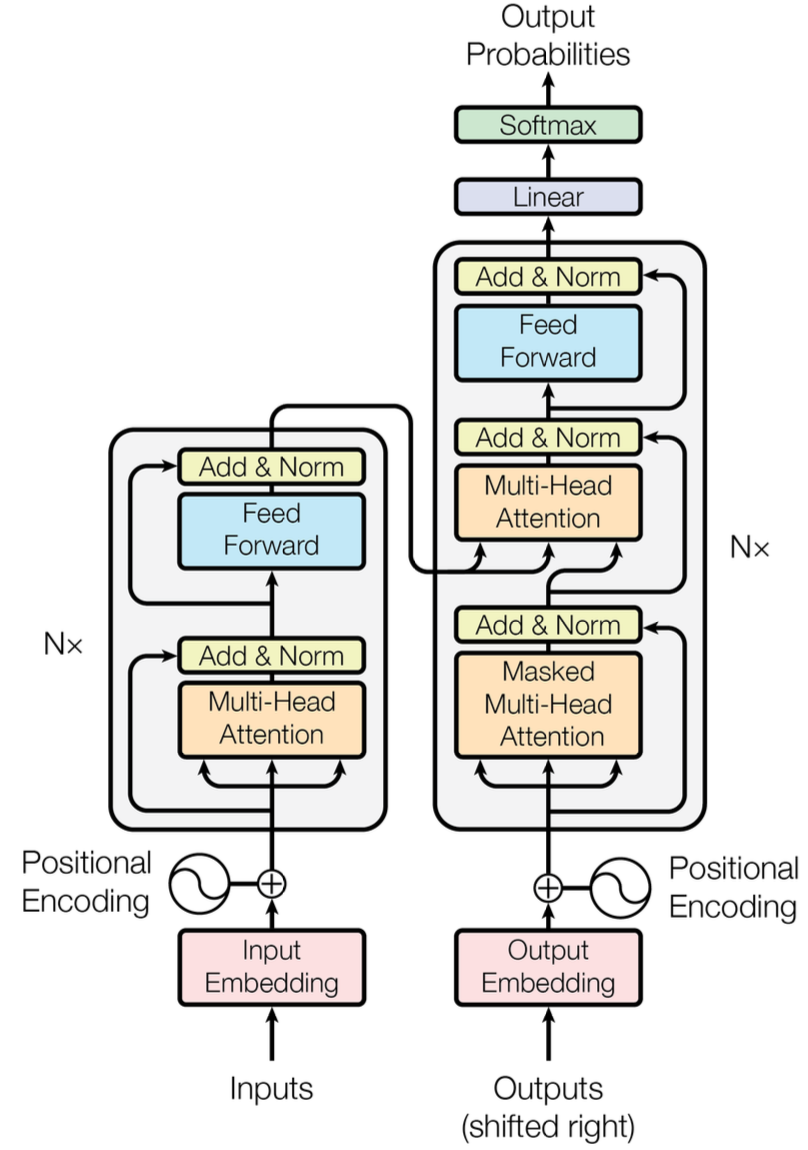 Figure 1. The Transformer - model architecture
Figure 1. The Transformer - model architecture
1. Encoder (Left): 이해의 과정
- Self-Attention: 한국어 문장(Source) 전체를 한 번에 입력받는다. 단어들 간의 관계를 파악하여, 이를 문맥이 반영된 '의미 공간상의 벡터(Latent Vector)'로 변환한다. ( 모두 원문에서 유래)
2. Decoder (Right): 생성의 과정
- Masked Self-Attention: 현재까지 생성된 영어 단어들만을 보며 문맥을 파악한다. (미래의 정답 단어를 미리 보는 것을 막기 위해 가림막(Mask)을 씌운다.)
- Encoder-Decoder Attention: Decoder가 (현재 작성 중인 문장)를 던지면, Encoder가 (원문의 맥락)를 제공한다. 즉, "내가 지금 이런 문장을 쓰고 있는데, 원문에서 어떤 부분을 참고하면 될까?"를 물어보는 과정이다. ( 생성의 과정)
3. Positional Encoding: 순서를 주입하다
예리한 사람이라면 여기서 의문을 가질 것이다.
Attention 메커니즘은 입력을 병렬로 처리하기 때문에 본질적으로 순서 정보(Sequence)를 인지하지 못한다. (마치 순서가 없는 집합(Set)과 같이 동작함)
따라서 Transformer는 입력 임베딩에 위치 정보를 강제로 주입하는 방식을 택했다.
단어 벡터에 고유한 주파수를 가진 사인/코사인(Sin/Cos) 파동값을 더해줌으로써, 위치 정보(Bias)를 심어주는 것이다.
기존 한계의 극복 (Why Transformer?)
이제, 이 구조가 어떻게 RNN의 고질적인 문제들을 해결했는지 확인해 보자.
1) Long Term Dependency 해결 (정보 손실 직접 연결)
Encoder는 문장의 모든 단어를 동시에 바라본다(Attention). 이 과정에서 문장의 맨 앞 단어와 맨 뒤 단어가 물리적 거리에 상관없이 행렬 연산을 통해 직접 연결(Direct Connection)된다.
즉, 거리가 멀어질수록 정보가 희석되던 RNN과 달리, Transformer는 긴 문맥도 손실 없이 완벽하게 파악할 수 있다.
2) 학습 속도 문제 해결 (순차 처리 병렬 처리)
RNN은 앞 단어의 계산이 끝나야 뒷 단어를 계산할 수 있는 순차적(Sequential) 구조였다.
반면 Transformer는 학습 단계에서 정답을 이미 알고 있으므로, Masking을 통해 전체 문장을 하나의 거대한 행렬로 만들어 병렬적(Parallel)으로 처리한다. 문장 길이에 비례하던 연산 제약이 사라지며 학습 속도가 비약적으로 향상되었다.
5. GPT와 BERT: 생성과 이해
Transformer의 성공 이후, AI 연구의 핵심은 "답지(Label)가 없는 데이터로 학습이 가능한가?"라는 질문으로 옮겨갔다.
인터넷상에는 한국어-영어 정답 쌍은 부족하지만, 단순히 글자만 적혀 있는 데이터, 즉 말뭉치(Corpus)는 사실상 무한하게 존재한다. 이 방대한 Corpus 자체를 학습에 이용할 수 있다면, 그 잠재가치는 엄청나다.
이 아이디어를 기반으로 거대 언어 모델의 양대 산맥이 탄생했다.
-
BERT (Google): Transformer의 Encoder 구조를 활용. 문장의 중간을 가리고 맞추는 "빈칸 채우기(Masked LM)"를 학습한다. 문맥을 양방향(Bidirectional)으로 파악하므로 문장의 이해(Understanding)에 강점이 있다.
-
GPT (OpenAI): Transformer의 Decoder 구조를 활용. 이전 단어들을 보고 "다음 단어 맞추기(Next Token Prediction)"를 학습한다. 문장을 생성(Generation)하는 데 특화되어 있다.
GPT의 진화: "Scale is All You Need"
특히 OpenAI는 "다음 단어 예측"이라는 단순한 과제에 담긴 거대한 가능성에 주목하고, 모델을 단계적으로 진화시켰다.
- GPT-1 (Insight): 모델 끝단에 긍/부정 판독기를 달아 실험한 결과, 별도의 지도 학습 없이도 문장을 훌륭하게 분류해냈다. 이는 "다음에 올 단어를 정확히 예측하려면, 이미 문장 전체의 의미를 이해하고 있어야 한다"는 사실을 증명한 것이다.
- GPT-2 (Hypothesis): 별도의 튜닝 없이 "Task Description + Context"만 던져줘도 그럴듯한 답변을 생성함을 확인했다. 연구진은 지능이 알고리즘의 복잡도가 아닌 "모델의 크기(Scale)와 데이터의 양"에 비례할 수 있다는 가설을 세운다.
- GPT-3 (Revolution): 가설을 검증하기 위해 파라미터를 무려 100배 이상 키웠고, 그 결과 모델은 인간 수준의 유창함을 보여주며 현재 LLM 혁명의 시발점이 되었다.
6. Transformer의 효율성에 대한 고찰
오늘 세미나의 핵심 질문 "도대체 Transformer는 왜 이토록 강력한가?"
공학적인 관점에서 Transformer는 RNN의 시간 복잡도(Time Complexity)를 공간 복잡도(Space Complexity)와 맞바꾼 거래다.
순차 처리를 없애기 위해 거대한 행렬()을 메모리에 올리는 방식을 택했고, 이는 필연적으로 모델의 사이즈를 거대하게 만들었다.
하지만 단순히 "몸집을 키워서" 잘하는 것일까? 그렇다면 과거의 거대 MLP 모델들은 왜 실패했는가?
앞서 Attention을 설명하면서 이것이 인간의 이해의 메커니즘을 모사한 것이기 때문일 수 있다는 이야기를 했다.
또 하나의 흥미로운 점은 Transformer의 핵심인 Softmax 함수가 통계역학의 볼츠만 분포와 형태적으로 동치라는 것이다.
자연(Nature)은 언제나 에너지를 최소화하고 엔트로피를 최대화하는 방향(Free Energy Minimization)으로 움직인다. 볼츠만 분포는 입자가 특정 에너지 상태에 존재할 확률을 나타내는 자연의 가장 근본적인 법칙이다.
Transformer가 학습하는 과정은 Loss(에너지)를 최소화하는 방향으로 가중치를 업데이트하는 과정이다.
어쩌면 Transformer가 언어를 그토록 잘 이해하는 이유는, 이 모델의 근간이 되는 수식이 자연계가 정보를 처리하고 평형 상태를 찾아가는 물리적 법칙과 맞닿아 있기 때문일 수 있다.
이러한 Energy-based Model 관점에서의 해석은 next AI (Tesler's Theorem) 연구를 위한 중요한 단서가 될 수 있다.
이 이상은 대외비로 공개하지 않는다. 컴퓨팅이 무엇인가?, 자연은 거대한 아날로그 컴퓨터인가? 에 대한 흥미로운 이야기들도 세미나에서 논의된 바 있다
김현준 (doctor3390@snu.ac.kr)
김희민 (heemin0924@snu.ac.kr)
박정민 (1348jungmin@snu.ac.kr)
최재현 (kmnops0920@snu.ac.kr)
