
서론
SHOOT 프로젝트를 하다가 JOIN에 대해 깨달은 사실이 두 가지 있다.
- JOIN은 정말 많이 사용한다.
- JOIN은 비용이 꽤 크다.
그래서 오늘은 JOIN이 어떻게 작동하는지 알아보고 효율적으로 사용하는 방법에 대해서 알아볼 것이다. 그리고 최종적으로 내 SHOOT프로젝트에 적용해보려고 한다.
본론
1. JOIN이란?
두 개 이상의 테이블 사이의 관련 컬럼을 기준으로 로우를 결합하는 것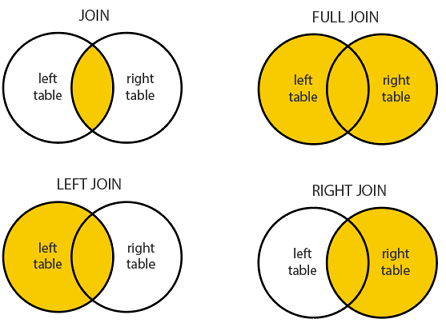
- 위 사진 처럼 JOIN은 다양한 종류를 가지고 있다. 사진 외에도 SELF JOIN이나 CROSS JOIN과 같은 것들이 더 있다.
그런데 실제로 JOIN을 사용해보니 JOIN, LEFT JOIN을 가장 많이 사용했던 것 같다.
JOIN을 더 자세하게 알아보기 위해서는 데이터베이스에 작동원리를 조금 이해할 필요가 있어보인다. 그 중에서도 어떤식으로 JOIN을 할 지 결정해주는 옵티마이저라는 친구에 대해서 먼저 알아보자.
2. 옵티마이저
옵티마이저는 그대로 직역하면 최적화하는 친구. 멋진 놈이다.옵티마이저는 자기만의 여러가지 규칙으로 실행을 어떻게 할지 판단한다.
JOIN은 다음과 같은 JOIN 기법에 따라 수행하게 되기 때문에 어떤 방법을 사용할지도 옵티마이저의 판단에 따른다.
- Nested loops 조인
- Sort merge 조인
- Hash 조인
위 3가지의 JOIN 기법을 가볍게 살펴보고 내 프로젝트에서는 어떻게 돌아가는지 한 번 살펴보도록 하자
RDB에서 공통적으로 사용하는 위 3가지 기법외에도 Hybrid 조인, Star조인 등이 존재하는데 주로 사용하는 postgreSQL에서는 위 3가지 방식만을 사용하는 것 같다.
3. 조인 기법
1. Nested loops 조인
한 테이블의 row를 기준으로 다른 테이블의 row를 순차적으로 결합하여 조인하는 방식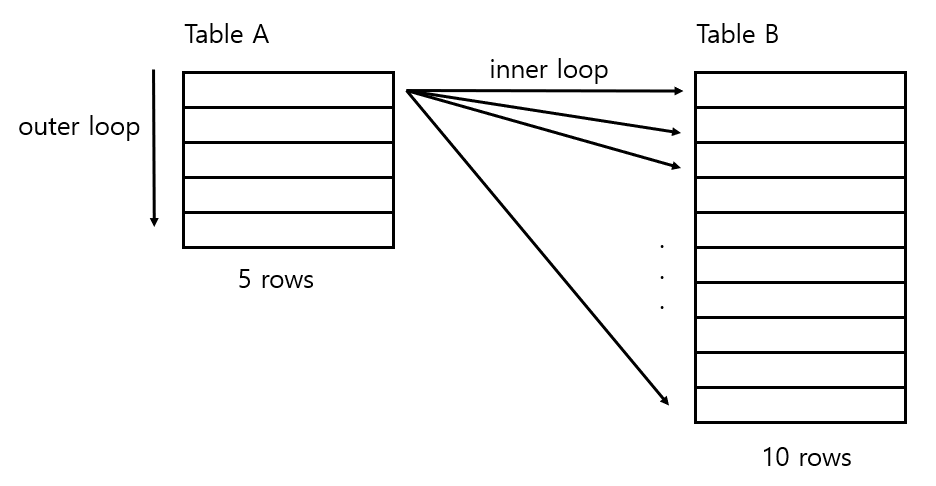 출처 : https://schatz37.tistory.com/2
출처 : https://schatz37.tistory.com/2
이해하기 너무 좋은 것 같아서 다른 티스토리에서 가져왔다. 위 사진처럼 중첩 for문의 방식으로 JOIN을 수행한다.
순서는 다음과 같다.
- A테이블에 첫 번 째 row를 기준으로 잡음
- B테이블을 다 둘러보면서 JOIN할 row를 찾음
- 다시 A테이블에 다음 row를 기준으로 잡음
- 반복
매우 단순하다. 이를 속도측면으로 접근하는 것도 그리 어렵지 않다. 2번 작업에서 A테이블의 한 row를 기준으로 B테이블의 row들을 탐색하게 된다. 이 때 탐색속도가 빠르면 JOIN의 속도 또한 빨라진다. 또한 테이블에 데이터가 적으면 빨라진다.
- 즉 언제 효율적인가?
1. 테이블에 row수가 적을 때
2, JOIN을 하는 column의 인덱싱이 존재할 때
-> 반대로 column이 인덱싱되어있지 않고 데이터수가 너무 많으면 다른 조인 기법을 사용한다.
그 외에 더 자세한 내용은 위 티스토리 블로그에 너무 잘 적혀있다.
2. Hash 조인
조인할 두 테이블 중 하나의 테이블을 이용해 해시 테이블을 만들고 조인할 테이블에 대입하여 조인하는 방식작동 순서는 다음과 같다.
- 한 테이블을 기준으로 Hash테이블을 만든다.
- 다른 테이블을 Hash함수에 넣어 Hash테이블에 대입하여 조인을 진행한다.
뭐 크게 어려운 내용은 없다. 자료구조 시간에 배웠던 해시테이블이다. 해시테이블을 효율적으로 만드는 방법을 검색하면 이 방법이 효율적으로 돌아가기 위한 조건을 알 수 있다. 그러니 이 방법이 언제 효율적인지나 알아보자
- 언제 효율적인가?
1. 두 테이블에 조인할 컬럼 모두 인덱싱이 되어있지 않을 때
2. 두 테이블에 데이터가 너무 많아 오래걸릴 때
3. Sort Merge 조인
정렬먼저하고 조인하는 방식작동 순서는 다음과 같다.
- 두 테이블 모두 조인에 필요한 방향으로 정렬을 진행한다.
- 정렬된 테이블에 대하여 조인한다.
마찬가지로 어려운 내용은 아니다. 언제 효율적인지 알아보자
- 언제 효율적인가?
1. 두 테이블 모두 조인할 column에 대한 인덱싱이 없는 경우- 대용량의 자료를 조인할 경우
- 비교 연산자가 사용된 경우
3. 내 테이블에서 테스트
자 그럼 위 조인 알고리즘에 대해서 알아봤으니 실제 프로젝트에서 사용했던 내 테이블들은 어떤 방식으로 조인되고 있는지 알아보고 어떻게 하면 더 효율적으로 쓸 수 있을지 까지 알아보자.
-
shooot.channel Table
Column Type Collation Nullable Default Storage Stats target email character varying(320) not null extended pw character(64) not null extended name character varying(20) not null extended sex smallint not null 1 plain birth date not null plain description character varying(1000) extended profile_img character(31) extended authority smallint not null 0 plain creation_time timestamp without time zone not null CURRENT_TIMESTAMP plain login_type character varying(12) not null 'local'::character varying extended subscribe_count integer not null 0 plain Indexes : "email" PRIMARY KEY, btree (email)가장 조인이 빈번하게 일어나는 채널 테이블이다.
-
shoot.post Table
Column Type Collation Nullable Default post_idx integer not null nextval('shoot.post_post_idx_seq'::regclass) post_title character varying(32) not null post_type smallint not null post_video character(26) not null post_upload_time timestamp without time zone not null CURRENT_TIMESTAMP upload_channel_email character varying(320) not null post_description character varying(1024) post_thumbnail character(30) post_good_count integer not null 0 delete_time timestamp without time zone comment_count integer not null 0 post_view_count integer not null 0 category_idx integer not null '-1'::integer
프로젝트에서 사용했던 두 테이블을 다양항 상황에서 JOIN을 해보도록 하자
SELECT * FROM shoot.post JOIN shoot.channel ON shoot.post.upload_channel_email = shoot.channel.emailsql은 위의 적힌대로 사용해본다.
경우 1 : 외래키 부여
-
외래키 부여
Foreign-key constraints: "upload_channel_email" FOREIGN KEY (upload_channel_email) REFERENCES shoot.channel(email) ON DELETE CASCADE채널 테이블의 p key를 게시글 테이블의 upload_channel_email 컬럼의 f key로 등록해주었다. 이제 위의 쿼리를 EXPLAIN함수를 통해 어떻게 진행되었는지 보도록 하자
-
결과
QUERY PLAN -------------------------------------------------------------------------- Hash Join (cost=1.04..3.23 rows=10 width=1693) Hash Cond: ((post.upload_channel_email)::text = (channel.email)::text) -> Seq Scan on post (cost=0.00..2.10 rows=10 width=153) -> Hash (cost=1.02..1.02 rows=2 width=1540) -> Seq Scan on channel (cost=0.00..1.02 rows=2 width=1540)
경우 2 : 외래키 해제
-
외래키 해제
ALTER TABLE shoot.post DROP CONSTRAINT upload_channel_email;위의 sql을 실행하여 외래키 제약조건을 풀어주고 테스트 하였다.
-
결과
QUERY PLAN -------------------------------------------------------------------------- Hash Join (cost=1.04..3.23 rows=10 width=1693) Hash Cond: ((post.upload_channel_email)::text = (channel.email)::text) -> Seq Scan on post (cost=0.00..2.10 rows=10 width=153) -> Hash (cost=1.02..1.02 rows=2 width=1540) -> Seq Scan on channel (cost=0.00..1.02 rows=2 width=1540)결과는 똑같이 나왔다. 지금 상황에서는 외래키 제약조건이 있고 없고는 차이가 없나보다
경우 3 : 외래키 부여 + 인덱스 부여
-
외래키 부여 + 인덱스 부여
ALTER TABLE shoot.post ADD CONSTRAINT upload_channel_email FOREIGN KEY (upload_channel_email) REFERENCES shoot.channel (email) ON DELETE CASCADE; CREATE INDEX btree_test ON shoot.post USING btree (upload_channel_email);외래키도 다시 부여해주고 인덱싱도 b tree로 시켜줘보자
-
결과
QUERY PLAN -------------------------------------------------------------------------- Hash Join (cost=1.04..3.25 rows=11 width=1693) Hash Cond: ((post.upload_channel_email)::text = (channel.email)::text) -> Seq Scan on post (cost=0.00..2.11 rows=11 width=153) -> Hash (cost=1.02..1.02 rows=2 width=1540) -> Seq Scan on channel (cost=0.00..1.02 rows=2 width=1540)왜 계속 똑같은 결과가 나올까...
경우 4 : 외래키 해제 + 인덱스 부여
- 외래키 해제, 인덱스 부여
외래키를 다시 해제하고 테스트해보자ALTER TABLE shoot.post DROP CONSTRAINT upload_channel_email; - 결과
우리 옵티마이저 선생님이 외래키인지 뭔지 인덱싱이 됐는지 안됐는지는 지금 관심이 없어보인다.QUERY PLAN -------------------------------------------------------------------------- Hash Join (cost=1.04..3.25 rows=11 width=1693) Hash Cond: ((post.upload_channel_email)::text = (channel.email)::text) -> Seq Scan on post (cost=0.00..2.11 rows=11 width=153) -> Hash (cost=1.02..1.02 rows=2 width=1540) -> Seq Scan on channel (cost=0.00..1.02 rows=2 width=1540)
효율적인 방법 알아보고 싶었는데 옵티마이저 선생님은 지금 내가 생각한 원인들에 크게 관심이 없어보인다.
결론
JOIN이 어떤식으로 작동하는지 알아보고 JOIN을 더 효율적으로 사용하는 방법을 알아보려고 했다. JOIN을 효율적으로 사용하기 위해 옵티마이저가 잘 선택할 수 있도록 그리고 그 선택한 방법이 효율적으로 돌아갈 수 있도록 하는 것이 중요하다고 생각했다.
그래서 F key와 column 인덱스에 집중하여 테스트를 해봤다. 그런데 옵티마이저가 항상 같은 선택을 한다. 그래서 옵티마이저가 같은 선택을 한 이유는 다음과 같은 경우가 있다고 생각한다.
- 각 테이블에 들어있는 데이터 개수가 너무 적어 옵티마이저가 항상 같은 선택을 했다. 즉 옵티마이저의 결정에 f key나 인덱스보다는 테이블 데이터 개수가 더 큰 영향을 줬다.
- upload_channel_email 테이블을 b tree로 인덱싱하는 것은 의미가 없다. 즉 옵티마이저는 그 컬럼을 b tree로 인덱싱했다고 해서 옵티마이저가 신경을 써주는 것은 아니다.
- 인덱싱이나 f key는 사실 영향을 주는 것은 맞는데 더 큰 영향을 주는 원인이 존재한다.
그래서 다음에는 옵티마이저에 대해서 더 깊게 알아보려고 한다. 그리고 오늘 옵티마이저가 똑같은 결과를 도출한 이유에 대해서도 알아보려고 한다.
참고
- https://www.w3schools.com/sql/sql_join.asp
- https://www.dofactory.com/sql/join
- https://schatz37.tistory.com/2
- https://velog.io/@hansung/Postgresql-Cost-Based-OptimizerCBO
- https://dataonair.or.kr/db-tech-reference/d-guide/da-guide/?mod=document&uid=305#:~:text=Hash%20%EC%A1%B0%EC%9D%B8%EC%9D%98%20%EA%B8%B0%EB%B3%B8%20%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98,%EC%9D%84%20%ED%83%90%EC%B9%A8%ED%95%9C%EB%8B%A4%E2%80%9D%EB%8A%94%20%EA%B2%83%EC%9D%B4%EB%8B%A4.
- https://stackoverflow.com/questions/49023821/nested-join-vs-merge-join-vs-hash-join-in-postgresql
- https://coding-factory.tistory.com/758
- https://itholic.github.io/database-cardinality/
