sprint-CloudWatch
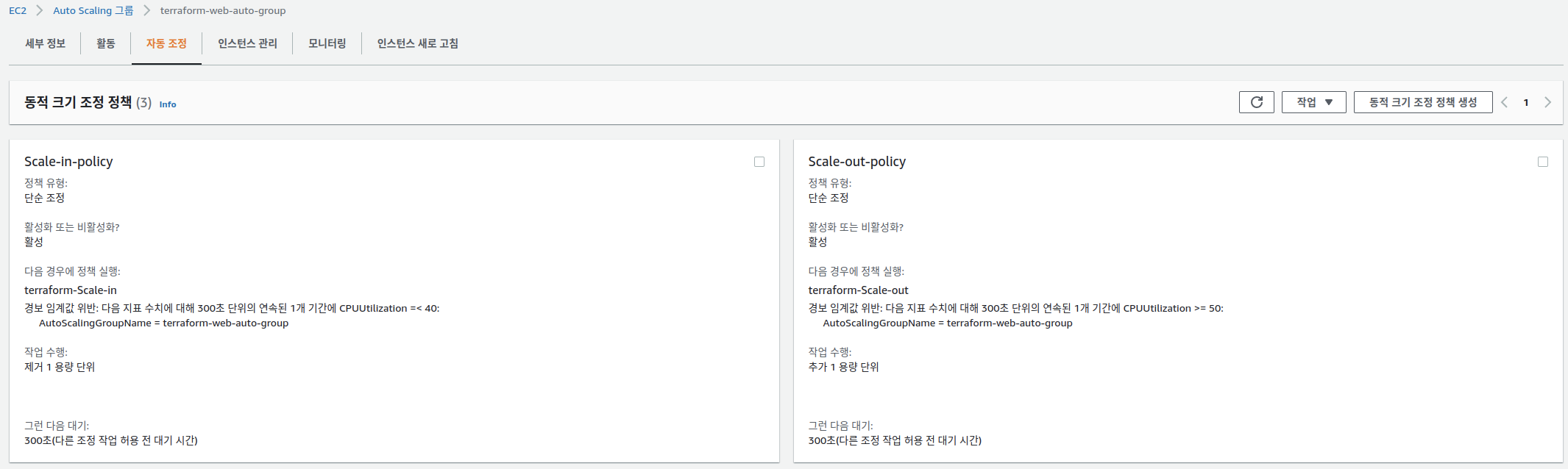
갑작스러운 트래픽 증가에 대응하기 위해서는, 서버의 주요 메트릭을 모니터링하고, 특정 메트릭이 임계치를 넘을 때, 수평 확장이 자동으로 진행되게 하는 것이 바람직합니다. 우리는 이미 앞서 AWS를 통해 이러한 서비스를 제공하는 Auto Scaling Group (이하 ASG)에 대해 배웠습니다. 스프린트를 통해 ASG의 원리를 익히고, 메트릭에 따른 스케일링 정책을 세우고 모니터링을 통해 정책이 적용되는지 확인해봅시다.
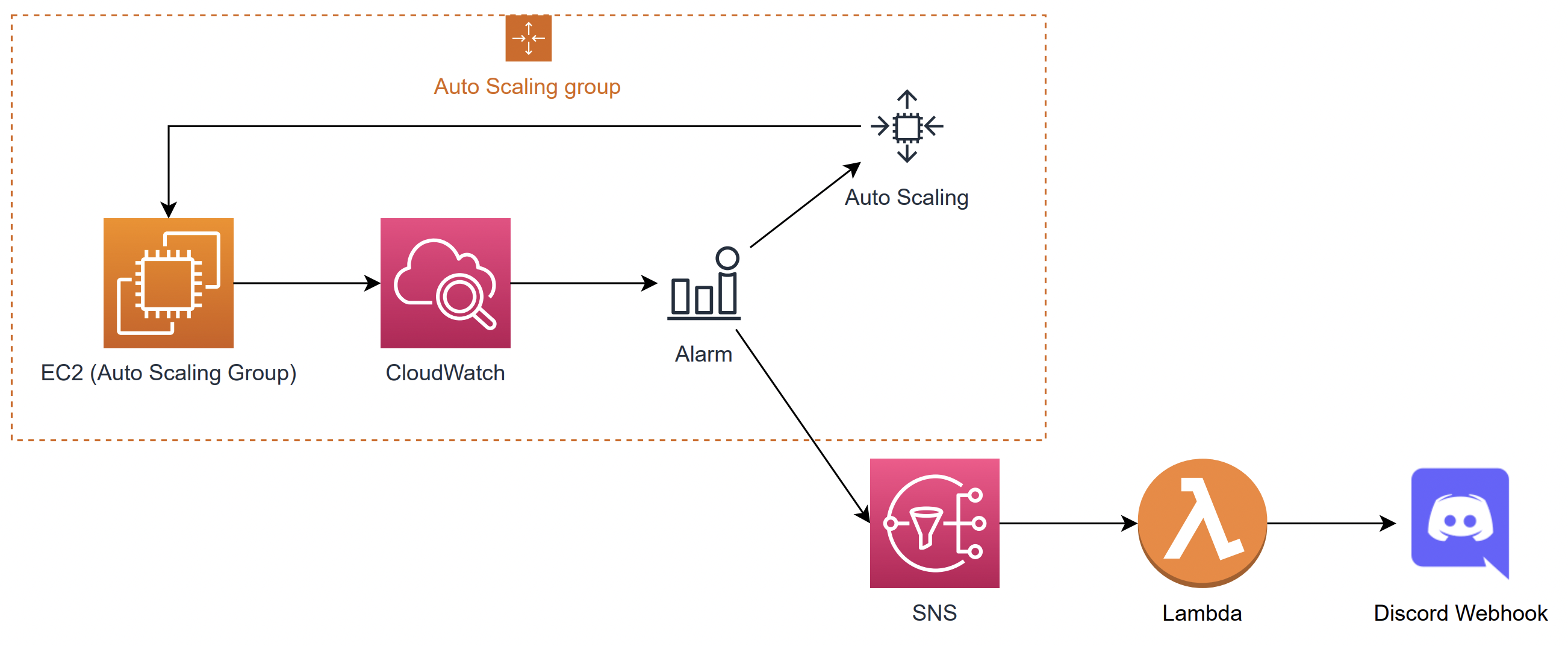
추가적으로 모니터링을 통해 모든 지표를 항상 관찰할 수 없으므로, 주요 메트릭의 임계치, 또는 장애 발생 예상 시점(예를 들어, CPU 사용량이 80%에 도달할 경우)을 경보의 형태로 제공해야 합니다. 이를 기존에 익혔던 SNS 및 람다를 통해 구현해봅시다.
step 1
테라폼으로 vpc, launch-template, autoscaling, user-data ...
terraform init
terraform applystep 2
AWS console에서 경보생성
AWS 경보생성 hands-on
지표선택 CPUUtilization
지표 및 조건 지정 p95
CloudWatch 통계 정의 참조
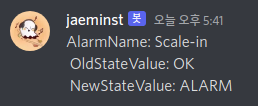
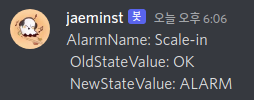
Scale-in 조건: CPU 40% 이하
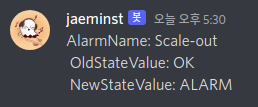
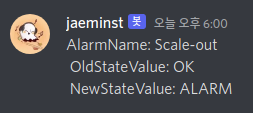
Scale-out 조건: CPU 50% 이상
지표수집기간 5분
경보상태 SNS 주제 생성
생성시 email 아무거나..(필요없으나 여기서 생성시 필수항목)
경보생성 완료
step 3
Lambda 함수 생성
런타임 python 3.x
블루프린트 cloudwatch-alarm-to-slack-python 기반 코드작성됨.
code: urclass 참조 후 username부분 자기이름으로 수정 (참고: username=봇이름)
환경 변수 등록
| KEY | VALUE |
|---|---|
| HOOK_URL | https://discord.com/api/webhooks/*********1336/*********ywwhZYq57yd0x.... |
트리거에 sns 연결
step 4
ec2 연결
session-manager가 없으신분들은 아래와 같이 수동변경 하거나, 테라폼의 시작템플릿에 key_name: "MyKeyPair" 등록
-
시작템플릿에서 편집 - 새로운버전 생성 - pem 사용체크
-
오토스케일링에서 인스턴스 새로고침 - 새로고침 시작 - 일치 건너띄기 체크해제 - 원하는구성 시작 템플릿 업데이트 체크 - 인스턴스 새로고침 시작(5분정도 걸림)
-
ec2 연결 후
stress -c 1 --timeout 300s입력