
1. 빅데이터 기술 기초 다지기
아파치 하둡(Apache Hadoop) : 높은 확장성과 신뢰성을 보유한 분산 스토리지와 분산 처리 기능을 제공하기 위해 다양한 소프트웨어를 밀접하게 통합한 에코시스템. 대표적으로 분산 파일 시스템 HDFS(Hadoop Distributed File System)과 분산 서버 클러스터 환경에서 프로세스를 실행하는 YARN(Yet Another Resource Negotiator)가 있다.
클러스터(Cluster)란?- 저장이나 연산 등 하나 이상의 기능을 제공하기 위해 협력하는 서버의 조합.
마스터(Master)와워커(Worker)가 존재- 마스터: 워커를 조율하는 역할을 담당하며, 워커 장비에서 실행되는 서비스나 데이터에 대한 메타 데이터를 관리하고 워커 장비의 일부에 장애가 발생하더라도 서비스가 멈추지 않고 계속 실행 될 수 있게 보장.
- 워커 : 실제 작업을 수행하며, 데이터를 처리하고 연산을 수행하고 조회나 검색 등의 서비스를 제공하는 역할
1-1. 하둡 에코시스템 둘러보기
하둡 에코시스템은 하둡을 중심으로 만들어진 데이터 엔지니어링 프로젝트와 프레임워크 전부를 의미.
여기서는 프로젝트의 의존 관계를 데이터와 제어 두가지로 구분함.
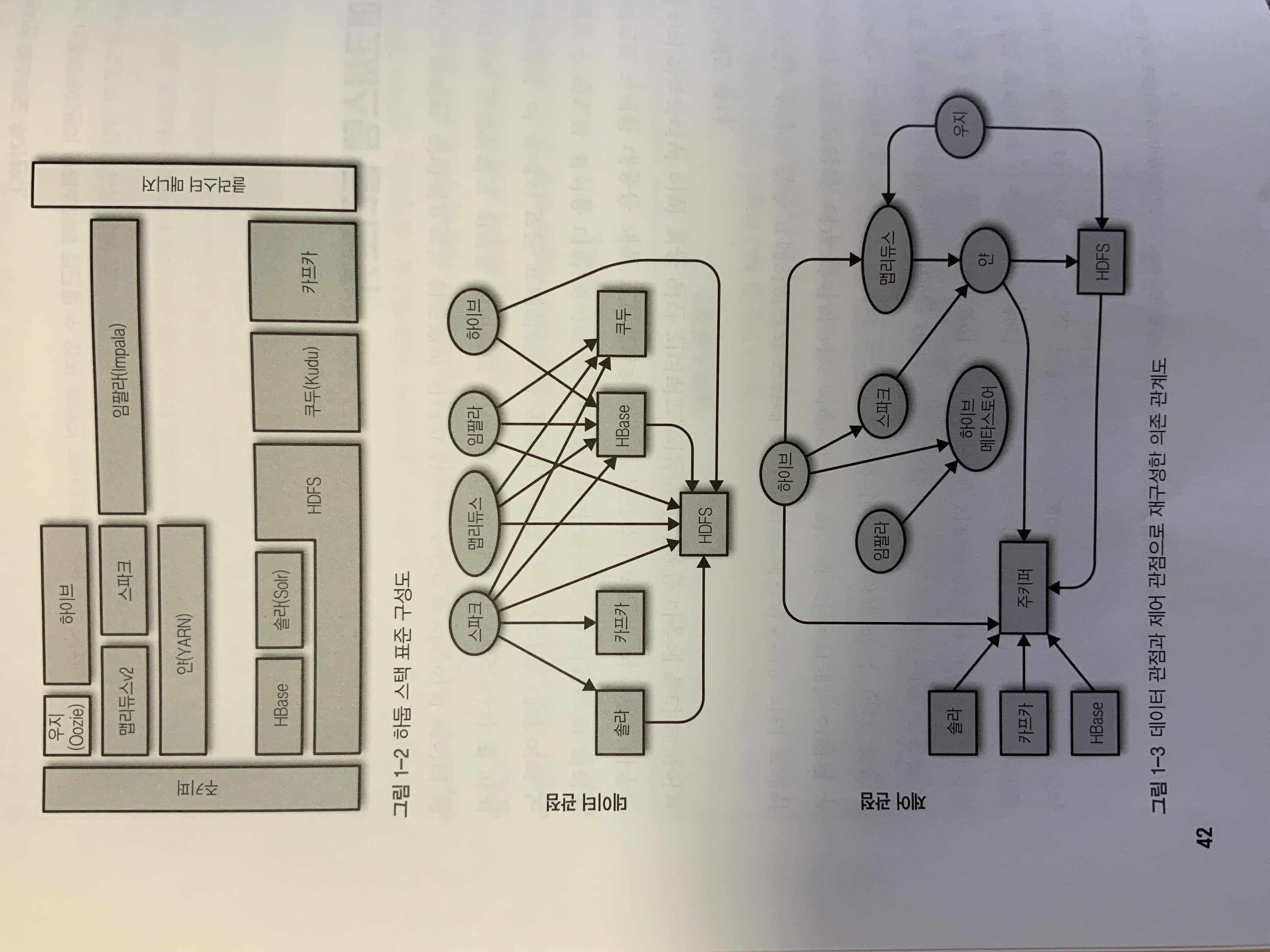
핵심 컴포넌트
-
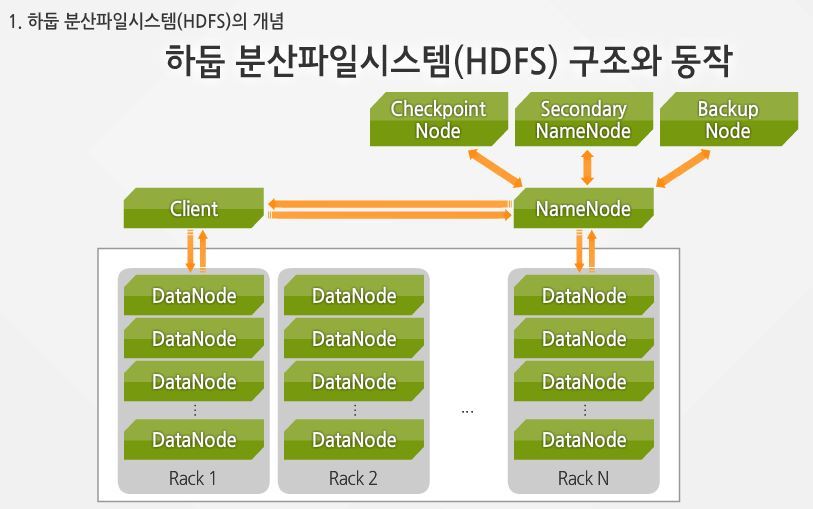
**HDFS**-
**하둡 분산 파일 시스템(Hadoop Distributed File System)**은 확장성과 장애 허용성을 가진 분산 파일 시스템 -
상당히 긴 순차 접근(Sequential access) 방식을 통해 디스크에 불변 데이터를 저장하는데 최적화돼 있음
-
데이터를 설정 가능한 크기의 block으로 나눠 저장.
-
기본은 128MB이며, 데이터 회복성 및 데이터 병렬 처리를 위해 여러대의 서버에 각 블록의 복제본을 저장
-
클러스터에 있는 워커 노드는
데이터 노드(Data node)데몬을 실행 새 블록을 전달받아서 로컬디스크에 저장- 데이터의 저장 및 제공을 담당
- 블록과 블록의 ID만 알고 있음
-
마스터 서버에서 실행되고 있는
**네임 노드(Name node)**는 파일 자체의 메타 데이터를 관리- 파일이 어느 복제본에 속하는지에 대한 정보
- 파일과 블록 사이의 매핑 정보
- 파일 이름, 권한, 속성, 복제 계수(Replication factor)등에 대한 정보
-
불변성을 위해 파일의 일부분 수정을 지원하지 않음.
-
-
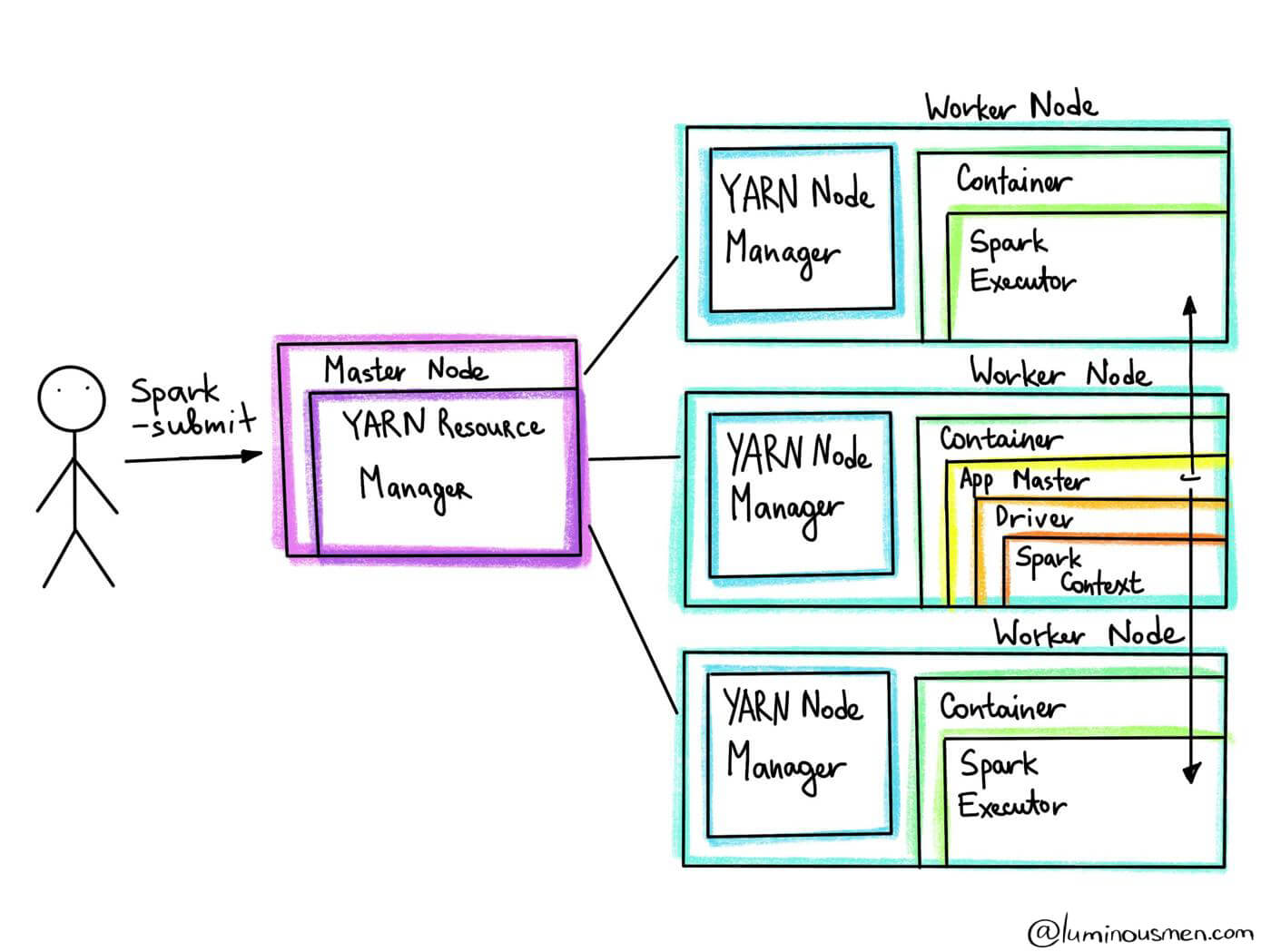
YARN(Yet Another Resource Negotiator)-
작업 스케줄링, 클러스터 리소스 관리를 위한 프레임 워크
-
워커 노드 안에
노드 매니저(Node Manager)가리소스 매니저(Resource Manager)에 다양한 정보 전달- 가상 코어(vcore)의 단위로 얼마나 많은 연산 자원을 사용할 수 있는지
- 해당 노드에 메모리가 얼마나 남아 있는지
-
-
ZooKeeper-
분산 환경에서 서버들간의 상호 조정이 필요한 다양한 서비스 제공
-
하나의 서버에서 처리한 결과를 다른 서버들과 동기화(데이터 안정성 보장)
-
운영(active) 서버에서 문제가 발생하여 서비스 제공할 수 없는 경우 다른 대기중인 서버를 운영서버로 변경하여 중지없이 제공
-
하나의 서버에만 서비스가 집중되지 않도록 서비스를 분산하여 동시에 처리
-
중앙 집중식 서비스로 분산처리 및 분산 환경을 구성하는 서버 설정을 통합적으로 관리
-
지노드(znode): 데이터를 가지고 있으며, 0개 이상의 자식 노드를 가질수 있음 -
앙상블(ensemble): 회복성을 확보하기 위해 인스턴스를 각기 서로 다른 서버에 배포 -
쿼럼(quorum): 다수결 원칙에 따라 합의(consensus)를 이끌어 내므로 홀수의 서버에 배포하고 이때 과반수의 서버로 이루어진 그룹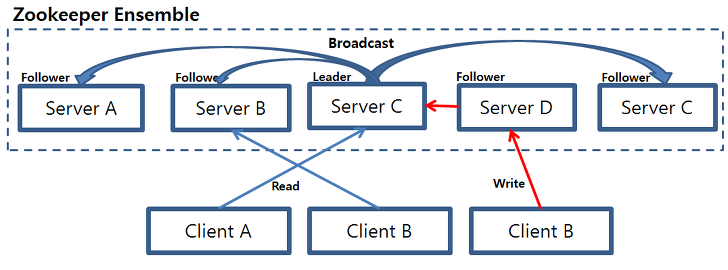
프로젝트 주키퍼 사용 목적 HDFS 고가용성 조율 HBase 메타데이터 관리 및 조율 솔라 메타데이터 관리 및 조율 카프카 메타데이터 관리 및 조율 얀 고가용성 조율 하이브 테이블 및 파티션 잠금 및 고가용성
-
-
아파치 하이브(Hive) 메타스토어- 하둡 내에 존재하는
비정형 바이너리 데이터(unstructured binary data)가 아닌정형 데이터셋(structured dataset)에 대한 정보를 데이터 셋, 테이블, 뷰 같은 논리적인 위계 구조로 구성해서 관리 - HDFS에서는 하이브 테이블이 디렉토리와 같다.
- 파티셔닝을 지원하며, 파티션된 테이블은 HDFS 상에서 하위 디렉토리를 가지게 된다.
- 하나의 테이블 안에서의 모든 파일은 동일한 포맷으로 저장돼야 한다.
관리형 테이블(managed table),외부 테이블(external table)을 지원- 관리형 테이블 사용시 테이블 삭제되면 스토리지 엔진에 저장된 데이터를 모두 삭제
- 외부 테이블 사용시 데이터베이스에 있는 테이블의 메타데이터만 관리
- 하둡 내에 존재하는
연산 프레임워크
-
하둡 맵리듀스(MapReduce)- 대용량 데이터를 분산 처리하기 위한 프로그래밍 모델 프레임워크
- MapReduce Framework를 이용하면 대규모 분산 컴퓨팅 환경에서, 대량의 데이터를 병렬로 분석 가능
- 연산을
맵(Map),셔플(Shuffle),리듀스(Reduce)3 단계로 나눠서 처리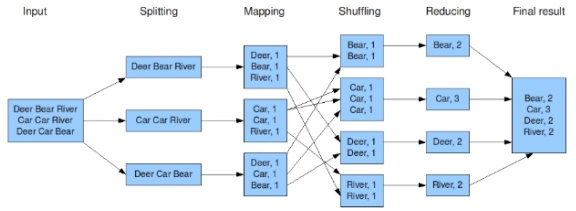
-
아파치 스파크(Spark)- 효율성과 사용성에 중점을 둔 분산 연산 프레임워크
- 다수의 저사양 장비로 이루어지는 워크 노드에 있는 메모리를 최대한 활용하는 것
- 배치 연산과 스트리밍 연산을 모두 지원
- 데이터셋에 직접 적용할 수 있는 풍부한 API를 제공
- 프로세싱 그래프가 표준 쿼리 옵티마이저를 거친 후에 실행
- 스파크 표준 쿼리 옵티마이저 : 관계형 데이터베이스 혹은 대규모 병렬 쿼리 엔진의 쿼리 옵티마이저와 비슷
- 파이프라인 실행의 효율성을 극대화 하기 위해 프로세싱 그래프를
재배치(rearrange),결합(combine),가지치기(prune)사용
- 파이프라인 실행의 효율성을 극대화 하기 위해 프로세싱 그래프를
분석용 SQL 엔진
-
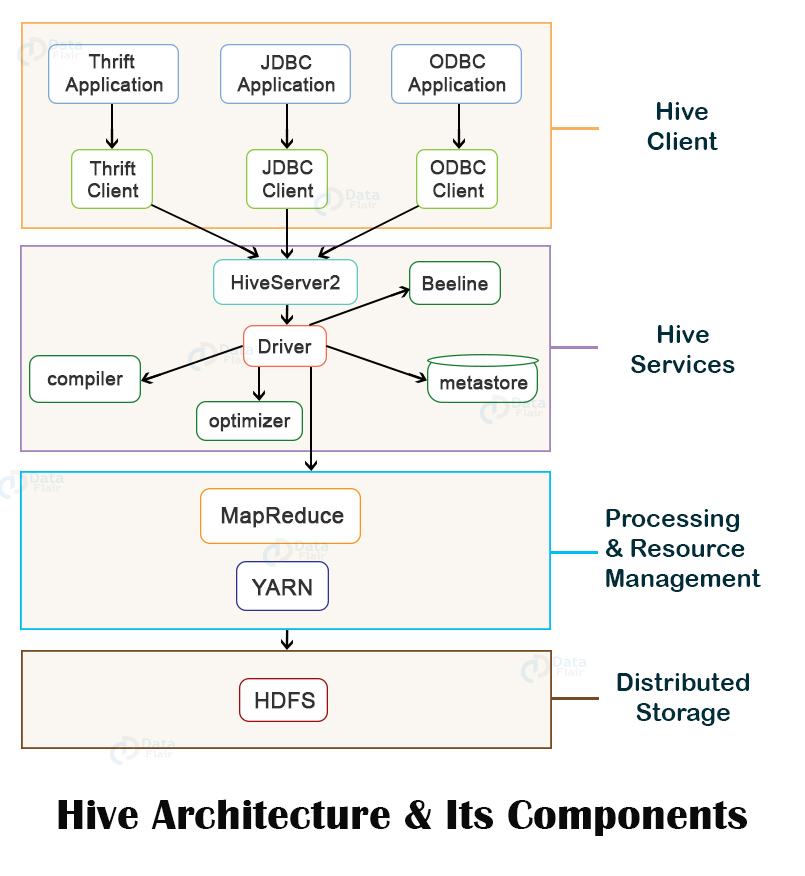
아파치 하이브(Hive)- 하둡에 사용되는 원조 데이터 웨어하우징 기술
- HDFS에 저장된 정형 데이터를 SQL과 비슷한 문법(하이브QL)으로 쿼리할 수있게 만든 기술
- ETL(추출(Extract), 변환(Transform), 적재(Load)), 보고서 데이터 생성, 벌크 데이터 처리 등 오프라인 배치 작업에 적합
-
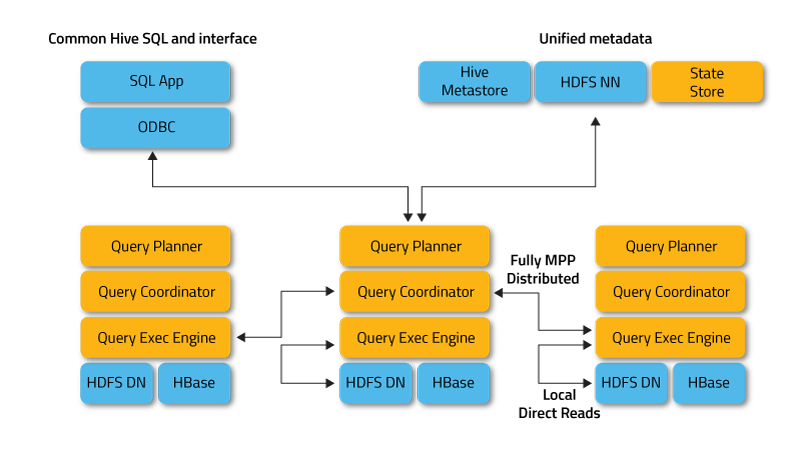
아파치 임팔라(Impala)- 대규모 병렬 처리(Massive Parallel Processing) 엔진
- MapReduce를 사용하지 않고 C++로 개발한 인메모리 엔진을 사용하여 빠른 성능을 보여줌
- 하둡이나 클라우드 스토리지에 저장된 대용량 데이터셋에 대한 고속, 대화형 SQL 쿼리를 목적으로 설계
- 테라바이트 단위의 데이터에 대해 다수의 동시 실행 애드혹 쿼리, 보고서 스타일의 쿼리를 수초내에 처리하는 것이 목표
스토리지 엔지
-
아파치 HBase-
HDFS의 컬럼(열) 기반 데이터베이스
-
분산 테이블에 cell이라고 불리는 키-값 쌍의 반정형 데이터 형식으로 HDFS에 저장
-
실시간 랜덤 조회 및 업데이트 가능
-
각각의 프로세스들은 개인의 데이터를 비동기적(동시성 X)으로 업데이트 할 수 있음. 단 MapReduce는 일괄처리 방식으로 수행!
-
Hadoop 및 HDFS위에 Bigtable과 같은 기능을 제공
-
Cell key를 위계 구조(hierarchy)를 가지도록 세분화
-
로우 키: Cell의 논리적인 그룹인 로우row를 정의함 -
컬럼 패밀리: 메모리와 디스크에 분리되어 저장되고, 컬럼 한정자로 세분화되는데 하나의 로우에 수백만 개의 컬럼 한정자가 있을 수 있음.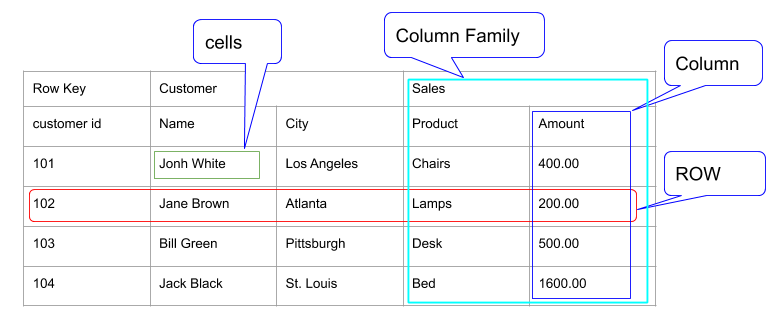
-
버전: 타임스탬프로 되어 있음. -
리전(region): HBase에서 수평확장의 기본단위이며, 함께 저장되는 테이블의 부분집합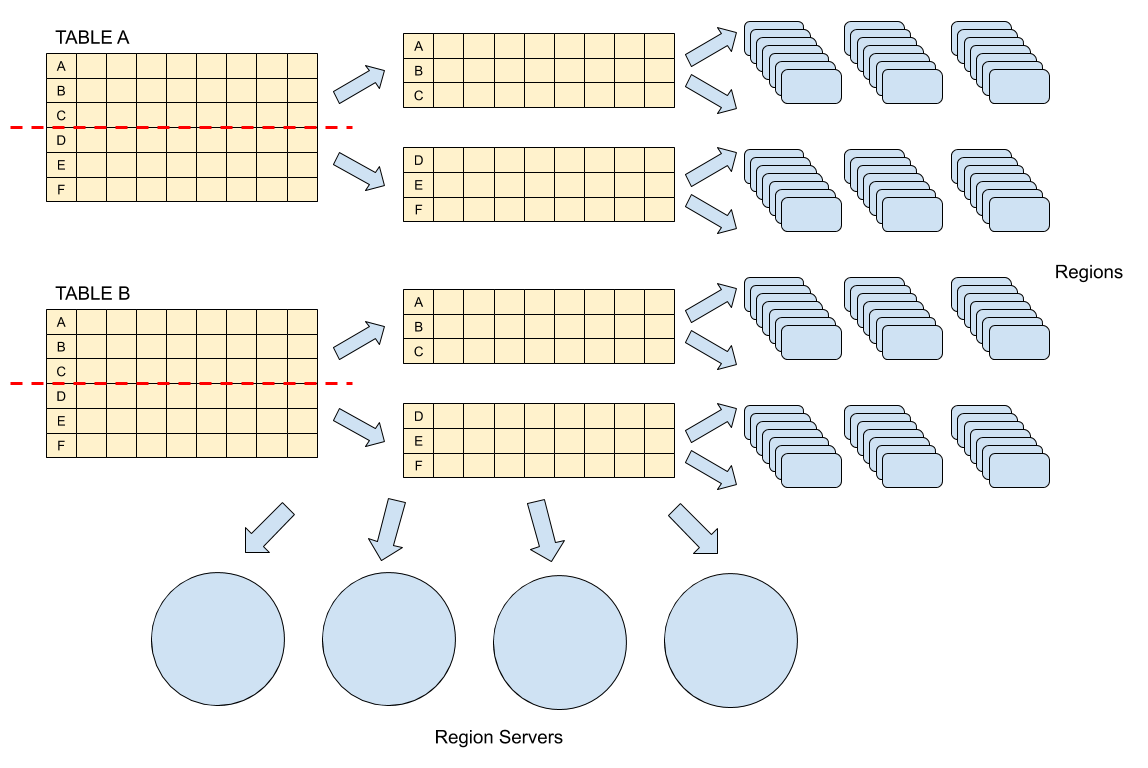
-
-
-
아파치 쿠두(Kudu)- 미리 정의된 스키마를 따르는 테이블에 타입을 가진 컬럼으로 구성된 레코드를 저장하는 정형 데이터 스토어
- 컴럼의 일부는 테이블의 기본 키로 사용되며, 인덱스가 생성됨
- 파티셔닝 매커니즘
범위 파티셔닝(Range Partitioning): 각 태블릿은 상한과 하한으로 이뤄진 범위를 갖고 있으며, 범위 내에 들어가는 파티션 키를 가진 모든 레코드는 해당 태블릿에 저장해시 파티셔닝(Hash Partitioning): 사용자는 테이블 파티셔닝의 기준이 되는 고정된 수의 해시 버킷을 지정할 수 있고 각 행에서 선택된 컬럼의 해시 값을 해시 커빗 수로 나눈 나머지를 기준으로 태블릿에 저장
-
아파치 솔라(Solr)- 정보검색 라이브러리인 루씬의 엔터프라이즈 버전
- 텍스트 검색, 다면적 검색, 실시간 인덱싱, 클러스터링, 데이터베이스 통합, 다양한 문서처리 및 솔라 분산 인덱싱 등 기능을 지원
- 루씬에서 나온 개념인 역방향 인덱스(inverted index)를 사용
-
아파치 카프카(Kafka)- 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산 데이터 스트리밍 플랫품
- 입수되는 메시지를 분산 저장되는 순차적인 로그로 저장하고, 클라이언트나 크라이언트의 그룹은 간단한 숫자 형태의 오프셋을 이용해 특정 지점으로부터의 데이터를 가져옴
- 다양한 업스트림 소스와 다운스트림 싱크를 통합하고 회복성있는 고가용성 입수 버퍼를 제공
토픽(topic): 기초가 되는 데이터 구조브로커(broker): 여러대의 서버프로듀서(producer): 카프카 토픽의 파티션으로 메시지를 발행컨슈머(consumer): 토픽에 있는 데이터를 읽음컨슈머 그룹(consumer group): 확장성을 위해 여러 컨슈머로 묶을 수 있음
데이터 입수
-
아파치 플룸(Flume)
- 대량의 로그 데이터를 여러 소스에서 수집하여 저장하기 위한 목적
- 이벤트 : 플룸에서 전달하는 데이터 단위
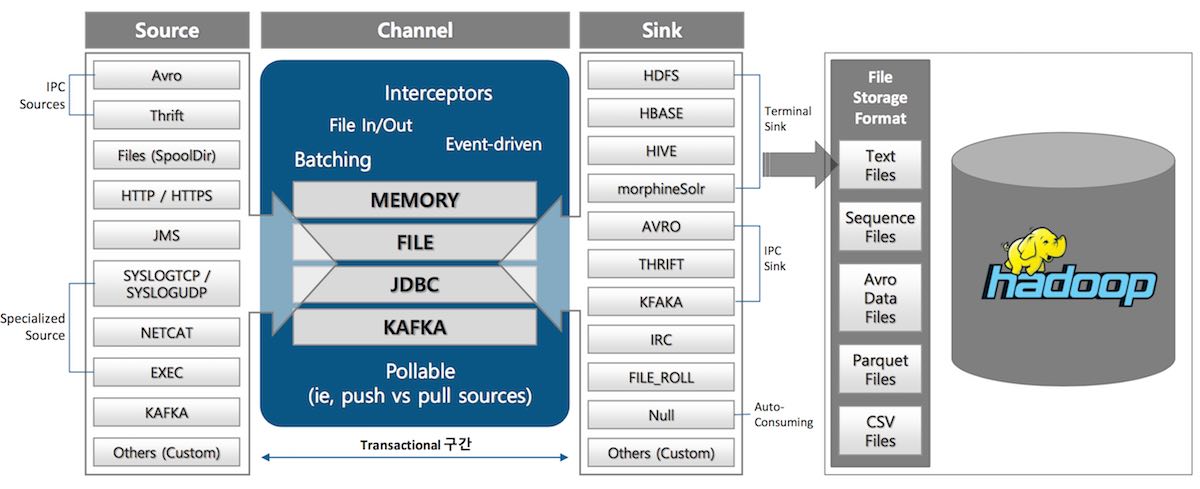
-
아파치 스쿱(Sqoop)
-
관계형 데이터베이스와 하둡 사이에서 데이터 이관을 지원하는 툴
데이터 임포트

데이터 익스포트

-
컴포넌트 요약
| 프로젝트 이름 | 설명 | 용도 | 의존 관계 |
|---|---|---|---|
| ZooKeeper | 분산 설정 서비스 | 분산 프로세스와 분산 잠금 사이의 메타데이터 공유 | 없음 |
| HDFS | 분산 파일 스토리지 | 불변 데이터를 위한 확장성 있는 스토리지 | ZooKeeper |
| Yarn | 분산 리소스 스케줄링 및 실행 프레임워크 | 확장성 있는 분산 컴퓨팅 자원을 필요로 하는 프레임워크 | ZooKeeper, HDFS |
| MapReduce | 범용 분산 연산 프레임워크 | 배치 연산 작업 | Yarn, HDFS |
| Spark | 범용 분산 연산 프레임워크 | 배치, 분석 SQL, 스트리밍 작업 | 자원 스케줄러(Yarn, Mesos) 및 데이터 소스(HDFS, Kudu 등) |
| Hive | SQL 기반 분석 쿼리 프레임워크 | 분산 SQL 작업 | Yarn, 데이터 소스(HDFS, Kudu) |
| Impala | SQL 기반 대규모 병렬 처리 분산 엔진 | 분석 및 대화형 SQL 작업 | 데이터 소스(HDFS, Kudu, HBase) |
| HBase | 위계 구조를 가진 키-값 데이터 분산/정렬 스토어 | 정형 키를 가진 로우 기반 데이터에 대한 고속 랜덤 읽기/쓰기 | HDFS, ZooKeeper |
| Kudu | 정형 데이터용 분산 스토어 | 랜덤 읽기/쓰기 및 분석 작업 | 없음 |
| Solr | 엔터프라이즈 검색 프레임 워크 | 확장성 있는 도큐먼트 인덱싱 및 임의 필트 쿼리 | HDFS, ZooKeeper |
| Kafka | 분산 발행/구독 메시징 프레임워크 | 데이터 프로세싱 파이프라인의 주기적 또는 실시간 실행 | ZooKeeper |
