Abstract & Introduction
- 좋은 성능을 내기 위해서는 모델 앙상블과 방법을 사용할 수 있지만, 연산량이 많고 시간이 오래 걸린다.
- 정답에 대한 레이블 뿐만이 아니라, 이외에 레이블에 대한 작은 확률 정보까지도 성능에 도움이 된다는 생각에서 지식 증류는 시작된다고 한다.
- Cumbersome Model이 하는 방식으로 small model이 학습할 수 있다는 점을 제시하였고, 이렇게 되면 기존의 normal한 방식으로 학습을 하는 것보다 더 좋은 성능을 가진다.
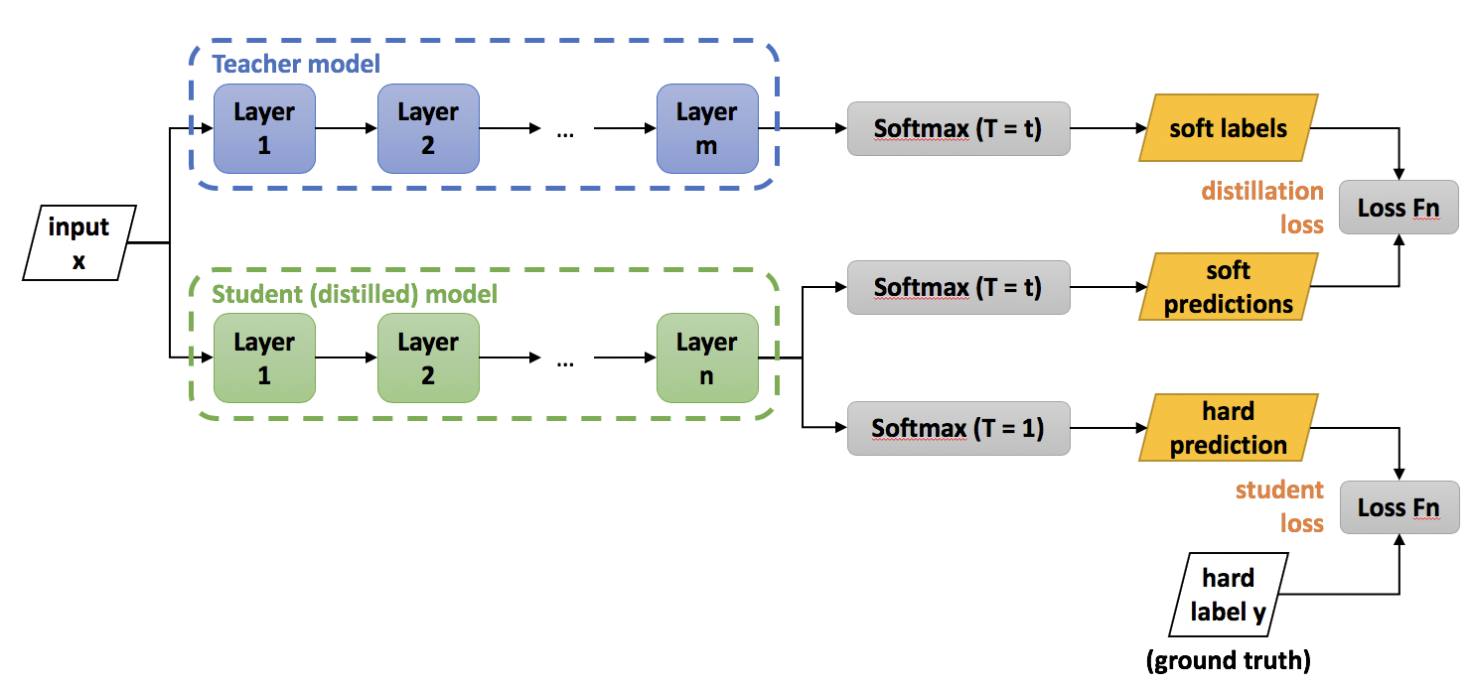
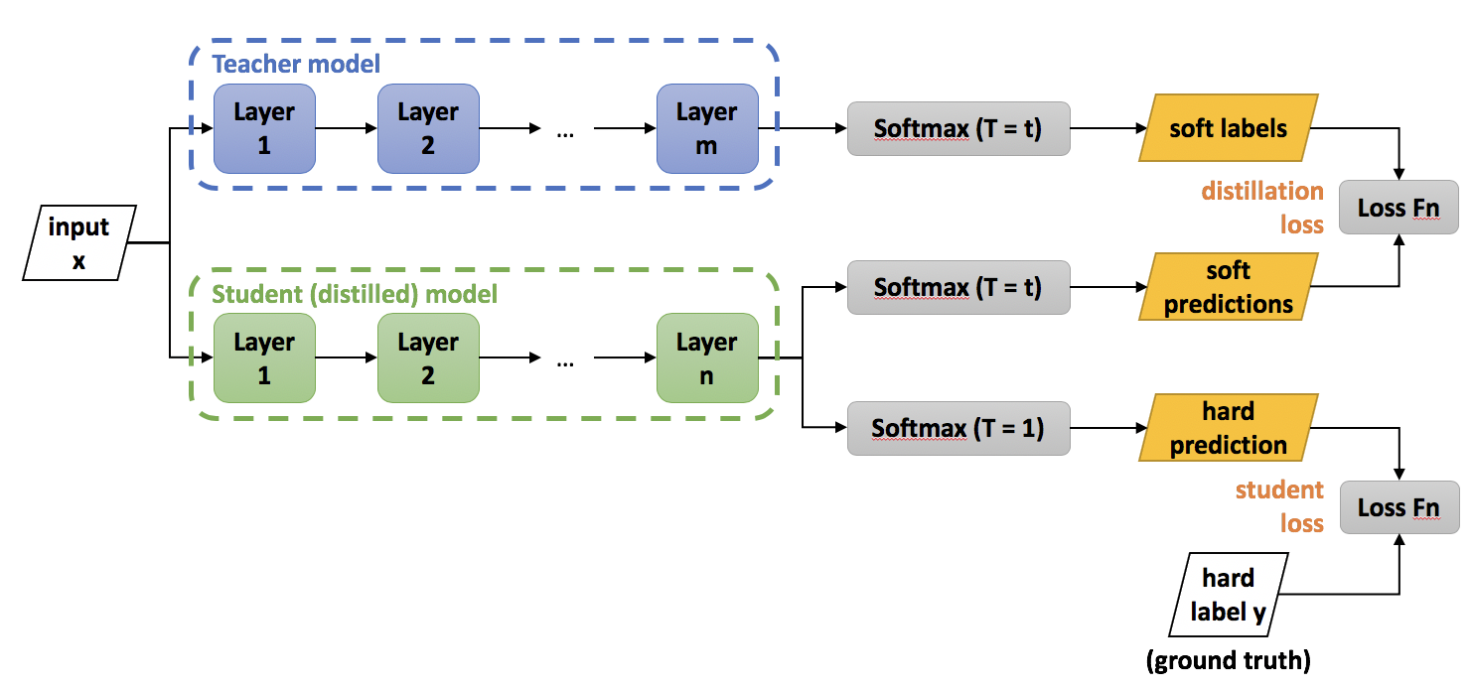
- student 모델이 학습하는데 사용하는 cumbersome model의 결과로 나온 class probability를 soft target이라고 간주한다.
- 이로 생기는 이점은 soft target이 high entropy라서 일반적인 학습에 사용하는 hard target보다 정보가 많고, training gradient 간에 gradient의 variance가 작아서 small model이 적은 data로도 효율적인 학습이 가능하다.
Distillation

- 여기서 T=1일 때 우리가 알고 있는 softmax와 같고, T값이 커질수록 확률 분포가 soft한 형태를 가지게 된다고 한다.
- Knowledge를 small model로 전이할때는 높은 값의 T를 사용하다가, 학습이 끝나면 small model은 T=1을 사용한다고 한다.
- Loss Function은 2 가지로,
- cumbersome 모델이 주는 soft target과 distilled 모델이 내놓는 softmax 사이의 cross entropy(두 모델의 T값은 동일해야함)
- correct label에 대한 cross entropy (Temperature은 1임)
- 저자들은 2번째 term에 더 낮은 가중치를 두는게 best result라고 한다.
- soft target의 경우 미분 시에 생기는 scale 문제 때문에 값의 temperature의 제곱만큼을 중요하다고 한다.
MNIST
- 3에 대해서 학습하지 않아도 t를 적절히 높히면 3을 아예 예측하지 못하진 않았다.
- 올바른 bias를 받았을 때는 정확도가 3에 대해서 98%까지도 나왔다.
Reference

1999.09.10 / LIG Nex1 AI Researcher