허프만 압축
1) 등장 배경
- 파일의 각 문자가 8bit인 아스키 코드로 저장되면, 그 파일의 bit수는
8x(파일의 문자 수)가 됨 - 이 때, 파일의 각 문자는 일반적으로
고정된 크기의 코드로 표현 - 고정된 크기의 코드로 구성된 파일을 저장하거나 전송할 때 파일의 크기를 줄이고, 필요시 원래의 파일로 변환할 수 있다면, 메모리 공간을 효율적으로 사용할 수 있으며, 파일 전송시간을 단축 가능
- 파일의 크기를 줄이는 법:
파일 압축(file compression)
2) 허프만 압축 구조
허프만 압축: 파일에 빈번히 나타나는 문자에는 짧은 이진코드를, 드물게 나타나는 문자에는 긴 이진 코드를 할당- 문자 코드는
접두부 특성(prefix property)을 가짐- 각 문자에 할당된 이진 코드가 다른 문자에 할당된 이진 코드의 접두부가 되지 않음
1. 알고리즘 수행 과정
1.1. 이진트리 만들기
1) 각 문자별로 단말 노드를 만들고, 그 문자의 빈도수를 노드에 저장
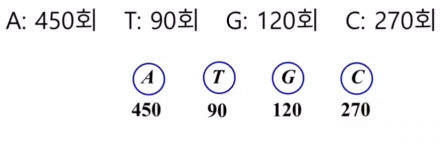
2) n개의 노드의 빈도수에 대한 우선 순위 큐Q를 생성
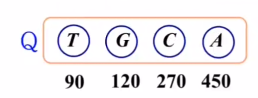
3) 빈도수가 가장 적은 2개의 노드를 Q에서 제거해 새 노드N을 만듦
N의 빈도수 = A의 빈도수 + B의 빈도수
4) 새 노드 N을 Q에 삽입
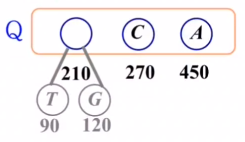
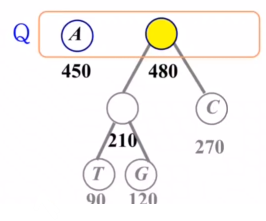
5) Q에 노드 수가 1이 될 때 까지 2~4를 반복
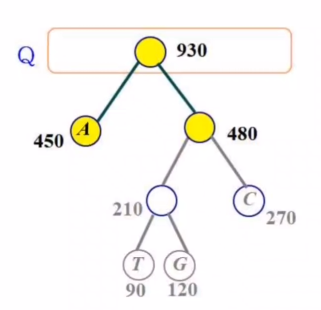
1.2. 압축하기
- 트리르 살펴보면 각 단말 노드에만 문자가 존재함
- 루트로 부터 내려가며
왼쪽은 0을,오른쪽은 1을 부여
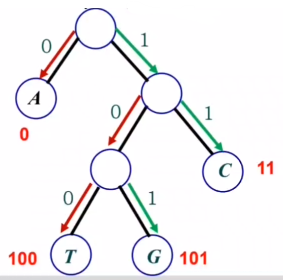
- 가장 빈도수가 높은
A가 가장 짧은 코드- 루트 노드와 가장 가까움
- 빈도수가 낮은 문자는 긴 코드
- 루트 노드와 멀어짐
2. 시간복잡도
- n개의 노드를 만들고, 각 빈도수를 노드에 저장:
O(n) - n개의 노드로 우선순위 큐를 만듦:
O(n) - 두 노드를 삭제 후 새 노드 만들기:
O(logn)- while n-1번 반복:
O(nlogn)
- while n-1번 반복:
- 결론:
O(nlogn)

그냥 하자