Index
클러스터 인덱스
-
mysql에선 클라스터 인덱스 자체가 데이터 테이블임
클러스터 인덱스 컬럼 지정 우선 순위
- Primary key로 지정한 칼럼
- Unique, NOT NULL로 지정한 컬럼
- 내부적으로 auto_increment가 적용된 칼럼을 만들어서 해당 칼럼을 클러스터 인덱스의 기준 컬럼으로 설정
인덱스 언제 사용할까?
( 효과적으로 적용하기 )
- 데이터가 충분히 多
- nullable 하지 않은 컬럼
ㄴ null값이 많다면 효과가 미미(찾으려고 탐색해서)
- nullable 하지 않은 컬럼
- where조건절, join 시 자주 사용되는 컬럼
- 카디널리티가 높은 컬럼
ㄴ 중복데이터가 적은 컬럼
- 카디널리티가 높은 컬럼
- 선택도가 낮은 컬럼
ㄴ 조회 결과가 원본데이터의 약 5%미만
- 선택도가 낮은 컬럼
View
- 가상의 테이블
- 실제 물리적으로 데이터를 저장한 것이 아닌 논리적으로 테이블처럼 활용 가능한 것
- 조회 쿼리를 특정한 이름으로 저장해놓은 것(=메서드화)
View를 사용하는 이유?
- 쿼리의 재사용성
- 유지보수성 증가
- 쿼리의 간소화
- 보안성
View 생성
create [or replace] view [뷰이름]
as
select 쿼리
[with check option]
[with read only]-
or replace : 같은 이름의 view가 이미 존재한다면, 해당 뷰의 쿼리를 대체
-
with check option : view 생성 시 where 조건절을 벗어나는 데이터는 삽입/수정 불가
-
with read only : 해당 view는 조회(select)만 가능
View 삭제
drop view [뷰이름]View 종류
- Simple View (단순 뷰)
하나의 테이블로 만든 뷰
insert, update, delete 가능
- 제한되는 경우
- View의 조회쿼리에 포함되지 않은 칼럼 중, not null이 지정된 컬럼이 있는 경우
- distinct 포함하는 경우
- group by, 집계함수 사용하는 경우
-
Complex View (복합 뷰)
여러 테이블을 join한 쿼리로만든 View
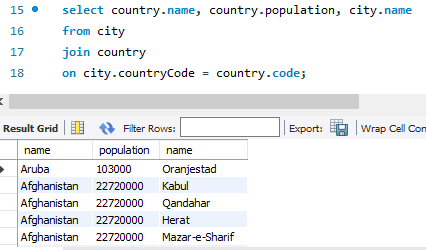
-
Inline View (인라인 뷰)
일반적으로 가장 많이 사용
from절에서 사용하는 subQuery
한번 사용하고 말 경우 (재사용성 無)
과목평가 정리
*as, "" : 생략가능, 웬만하면 명시적으로 쓰소잉
SELECT name as "나라이름"
FROM country
WHERESELECT name as "나라이름"
FROM country
WHERE Continent like "%i_"
and region is null
and population between 100000 and 200000
and code in ('AAA', 'ABC', 'AIA');실행순서
1. from
2. where
3. group by
4. having
5. select
6. order by테이블 제약사항
primary key
- 식별자 역할
- not null, unique
foreign key
- 외래키
- 다른 테이블의 P.K 또는 F.K를 참조
- 참조중인 부모 테이블의 컬럼의 값이 삭제/수정
- restrict :
해당 부모테이블의 데이터를 참조하는 자식 테이블이 있다면 부모데이터 삭제/수정 불가능 - cascade :
해당 부모테이블의 데이터를 참조하는 자식 테이블이 있다면 자식테이블의 데이터 또한 삭제/수정 - set null :
해당 부모테이블의 데이터를 참조하는 자식 테이블이 있다면 부모데이터를 삭제/수정 시, 자식테이블의 데이터 null로 변경
- restrict :
unique
- 유일한 값 보장
default[값]
auto_increment
- 데이터 추가 시, 값을 부여하지 않아도 자동으로 1씩 증가하며 값 부여
- P.K로 지정할 컬럼이 마땅하지 않은 경우(식별자 역할할 수 있는 칼럼), 새로운 컬럼을 만들어 auto_increment부여하여 PK로 지정
check (조건절)
- 조건절을 만족하는 데이터만 넣을 수 있음
current_timestamp
집계 함수
min()
max()
avg()
sum()
count()
DML / TCL / DDL
DML(Data Manipulation Language)
- select
- insert
insert into [테이블명] (col1,col2) values(val1,val2) - update
update[테이블명] set col1 = val1, col2 = val2 where id = '1'; - delete
delete from[테이블명] where id='3';
TCL(Transaction Control Language)
- start transaction
- commit
- rollback
- savepoint p1 (rollback to pq)
p1 포인트의 작업만 되돌림
DDL(Data Definition Language)
- create
- alter
- drop
- truncate [테이블명]
해당 테이블의 모든 row 삭제
해보면 좋을 것들
-테이블 생성하는 방법
-특정컬럼의 제약조건 생성하는 방법
-컬럼명 변경하는 방법
Index, view 개념 및 특징, 기본 사용법
인덱스의 특징
- 조회 속도를 향상 시켜줌
- 보조인덱스의 경우, 데이터 수정/삭제 시 인덱스까지 함께 관리해야하기 때문에 부하가 생김
- 인덱스 사용 시, 여러가지를 고려해야함.
- 데이터가 충분히 多
- nullable 하지 않은 컬럼
ㄴ null값이 많다면 효과가 미미(찾으려고 탐색해서)
- nullable 하지 않은 컬럼
- where조건절, join 시 자주 사용되는 컬럼
- 카디널리티가 높은 컬럼
ㄴ 중복데이터가 적은 컬럼
- 카디널리티가 높은 컬럼
- 선택도가 낮은 컬럼
ㄴ 조회 결과가 원본데이터의 약 5%미만
- 선택도가 낮은 컬럼
mysql에서 자동으로 인덱스를 만들어주는 경우
- unique, foreign key의 경우 보조 인덱스 자동 생성
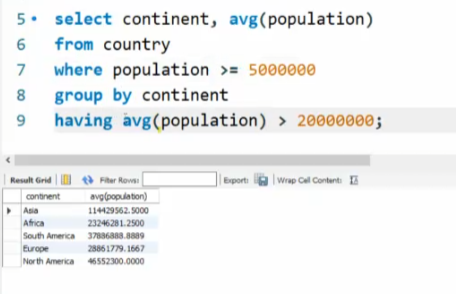
group by와 having 절
- where절은 원래 있던 값에 적용
- having절은 그룹화된 결과에 적용
- having절은 집계함수와 사용될 수 밖에 없음
JDBC의 특징
- Java DataBace Connectivity
데이터베이스가 변경되더라도 동일한 API를 사용할 수 있다.
JDBC 주요 클래스
- Driver 인터페이스
- 자바 어플리케이션과 DB간 상호작용을 위한 zmffotm
- DriverManager 인터페이스
- 드라이버 관리
- 자바 응용프로그램과 DB와 연결하는 역할
Connection conn = DriverManager.getConnection(url,user,password); - Connection 인터페이스
- DB와의 연결 정보를 가지고 있음
PreparedStatement pstmt = Connecion.prepareStatement(sql); - PreparedStatement 인터페이스
- 쿼리 실행, 결과 반환
- 조회
ResultSet rs = PreparedStatement.executeQuery(); - 삽입/수정/삭제
int cnt = PreparedStatement.executeUpdate();
- ResultSet 인터페이스
- 조회 결과 정보 담고 있음
ResultSet.next()를 통해 포인터를 다음 행으로 이동- 가장 처음에는 맨 위 비어있는 행을 가리키고 있음
ResultSet.getXXX(label || index)ResultSet.getString(label||index )ResultSet.getInt(label||index )
해보면 좋을 것
class파일 하나 만들어서 해보기
