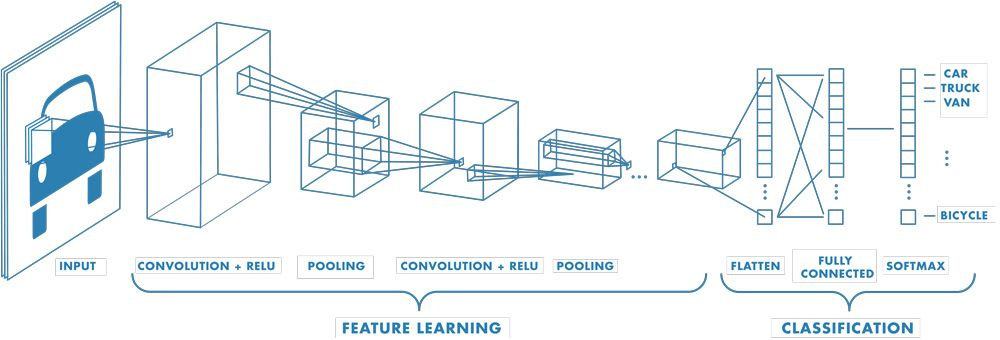
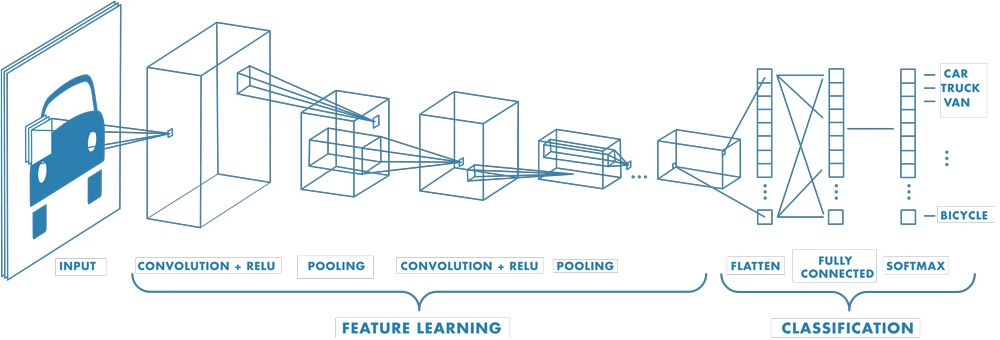
CNN의 작동 방식
Convolutional neural network는 수백 개의 계층을 가질 수 있으며 각 계층은 영상의 서로 다른 특징을 검출합니다.
서로 다른 해상도의 필터가 적용되고, 컨벌루션된 각 영상은 다음 계층의 입력으로 사용됩니다. 필터는 밝기, 경계와 같은 매우 간단한 특징에서 객체를 고유하게 정의하는 특징으로 복잡도를 늘려갈 수 있습니다.
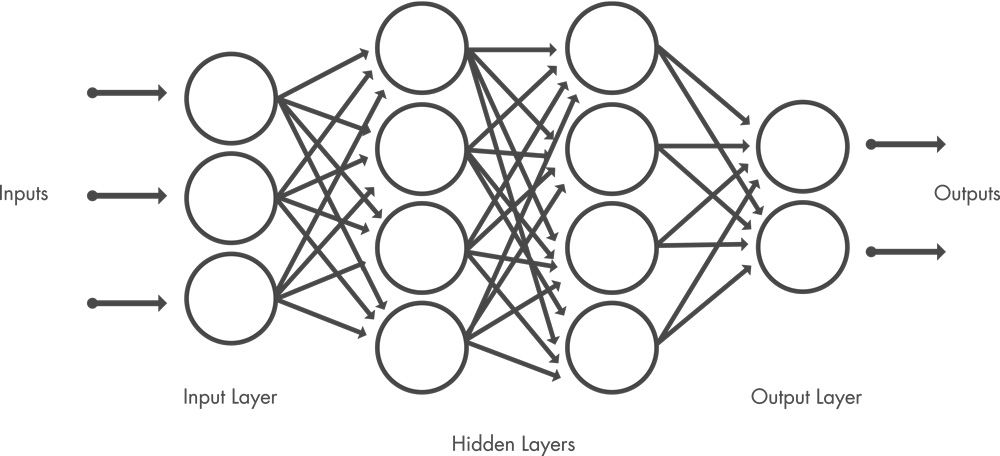
공유 가중치 및 편향
전통적인 신경망과 달리, CNN에는 주어진 계층의 모든 은닉 뉴런에 대해 동일한 공유된 가중치 및 편향 값이 있음
분류 계층
CNN 아키텍처는 여러 계층에 있는 특징을 학습한 후 분류 계층으로 넘어갑니다
마지막에는 두 번째 계층은 K차원의 벡터를 출력하는 완전 연결 계층이며(K는 예측 가능한 클래스의 개수)분류되는 영상의 각 클래스에 대한 확률을 포함합니다.
CNN의 중요성
영상 및 시계열 데이터에서 주요 특징을 찾아내고 학습하기 위한 최적의 구조를 제공하며 다음과 같은 기술에 활용될 수 있습니다.
의료 영상
오디오 처리
객체 검출
합성 데이터 생성
이번 수업에서는 객체 검출파트를 keras를 이용해서 할 수 있음
기본적인 코드 구조
'''
clear_session()
model = Sequential([Conv2D(16, kernel_size = 3, input_shape=(28, 28, 1),
padding='same', activation='relu'), # strides = 1(기본값,1)
MaxPooling2D(pool_size = 2 ), # strides = 2(기본값이 pool_size 동일)
Flatten(),
Dense(10, activation='softmax')
])
model.summary()
model.compile(optimizer=Adam(learning_rate=0.001), loss='sparse_categorical_crossentropy')
'''
