[논문 리뷰 + 코드 구현] ViT : An Image is Worth 16x16 Words : Transformers For Image Recognition At Scale
[논문 리뷰]

이번에는 ViT를 PyTorch로 구현해보고자 한다.
2021년 이후 Computer Vision의 Foundation Model로 빼먹을 수 없는 ViT..
간단한 Image Classification Dataset을 사용하여 Image Classification을 위한 ViT를 구현해보자.
(논문보다 모델을 간단히 만들 예정이다. Transformer block 수는 4,5개 정도?)
먼저, 바로 구현에 들어가기 이전, 간단한 논문의 내용을 살피고 들어가보자.
(빈틈없는 공부를 위해, Attention 논문부터 다시 보도록 하자...)
1. 논문 다시 읽고 흐름 잡기
Attention Is All You Need
이전 게시글을 참고해도 좋다.
[논문 리뷰] Attention Is All You Need
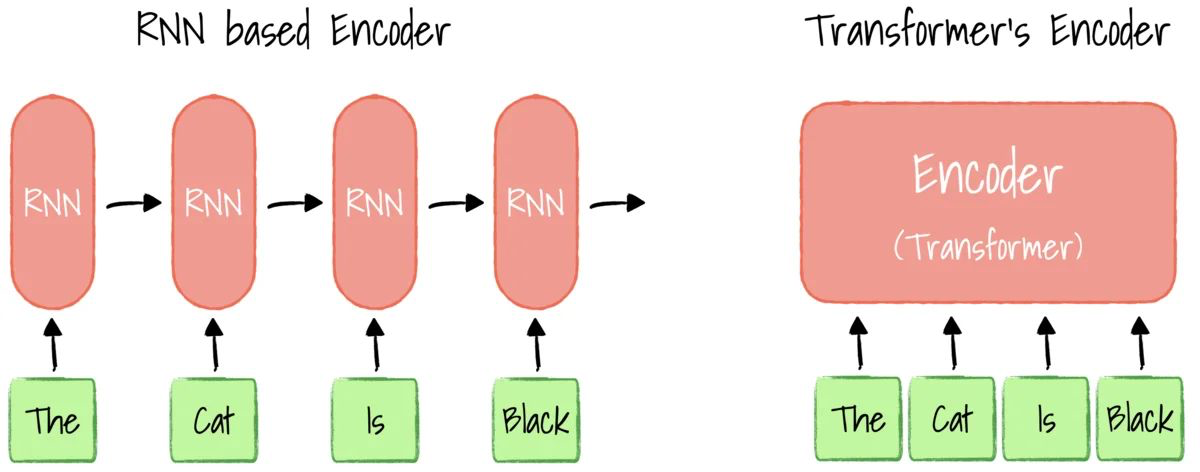
기존의 RNN (LSTM이나 GRU같은..) 모델들은 언어 모델링이나 기계 번역 같은 시퀸스 문제에서 가장 뛰어난 성능 (State of the art)을 보여주는 확고한 접근 방식이었다.
하지만 그들 또한 문제가 존재하는데, 바로 순차적 계산 (Sequential Computation), 시점 에서의 히든 스테이트 를 계산하려면, 반드시 이전 시점의 이 완성되어야 했다.
이러한 순차적 특성 (Inherently Sequential Nature) 때문에 학습 할 때에 병렬화 (Parallelization) 이 불가능했다. 즉, 아무리 계산 자원이 많아도 앞의 계산이 끝날 때까지 기다려야 하므로 속도를 높이는 데에 한계가 존재했던 것이다. 특히 문장의 길이가 길어질수록 더 심해졌다.
어텐션 메커니즘은 이미 시퀸스 모델링에서 중요한 요소로 자리잡고 있었다. 입력이나 출력 시퀸스 내의 거리에 상관없이 의존성 (Dependency)을 모델링할 수 있게 해주기 때문인데, 이 시점까지 예외없이 어텐션은 순환 신경망(RNN)과 함께 사용되고 있었다.
Attention Is All You Need 논문은 바로 Transformer라는 새로운 Architecture를 제시한다.
그들이 제시한 Architecture는 다음과 같다 : 순환(Recurrence)를 완전히 배제한다. 바로 위에서 언급한 단점 때문이다.
대신, 입출력 사이의 전역적 의존성(Global dependencies)를 파악하기 위해 오직 어텐션 메커니즘에만 의존한다. 이러한 변화를 통해 Transformer는 훨씬 더 많은 병렬화를 가능케 하며, 번역 품질 면에서도 기존 최고 수준을 달성하면서도 훈련 시간은 획기적으로 단축시킬 수 있다고 한다.
근데.. 병렬화가 뭐죠..?
병렬화는 입력된 시퀸스의 모든 위치에 대한 계산을 동시에 수행하는 능력을 의미한다.
기존의 RNN은 문장을 처리할 때
"첫번째 단어" "그 결과를 바탕으로 두 번째 단어" ...
순서대로 진행해야 했다.
반면, 병렬화가 가능하다는 것은 문장 전체를 하나의 거대한 행렬로 보고, 모든 단어 간의 관계 계산을 한 번에 처리할 수 있다는 뜻이다.
그런데 사실 RNN의 순차적 계산 문제를 해결하기 위해 CNN 기반의 모델들(Extended Neural GPU, ByteNet, ConvS2S) 가 등장했다.
이 모델들은 CNN을 Basic Block으로 사용하여 입출력의 숨겨진 표현(Hidden representations)을 병렬로 계산하려 했다.
하지만 이 모델들은 멀리 떨어진 위치 간의 관계 를 학습하는 데에 어려움이 있었다. 두 위치 사이의 거리가 멀어질수록 필요한 연산 횟수가 증가하기 때문이다. (ConvS2S는 선형적, ByteNet은 로그적으로 증가했다고 한다.)
반면 Transformer는 거리에 상관없이 상수 횟수(Constant Number)의 연산 만으로 모든 위치를 연결할 수 있었는데, 이는 긴 거리의 의존성 (Long-range dependencies)를 학습하는 데 훨씬 유리하다. 다만 이 과정에서 평균화로 인해 해상도(resolution)이 떨어지는 단점이 생기는데, 이를 Multi-Head Attention 으로 보완했다.
참 궁금한 것도 많은 나는 또 생각이 드는데...
그럼 기존에 시도했던 CNN 모델에 Transformer가 해결한 것처럼 Multi-Head Attention을 붙이면 되지 않아요..?
라고 생각을 했는데, 역시 이미 있다고 한다. 더 나아가 예전에 읽은 논문들 중에서도 두 개나 있다.
(1) BoTNet (BottleNeck Transformer, 2021)
- "ResNet의 마지막 단계에서는 이미 이미지 크기가 많이 줄어들었으니 (7x7 등), 거기서는 Conv 대신 Multi-Head Attention(MHA)를 써도 연산량이 감당되지 않을까?" 라는 아이디어에서 나온 모델이다.
- 구조는 ResNet50에 마지막
BottleNeck블록의 3x3 합성곱 층을 떼어내고, 그 자리에 Multi-Head Self-Attention 층을 끼워 넣었다.- 결과는 파라미터 수는 줄이면서도 정확도는 훨씬 올라갔다. CNN이 텍스쳐를 잡고, Attention이 물체 간의 관계를 잡았기 때문이다.
(2) DETR (DEtection TRansformer, 2020)
- "CNN으로 일단 Feature Map을 뽑고, 그 위에 Transformer를 얹어서 물체를 찾아볼까?" 라는 아이디어에서 나온 모델이다.
- CNN을 Backbone 모델로 만들고, Transformer Encoder-Decoder를 얹은 모델이다.
- 그 결과, CNN이 이미지를 압축해주고, Transformer가 전체적인 위치 관계를 파악해서 물체를 탐지해준다.
(3) CBAM (Convolutional Block Attention Module) / SE-Net
- "Transformer만큼 무거운 MHA 말고, 좀 더 가벼운 Attention을 CNN 중간중간에 끼워 넣자" 라는 생각에서 나온 모델이다.
- 채널별 중요도를 계산하거나 공간적 중요도를 계산해서 Feature Map에 곱해주는 방식이다.
그런데 왜 모든 CNN을 이걸로 대체하지 않았을까?
바로 연산량 문제가 있기 때문이다.
CNN은 이미지 크기에 비례하여 이미지가 커져도 적당히 늘어나는 반면, Attention은 이미지 픽셀 수의 제곱에 비례하여 메모리가 터진다.
2. ViT 논문 읽기
An Image is Worth 16x16 Words:Transformers for Image Recognition At Scale
자, 그럼 ViT 논문으로 들어가보자.
Transformer와 같은 Self-attention 기반 Architecture는 NLP 분야에서 사실상의 표준이 되었는데, 컴퓨터비전 분야에서는 여전히 Convolutional Architecture가 지배적이다.
NLP의 성공에 영감을 받아 CNN과 Self-attention을 결합하거나 컨볼루션을 완전히 대체하려는 시도가 있었지만, 특수한 어텐션 패턴으로 인해 하드웨어 가속기에서 효과적으로 확장되지 못했다고 한다.
때문에 여전히 ResNet과 같은 아키텍쳐가 SOTA로 자리잡고 있다.
여기서 말하는 특수한 어텐션 패턴은?
초기 vision 분야에서 self-attention으로 convolution을 대체하려 했지만, vision특유의 패턴 때문에 일반화가 어려웠다는 것이다. 다시 말해, NLP에서의 self-attention과 Vision에서 요구되는 attention의 성질이 다르다는 것이다.
NLP에서 self-attention이 잘 먹힌 이유
NLP에서는 입력이 Token Sequence이고, self-attention은 다음과 같은 성질을 가진다.
- Global : 모든 토큰이 모든 토큰을 볼 수 있다.
- permutation invariant Positional encoding으로만 순서를 주입한다.
- 의미 기반 관계 학습으로, 거리보다 의미적 관련성이 더 중요하다.
이러한 특성들 때문에 Convolution없이도 문맥 구조를 잘 학습할 수 있었다.
Vision에서 Convolution이 강력한 이유 (Inductive Bias)
이미지는 NLP와 완전 다르다. CNN이 강한 이유는 강한 Inductive Bias를 가지고 있기 때문이다.
CNN의 핵심 inductive bias
* inductive bias는 training에서 보지 못한 데이터에 대해서도 적절한 귀납적 추론이 가능하도록 하기 위해 모델이 가지고 있는 가정들의 집합을 의미한다.
1. Locality (국소성)
-> 인접한 픽셀 간의 관계가 가장 중요하다
2. Translation Equivariance (이동 등변성)
-> 물체가 위치를 조금 옮겨도 같은 패턴으로 인식한다.
3. Hierarchical structure
-> Edge -> texture -> part -> object
정리해보자면, 초기 vision self-attention 시도들은 convolution이 가진 locality, translation equivariance 같은 강력한 inductive bias를 대체하지 못했고, 그 결과 vision 특유의 attention 패턴을 효율적으로 학습할 수 없었다
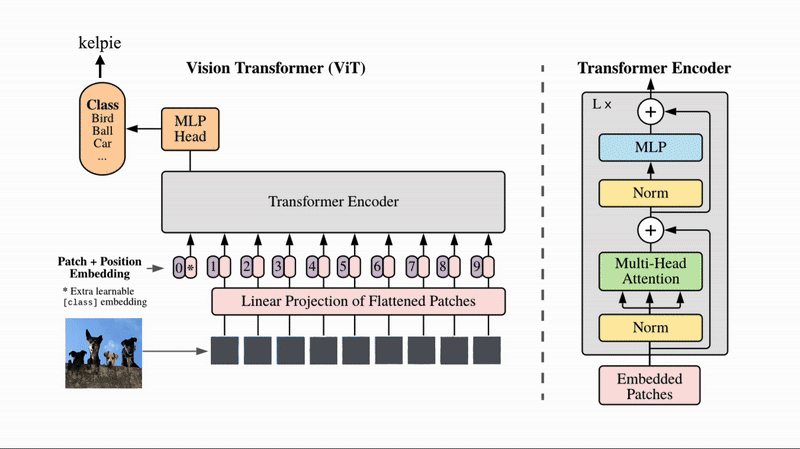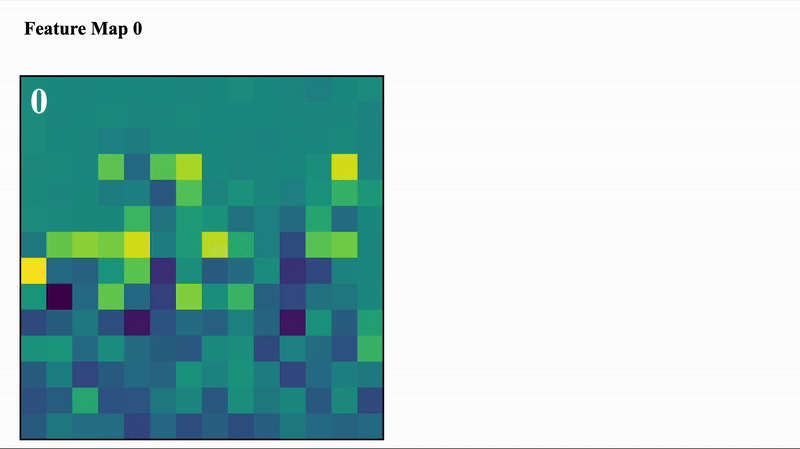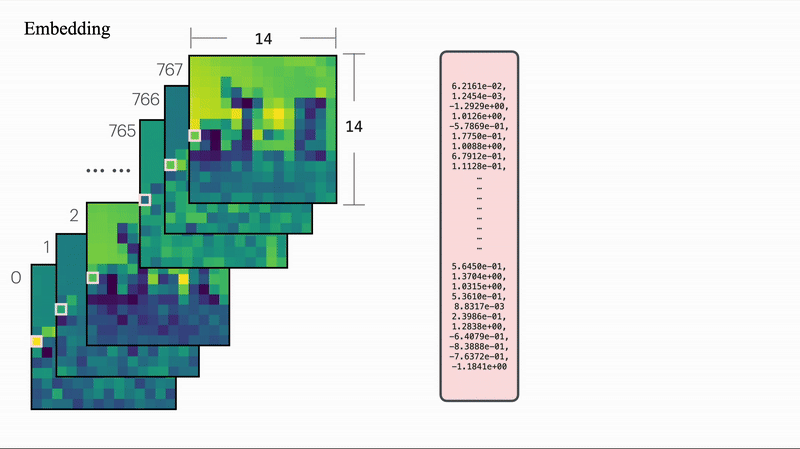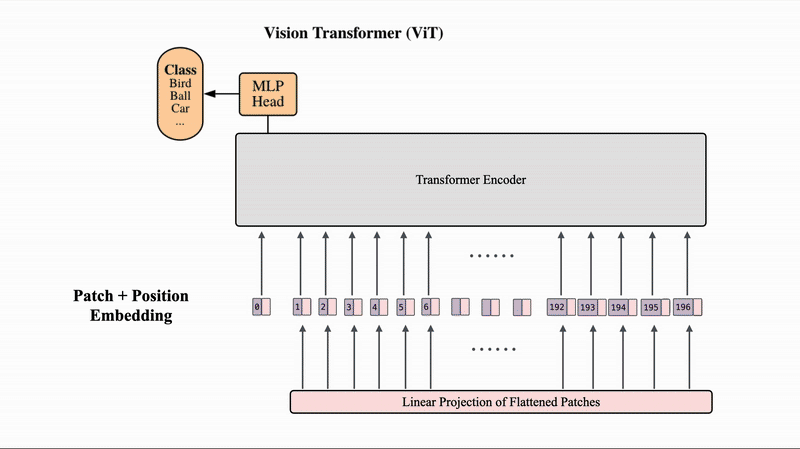
하지만 ViT는 이미지를 patch로 분할하고, 이 패치들의 선형 임베딩 시퀸스를 Transformer의 입력으로 제공한다. 이 방식에서 이미지 패치는 NLP의 토큰과 동일하게 취급되며, 이미지 분류를 위해 지도학습(supervised fashion)으로 훈련된다.
여기서 이미지를 패치로 나눌 때 우리가 흔히 Augmentation에 진행했던 RandomCrop이나 CenterCrop과는 조금 다르다.
ViT의 Patch Partitioning은 이미지를 버리는 부분 없이 쪼개는 개념이다._
Data Augmentation (Crop) | Patch Partitioning |
|---|---|
목적 : 이미지의 일부분만 잘라서 다양성을 주거나(RandomCrop), 중심만 남기기(CenterCrop)특징 : 잘려나간 나머지 부분은 버려진다. 예시 : 256 x 256 이미지에서 224 x 224 영역 하나만 선택. | 목적 : 이미지를 Transformer에 넣기 위해 단어(Token) 처럼 만드는 것. 특징 : 이미지 전체를 사용하며, 겹치지 않게 (Non-Overlapping) 모든 영역을 균일한 크기로 나눈다. 예시 : 224 x 224 이미지를 16 x 16크기의 패치 196개(14 x 14) 로 조각낸다. 하나도 버리지 않는다. |
* 선형 임베딩 시퀸스 (Linear Embedding Sequence) 란?
2차원 이미지(그림)을 1차원인 트랜스포머(언어 모델)이 이해할 수 있는 형태(단어들의 나열)로 바꾸는 과정을 말한다.
- 왜 시퀸스(Sequence)인가? (2D 1D)
Transformer는 원래 NLP 처리를 위해 만들어진 모델이다. 언어는 순서가 있다.
- 나는, 학교에, 간다, (이렇게 순서대로,..
하지만 이미지는 2차원 Grid이다.
- (0,0) 좌표, (0,1)좌표.. 이렇게...
그래서 이미지를 Transformer에 넣으려면 2차원 판을 잘라서 한 줄로 쭉 늘어세워야 한다.
- 패치 : 이미지를 16 x 16 조각으로 자른다.
- 시퀸스 : 이 조각들을 왼쪽 위부터 오른쪽 아래 순서로 한 줄로 나열한다.
- 왜 선형 임베딩 인가? (Pixel Vector)
잘라낸 패치 하나(16 x 16, 3C)는 숫자들의 뭉치일 뿐이다. (16 x 16 x 3 = 768개의 숫자) 이 날것의 픽셀값들을 모델이 학습하기 좋은 Vector로 바꿔줘야 하는데, 이 때 가장 단순한 방식인 선형 변환(Linear Projection) 을 사용한다.
- 과정
1. 패치의 픽셀들을 1줄로 편다. ()- 여기에 학습 가능한 행렬 를 곱한다. (Embedding = )
- 이 과정이 형태의 1차 함수이므로, Linear라고 부른다. (ReLU 같은 비선형 함수 통과하지 않음)
코드 예시
import torch.nn as nn
# 이미지 크기 : 224x224, 패치 크기 : 16, 임베딩 차원 : 768
patch_size = 16
in_channels = 3
embed_dim = 768
# 핵심 : Kernel Size와 Stride를 패치 크기와 똑같이 설정해야 한다.
patch_embed = nn.Conv2d(
in_channels = in_channels,
out_channels = embed_dim,
kernel_size = patch_size, # 16x16 영역을 본다/
stride = patch_size # 16 만큼 건너 뛴다 (겹치지 않게)데이터 규모에 따른 성능 차이 또한 존재한다
강력한 정규화 없이 훈련할 경우, ViT는 비슷한 크기의 ResNet보다 몇 퍼센트 포인트 낮은 정확도를 보인다. 이는 Transformer가 CNN 고유의 귀납적 편향(Inductive Bias) 가 부족하여 데이터가 충분하지 않을 때 일반화가 잘 되지 않기 때문이다.
ViT 논문 리뷰
1.
2. ViT Architecture : 이미지 패치화 및 선형 투영(Linear Projection)
ViT의 핵심은 2D 이미지 데이터를 트랜스포머가 수용 가능한 1D 임베딩 시퀸스로 변환하는 전처리 파이프라인에 있다.
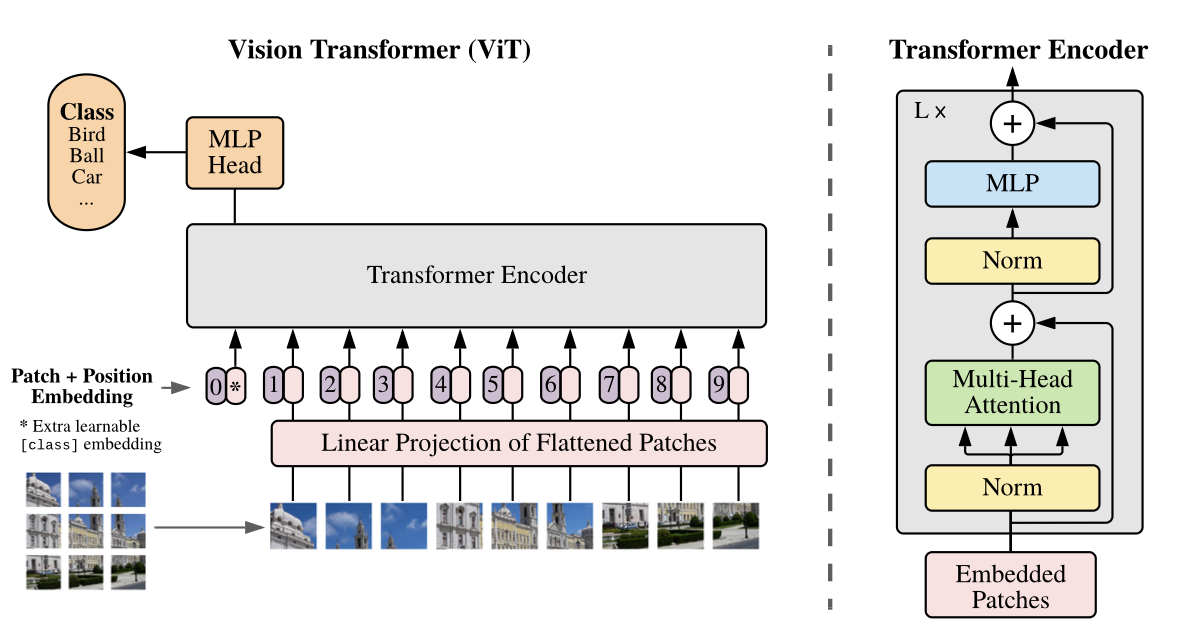
2.1 이미지 분할 및 차원 설계 (Patch Partitioning)
입력 이미지 는 해상도 를 가진 개의 패치로 분할된다. 여기서 이며, 이는 트랜스포머의 유효 시퀸스 길이를 결정한다.
시퀸스 길이는 패치 크기의 제곱에 반비례하므로, 값의 설정은 연산 복잡도와 정밀도 사이의 전략적 트레이드오프 지점이 된다.
2.2 선형 투영 및 임베딩 행렬
분할된 패치는 Flattening된 후 선형 투영을 통해 차원의 latent 공간으로 매팽된다.
- 투영 행렬(Projection Matrix) : 를 적용하여 각 패치를 임베딩한다.
- [class] 토큰 : BERT의 설계를 계승하여, 학습 가능한 임베딩 벡터 를 시퀸스 최전단에 배치한다. - 위치 임베딩(Position Embedding) : 1D 학습 가능 위치 임베딩 를 합산하여 공간 정보를 주입한다. 초기화 시 이 임베딩은 2D 정보를 갖지 않으며, 모델은 학습 과정에서 패치 간의 공간적 상관관계를 스스로 슥듭한다.
2.3 하이브리드 아키텍쳐(Hybrid Architecture) 변체
원시 이미지 패치 대신 CNN(ResNet50 같은..)의 Feature Map을 입력 시퀸스로 활용할 수 있다. 이 경우 Feature Map의 공간적 차원을 Flattening하고 패치 크기로 간주하여 차원으로 투영한다. 이는 소규모 데이터셋에서 수렴 속도를 높이는 전략적 대안이 될 수 있다.
계속 작성 예정임다…
