오늘 할 일
- EMR 살펴보기
- EMR 사용해보기
EMR 살펴보기
소개
- https://www.slideshare.net/awskorea/3-amazonemr-advanced-skill
- EMR 고급활용 기법 (AWS SUMMIT)
- Amazon EMR은 Hadoop을 기반으로 하는 빅데이터 프레임워크이다.
- Spark, Hive, Presto와 같은 오픈소스 프레임워크를 사용한다.
- EMR에 데이터를 가져오는 가장 일반적인 방법은 S3에서 로드하는 것이다.
- 그 외에도, DynamoDB에서 가져오는 방법도 있다.


비용
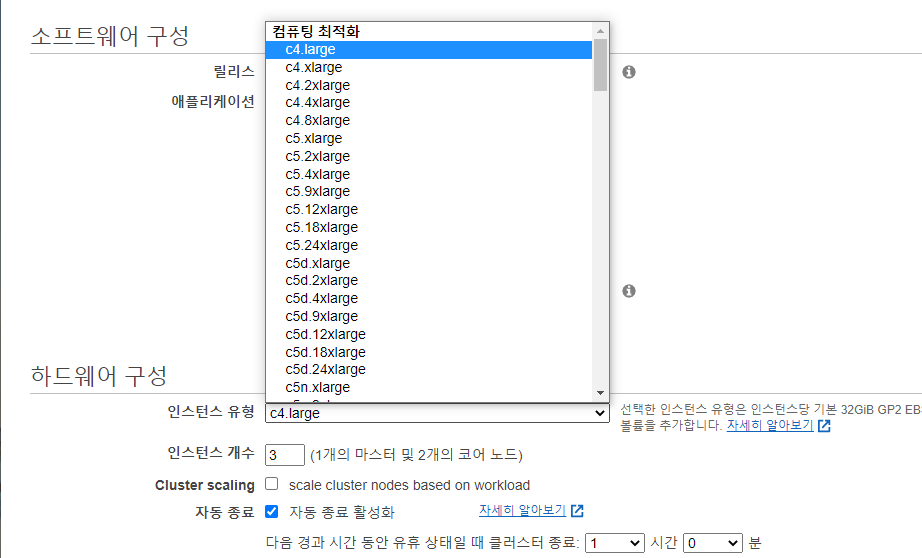
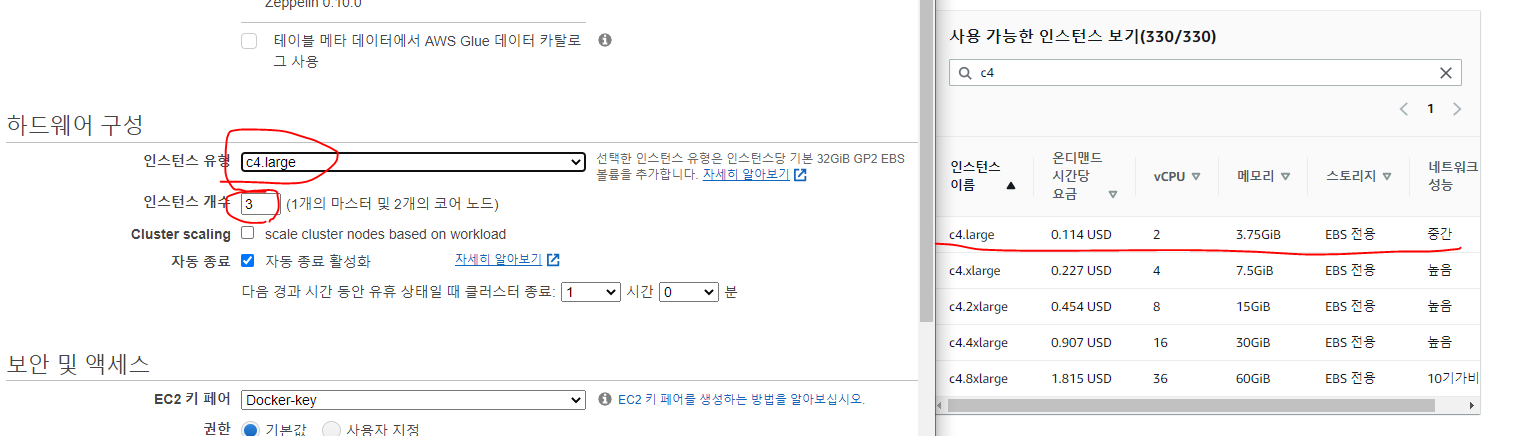
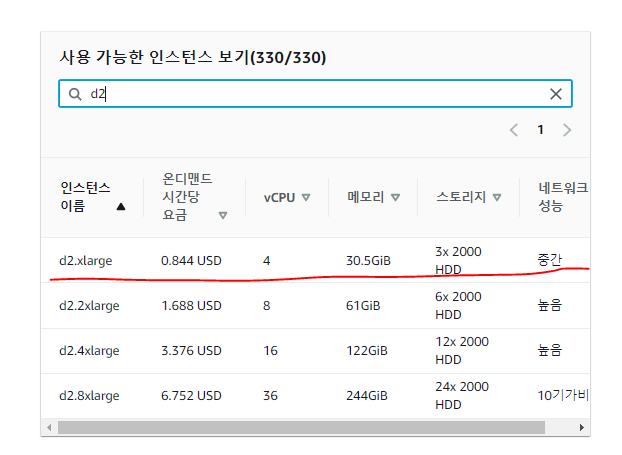
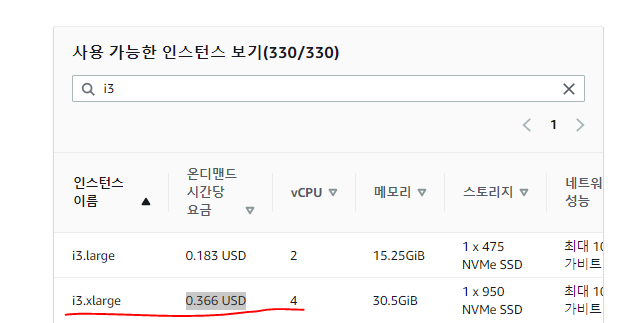
- 다음과 같이 다양한 인스턴스를 지원한다. (t2.micro가 없다...)
c4.large시간당 0.114달러*3 = 0.342달러
d2.xlarge시간당 0.844달러*3 = 2.532달러
i3.xlarge시간당 0.366달러- 이 외에도 다양한 비용이 존재하지만, 가장 저렴한
c4.large를 사용해본다.
EMR 노트북
- Amazon Cluster와 함께 아마존 EMR노트북을 사용할 수 있다.
- 노트북 컨텐츠는 내구성과 유연한 재사용을 위해 클러스터 데이터와 별도로 Amazon S3에 저장된다.
EMR 노트북 사용시 고려사항
클러스터 요구사항
- 퍼블릭 액세스 차단 Amazon EMR 활성화
- 호환되는 클러스터 사용
- Amazon EMR을 사용한 클러스터만 지원한다.
- Amazon EMR 리리스 버전 5.18.0이상의 클러스터만 지원한다.
- AMD EPYC 프로세서가 있는 EC2인스턴스를 사용해야한다. (M5a, r5a안됨)
- 하둡, Spark, Livy가 설치된 상태에서 클러스터를 시작해야 한다.
- kerberos인증 지원 안됨
- 마스터노드가 하나인 클러스터만 사용가능
- AWSGraviton2는 지원되지 않는다.
- 지원이 용이한 5.30 혹은 5.32이상, 6.2.0이상의 버전을 사용하도록 한다.
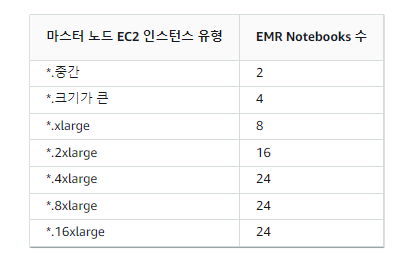
동시에 연결된 EMR Notebooks에 대한 제한

EMR 사용해보기1
S3 생성

EMR 클러스터 생성
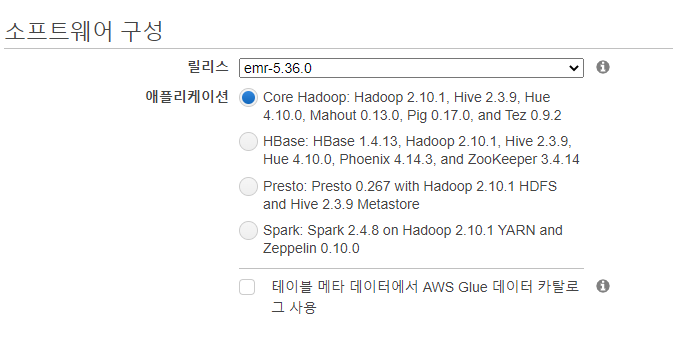
단계1: 소프트웨어 및 단계
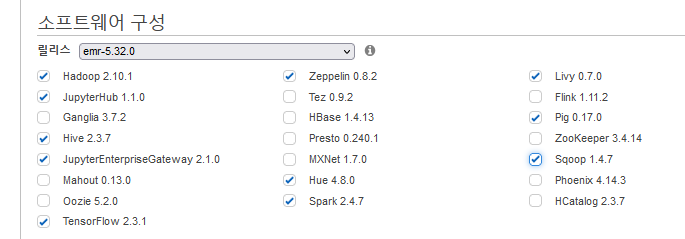
- 사용할 소프트웨어 구성이다.
- 우리는 Spark, Livy, Sqoop을 사용할 예정이기 때문에 고급 옵션으로 생성할 것이다.
- 기본적으로 필요한 옵션을 여기서 확인한후 참고한다.
- Spark on Hadoop, Yarn and Zeppelin
- Hadoop, Hive, HDSF등을 설치해본다.
- 이렇게 사용해 볼 것이다.
- 설정은 일단 이렇게 해본다.
단계2: 하드웨어
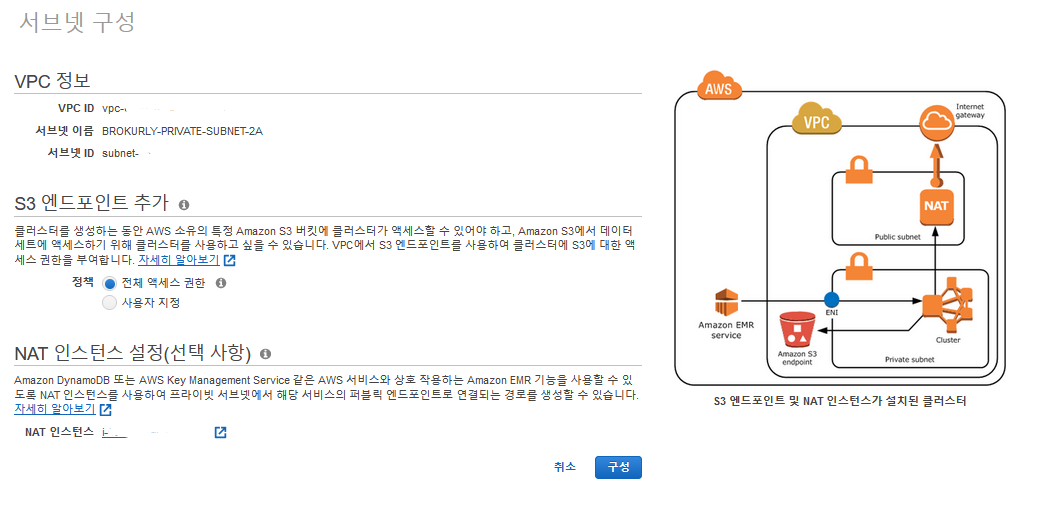
- EMR에서 S3에 접근하기 위해 NAT인스턴스를 요구한다.
- EMR이 Amazon DynamoDB, KMS 및 Kinesis에 접근하기 위해서는 클러스터가 이 IP범위에 도달할 수 있어야 한다.
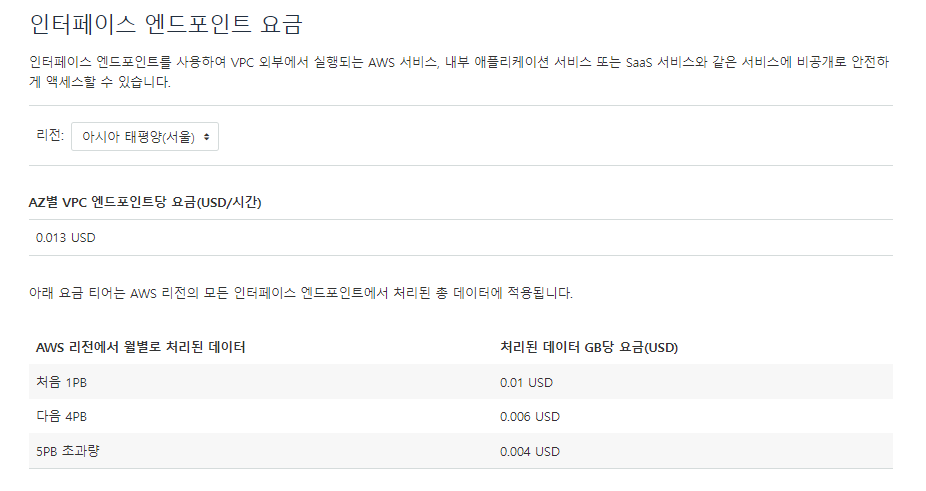
- S3 엔드포인트를 추가한다.
- 엔드포인트에 대한 비용은 처음 1Pb부터 Gb요금이 0.01달러 + AZ별 VPC 엔드포인트당 시간당 0.013달러가 요구된다.
- 엔드포인트를 생성한다.
- 가장 저렴한 인스턴스인 c4.large로 생성한다.
- 마스터는 온디맨드로
- 코어 (worker)는 스팟인스턴스로 사용할 것이다.
단계3: 일반 클러스터 설정
단계4: 보안
- 위와같이 생성한다.



노트북 생성
- 안된다...
- 자습서를 따라하며 다시 시도해보도록하자

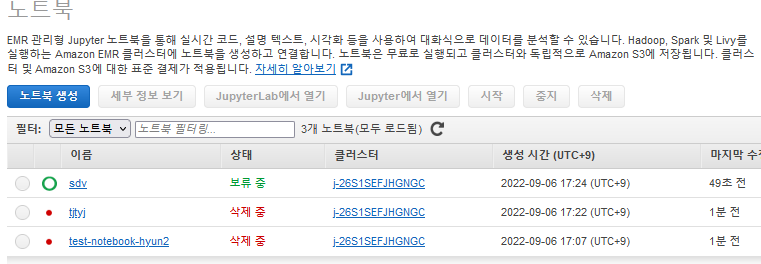
EMR정리
- 노드북 삭제
- 클러스터 삭제
내일 할일

Talking Potato