Abstract
- DM의 방식에 Denoising autoencoder를 이용하면 재학습 없이 이미지 형성 과정을 제어하는 것이 가능하다.
- DM은 픽셀 공간에서 직접적으로 동작하기 때문에 엄청나게 많은 양의 GPU를 소모하며, 추론 과정 또한 연속적인 평가로 인해서 고비용을 요구한다.
- 한정된 계산 자원을 가지고, 퀄리티와 유연성을 유지하면서 DM의 학습을 가능하게 하기 위해서 저자는 DM을 사전 학습 된 autoencoder의 latent 공간에 적용한다.
Introduction

- 저자는 pixel 공간과 비교했을 때 perceptual 하게는 동일하지만, 계산적으로는 조금 더 적합한 공간인 latent 공간을 찾는 것을 목표로 했다.
- 저자는 data space와 비교했을 때, perceptual 하게는 동일하지만 차원은더 낮은 표현 공간을 제공할 수 있는 autoencoder를 학습한다.
- 저자는 이를 Latent Diffusion Model(LDM)이라고 칭한다.
- 이러한 접근의 장점은 autoencoder를 사전에 1번만 학습시켜 놓으면 추후에 다양한 DM을 학습하거나 여러가지 task에도 재사용할 수 있다는 점이다.
Method
- 고해상도 이미지 합성을 위한 DM을 학습하는데 드는 계산적인 요구들을 낮추기 위해서 저자는 DM들이 대응하는 오차를 undersampling 하는 것을 통해서 perceptual 하게 관련없는 디테일들을 무시하는 것을 관찰했지만, 그럼에도 불구하고 여전히 엄청난 양의 에너지 자원과 계산 시간을 요구하는 것을 확인했다.
- 저자는 이러한 단점을 극복하기 위해서 “압축 단계”과 형성을 위한 “학습 단계”를 명시적으로 분리하는 것을 제시한다.
- 이 것을 위해서 저자는 latent 공간에 대해서 학습을 하는 autoencoder를 활용한다.
1) Perceptual Image Compression
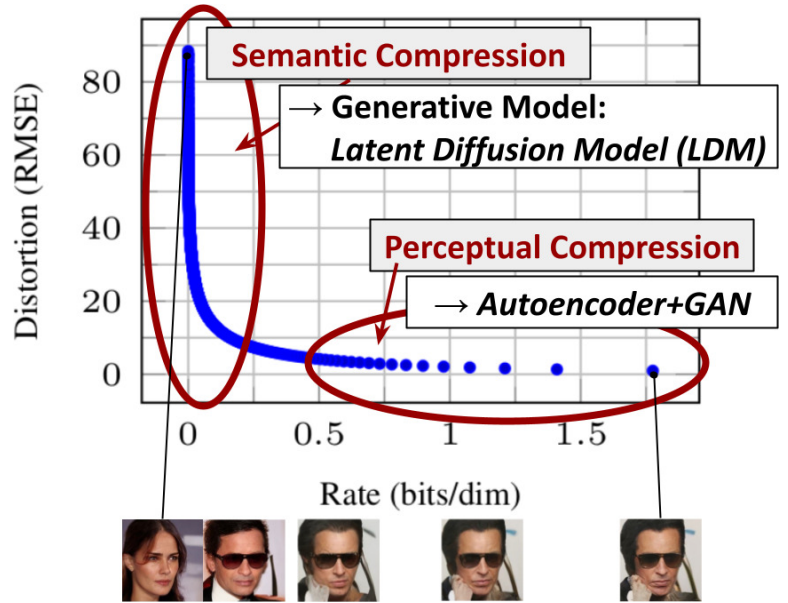
- 논문에서 제시하는 perceptual compression model은 perceptual loss와 patch-based adversarial 목적 함수를 함께 사용하여 학습시킨 autoencoder로 이루어져 있다.
- 임의의 높은 변화율 latent 공간을 회피하기 위해서 저자는 2개의 다른 정규화 방법인 KL 정규화 방법과 VQ정규화 방법을 실험에 사용한다.
- LDM은 2차원 공간에서 동작하도록 설계되었기 때문에 비교적 적은 압축률을 사용하면서도 아주 좋은 성능의 복원을 하는 것이 가능하다.
2) Latent Diffusion Models
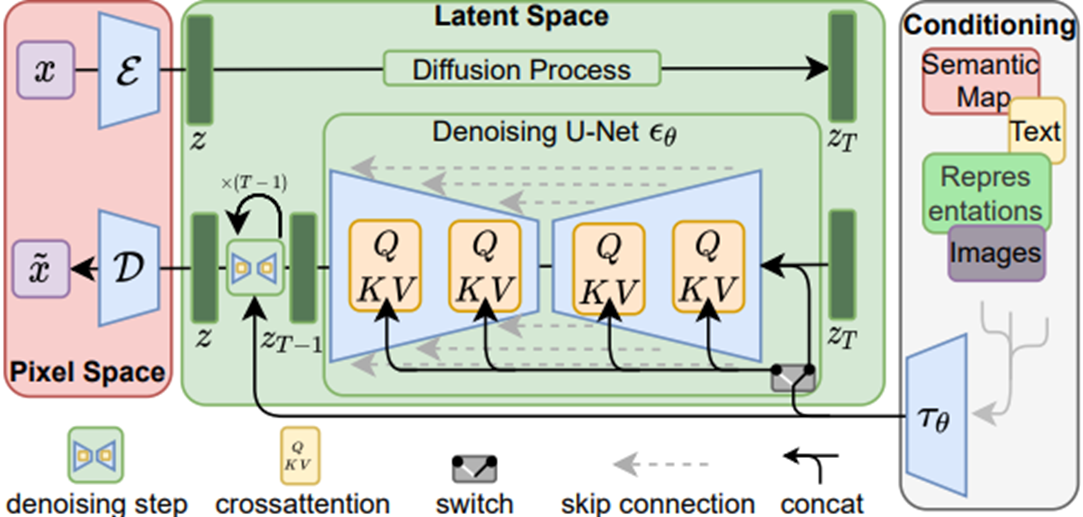
Latent Diffusion Model의 학습 흐름도
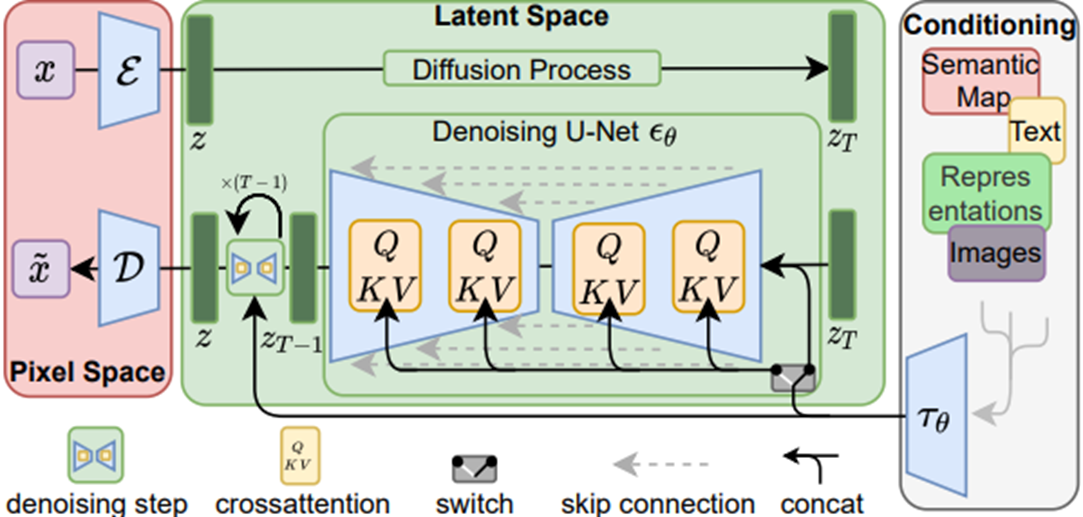
- DM이란 정규 분포화 된 변수(노이즈 낀 이미지)에 대해서 점진적으로 denoising을 적용하여서 데이터의 분포인 p(x)를 학습하도록 설계된 확률 모델이다.
- 이미지 합성에 있어서, 대부분의 성공적인 모델들은, denoising score-matching과 일치하는, p(x)에 대한 변화의 아래쪽 경계에 대한 재측정된 변수에 의존한다.
- 이러한 모델들은 다르게 말하면 결국 input “x”의 noise가 낀 버전인 “xt”를 denoise 했을 때의 결과를 예측하도록 학습된 autoencoder라고 할 수 있다.
3) Conditioning Mechanisms
LDM의 컨디셔닝 방식
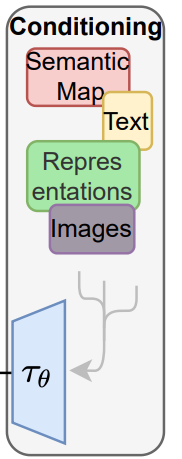
- 컨디셔닝 확률은 p(z|y) 의 형태로 설계되어있고, 여기서 “z”는 input “x”에 대한 latent 공간에서의 표현이고, “y”는 컨디셔닝을 위한 input이며 여기에는 image, text prompt, semantic map 등 다양한 유형이 해당될 수 있다.
- 저자는 DM의 구성 중 하나인 UNet의 backbone을 cross-attention mechanism을 이용하여 증강하는 것으로 이전의 DM을 컨디셔닝에 있어서 유연한 이미지 형성 모델로 만들고 있다.
- input y는 domain specific 인코더에 먼저 전처리 된 후에 cross-attention layer을 거쳐서 UNet의 intermediate layer들에 매핑된다.
4) Experiment
Text-to-Image(T2I) Image Generation 정성적 결과

Layout-to-Image Generation 정성적 결과

Semantic-to-Image Generation 정성적 결과

Super Resolution(SR) 정성적 결과

Inpainting 정성적 결과

- 실험에서는 “학습 단계”와 “추론 단계” 모두에 있어서 pixel 기반 DM의 결과와 비교를 하고 있다.
- 저자는 LDM들이 신기하게도 VQ-정규화 기반 latent 공간에서 학습된 LDM들이 더 높은 샘플 퀄리티를 보이고 있다고 말한다.
- 너무 적은 다운샘플링은 너무 높은 계산량을 요구하였고, 너무 많은 다운샘플링은 input의 특징을 너무 많이 손실 시켜서 복원의 퀄리티가 좋지 못하기 때문에 둘 사이 어딘가에서 효율적인 구간을 찾아서 적당한 다운샘플링을 하는 것이 중요하다고 말한다.
- 결과적으로 다운샘플링 인자가 4, 8, 16일때의 모델들이 가장 결과가 좋게 나타났다고 한다.
Conclusion
- 논문에서는 퀄리티를 낮추지 않으면서도, denoising DM의 학습과 샘플링의 효율을 동시에 높이는 간단하고도 효율적인 모델인 LDM을 제시한다.
- 이와 cross-attention conditioning method를 기반으로 했기에 논문에서의 실험 결과는, 특정 task에 맞춤 설계된 구조 없이, 넓은 범위의 conditional 이미지 합성 task들에 대해 SOTA와 비교해도 만족할만한 결과를 보여주는 것이 가능하였다고 말한다.
Reference
Paper URL: https://arxiv.org/pdf/2112.10752
Github URL: https://github.com/CompVis/latent-diffusion

1999.09.10 / LIG Nex1 AI Researcher