Pruning-as-Search: Efficient Neural Architecture Search via Channel Pruning and Structural Reparameterization
논문 리뷰
목록 보기
13/21
Abstract & Introduction
- NAS는 depth와 width를 자동으로 찾지만, searching overhead가 있어서 모델을 찾는데 엄청난 cost가 소모된다.
- structured pruning(network pruning)은 layer당 filter을 얼마나 줄일지 ratio를 자동적으로 결정하는 것이 어렵다.
- 이 논문에서는 Pruning-as-Search(PAS)를 제안하여서 layer당 filter의 압축률을 자동으로 최적화하고 end-to-end로 기법을 적용하여 효율화한다. 이는 기존과 비슷한 훈련 cost를 가지면서 자동으로 sub-network를 찾는다.
- depth-wise convolution(DBC)을 각 convolution layer 뒤에 추가하여 pruning indicator로 활용한다.
- DBC layer의 훈련 능력을 위해서 Straight-Through-Estimator(STE)를 적용했다.
- pre-trained network에서 시작하기 때문에 fine-tuning은 추가로 한번만 필요하다.
- magnitude trap에서 벗어나 있기 때문에 이전의 pruning 방식들과는 다르다.
- layer width의 유연성을 위해서 identical path를 convolution layer에 structural reparameterization하여, inference 단계에서 sub-network들의 residual connection을 없앤다.
Challenges and Motivations
C1. NAS의 방대한 양의 searching cost
- 후보군이 많을수록 저장공간이 많이 필요하다.
C2. Pruning에서의 magnitude trap
- 일반적으로는 filter/channel들이 작은 magnitude를 가지면 최종 정확도에 영향을 덜 줄것이라고 생각하지만, 이러한 생각은 반드시 참이 아니며 small channel들을 바로 제거하면 정확도에 영향을 줄만큼 커질 기회를 없애는 문제가 발생하며 이를 Magnitude trap이라고 한다.
C3. Width의 뻣뻣함 제약
- ResNet에는 residual connection이 있고, 이는 입력차원 = 출력차원의 제한을 가지며, 이로 인해 design flexibility가 감소된다.
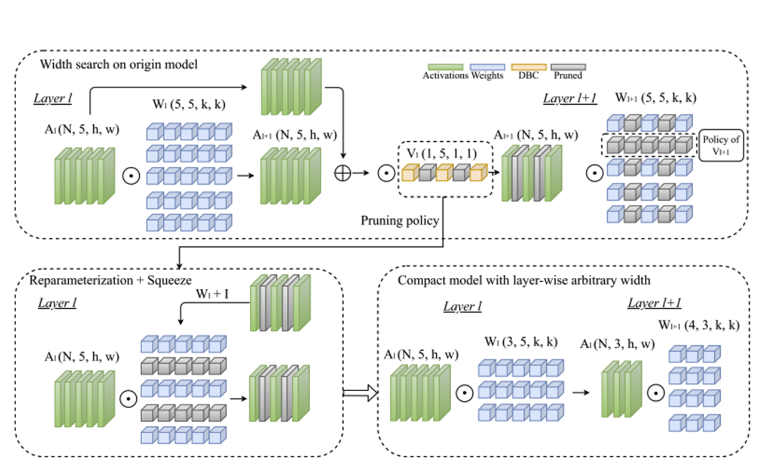
Pruning as Search Algorithm
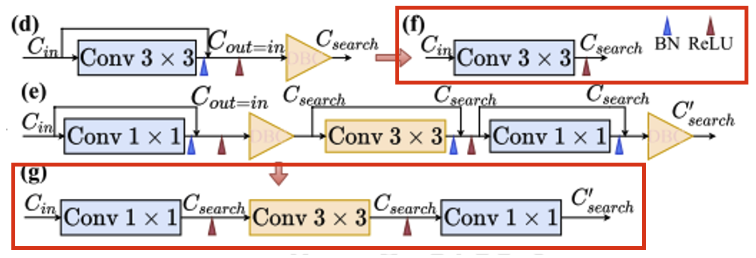
Depth-Wise Binary Convolution Layers
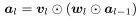
- 자동 channel pruning을 위해서 depth-wise 1x1 convolution layer을 사용하였다.
- 은 DBC layer의 파라미터이며 pruning indicator로 사용된다.
- 여기서 의 이진화로 인해서 미분불가능하여 back propagation 할 수 없는 문제가 발생하는데, 이를 STE를 이용하여 해결한다.
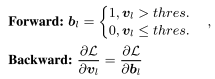
- 임곗값은 0.5로 하였고, 0과 1로 을 이진화한다.
- STE와 DBC layer의 결합을 통해 pruning policy와 parameter 학습을 분리하며, DBC layer에서 gradient 소실을 방지하여 pruned channel의 정보를 보존한다.
- pruned model을 적용하기 위해서 DBC layer의 이진화 값을 이용하여 0인 것은 앞쪽으로, 1인 것은 뒤쪽으로 재구성하여 그룹화한다.
Training Loss Function
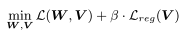
- 앞쪽 항은 모델 학습 단계에서의 loss이고, 뒤쪽은 계산 복잡도에 관련된 regularization 항이다.
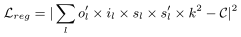
- 위 식은 현재 MAC와 목표 MAC 사이의 norm의 제곱으로 정의한다.
Simultaneous Pruning and Training for C1
- end-to-end channel pruning 방식은 DBC와 STE를 활용하여 모델의 학습과 pruning indicator을 동시에 할 수 있기에 학습 단계에서 효율적이다.
DBC layer as Indicators for C2
- DBC layer은 pruning indicator로서 2 가지 장점을 가진다.
- SGD를 활용하여 자연스럽게 학습이 가능하며 이를 통해 pruning policy도 학습동안 역동적으로 업데이트 된다.
- STE를 활용하였기 때문에 DBC layer에 의해서 pruning된 채널은 forward에서도, backward에서도 사용되지 않으며, 이는 결과적으로 모델 원본 weight를 파괴하는 soft-mask와 구별된다.
Structural Reparameterization for C3
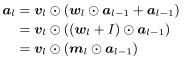
- skip connection이 한 개의 convolution만 건너서 연결할 때 가능하기에 ResNet을 사용한 것이 아닌 RepVGG에서 제시한 모델을 사용한다.
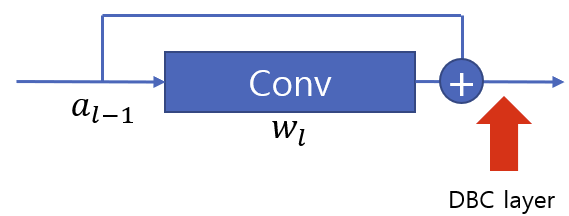
- 합 연산 이후 DBC layer을 두어서 reparameterization이 가능하도록 한다.
- 이 과정 이후에 skip connection을 제거하여 압축모델을 만들어서 추론 속도를 가속한다.

1999.09.10 / LIG Nex1 AI Researcher