시각지능
Object Detection
예시 : 자율 주행, 스포츠, 의료, 군사 등
Object Detection이란?
Classification + Localization
Multi-Labeled Classification + Bounding Box Regression
주요 개념
-
Bounding Box
하나의 object가 포함된 최소 크기 박스, 즉 위치 정보

-
Class Classification
Object가 Bounding Box 안에 있는지, 이에 대한 확신의 정도
Confidence Score가 1에 가까울수록 object가 있다고 판단하며 0에 가까울수록 없다고 판단한다. (모델에 따라 계산이 다름)
-
IOU(Intersection over Union)
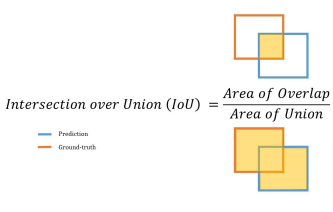
두 박스의 중복 영역 크기를 통해 측정
- 겹치는 영역이 넓을수록 좋은 예측
- 0~1 사이의 값 값이 클수록 좋은 예측
-
NMS(Non-Maximum Suppression)
동일 Object에 대한 중복 박스 제거
-
Precision, Recall, AP, mAP
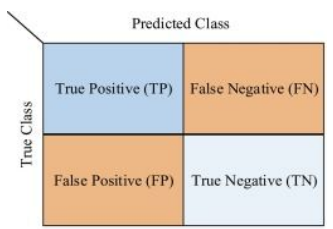
- Precision
-TP/(TP+FP)
-모델이 Object라 예측한 것 중 실제 Object의 비율
- Recall
-TP/(TP+FN)
-실제 Object중 모델이 예측하여 맞춘 Object의 비율
Precision-Recall Curve
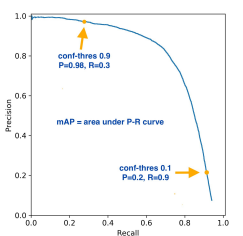
- Precision과 Recall을 모두 감안한 지표
- Average Precision: 그래프 아래의 면적
- mean Average Precision: 각 클래스 별 AP를 합산하여 평균을 낸 것
-
Annotation
이미지 내 Detection 정보를 별도의 설명 파일로 제공되는 것
VOC, COCO, ImageNet, Open Images 등이 있음
YOLO v8
Quick Manual
#라이브러리 설치
!pip install ultralytics
#라이브러리 불러오기
from ultralytics import YOLO
#모델 선언()
model = YOLO()
#모델 학습
model.train()
#모델 검증
model.val()
#예측값 생성
model.predict()
Keras로 CNN 활용하기
import os
os.environ['BACKEND'] = 'tensorflow' ## PyTorch, JAX도 가능
import keras # 케라스 불러오기
CIFAR-10
-
32 X 32 X 3의 해상도의 사물 데이터를 모아 놓은 데이터 세트
-
CIFAR-10 데이터 세트는 10개의 클래스로 구성
-
학습 데이터 50,000개, 테스트 데이터는 10,000개
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import keras
(train_x, train_y), (test_x, test_y) = keras.datasets.cifar10.load_data()
labels = {0: 'Airplane',
1: 'Automobile',
2: 'Bird',
3: 'Cat',
4: 'Deer',
5: 'Dog',
6: 'Frog',
7: 'Horse',
8: 'Ship',
9: 'Truck',
}
Modeling 1
import keras
from keras.utils import clear_session
from keras.models import Sequential
from keras.layers import Input, Dense, Flatten
# 1. 메모리 청소
clear_session()
# 2. 모델 선언 : 리스트 안에 추가하는 방식
model1 = Sequential([Input(shape=(32,32,3)),
keras.layers.Rescaling(1/255),
Flatten(),
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(128, activation='relu'),
Dense(128, activation='relu'),
Dense(256, activation='relu'),
Dense(256, activation='relu'),
Dense(10, activation='softmax'),
])
# 3. 레이어 블록 조립 : .add() 방식
# model1.add( Input(shape=(32,32,3)) )
# model1.add( keras.layers.Rescaling(1/255) )
# model1.add( Flatten() )
# model1.add( Dense(64, activation='relu'))
# model1.add( Dense(64, activation='relu'))
# model1.add( Dense(128, activation='relu') )
# model1.add( Dense(128, activation='relu') )
# model1.add( Dense(256, activation='relu') )
# model1.add( Dense(256, activation='relu') )
# model1.add( Dense(10, activation='softmax') )
# 4. 컴파일
model1.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model1.summary()
from keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss', # 얼리스토핑을 적용할 관측 지표
min_delta=0, # 임계값
patience=5, # 성능 개선이 발생하지 않았을 때, 몇 epochs 더 지켜볼 것인지
verbose=1, # 몇 번째 epochs에서 얼리스토핑이 되었는가 알려줌
restore_best_weights=True # 최적의 가중치를 가진 epoch 시점으로 가중치를 되돌림
)
model1.fit(train_x, train_y, validation_split=0.2,
epochs=10000, verbose=1,
callbacks=[es]
)
y_pred = model1.predict(test_x)
model1.evaluate(test_x,test_y)Modeling 2
# 2. 모델 선언 : 리스트 안에 넣는 방식
model2 = Sequential([Input(shape=(32,32,3)),
keras.layers.Rescaling(1/255),
Conv2D(filters=64, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
Conv2D(filters=64, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
MaxPool2D(pool_size=(2,2),# pooling 필터의 가로 세로 사이즈
strides=(2,2) # pooling 필터의 이동 보폭 (기본적으로 pool_size를 따름)
),
Conv2D(filters=128, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
Conv2D(filters=128, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
MaxPool2D(pool_size=(2,2),# pooling 필터의 가로 세로 사이즈
strides=(2,2) # pooling 필터의 이동 보폭 (기본적으로 pool_size를 따름)
),
Conv2D(filters=256, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
Conv2D(filters=256, # 서로 다른 필터 64개를 사용하겠다.
kernel_size=(3,3), # Conv2D 필터의 가로 세로 사이즈
strides=(1,1), # Conv2D 필터의 이동 보폭
padding='same', # 1.feature map 사이즈 유지 | 2.외곽 정보 더 반영
activation='relu', # 주의!
),
MaxPool2D(pool_size=(2,2),# pooling 필터의 가로 세로 사이즈
strides=(2,2) # pooling 필터의 이동 보폭 (기본적으로 pool_size를 따름)
),
Flatten(),
Dense(10, activation='softmax')
])
# 3. 컴파일
model2.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model2.summary()
훈련 및 예측 방식은 동일

데이터 분석가