1. CPU와 컴파일러에서의 명령어 재배치
1.1. 느림보 메모리
- CPU는 RAM에서 데이터를 읽어 오는데 이들은 물리적으로 떨어져있기 때문에 많은 시간이 걸림
- 따라서 CPU의 입장에선 데이터를 읽어오는동안 아무 것도 못하기 때문에 손해임
1.2. 캐시
- 위의 문제를 해결하기 위해 cpu안에 조그마한 메모리를 넣어둔 것
- cpu에서 연산을 수행하는 부분과 거의 붙어있어 읽기/쓰기 속도가 매우 빠름
- 캐시를 사용한 연산 처리 과정
- cpu가 특정 주소에 있는 데이터에 접근하려 함
- 캐시에 있는지 확인
- 캐시에 있다면 해당 값을 읽음(Cache hit)
- 없다면 메모리까지 갔다옴(Cache miss)
- 캐시의 작동 방식
- 메모리를 읽으면 일단 캐시에 저장
- 만약 캐시가 다 찼다면 특정한 방식에 따라 처리(LRU 와 같은 방법을 사용)
- 캐시를 이해한 코드 작성
- 두 코드 중 속도가 빠른 코드는 아래 코드임: 자주쓰는 데이터가 캐시에 오래동안 저장되기 때문
<1번 코드>
<2번 코드>for (int i = 0; i < 10000; i++) { for (int j = 0; j < 10000; j++) { s += data[j]; } }for (int j = 0; j < 10000; j++) { //j가 밖에 for (int i = 0; i < 10000; i++) { s += data[j]; } }
- 두 코드 중 속도가 빠른 코드는 아래 코드임: 자주쓰는 데이터가 캐시에 오래동안 저장되기 때문
1.3. 명령어 재배치
- 컴파일러는 우리의 코드를 어셈블리어로 생성한 뒤 명령어를 재배치함
- 이는 현대의 CPU가 한 번에 한 명령어씩 실행하지 않기 때문
CPU 파이프라이닝(pipelining)
-
한 작업이 끝나기 전에, 다음 작업을 시작하는 방식으로 동시에 여러개의 작업을 동시에 실행하는 것
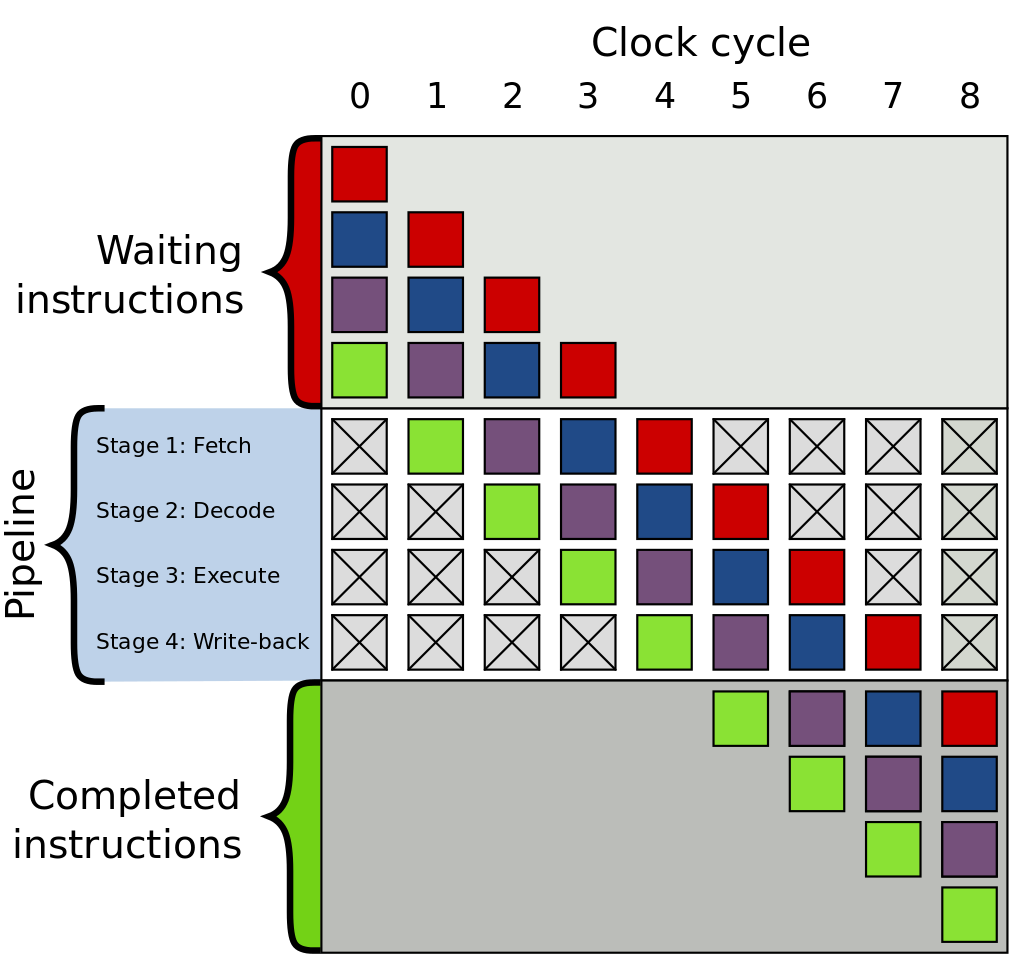
-
CPU에서 명령어를 실행할 때 여러 단계를 거침
- 명령어 읽기
- 명령어 해석
- 명령어 실행
- 결과 쓰기
-
위 단계의 실행 속도는 명령어마다 천차 만별임
- 따라서, 컴파일러는 우리가 어떠한 최대한 CPU의 파이프라인을 효율적으로 활용할 수 있도록 명령어를 재배치하게 됨
-
컴파일러는 명령어를 재배치할 때, 다른 쓰레드들을 고려하지 않아 멀티 쓰레드 환경에서 예상치 못한 결과가 나올 수 있음
1.4. 수정 순서
- 해당 객체의 값의 변화를 기록한 것(수정 순서는 재배치되지 않음!)
- 모든 쓰레드에서 변수의 수정 순서에 동의한다면, 문제될 것이 없음

- 모든 쓰레드에서 변수의 수정 순서에 동의한다면, 문제될 것이 없음
2. 원자성
- cpu가 명령어 1개로 처리하는 명령으로, 중간에 다른쓰레드가 끼어들 여지가 전혀 없는 연산
- 원자적인 연산이 아닌 경우에는 모든 쓰레드에서 같은 수정 순서를 관찰할 수 있음이 보장되지 않기에 직접 적절한 동기화 방법을 통해서 처리해야 함
- c++에서 제공하는 원자적 연산은 올바른 연산을 위해 뮤텍스를 필요로 하지 않기 때문에 빠른 속도로 처리가능
- 예제 코드
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
void worker(std::atomic<int>& counter) {
for (int i = 0; i < 10000; i++) {
counter++;
}
}
int main() {
std::atomic<int> counter(0);
std::vector<std::thread> workers;
for (int i = 0; i < 4; i++) {
workers.push_back(std::thread(worker, ref(counter)));
}
for (int i = 0; i < 4; i++) {
workers[i].join();
}
std::cout << "Counter 최종 값 : " << counter << std::endl;
}- 실행 결과
Counter 최종 값 : 40000
std::atomic<int> counter(0);atomic의 템플릿 인자로 원자적으로 만들고 싶은 타입을 전달- 위의 경우 0으로 초기화 된 원자적 변수를 정의
- counter가 원자적 변수이기 때문에
counter++이 뮤텍스의 보호를 받지 않아도 수행 중 다른 쓰레드가 실행되지 않음 - 컴파일러가 해당 연산을 여러줄이 아닌 한줄로 나타냈기 때문
- 즉, 원자적인 코드를 생성할 수 있기 때문
atomic객체의 연산들이 정말 원자적으로 구현 가능한지 확인하기 위해선is_lock_free()함수를 호출하면 됨
실행 결과:std::atomic<int> x; std::cout << "is lock free ? : " << boolalpha << x.is_lock_free() << std::endl;Is lock free ? : true
이때 lock은 뮤텍스에서 사용되는 의미가 아니라 원자적임을 의미
3. memory_order
atomic객체들의 경우 원자적 연산 시에 메모리에 접근할 때 어떤 방식으로 접근 하는지 지정 가능
3.1. memory_order_relaxed
- 가장 느슨한 조건
- 주위의 다른 메모리 접근들과 순서가 바뀌어도 무방
- 예제 코드
#include <atomic>
#include <cstdio>
#include <thread>
#include <vector>
using std::memory_order_relaxed;
void t1(std::atomic<int>* a, std::atomic<int>* b) {
b->store(1, memory_order_relaxed); // b = 1 (쓰기)
int x = a->load(memory_order_relaxed); // x = a (읽기)
printf("x : %d \n", x);
}
void t2(std::atomic<int>* a, std::atomic<int>* b) {
a->store(1, memory_order_relaxed); // a = 1 (쓰기)
int y = b->load(memory_order_relaxed); // y = b (읽기)
printf("y : %d \n", y);
}
int main() {
std::vector<std::thread> threads;
std::atomic<int> a(0);
std::atomic<int> b(0);
threads.push_back(std::thread(t1, &a, &b));
threads.push_back(std::thread(t2, &a, &b));
for (int i = 0; i < 2; i++) {
threads[i].join();
}
}- 실행 결과(세 가지 결과가 도출 가능)
x : 1 y : 0x : 0 y : 1x : 1 y : 1
- 읽기/쓰기
- 객체들에 대해 원자적으로 읽고 쓸때,
memory_order_relaxed방식으로 실행
- 객체들에 대해 원자적으로 읽고 쓸때,
b->store(1, memory_order_relaxed); // b = 1 (쓰기)
int x = a->load(memory_order_relaxed); // x = a (읽기)- 순서가 상관없기 때문에 a,b모두 0인 경우를 제외한 모든 경우가 결과로 도출 가능함
- 순서가 상관없는 연산의 경우 사용가능
3.2. memory_order_release
- 해당 명령 이전의 모든 메모리 명령들이 해당 명령 이후로 재배치 되는 것을 금지
- 만약 같은 변수를
memory_order_acquire으로 읽는 쓰레드가 있다면,memory_order_release이전에 오는 모든 메모리 명령들이 해당 쓰레드에 의해서 관찰될 수 있어야 함
3.3. memory_order_acquire
- 해당 명령 뒤에 오는 모든 메모리 명령들이 해당 명령 위로 재배치 되는 것을 금지
3.4. memory_order_acquire와 memory_order_release를 사용한 두 쓰레드의 같은 변수 동기화
-
예제 코드
#include <atomic> #include <iostream> #include <thread> #include <vector> using std::memory_order_relaxed; std::atomic<bool> is_ready; std::atomic<int> data[3]; void producer() { data[0].store(1, memory_order_relaxed); data[1].store(2, memory_order_relaxed); data[2].store(3, memory_order_relaxed); is_ready.store(true, std::memory_order_release); } void consumer() { // data 가 준비될 때 까지 기다린다. while (!is_ready.load(std::memory_order_acquire)) { } std::cout << "data[0] : " << data[0].load(memory_order_relaxed) << std::endl; std::cout << "data[1] : " << data[1].load(memory_order_relaxed) << std::endl; std::cout << "data[2] : " << data[2].load(memory_order_relaxed) << std::endl; } int main() { std::vector<std::thread> threads; threads.push_back(std::thread(producer)); threads.push_back(std::thread(consumer)); for (int i = 0; i < 2; i++) { threads[i].join(); } } -
실행결과
data[0] : 1 data[1] : 2 data[2] : 3
- 재배치 금지
data의 원소들은store하는 명령들은 모두relaxed덕분에 자기들 끼리 재배치 가능하지만, 아래release이후로 넘어가서 재배치 될 순 없음- 따라서
consumer에서data들의 값을 확인했을 때 언제나 적확하게 1,2,3이 들어있게 됨
data[0].store(1, memory_order_relaxed); data[1].store(2, memory_order_relaxed); data[2].store(3, memory_order_relaxed); is_ready.store(true, std::memory_order_release);
3.5. memory_order_acq_rel
acquire와release를 모두 수행하는 것- 읽기와 쓰기를 모두 수행하는 명령들(fetch_add)에서 사용가능
3.6. memory_order_seq_cst
- 메모리 명령의 순차적 일관성을 보장
- 순차적 일관성: 메모리 명령 재배치도 없고, 모든 쓰레드에서 모든 시점에 동일한 값을 관찰할 수 있는 동작방식

그냥 하자