오늘 할일
- EMR 다시 만들기
- 데이터 받아서 데이터분석 시연용 데이터 만들기
- 데이터분석 코드 만들어놓기
공지
- 이번주 내 브리핑
- CTC가 채용의 메인
- JD 오픈 = Job Description(직무)
- 포지션에 기재된 필요경력 무시
- 신입 채용 포인트: 기본 기술의 이해, 팀 핏(존중, 배려 기반 커뮤니케이션 등), 성장 가능성
- DevRel : Developer Relations의 약자이며 더 줄여서 DR이라고도 부르기도 합니다. 명칭에서 유추해볼 수 있듯 개발자와의 관계에 초점을 두는 직무입니다
- 22일 최종 프로젝트
- 20일 (화) 10시까지 발표자료집 인쇄용 제출
- 26일까지 발표자료/소스 및 이력서 전달
- 27일: 서류 합격자 실무 면접 및 최종면접 진행
- 포트폴리오 링크 절대 안들어감
- PDF로 5장내외로 축약해서 제출하기
- 프로젝트 하고 집에서도 다른 회사 이력서도 넣어보기
- 5개의 직무를 보내주셨는데 5개 모두 지원해도 됨
- CTC외의 다른 메가존 직무에 지원해도 CTC에서 모른다.
시연용 데이터 만들기
이름데이터 만들기
성씨
text = ''' 김(金) 10,689,959 1 9,925,949 1 8,785,341 2 이(李) 7,306,828 2 6,794,637 2 5,985,056 3 박(朴) 4,192,074 3 3,895,121 3 3,435,858 4 최(崔) 2,333,927 4 2,169,704 4 1,913,329 5 정(鄭) 2,151,879 5 2,010,117 5 1,780,734 6 강(姜) 1,176,847 6 1,044,386 6 958,181 7 조(趙) 1,055,567 7 984,913 7 877,058 8 윤(尹) 1,020,547 8 948,600 8 834,121 9 장(張) 992,721 9 919,339 9 810,235 10 임(林) 823,921 10 762,767 10 672,782 11 한(韓) 773,404 12 704,365 11 628,396 12 오(吳) 763,281 11 706,908 13 619,774 13 서(徐) 751,704 14 693,954 14 611,206 14 신(申) 741,081 13 698,171 12 620,983 15 권(權) 705,941 15 652,495 15 567,990 16 황(黃) 697,171 16 644,294 16 564,292 17 안(安) 685,639 17 637,786 18 556,429 18 송(宋) 683,494 18 634,345 17 557,193 19 전(全) 559,110 21 493,419 21 430,059 20 홍(洪) 558,853 20 518,635 20 457,583 21 유(柳)* 478,990 19 603,084 19 509,127 22 고(高) 471,396 22 435,839 22 384,061 23 문(文) 464,040 23 426,927 23 375,866 24 양(梁) 460,600 25 389,152 25 344,209 25 손(孫) 457,303 24 415,182 24 368,744 26 배(裵) 400,641 26 372,064 26 323,031 27 조(曺) 398,260 27 362,817 28 304,837 28 백(白) 381,986 28 351,275 27 309,578 29 허(許) 326,770 29 300,448 29 264,238 30 유(劉) 302,511 32 242,889 32 218,449 31 남(南) 275,648 30 257,178 30 222,269 32 심(沈) 271,749 31 252,255 31 219,741 33 노(盧) 256,229 33 220,354 33 196,285 34 정(丁) 243,803 36 187,975 36 165,382 35 하(河) 230,481 34 209,756 34 184,651 36 곽(郭) 203,188 37 187,322 38 163,433 37 성(成) 199,124 38 184,555 37 163,565 38 차(車) 194,782 39 180,589 39 159,680 39 주(朱) 194,766 43 176,232 42 153,508 40 우(禹) 194,713 42 176,682 41 155,471 41 구(具) 193,080 41 178,167 40 157,683 42 신(辛) 192,877 46 167,621 47 137,874 43 임(任) 191,261 44 172,726 44 147,700 44 전(田) 186,469 35 188,354 45 146,664 45 민(閔) 171,740 47 159,054 46 141,429 46 유(兪) 167,927 40 178,209 35 168,082 47 류(柳)* 163,703 48 나(羅)* 160,946 45 172,022 43 150,012 49 진(陳) 157,599 48 142,496 49 123,092 50 지(池) 153,491 49 140,824 48 125,648 51 엄(嚴) 144,425 50 132,990 50 116,039 52 채(蔡) 131,557 52 114,069 52 97,650 53 원(元) 129,522 51 119,356 51 104,535 54 천(千) 121,780 54 103,811 53 97,419 55 방(方) 94,831 58 81,710 55 81,469 56 공(孔) 91,869 56 83,164 56 72,388 57 강(康) 91,625 53 109,925 58 69,820 58 현(玄) 88,824 57 81,807 57 72,164 59 함(咸) 80,659 60 75,955 59 65,193 60 변(卞) 78,156 59 78,685 60 64,147 61 염(廉) 69,387 62 63,951 61 54,533 62 양(楊) 69,101 55 93,416 54 81,589 63 변(邊) 60,633 65 52,869 63 50,380 64 여(呂) 60,522 63 56,692 64 48,965 65 추(秋) 60,483 64 54,667 65 48,643 66 노(魯) 58,698 61 67,032 62 54,477 67 도(都) 56,850 66 52,349 66 46,528 68 소(蘇) 52,427 69 39,552 69 39,728 69 신(愼) 51,865 68 45,764 67 40,772 70 석(石) 49,203 67 46,066 68 40,390 71 선(宣) 42,733 70 38,849 71 33,718 72 설(薛) 42,646 72 38,766 70 34,264 73 마(馬) 38,949 74 35,096 74 30,865 74 길(吉) 38,173 76 32,418 73 30,932 75 주(周) 37,240 71 38,778 72 33,222 76 연(延) 34,766 78 28,447 75 27,940 77 방(房) 33,520 73 35,366 80 22,539 78 위(魏) 31,342 77 28,675 77 24,259 79 표(表) 30,743 79 28,398 76 24,570 80 명(明) 29,110 80 26,746 78 23,380 81 기(奇) 28,829 81 24,385 79 22,706 82 반(潘) 28,062 84 23,216 81 21,553 83 라(羅)* 25,960 84 왕(王) 25,565 83 23,447 82 20,378 85 금(琴) 25,432 82 23,489 83 20,361 86 옥(玉) 25,107 85 22,964 84 20,196 87 육(陸) 23,455 86 21,545 85 18,841 88 인(印) 22,363 88 20,635 86 18,281 89 맹(孟) 22,028 89 20,219 87 17,648 90 제(諸) 21,976 90 19,595 88 17,394 91 모(牟) 21,534 92 18,955 93 16,046 92 장(蔣) 21,508 95 17,708 92 16,107 93 남궁(南宮) 21,308 93 18,743 91 16,228 94 탁(卓) 21,099 91 19,395 89 16,943 95 국(鞠) 20,547 98 16,697 94 15,562 96 여(余) 20,134 94 18,146 96 14,763 97 진(秦) 19,301 87 21,167 90 16,445 98 어(魚) 18,849 96 17,551 95 15,351 ''' print(text) F_name_set = set() for i, item in enumerate(text.split('\t')): item = item.split(' ') if(not i%6): F_name_set.add(item[0][0]) F_name_list = list(F_name_set)
- 위는 한국 성씨를 인구수대로 정렬한 데이터이다.
- 위를 성씨만 골라서 중복없이 리스트로 담는다.
이름
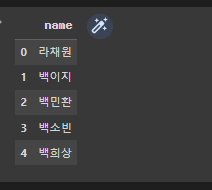
import requests import json import time import pandas as pd from itertools import product import random name_list = [] page = 1 while(len(name_list) < 5000): url = 'https://koreanname.me/api/rank/2008/2022/'+str(page) page += 1 res = requests.get(url).json() for gender in ['male', 'female']: for i in range(len(res[gender])): name_list.append(res[gender][i]['name']) names = [] for name in list(product(F_name_list, name_list)): names.append(name[0] + name[1]) random.shuffle(names) name_df = pd.DataFrame(data=names, columns=['name']) name_df.head()
- https://koreanname.me 에서 이름은 크롤링해온다.
- 여기서 얻은 이름과 아까 얻은 성씨를 모아 이름을 랜덤으로 만들어준다.
name_df['customer_id'] = name_df.index.tolist() name_df.head()
- 현재 index를 고객 id로 넣어줄 것이다.
상품 데이터 만들기
- https://www.kaggle.com/code/mobasshir/food-recommendation-dataset-exploration/data
- 위 주소의 Kaggle데이터를 사용한다.
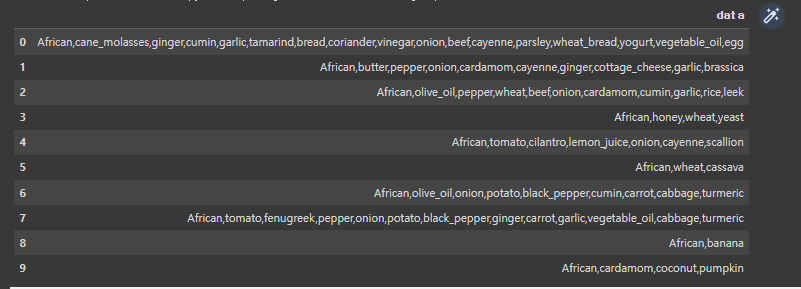
import pandas as pd import numpy as np pd.set_option('display.max_colwidth', -1) data_path = '/content/drive/MyDrive/Colab Notebooks/Recommand-data/kaggle_and_nature.csv' item_df = pd.read_csv(data_path, sep='\t', skiprows=4) item_df.columns = ['data'] item_df.head(10)
- 캐글 데이터를 읽고 Pandas DataFrame으로 만들어준다.
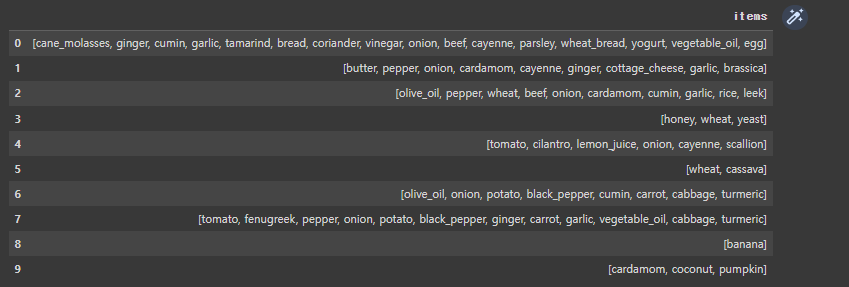
item_df['items'] = item_df['data'].apply(lambda x: x.split(',')[1:]) item_df = item_df.drop(labels=['data'], axis=1) item_df.head(10)
- 앞에 Africa와 같은 지역 이름을 빼주고, 구매 목록만 list형으로 남겨준다.
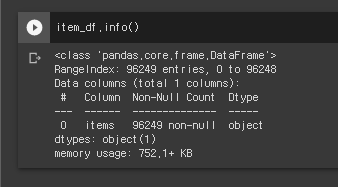
- 총 96249개의 데이터가 존재한다.
상품 데이터 이름데이터 합치기
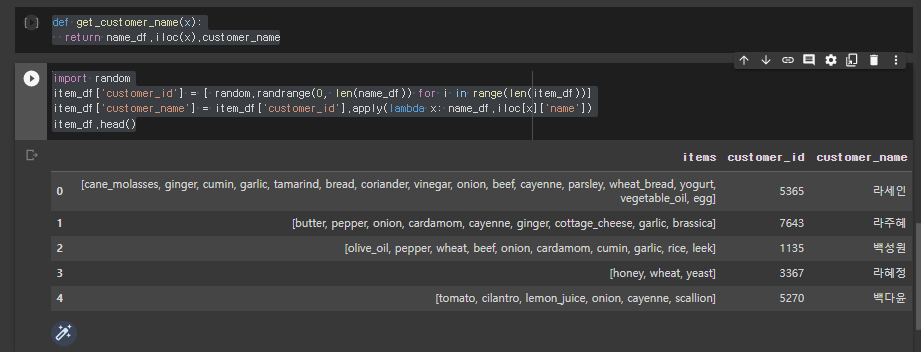
def get_customer_name(x):
return name_df.iloc(x).customer_name
>
import random
item_df['customer_id'] = [ random.randrange(0, len(name_df)) for i in range(len(item_df))]
item_df['customer_name'] = item_df['customer_id'].apply(lambda x: name_df.iloc[x]['name'])
item_df.head()- 랜덤으로 회원번호를 뽑아 새로운 열을 만들고, 그 회원번호로 이름을 조회해서 구매목록 데이터와 고객 데이터를 합친다.
구매상품 목록 번역하기
import googletrans import time translator = googletrans.Translator() trans_dict = {} error_list = [] def item_translate(item_list): translated = [] for item in item_list: in_dict = trans_dict.get(item, 0) if(in_dict): translated.append(in_dict) else: try: translated_item = translator.translate(item, dest='ko').text trans_dict[item] = translated_item translated.append(translated_item) except: print(i) error_list.append(i) continue return translated #testdf = item_df.iloc[:10] for i in range(len(item_df)): item_df.iloc[i]['items'] = item_translate(item_df.iloc[i]['items']) item_df.head()
- 만약 googletrans 모듈이 존재하지 않는다는 에러가 난다면,
!pip install googletrans==4.0.0-rc1item_df.to_csv('/content/drive/MyDrive/Colab Notebooks/Custommer.csv')
- 결과를 저장해준다.
EMR
전제조건
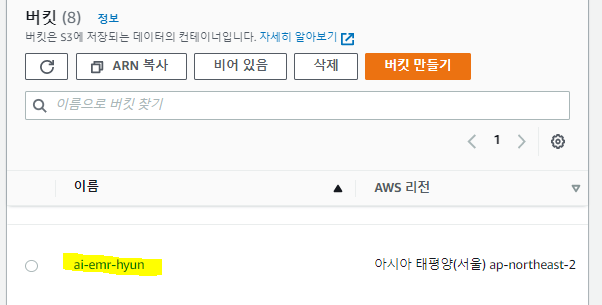
- S3 버킷 생성
- Spark 애플리케이션 코드(나중에 제공됨) 및 Spark 애플리케이션의 결과에 이 버킷을 사용합니다.
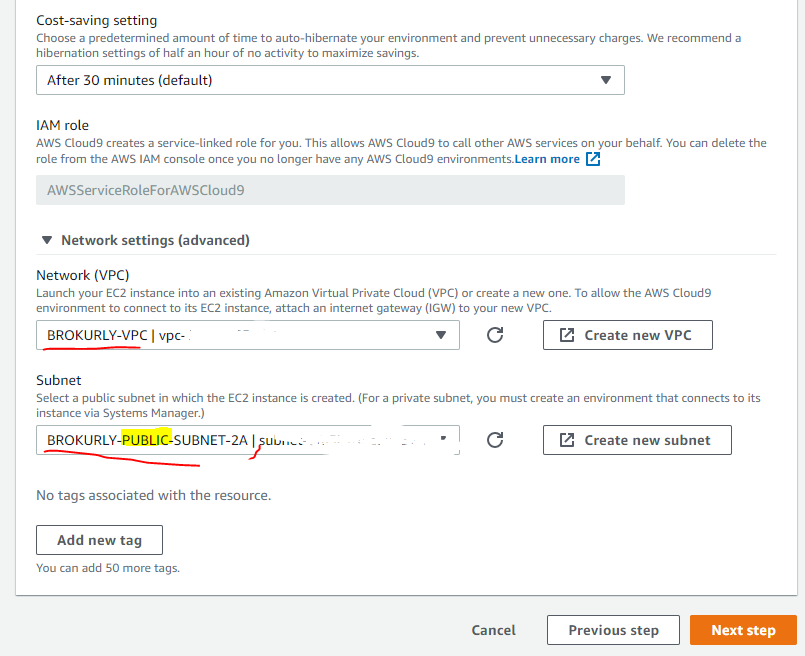
- EMR클러스터를 실행하는데 사용할 새 VPC 배포
- 가용영역 수를 3개 이상으로 한다.
- 프라이빗 서브넷을 생성하지 않는다.
작업 공간 생성
Cloud9 시작
- 환경을 만들고
시작 탭과하단 작업 영역을 닫고 기본 작업 영역에서새 터미널탭을 열어 환경을 사용자지정한다.Cloud9 작업 공간 구성
sudo pip uninstall -y awscli
- AWS CLI 1.x를 제거한다.
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"unzip awscliv2.zipsudo ./aws/install. ~/.bash_profile
AWS CLI 2.x버전을 설치해준다.aws --version
- 최신 버전이 있는지 확인한다.
aws ec2 create-key-pair --key-name hyun-emr-workshop-key-pair --query "KeyMaterial" --output text > emr-workshop-key-pair.pemchmod 400 emr-workshop-key-pair.pem
- SSH KeyPair를 생성하여 EMR 클러스터에 SSH로 연결할 수 있도록 한다.
- 생성한 키를 emr-workshop-key-pair.pem파일로 생성하고, 권한을 400으로 만든다.
sudo yum -y install jq
- jq설치
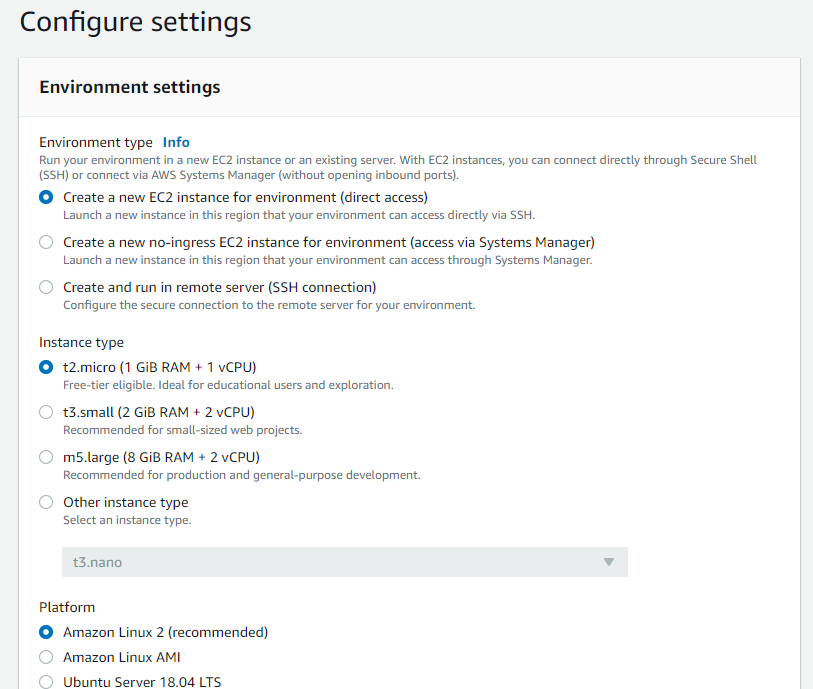
EMR 인스턴스 집합
- EC2인스턴스에 대한 다양한 프로비저닝 옵션을 선택할 수 있으면, 클러스터의 각 노드 유형에 대해 유연하고 탄력적인 리소스 전략을 개발할 수 있다.
- 스팟 인스턴스를 채택한다면, 제품군, 세대, 크기 및 가용 영역에 걸쳐 인스턴스 유형을 유연하게 선택하는 것이 좋다.
- Amazon EMR은 용량을 할당할 더 많은 용량풀을 보유하고, 중단 가능성이 가장 적은 스팟 인스턴스를 선택한다.
적절한 크기의 SPARK 실행기
- Spark실행기의 크기를 적절하게 조정하여 EC2인스턴스 유형을 유연하게 선택해야한다.'
- 단일 EC2 인스턴스 유형을 사용할 때, 더 큰 활용도와 성능최적화를 달성할 수 잇지만, 스팟 인스턴스를 채택할 때의 아이디어는 Spark애플리케이션을 실행하기 위해 원하는 규모를 달성하고 유지하기위해 최대한 유연하게 하는 것이다.
- 오늘날 회사의 개발자는 보통 72Gb RAM과 16개의 core를 사용한다.
Spark실행기에 대한 Amazon EMR 기본 메모리 제한
1:8 vCPU:Mem ratio- 우리의 결론은 지원되는 가장 작은 인스턴스 유형도 사용할 수 있는 유연성으로 R 제품군 인스턴스를 사용하기 위해 Spark 애플리케이션 제출에 "–executor-memory=18GB –executor-core=4" 를 사용한다는 것입니다.
인스턴스 유형 선택
- 먼저 우리는 "–executor-memory=18GB –executor-core=4"로 Spark 애플리케이션을 사용할 것이다.
- 이 제약 조건을 충족하면서 인스턴스 다양화를 적용하기위해 인스턴스를 설정한다.
클러스터 시작 1 (소프트웨어 및 단계)
- 먼저 온디맨스 인스턴스와 스팟 인스턴스를 혼합하여 실행되는 EMR 클러스터를 시작한다.
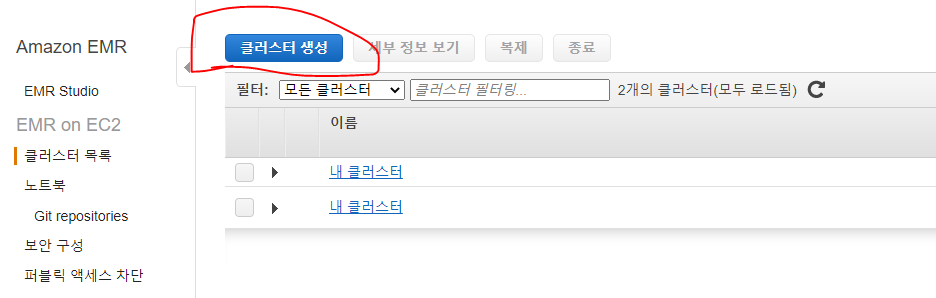
- EMR 콘솔 열기
클러스터 생성클릭
고급 옵션으로 이동을 클릭
- EMR 릴리스를 선택 (5.32.0을 사용해본다.), 구성요소 목록에서 Hadoop, Spark, Ganglia만 선택한다. (JupyterHub, JupyterEnterprise, TensorFlow, Zeppelin, Livy, Sqoop 도 사용해본다.), Ganglia를 사용하여 클러스터 리소스 사용률을 모니터링한다.
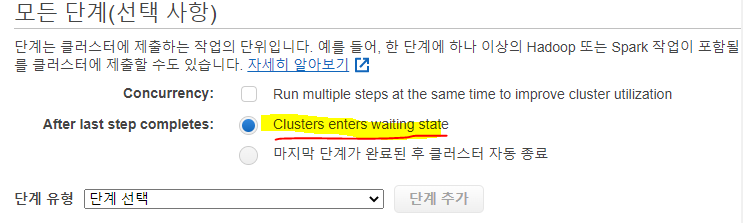
- 단계(선택사항)으로가서 아래 지침에 따라 단계를 추가한다.
- Cluster enters waiting state (단계 종료 후 클러스터 대기상태)
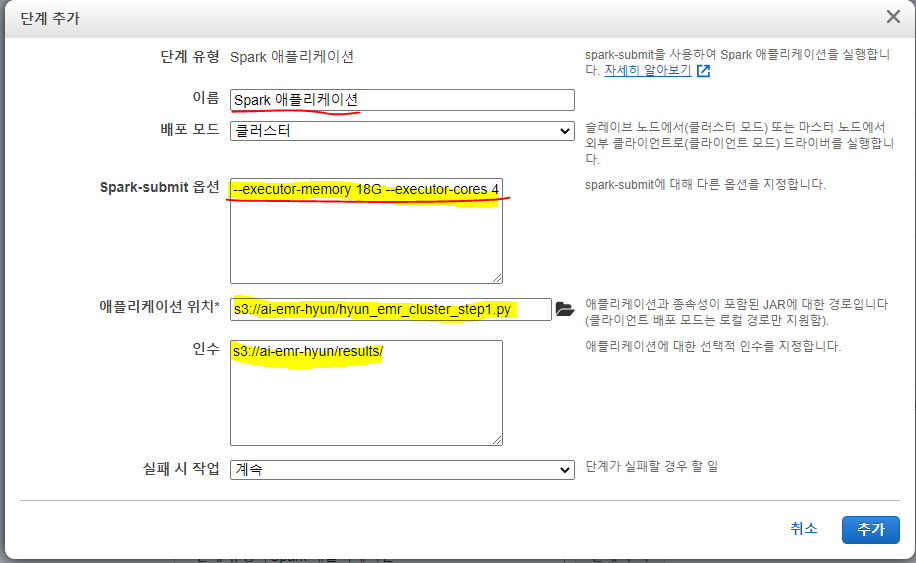
단계 유형드롭다운에서 Spark 애플리케이션을 선택하고 단계 추가를 클릭한 다음, 아래 세부정보를 추가한다.
- Spark-submit옵션 : 여기에서 이전 섹션에서 설명한 대로 각 실행기의 메모리및 코어 수를 구성한다.
--executor-memory 18G --executor-cores 4
- 애플리케이션 위치 : 여기에서 Spark 애플리케이션의 위치를 구성한다. 다음 Python코드를 파일에 저장하고, S3에 업로드 한다.
- 인수 : Spark가 작업 결과를 기록할 위치를 구성
- 실패 시 조치 :
계속으로 둔다.

클러스터 시작 2 (하드웨어)
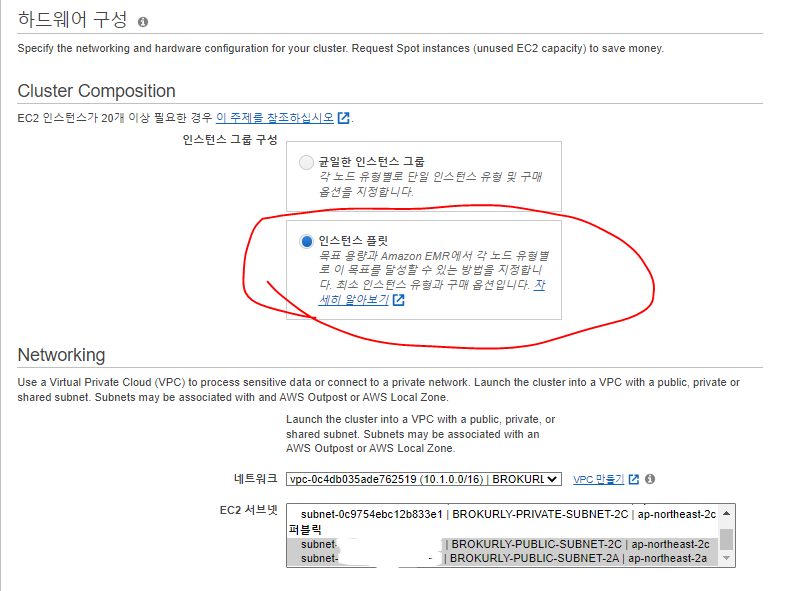
Cluster Composition
- 인스턴스 그룹 구성 -> 인스턴스 플릿(instance fleets)
- 네트워킹 -> 처음 생성한 VPC를 선택하고 모든 서브넷 선택
- 인스턴스 집합의 서브넷 및 인스턴스 유형 목록을 제공하는 것이 좋다.
- EMR은 인스턴스 유형의 비용 및 가용성에 따라 최적의 서브넷 (AZ) 하나를 자동으로 선택한다.
Allocation Strategy
- 온디맨드 인스턴스에 대한 최저 가격 할당 전략과 스팟 인스턴스에 대한 용량 최적화 할단 전략을 활용하려면
Apply allocation strategy에 체크한다.
Cluster Nodes and Instances
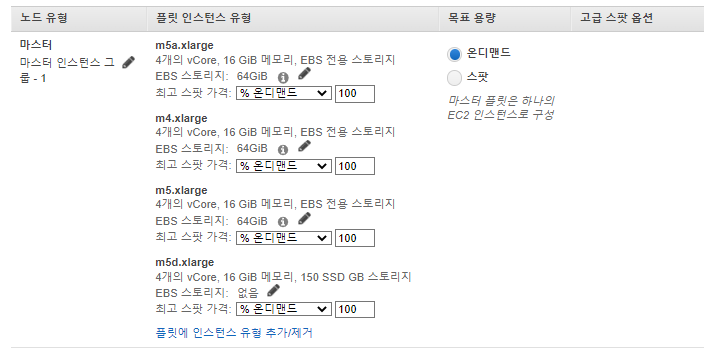
마스터 노드
- 마스터 노드에는 일반적으로 큰 계산 요구사항이 없다.
- 다만, Jupyterhub, Hue등 특별히 배포된 애플리케이션이 있다면 성능이 필요할 수 있다.
- 소규모 클러스터 (50개 이하 노드)에는 범용 m5.xlarge인스턴스를 사용하고, 대규모는 더 큰 인스턴스 유형으로 늘린다.
- 노드유형 > 마스터 에서 인스턴스
유형 추가 / 제거를 클릭하고 범용 인스턴스 유형(m4.xlarge, m5.xlarge, m5a.xlarge, m5d.xlarge)들을 선택한다. EMR은 하나의 인스턴스만 프로비저닝하지만 지정된 인스턴스 유형에서 마스터 노드에 대해 가장 저렴한 온디맨드 인스턴스 유형을 선택한다.
- 클러스터의 수명이 매우 짧고 실행이 비용 중심적인 경우가 아니면 스팟인스턴스를 선택하지 않는 것이 좋다.
- 마스터 노드가 중단되면 전체 클러스터가 종료된다.
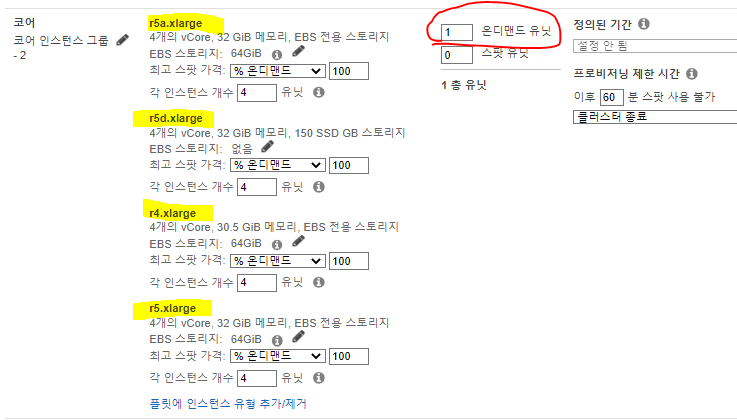
코어 노드
- EMR 인스턴스 집합을 사용할 때 하나의 코어 노드는 필수이다.
- 단일 코어 노드가 하나의 실행기와 YARN애플리케이션 마스터를 실행할 수 있도록 4개의 온디멘드유형를 지정한다. (r5a.xlarge, r5d.xlarge, r4.xlarge, r5.xlarge, r5b.xlarge)
- 코어노드는 HDFS를 사용하여 데이터를 처리하고 정보를 저장하므로, 코어 인스턴스를 종료하면 데이터 손실 위험이 있다. YARM 애플리케이션 마스터는 코어 노드중 하나에서 실행되며, Spark애플리케이션의 경우 Spark드라이버는 Spark애플리케이션의 단일 실패 지점이다. 드라이버가 죽으면 연결된 다른 모든 구성 요소도 버려진다.
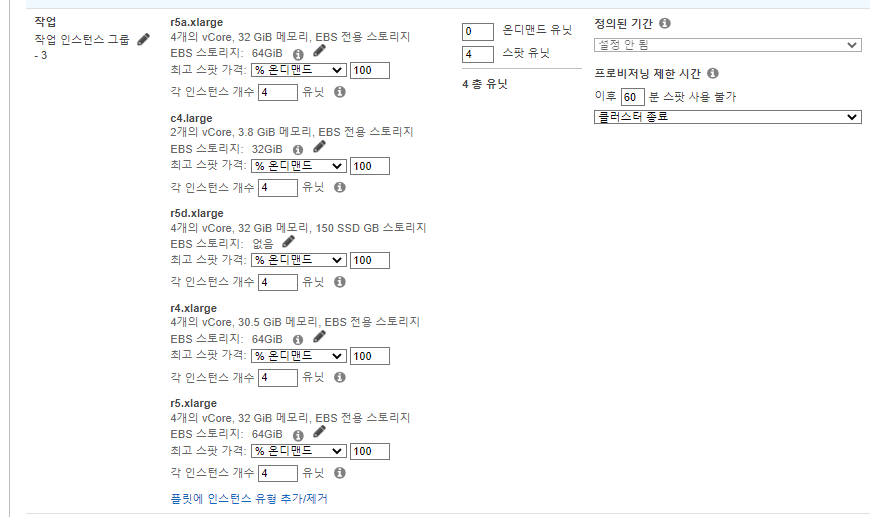
작업 노드
- 작업 노드는 Spark실행기만 실행하고 HDFS DataNode는 실행하지 않으므로, 작업 노드는 더 빠른 실행 시간을 달성하기 위해 병렬 실행을 확장하고 늘리는데 적합하다.
- 플릿에 인스턴스 유형을 추가/제거해, 실행기 크기에 적합한 인스턴스 유형을 선택한다. 실행기 크기가 4vCore이므로 1개의 실행기를 실행하기 위해 4개의 스팟를 지정해본다.
Cluster Scaling
- EMR클러스터의 코어 또는 작업 노드 (EC2)수를 자동으로 조정할 수 있다.
- Cluster scaling을 활성화해준다.
- Minimum Capacity Units를 4로 설정한다. (2로 해본다.)
- Maxmum : 68 (32로 설정한다.)
- On-demand limit : 1로 설정하여 온 디맨드 인스턴스에서 코어 노드만 실행하도록 한다.
- MaximumCoreCapacityUnits을 1로 설정하여 단일 코어 노드만 허용한다.








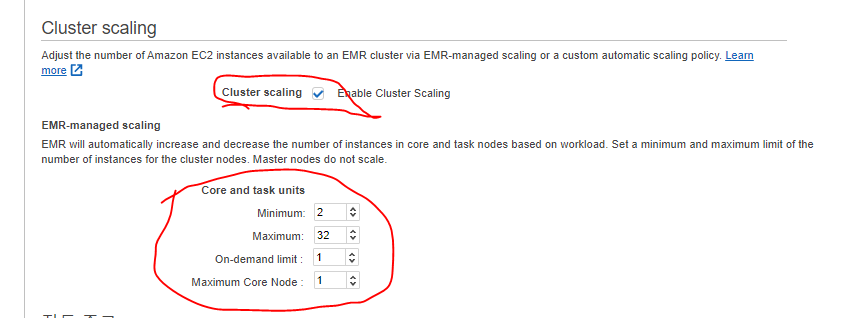
클러스터 시작 3,4 (하드웨어)
- 태그를 넣어 나중에 비용 보고서에서 볼 수 있도록 한다.
- 종료 보호는 오늘 삭제할 것이기 때문에 체크를 해제해준다.
- 보안에서는 EC2 키페어를 설정해주고 클러스터를 설정한다.
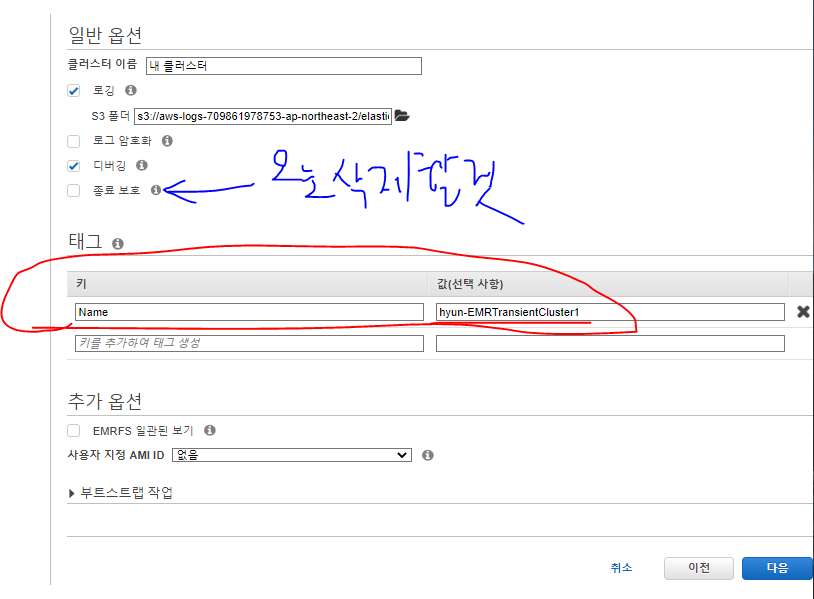
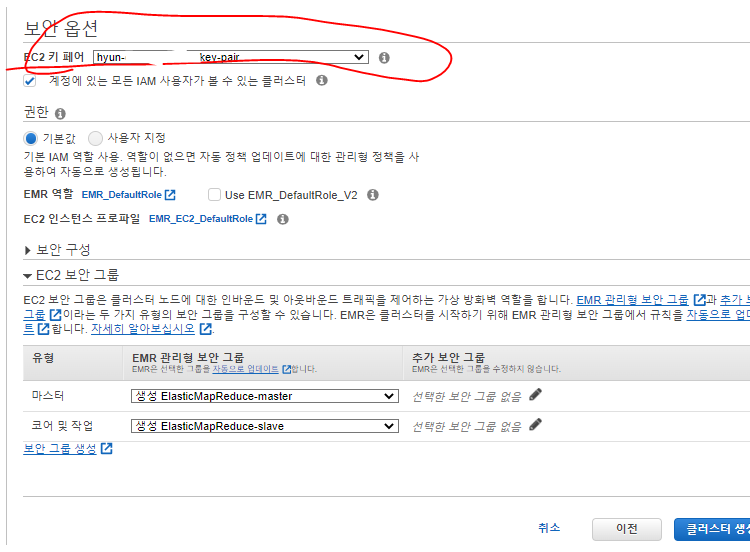
클러스터 검사
EMR 관리 콘솔
- EMR 클러스터페이지에서 클러스터의 상태는
시작또는실행이다.시작중이면, 클러스터가 실행 단계에 도달할 떄까지 기다리는 동안 하드웨어 탭에서 인스턴스 집합의 상태를 볼 수 있다.- 단계 탭으로 이동하면, Spark애플리케이션이
보류혹은실행중이다. 보류중이면 실행에 도달할 떄까지 기다린다.
EMR 클러스터 내 애플리케이션 사용자 인터페이스
- EMR 클러스터 페이지의 AWS Management 콘솔에서 요약 탭 으로 이동합니다.
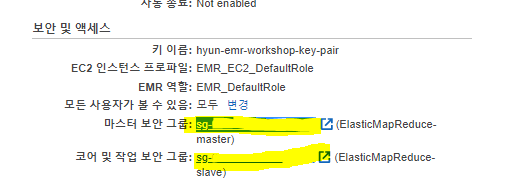
- 마스터용 보안 그룹에서 보안 그룹의 ID를 클릭합니다.
- ElasticMapReduce-master 라는 이름의 보안 그룹을 확인하십시오.
- 아래쪽 창에서 인바운드 탭 을 클릭하고 인바운드 규칙 편집 을 클릭합니다.
- 규칙 추가 를 클릭 합니다. 유형에서 SSH 를 선택하고 소스에서 사용자 지정 을 선택 합니다. Cloud9 환경 및 EMR 클러스터가 기본 VPC에 있으므로 기본 VPC의 CIDR(예: 172.16.0.0/16)을 도입합니다. VPC CIDR을 확인하려면VPC 콘솔기본 VPC 의 CIDR을 찾습니다 .
- 저장 클릭
- 이제 마스터노드에 SSH접근이 될 것이다.
Resource Manager 웹 인터페이스에 액세스
- EMR 관리 콘솔로 이동하여 클러스터를 클릭하고 애플리케이션 사용자 인터페이스 탭을 엽니다. 클러스터 내 애플리케이션 인터페이스 목록이 표시됩니다.
- 요약 섹션 에서 마스터 공용 DNS 를 복사하면 ec2.xx-xxx-xxx-xxx와 같이 표시됩니다. .compute.amazonaws.com
- Cloud9 환경에서 아래 명령을 실행하여 Resource Manager가 바인딩된 포트 8088에 대한 SSH 터널을 설정합니다(명령을 마스터 노드 DNS 이름으로 업데이트).
ssh -i ~/environment/emr-workshop-key-pair.pem -N -L 8080:ec2-###-##-##-###.compute-1.amazonaws.com:8088 hadoop@ec2-###-##-##-###.compute-1.amazonaws.com


Talking Potato