[DB] #05. SQL II
EXISTSFROMHAVINGIndexJOINNested Subqueriesaggregate functiondbdomainfor allgroup bylateralrankingsqltransactionuniquewith
Database
목록 보기
6/14

5.1 Aggregate Functions
Aggregate Functions
- 집계함수
- avg, min, max, sum, count 지원
- 테이블 속성에 적용 가능
- student 관계의 tuple 개수 찾기
Select count(*) from student;- 키 속성이 아닌 경우 Null값 존재 → 속성마다 다른 값 반환
- 2010년 봄에 강의한 교수의 유일한 값의 개수 찾기
Select count(distinct pID) from teaches where semester='Spring' and year=2010;
Group By Clause
-
group by절- 전체 테이블을 특정 속성 값으로 tuple 분류
- 분류된 각 그룹에 대해 집계 함수 적용
-
Example>
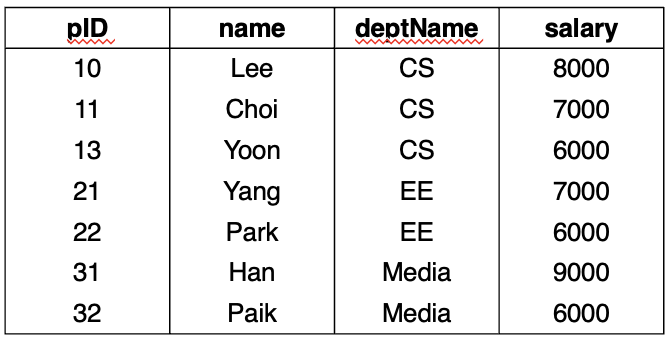
Select deptName, count(*) from professor group by deptName;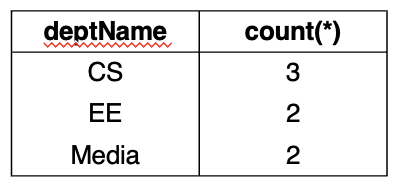
Select deptName, avg(salary) from professor group by deptName;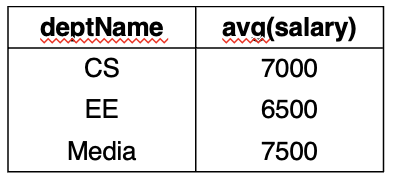
-
사용 시 주의 사항
group by절에 나온 속성 + 집계 함수만 select절에//Error : pID 때문 Select deptName, pID, avg(salary) from professor group by deptNamegroup by절에 나온 속성 →select절에 표시 필수 X
Having Clause
having절group by절 결과로 생성된 그룹에 대해 임의 조건 명시 →group by절 필수
- 사용자가 원하는 그룹만 보이게 하는 기능
where절 : 조건 각 tuple에 적용 → 조건 만족하는 tuple이 다음 단계로having절 : 각 그룹에 조건 적용 → 조건 만족하는 그룹이 다음 단계로 →where절 조건이 적용 후 생성된 그룹에having절 조건 적용
- deptName 값 기준으로 그룹 생성 → 각 그룹에 대해 avg(salary)>6900 조건을 만족하는 그룹만 select절이 표시
Select deptName, avg(salary) from professor group by deptName having avg(salary) > 6900; - 다섯명 이상의 종업원을 가진 부서에서 4만불 이상의 소득을 가진 종업원 수 구하기
→ 4만불 이상 소득을 가진 종업원을 5명 이상 가진 부서의 종업원 수 구하기//Wrong query Select dname, count(*) from department, employee where dnumber = dno and salary > 40000 group by dname having count(*) > 5;Select dname, count(*) from department, employee where dnumber = dno and salary > 40000 and dno in (select dno from employee group by dno having count(*) > 5) group by dname;
Null Values and Aggregates
- 집계함수 : Null 값 무시
- 모든 값 = Null : count → 0 반환, 나머지 → null 반환
5.2 Joined Relations
Joined Relations
- 조인 테이블
- 두 개의 입력 테이블 → 한 개의 결과 테이블
where절,from절에서 사용- Join type + Join condition
- Join type
- 조인 테이블의 조인 속성을 처리하는 방식 결정
- 조인되지 않은 tuple 어떻게 처리할 지 결정
- Inner join = join (Inner 생략 가능)
- Left outer join, Right outer join, Full outer join
Outer Joins
- 조인 연산에서 값 매치 X → 손실 X, 정보 유지
- 조인 연산 수행 → 제외된 tuple을 null값 이용하여 추가
Join Conditions
- 두 입력 테이블에서 어떤 조건으로 tuple 매치되는지 결정
- 어떤 속성이 결과 테이블에 나타날 지 결정
- 조인 조건
- 자연적인 방법
- 조인 조건을 명시하는 방법
- 자연 조인에 사용되는 속성을 명시하는 방법
using
Joined Relations Example

→ 공통 속성 = cID
-
Inner join
myCourse inner join myPrereq on myCourse.cID = myPrereq.cID //inner 키워드 생략 가능
→ 자연조인이 아닌 일반 조인 : 모든 속성이 결과 테이블에 표시
-
Outer join
myCourse left outer join myPrereq on myCourse.cID = myPrereq.cID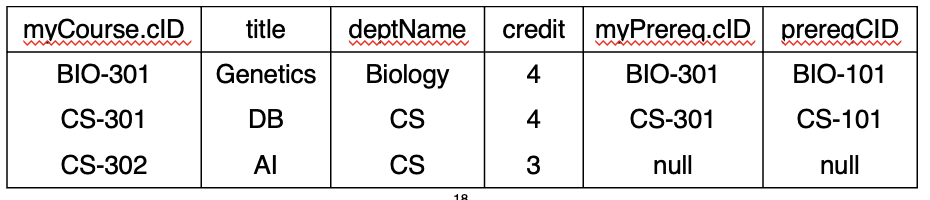
-
Natural Outer join
myCourse natural full outer join myPrereq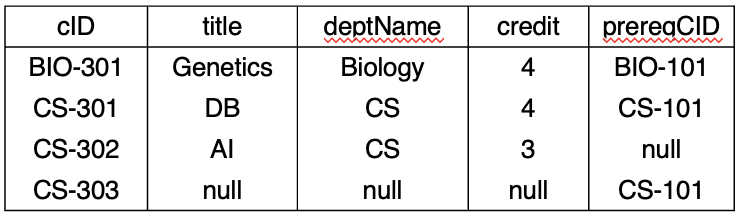
-
자연 조인 : 공통으로 존재하는 속성이 조인 속성
-
조인 속성은 결과 테이블에 한 번만
myCourse natural left outer join myPrereq myCourse left outer join myPrereq using(cID) // 두 표현식은 같은 결과 테이블 생성 -
using : natural 키워드가 없어도 자연 조인 생성
-
2023.10.12
5.3 Nested Subqueries
Nested Subqueries
- 중첩 서브 질의 지원
- select문장의 결과 = 테이블 → 테이블이 위치하는 곳에 select-from-where절
- 보통 where절, from절에 위치 → 집합 포함 관계, 집합 비교, 집합 원소 개수 등의 조건 사용하는 경우 흔하다
Single-row Subquery Example
- 단일 tuple 반환 → single-row subquery, scalar subquery
Select name from professor where salary = (select salary from professor where pID='10') and pID <> '10'; //pID가 10과 같지 않다 from절에는 위치 X
IN Operator
- 단일값이 다수값에 속하는지 검사
Select name, salary from professor where pID in (10, 21, 22); //where pID=10 or pID=21 or pID=22;
Subquery Example
- 2009년 가을 학기, 2010년 봄 학기에 개설된 과목 번호 구하기
Select distinct cID from teaches where semester = 'Fall' and year = 2009 and cID in (select cID from teaches where semester = 'Spring' and year = 2010);(select cID from teaches where semester = 'Fall' and year = 2009) intersect (select cID from teaches where semester = 'Spring' and year = 2010); - 2009년 가을 학기에 개설되었으나 2010년 봄 학기에는 개설되지 않은 과목 번호 구하기
Select distinct cID from teaches where semester = 'Fall', and year= 2009 and cID not in (select cID from teaches where semester = 'Spring' and year = 2010);(select cID from teaches where semester='Fall' and year=2009) except (select cID from teaches where semester='Spring' and year=2010); - pID=10인 교수가 강의한 과목을 수강한 학생 수 구하기
Select count(distinct sID) from takes where (cID,semester,year) in (select cID,semester,year from teaches where pID = 10);Select count(distinct sID) from takes, teaches where pID='10' and teaches.cID=takes.cID and teaches.semester=takes.semester and teaches.year=takes.year;
Comparison Operators
- 값 하나와 여러 값 간의 비교
- some, any Clause
(5 < some {0, 5, 6}) //true (5 = some {0, 5}) //true, == in (5 != some {0, 5}) //true (0!=5) != not in - all
(5 < all {0, 5, 6}) //false (5 = all {4, 5}) //false, !== in (5 != all {6, 7}) //true, == not in
Set Comparison Example
- CS 학과 교수 중 적어도 한 명보다는 봉급이 많은 교수 이름
Select distinct T.name from professor as T, professor as S where T.salary > S.salary and S.deptName='CS';Select name from professor where salary > some (select salary from professor where deptName='CS'); - CS 학과 모든 교수들의 급여보다 높은 급여를 받는 교수들의 이름
Select name from professor where salary > all (select salary from professor where deptName='CS');
Correlated Subqueries
- 내부 중첩 질의에서 외부 테이블을 참조하는 경우
- 내부 중첩질의를 외부 테이블의 각 tuple값에 대해 수행해야한다.
- 외부 테이블에서 한 개의 tuple pick → 이를 기준으로 내부 중첩 질의 수행
- 시간 많이 소요
“exists” Construct
- 인자형태로 표현되는 서브질의의 결과가 존재 → True 반환
- 내부 질의 수행하여 결과 tuple 반환 시 exists : True
- 2009년 가을학기와 2010년 가을학기에 개설된 강의번호 구하기
Select S.cID from teaches as S where S.semester = 'Fall' and S.year = 2009 and exists (select * from teaches as T where T.semester = 'Fall' and T.year = 2010 and S.cID = T.cID); //외부 테이블 사용 - 상관 중첩이 없는 exists
-
일반적으로 의미없는 SQL 문장
Select distinct sID from student where exists (select cID from course where deptName = 'CS');→ 외부 from절에 있는 student tuple에 영향을 받지 않는다.
→ 의미없는 where절
-
“for all” Queries
- “for all” 의미를 구현하는 연산자 제공 X
not exists사용- “X-Y=∅” 표현 = "not exists (X except Y)”
- X : CS학과의 모든 과목 (중첩질의)
- Y : 학생이 수강한 모든 과목 (상관중첩질의)
- CS 학과가 제공하는 모든 과목을 수강한 학생 이름
Select S.sID, S.name from student as S where not exists((select cID from course where deptName = 'CS') except(select T.cID from takes as T where S.sID = T.sID));
“unique” Construct
- 인자형식으로 표현되는 서브질의 결과의 중복성 검사
- 2009년 최대 한 번만 개설된 모든 과정을 찾아라
-
각 과목별로 2009년 개설된 과목 횟수 count
→ 1 이하 : 과목은 최대 한 번 개설된 것Select C.cID from course as C where 1 >= (select count(T.cID) from teaches as T where C.cID = T.cID and T.year = 2009);Select C.cID from course as C where unique (select T.cID from teaches as T where C.cID = T.cID and T.year = 2009);
-
- unique(공집합) : True
- tuple 중 속성이 한 개라도 null값 : 동일하지 않다 판별
unique{<1, null>, <1, null>} //true
Subqueries in “from” Clause
- 평균 급여가 6900보다 큰 부서의 부서 이름과 교수들의 평균 급여
Select deptName, avgSalary from (select deptName, avg(salary) as avgSalary from professor group by deptName) where avgSalary > 6900;Select deptName, avgSalary from (select deptName, avg(salary) from professor group by deptName) as deptAvg(deptName, avgSalary) where avgSalary > 6900; group by결과를 임시 결과에 할당 →having조건을where절에 명시 →having절 필요 XSelect deptName, avg(salary) from professor group by deptName having avg(salary) > 6900;- 모든 부서 중 가장 높은 총 급여 찾기
Select max(totalSalary) from (select deptName, sum(salary) from professor group by deptName) as deptTot(deptName, totalSalary);Select sum(salary) from professor group by deptName having sum(salary) >= all (select sum(salary) from professor group by deptName):
“lateral” Clause
from절에서 선행 관계, 서브 질의 참조- 서브쿼리 내에서 외부쿼리의 테이블 참조
- 교수 이름, 봉급, 그들의 학부의 평균 봉급 찾기
Select name, salary, avg(salary) //Syntax error from professor group by deptName;Select P1.name, P1.salary, avgSalary from professor P1, lateral (select avg(P2.salary) as avgSalary from professor P2 where P1.deptName = P2.deptName);
“with” Clause
- SQL 문장의 결과 임시 저장 → 복잡한 SQL 질의문 작성 시 유용
- 가장 높은 예산을 가진 학부 이름 찾기
With maxBudget(value) as (select max(budget) from department) select deptName, budget from department, maxBudget where department.budget = maxBudget.value;Select deptName, budget from department where budget = max(budget); //wrong SQL //where 절에서 집계함수 직접 사용 X -> 서브쿼리 이용Select deptName, budget from department where budget = (select max(budget) from department) - 총 봉급이 모든 학부 총 봉급 평균보다 높은 학부 찾기
with deptTotal(deptName, value) as (select deptName, sum(salary) from professor group bt deptName), deptTotalAvg(value) as (select avg(value) from deptTotal) select deptName from deptTotal, deptTotalAvg where deptTotal.value > deptTotalAvg.value;
2023.10.09
5.4 Ranking
깊게 공부할 필요 X, 해당 기능을 지원한다는 것 정도로만 알고있기
Top, Limit, or Rownum Clause
- 검색 되는 tuple 중 상위(하위) 몇 개(퍼센트) 만의 tuple 반환하는 기능
- SQL Server 예제
Select top (3) * from professor order by salary; Select top (10) percent with ties * from professor order by salary; - MySQL 예제
Select * from professor order by salary desc limit 3 offset 1; //offset 1 : 첫 번째 tuple skip 하는 효과 //상위 봉급자 중 최고를 제외한 3인 검색 - Oracle 예제
Select * from (select * from professor order by salary desc) where ROWNUM <= 3;
Ranking
- 대부분
order by절 사용Select ID, rank() over (order by GPA desc) as sRank from studentGrades order by sRank; - 표준SQL : rank() 함수 지원
- 순서를 정함에 있어 gap 발생 가능
- dense_rank() → gap 발생 X
- rank = 1등 1등 3등 … / dense_rank = 1등 1등 2등 …
- rank() 함수 사용 X
//correlated된 서브질의 형태 -> 비효율적 Select ID, (1 + (select count(*) from studentGrades B where B.GPA > A.GPA)) as sRank from studentGrades A order by sRank;
Ranks with Null
- null값 처리 : first, last
Select ID, rank() over (order by GPA desc nulls last) as sRrank from studentGrades; - Default값
- ASC 정렬 → NULLS LAST
- DESC 정렬 → NULLS FIRST
Ranking within Partition
- 간단하게 기능만 알고 넘어가기
- partiton by → 각 파티션에 대해 rank() 함수 적용
- 각 학과별 등수 계산하기
Select ID, deptName, rank() over (partition by deptName order by GPA desc) as deptRank from studentGrades order by deptName, deptRank;
Other Ranking Functions
- percent_rank()
- 등수가 포함되는 퍼센트 출력
- cume_dist()
- 누적 등수 알려주는 기능
- row_number()
ntile() Ranking
- 해당 속성값 기준으로 전체 테이블 균등하게 n등분 → 등분에 속하는 tuple 개수는 최대 한 개만 차이
- 예제
Select ID, ntile(3) over (order by GPA desc) as quartile from studentGrades;ID GPA ID NTILE /* GPA */ S1 2.8 S5 1 /* 4.2 */ S2 3.5 S3 1 /* 4.0 */ S3 4.0 S2 2 /* 3.5 */ S4 3.5 S4 2 /* 3.5 */ S5 4.2 S1 3 /* 2.8 */
5.5 More Features
간단히 살펴보기
Reusing Existing Schema/data
- Schema 복사
like
→ 모든 제약 사항 함께 복제 X (primary key, foreign key, indexed 복제 X)Create table t1 like professor
- Schema, data 복사
asCreate table t2 as (select * from professor) with data; - 특정 tuple의 data만 복사
Create table t3 as (select * from professor where deptName='CS');
Large-Object Types
- 대용량 객체 : photos, videos, document, CAD files 등 → Large-Object Type이 필요!
- blob : binary large object
-
photos, videos 를 위한 것
myImage blob(10MB)
- clob : character large object
- document 를 위한 것
- query : object 그 자체가 아닌 pointer 반환
Built-in Data Types
- date : ‘2021-09-21’
- time : ‘09:00:30’, ‘09:00:30.75’
- timestamp : data + time ‘2021-09-21 09:00:30.75'
- interval : ‘1’ month
- interval값에 date/time/timestamp 추가 ex. interval ‘100' day + currentDate
- date/time/timestamp 간의 차이 → 결괏값 interval
- interval값에 date/time/timestamp 추가 ex. interval ‘100' day + currentDate
User-Defined Types
create type사용자가 원하는 데이터 타입 정의Create type Dollars as numeric (12, 2) final; Create table myDepartment (deptName varchar(20), budget Dollars);- final : 해당 type 이용해 또 다른 type 생성 X not final : 해당 type 이용해 또 다른 type 생성 O
Domains
create domain사용자가 원하는 도메인 정의 →create type과 달리 무결성 제약을 가질 수 있다.Create domain degreeLevel varchar(10) constraint degreeLevelTest check (value in ('Bachelor', 'Master', 'Doctorate'));
Transactions
- ACID 성질을 가지는 DB 연산의 나열(sequence) → DB work의 논리적 단위
- 자세한 건 DB2에서
Indices
- 인덱스 생성하는 기능
Create index myCourseIndex on course(cID); - 기본적으로 SQL 표준에서는 존재 X → 대부분의 상용 DBMS는 지원
- 자세한 건 DB2에서

숭실대학교 컴퓨터학부 21