[DB] #01. Introduction to Databases
Database

1.1 Databases
데이터베이스를 사용하는 목적
- 데이터 관리 : 데이터 저장, 삭제, 수정 등
- 주체 : user
DB, DBMS, DBS

- DB
- 서로 연관 있는 데이터의 모임
- DBMS
- 사용자에게 데이터 관리에 필요한 기능 제공
- 데이터 정의, 생성, 변경, 삭제, 접근, 조작하는 기본적인 연산 기능 제공
- 데이터 추상화, 데이터 독립성, 데이터 보호 등의 다양한 기능 제공
- 명령어를 처리하는 주체
- DB와 직접적 상호작용
- DBS
- DataBsase System
- DB + DBMS
DBMS 장점
- Data abstraction : 데이터 추상화 제공 → 사용자가 쉽게 데이터베이스 접근 가능
- Easy accessing data : 접근 용이성
- 데이터 접근을 위한 언어 + 사용자 인터페이스 제공
- application만 있으면 됨.
- query : select, from, where
- controlled data redundancy, inconsistency : 데이터 중복 및 불일치성에 대한 제어
- 불일치성 : 데이터 간에 값이 서로 일치하지 않은 현상
- file system : 데이터 중복 → 불일치 발생하기 쉬움
- Integrity constraint : 무결성 제약 강화 ⭐️
- 무결하다 : 어떤 상황에서든 조건을 만족시킨다.
- ex. year(학년) : {1, 2, 3, 4} , 0 ≤ grade ≤ 4.5
- Atomicity of updates : 갱신 원자성 제공
- 갱신 시 연산이 부분적으로 반영 X, 원자적으로 이루어져야 함.
- 부분적 → 불일치 및 제약 조건 만족하지 않는 경우 발생
- Atomicity 원자성
- 고장 및 오류 상황에서도 대비할 수 있도록 보장함.
- ATM 500 500 / 1000 0 → 1000 500 이 되면 안 됨 !
- all(500 500) or nothing(1000 0)이 되어야 한다.
- Consistency 일관성
- 실제와 동일하게 보장해준다.
- Isolation 독립성

- user간 read/write 연산의 독립성 보장
- Durability 지속성
- 항상 정상적인 값이 DB에 저장되어야 한다.
- Concurrent access by multiple users : 다수 사용자의 동시성 제어
- Data security : 데이터 보호
- 악의적인 데이터 접근으로부터 데이터 보호
- file system : os가 제공하는 데이터 보호 기능 사용, 초보적인 수준
- Data backup & recovery : 데이터 백업 및 회복
- 시스템 장애 발생 대비 → 손실 방지
- 매우 중요, 구현 복잡
File Systems
- OS가 제공하는 기능
- pile(파일) : file(화일)을 구성하는 방식 중 하나
- 과거 : 파일 단위로 데이터를 관리 → 문제 : ACID를 보장하기 어려움
- 여러가지 제약 사항 → 화일 시스템만으로는 효율적인 DB 관리 불가능
1.2 Data Abstraction and Data Model
Instances and Schemas
- 사용자 지정 타입
→ DB에서는 타입이라는 용어보다는 Schema를 사용struct Student { ... }; struct Student s[60]; //타입을 사용하기 위한 객체 생성 s[0].id = 20212908; //데이터 생성create Student { ... }; - Instance = 변수의 값, schema = 변수의 타입
- Schema
- DB의 논리적, 물리적 구조
- 실제 데이터값이 schema 형태로 저장 관리
- Instance
- 데이터의 실제 값
- 시간의 흐름에 따라 자주 변경 (↔ schema는 자주 변경 X)
Abstraction in Computer Science
- Abstraction 추상화
- 개체들을 설명하기 위해
- 공통적인 속성을 뽑아내서
- 하나의 타입 형태로 만드는 과정
- 추상화 레벨에 따라 사용자에게 보이는 상세한 정도 달라짐
- 사물을 보는 높이에 따라 description 수준에 차이 발생
- 추상화 레벨도 함께 고려해야함
Three Level Abstraction
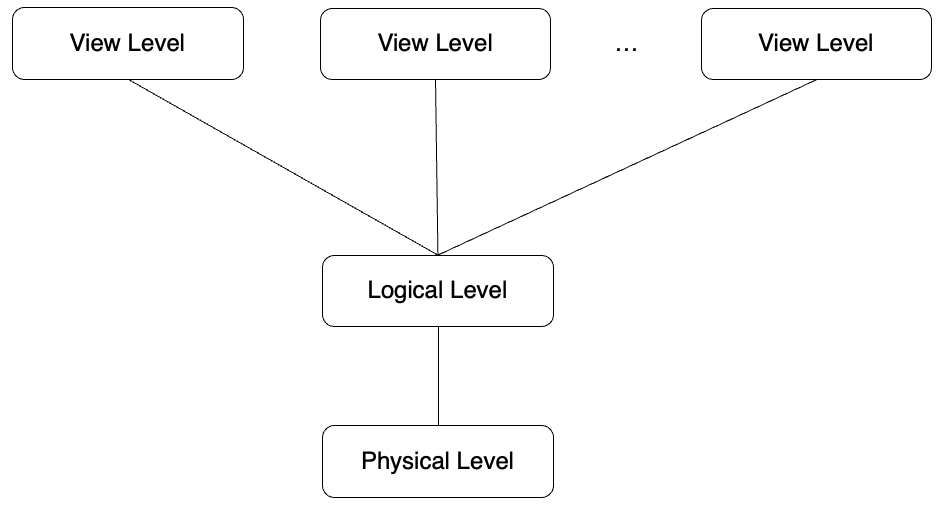
위에서 아래로 갈 수록 복잡해짐
- 실제로는 저장장치(디스크)에 복잡하게 존재 → 이를 추상화하여 세가지 다른 관점에서 조망
- 각 레벨마다 기술하는 추상화 방법은 DBS마다, Model마다 상이
- Physical level
- 실제 데이터 record가 어떻게 저장되는지 기술
- 데이터 필드 길이, 필드 간의 간격, 레코드의 전체 길이 등
- Logical level
- 데이터와 데이터간의 관계를 논리적 관점에서 추상화
- 예제>
type professor = record ID : string; name : string; department : string; salary : integer; end;- professor : 하나의 레코드
- ID, name, deparment, salary 등 4가지 구성요소로 이루어짐을 기술
- View level
- 특정 user가 흥미있어하는 database의 부분만을 추상화
- 보안 목적으로 나머지 부분은 숨김
- 동일 Logical Level에서의 추상화에 대해 다수 개의 서로 다른 View Level 추상화 가능
Three-schema Architecture
- 3단계 스키마 구조
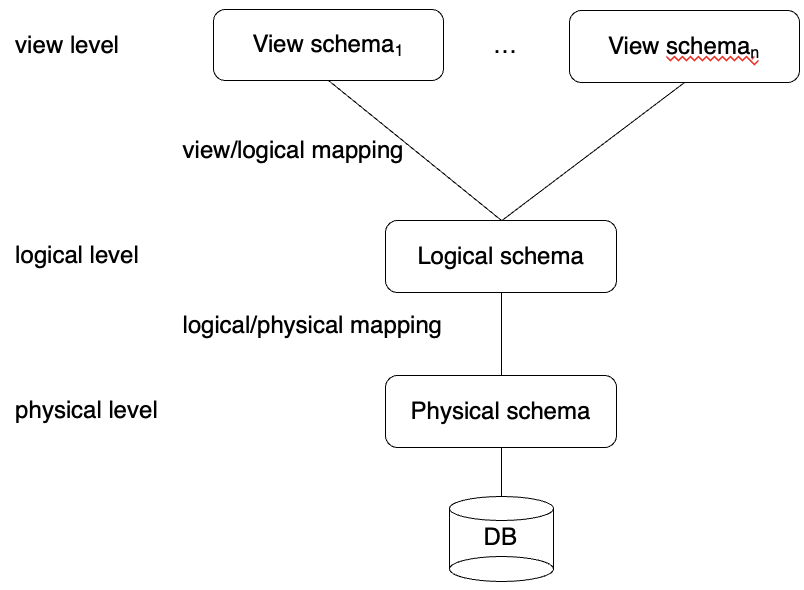
- 각 schema는 schema간의 변환을 이용해 레벨에 따른 Data View 제공
- 일명 ANSI/SPARC 구조
Data Independence
- Physical data independence
- 논리적 스키마 변화없이 물리적 스키마를 변화할 수 있는 기능
- Logical data independence
- 뷰 스키마 변화없이 논리적 스키마를 변화할 수 있는 기능
- View Schema
- 최종 사용자가 보는 데이터베이스 스키마
- 사용자는 이를 기반으로 DB 프로그램 응용 및 개발
- 데이터 독립성
- 사용자에게 많은 편이를 제공하는 기능
- 대부분 상용 데이터베이스시스템이 지원
- file system : 독립성 제공 X
Data Model
- Data Model
- 기술하는 명세
- 데이터 2. 데이터 관계성 3. 데이터 의미 4. 데이터 제약 조건 등
- 데이터 추상화를 지원하는 개념적인 도구
- Model 이용 → 데이터 기술, 조작
- 기술하는 명세
- 종류
-
Relational data model (관계형)
→ 80년대 이후 가장 많이 사용
-
Object-relational data model (객체관계형)
→ Relational + Object-oriented 장점 합쳐놓은 것
-
Object-oriented data model (객체지향)
-
Entity-Relationship data model (개체-관계)
→ database design 목적
-
XML
→ semi-structured data 목적
-
Hierarchical data model (계층)
-
Network data model (네트워크)
→ 현대사회에서 더이상 사용 X, 이를 지원하는 구 시스템 : legacy system
-
- 상용 DBMS : 데이터 Model 중 하나를 지원
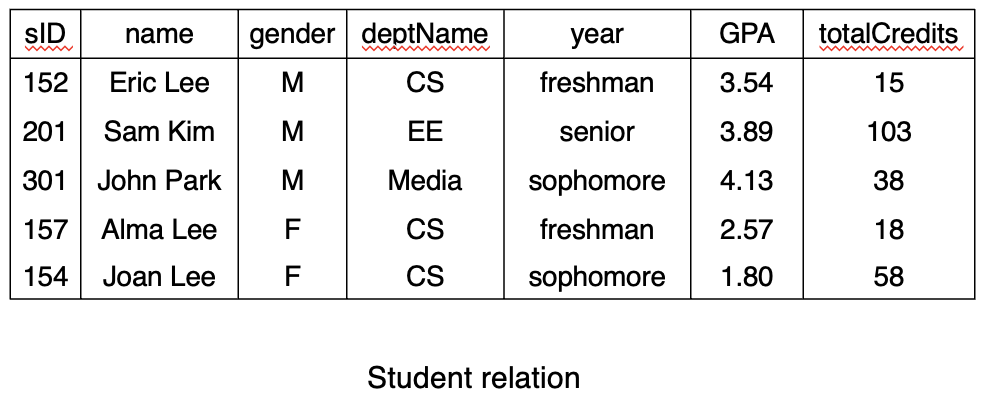
Relational Data Model
- 80년대 이후 가장 많이 사용되는 데이터 모델
- table 형태로 표현
- 기본 요소 = 관계 (relation)
Object-Relational Data Model
- 관계형 모델의 확장 : 관계형 데이터 모델 기반 + 객체지향 요소 부분적 도입
- 현재 가장 인기있는 데이터 모델
- 객체 관계형을 지원하는 DBS는 통상 관계형도 지원
- tuple의 속성이 complex type 가질 수 있도록 허용 ⁉️
- complex type : 중첩관계와 같은 비원자성 값 포함
- 모델링 기능 확장 시 ⁉️
- 관계형 기반, 데이터 접근에 대한 선언적 access 유지
- 기존 관계형 언어와의 상향 호환성 제공
XML (Extensible Markup Language)
- 웹 관련 국제 표준 기술
- W3C(월드와이드웹 컨소시엄)에서 정의
- SGML(표준 일반화 마크업 언어)에서 파생 → SGML보다 더 간단한 사용
- 문서 마크업 언어로 개발 → 현재는 문서 교환을 위한 표준 기술로 사용
- 데이터 교환 용이
- 새로운 태그 지정, 충접된 태그 구조 생성 기능 제공
- 데이터(문서) 교환의 기술적 문제 해결
- 구문 분석, 탐색, 쿼리 목적의 다양한 도구 지원
- 현대 상용 DBS에 널리 지원
Database Design
- 데이터베이스 설계
- 데이터베이스 구조를 설계하는 작업
- 사용자 요구사항 분석 → 좋은 Schema 생성
- DBS performance(성능)에 매우 중요
- Physical Design
- DB의 physical layout에서 결정
- Physical Schema 생성
- Logical Design
- DB Schema에서 결정
- Logical Schema, View Schema 생성
Database Design Approaches
-
Entity-Relationship Model [10장]
-
DB 설계 방식 중 가장 널리 사용되는 방식
-
enterprise : { entity(개체) + 관계성 } 으로 모델링
- entity : 서로 구분되는 것 (thing, object)
- relationship : 개체 간의 관계
-
entity-relationship diagram : 도식적으로 표현
→ 대상 DBMS schema에 매핑

-
Takes : ‘학생이 과목을 수강하다’ 라는 관계성
-
year : 관계성이 가지는 속성
→ DB가 관리하고자하는 데이터에 대한 기술
-
-
-
Normalization Theory [11장]
- 어떤 설계가 나쁜지 공식화 → 좋은 schema를 얻는 방법
1.3 Database Systems
Database Languages
- DBMS : 사용자들이 원하는 바를 표현하기 위해 DB 언어 제공
- SQL, QUEL, 관계대수, 예제 질의 등 제안 및 구현
- SQL : 현대 DBS에서 가장 많이 사용되는 언어
SQL Examples
- 교수번호가 0921인 교수이름 검색하기
Select name from professor where pID = '0921'; - 교수번호가 0921인 교수가 강의하는 과목명 검색
Select title from teaches, course where teaches.cID=course.cID and pID='0921'; - DBS에 접근하는 DB 응용 프로그램 : SQL 언어를 활용하여 개발 (→ 8장)
- SQL에 프로그래밍 요소 추가하는 방식
- SQL API 방식
DBMS Components 구성요소
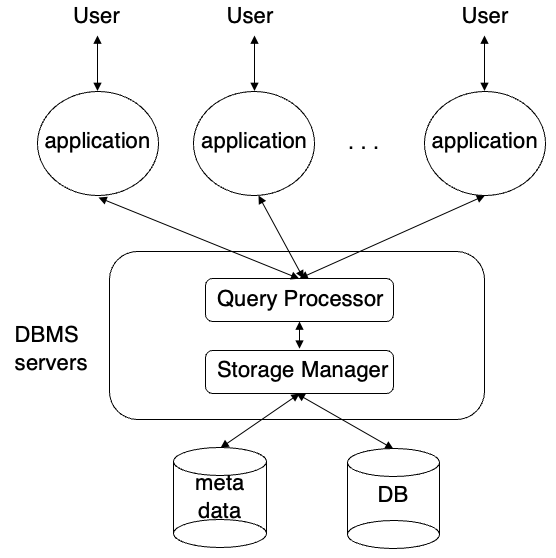
- Query processor 질의어 처리기
- 질의어 처리
- 권한 부여 및 철회
- 인증
- Storage manager 저장 관리자
- 데이터베이스 서버의 하단부분을 의미
- 데이터 저장, 검색
- 화일 구조, 색인, 트랜잭션 관리 등
- DB, meta data 관리
Data dictionary
- Data dictionary
- metadata를 저장하는 장소
- = directory, system catalog
- DB 언어를 처리하기 위해 DBMS가 참조하는 곳
- metadata : DB에 대한 데이터
-
Database schema : type
-
Integrity constraint : 제약 조건
-
Authorization : 접근 권한
-
Statistical data
→ 별도의 공간에 저장 및 관리
-
Transaction Management
- Transcation
- DB application에서 single logical function을 수행
- 일련의 데이터베이스 작업
- Concurrency control 동시성 제어
- 일관성 보장
- 동시 transaction 간의 상호작용 제어
- Recovery 복구
- 장애 발생 시에도 일관된 상태 유지 보장
Database Users
- Naive users
- Database application 이용 → 접근/관리
- 주어진 화면 형식에 의거하여 주어진 절차대로 사용
- Application programmars
- DBS에 접근하는 응용 프로그램을 개발하는 사용자
- Database designers
- Database analysts
- 다양한 데이터 분석 도구 이용 → DB 분석
- 빅데이터 시대 : 데이터 분석에 대한 중요성 증대
- Database administrator (DBA)
- DB에 대한 모든 권한을 가지고 있는 DBS의 superuser
- 모든 활동 주관
- schema 정의
- 저장구조 및 접근 방법 정의
- schema 및 물리 구조 변경
- DB 접근 권한 관리
- 제약 조건 관리
- 시스템 성능 관리
Database System Architecture
데이터 위치에 의거한 Database System 구조 분류
- Centralized 중앙집중식 데이터베이스
- Distributed 분산 데이터베이스
- Client-server 고객/서버 데이터베이스
- Parallel (multi-processor) 병렬 데이터베이스
- 병렬처리 기술을 데이터베이스 시스템에 적용
History of Database Systems
- 1960s
- 하드디스크 발명
- 그 전에는 Magnetic tapes에 데이터 저장 → tape : 순차적 접근, disk : 임의적 접근 가능(효율적)
- file system을 이용하여 자료 처리
- 1970s
- 본격적인 database 사용
- Network, Hierarchical Data Model 주로 사용 → legacy systems
- E.Codd 가 관계형 데이터모델 제안 → 단순한 모델로 복잡한 연산 효율적으로 처리 가능 → ACM Turing Award 수상
- 최초의 DB : System R (IBM Research)
- 1980s
- 관계형 모델을 지원하는 상용 데이터베이스 시스템 처음 출시
- DB 기술, 설계 기술, 트랜잭션 처리, 분산 데이터베이스에 대한 연구 및 개발 진행
- 객체지향형 DB 개념 정립
- 1990s
- 다량의 데이터 → data-mining, data warehouse 중요성
- 객체 관계형 데이터 모델 정립
- Web 등장
- 2000s
- Web상의 많은 데이터 처리 → XML standards
- 튜닝 및 자동 데이터베이스 관리 기술 발전
- 2010s
- 빅데이터 시대
- 원하는 정보를 찾기 위한 시간적 비용 증가
- 대용량 저장 시스템 : Google BigTable, Hadoop
- 대용량 분산 처리 플랫폼 개발
- NOSQL DB
- Not Only SQL
- 기존 DBMS보다는 다른 형태의 데이터 관리를 요구하는 응용 분야에 적합
- ACID 트랜잭션 지원을 통한 일치성, 강력한 질의어 제공, 구조적 데이터 저장 및 관리 강조 X → 성능을 위해 SQL의 약속을 완화시킴
- 분산 데이터 관리 및 운영, semi-structured 데이터 저장 관리
- 고성능, 유용성, 확장성 강조
